This article will explain what problems can occur when working with SQL NULL values and it also gives some solution recommendations to overcome these issues.
Read more »
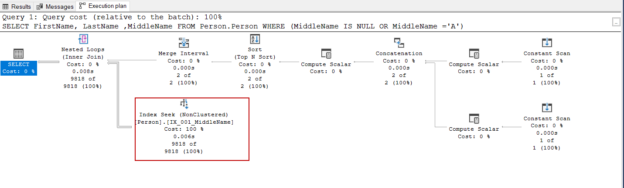
This article will explain what problems can occur when working with SQL NULL values and it also gives some solution recommendations to overcome these issues.
Read more »
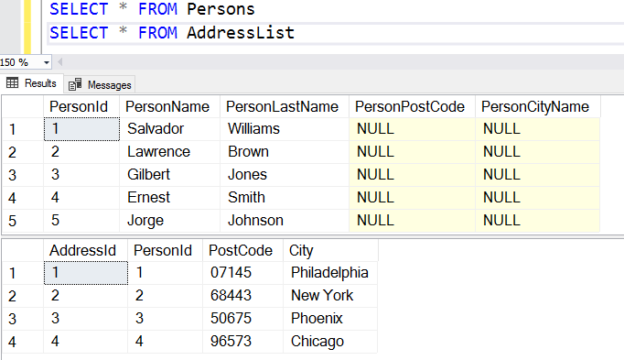
SQL Server creates an optimized execution plan based on the available inputs such as statistics, indexes. By default, it chooses a cost-optimized execution plan and executes the query. Sometimes, we use SQL queries table hints to override the default mechanism. Developers popularly use WITH (NOLOCK) query hint in a Select statement to avoid blocking issues.
Read more »
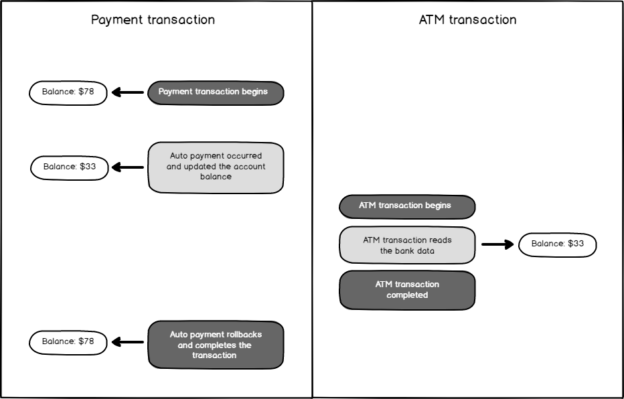
In this article, we will discuss the Dirty Read concurrency issue and also learn the details of the Read Uncommitted Isolation Level.
Read more »
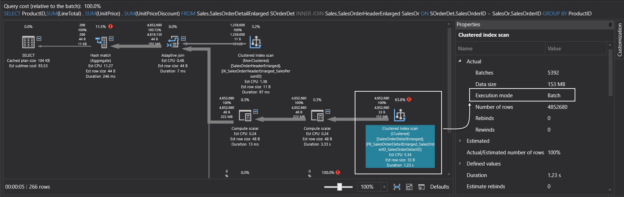
In this article, we will talk about SQL interview questions and answers that can be asked in the second-round technical stage. These interview questions are based on real-life experiences. Therefore, it can be a very useful source when preparing for the second round of SQL technical interviews.
Read more »
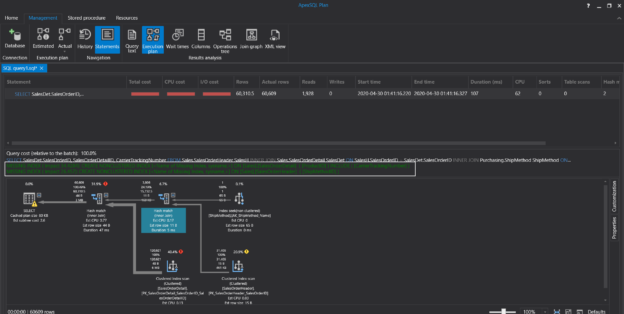
In this article, we will continue to learn essential techniques of the SQL Server query tuning with practical examples.
Read more »
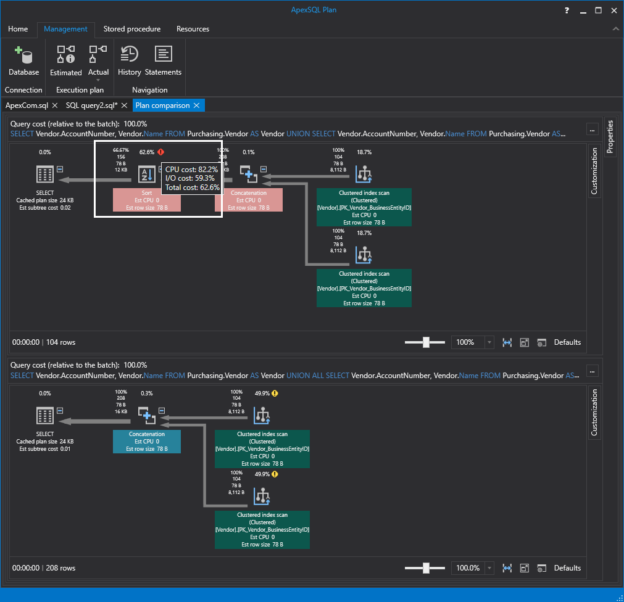
This article will cover some essential techniques for SQL query tuning. Query tuning is a very wide topic to talk about, but some essential techniques never change in order to tune queries in SQL Server. Particularly, it is a difficult issue for those who are a newbie to SQL query tuning or who are thinking about starting it. So, this article will be a good starting point for them. Also, other readers can refresh their knowledge with this article. In the next parts of this article, we will mention these techniques that help to tune queries.
Read more »
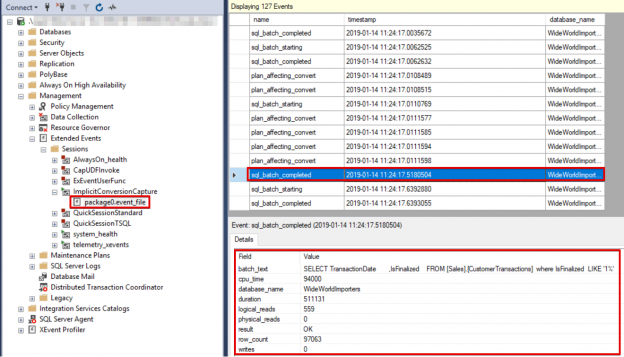
This article will provide an overview of SQL Server implicit conversion including data type precedence and conversion tables, implicit conversion examples and means to detect occurrences of implicit conversion
Read more »
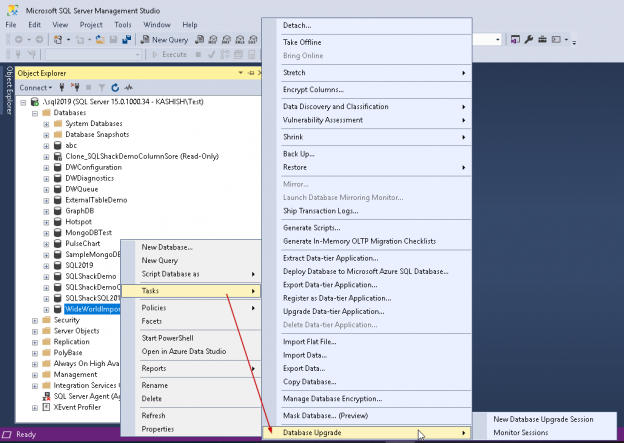
This article will cover managing a SQL Server database upgrade using new features in SQL Server Management Studio 18 including the query tuning assistant wizard, database upgrade feature, query store and more

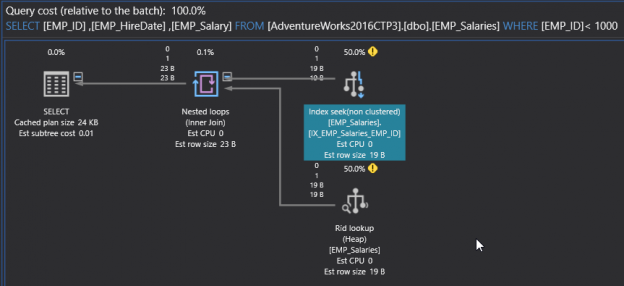
In the previous articles of this series (see the index at bottom), we discussed the characteristics of the SQL Execution Plan from multiple aspects, that include the way the SQL Execution Plan is generated by the SQL Server Query Optimizer internally, what are the different types of plans, how to identify and analyze the different components and operators of the Execution Plans, how to work with the plans using different tools and finally, tuning the performance of simple and complex T-SQL queries using the Execution Plans. In this, the last article of this series, but not the least, we will discuss where the Execution plan is stored and how to save it for future use.
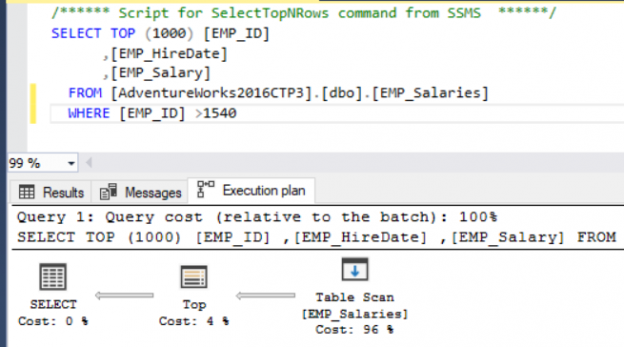
In the previous articles of this series (see the index at bottom), we went through many aspects of the SQL Execution Plan, where we discussed how the Execution Plan is generated internally, the different types of plans, the main components and operators and how to read and analyze the plans that are generated using different tools. In this article, we will show how we can use an Execution Plan in tuning the performance of T-SQL queries.
Read more »
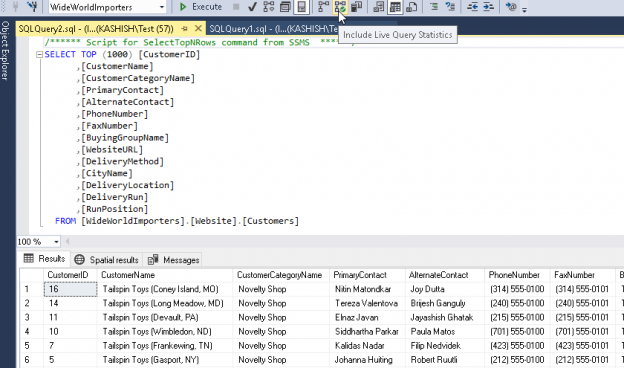
Database administrators are used to dealing with query performance issues. As part of this duty, it is an important aspect to identify the query and troubleshoot the reason for its performance degradation. Normally, we used to enable SET STATISTICS IO and SET STATISTICS TIME before executing any query.
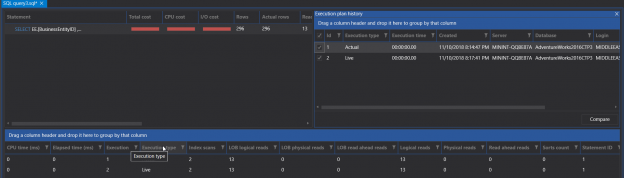
In the previous articles of this series (see the index at bottom), we discussed many aspects of the SQL Execution Plans, starting with the main concept of SQL Execution Plan generation, diving in the different types of the plans and showing how to analyze the components and operators of the SQL Execution Plans.
Read more »
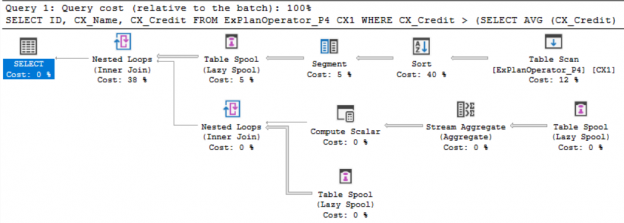
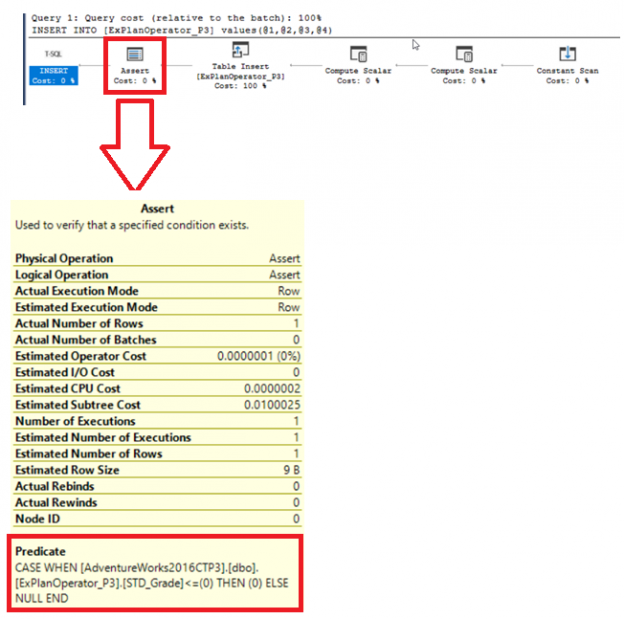
In the previous articles of this series, we went through three sets of SQL Server Execution Plan operators that you will meet with while working with the different Execution Plan queries. We described the Table Scan, Clustered Index Scan, Clustered Index Seek, the Non-Clustered Index Seek, RID Lookup, Key Lookup, Sort, Aggregate – Stream Aggregate, Compute Scalar, Concatenation, Assert, Hash Match Join, Hash Match Aggregate , Merge Join and Nested Loops Join Execution Plan operators. In this article, we will dive in the fourth set of these SQL Server Execution Plan operators.
Read more »
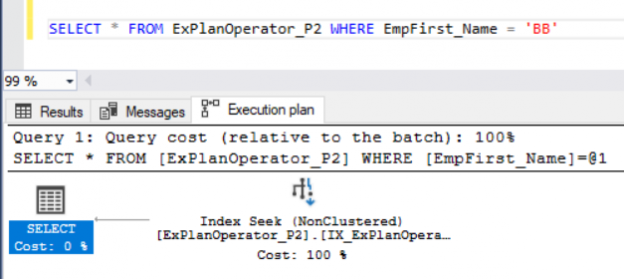
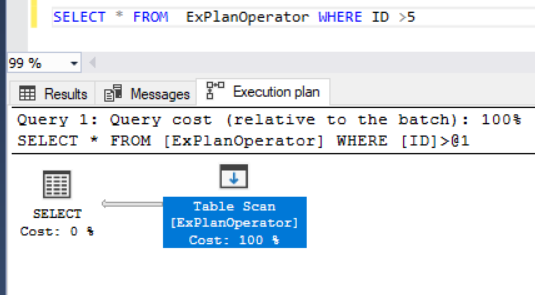
In the previous articles of this series, we discussed a group of SQL Server Execution Plan operators that you will face when studying the SQL Execution Plan of different queries. We showed the Table Scan, Clustered Index Scan, Clustered Index Seek, the Non-Clustered Index Seek, RID Lookup, Key Lookup and Sort Execution Plan operators. In this article, we will discuss the third set of these SQL Execution Plan operators.
Read more »
In the previous article, we talked about the first set of operators you may encounter when working with SQL Server Execution Plans. We described the Non Clustered Index, Seek Execution Plan operators, Table Scan, Clustered Index Scan, and the Clustered Index Seek. In this article, we will discuss the second set of these SQL Server execution plan operators.
Read more »
In the previous articles of this series, SQL Server Execution Plans overview , SQL Server Execution Plans types and How to Analyze SQL Execution Plan Graphical Components, we discussed the steps that are performed by the SQL Server Relational Engine to generate the Execution Plan of a submitted query and the steps performed by the SQL Server Storage Engine to retrieve the requested data or perform the requested modification operation.
Read more »
Of the many ways in which query performance can go awry, few are as misunderstood as parameter sniffing. Search the internet for solutions to a plan reuse problem, and many suggestions will be misleading, incomplete, or just plain wrong.
Read more »
Troubleshooting performance issues in a database is one of the main jobs of DBAs and by now most can trace the problem back to a query which is either running to slow or is causing a blocking issue on a key table. However, what is often not known is why this doesn’t cause problems in SSMS or why you don’t get the same query plan as what is inside the app. For example, in your extended event trace you see the query running longer from the application when compared to SSMS.
Read more »
In the previous article, we described, in detail, the different stages that a submitted SQL Server query goes through and how it processed by the SQL Server Relational Engine. The SQL Server Relational Engine generates the Execution Plan and the SQL Server Storage Engine performs the requested data retrieval or modification process. In this article, we will discuss the different types and formats for SQL Server Execution Plans.
Read more »
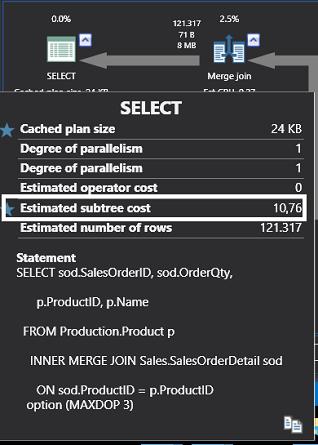
Query store was introduced in SQL Server 2016. It is often referred to as a “flight data recorder” for SQL Server. Its main function is that it captures the history of executed queries as well as certain statistics and execution plans. Furthermore, the data is persistent, unlike the plan cache in which the information is cleared upon a server restart or reboot. You can customize, within Query Store, how much and how long the query store can hold the data.
Read more »
One of the best ways to optimize performance in a database is to design it right the first time! Making design and architecture decisions based on facts and best practices will reduce technical debt and the number of fixes that you need to implement in the future.
Read more »
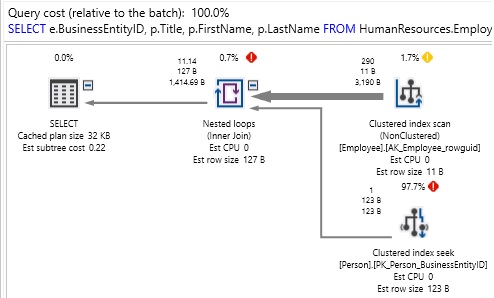
One of the main responsibilities of a database administrator is query tuning and troubleshooting query performance. In this context, SQL Server offers several tools to assist. But among them, query execution plans are essential for query optimization because they include all of the vital information about the query execution process. At the same time as it provides this valuable information “under the hood”, SQL Server creates a graphical description of the execution plan. Read more »
In this series of articles, we will navigate the SQL Server Execution Plan ocean, starting from defining the concept of the Execution Plans, walking through the types, components and operators of Execution Plans analyze execution plans and we’ll finish with how to save and administrate the Execution Plans.
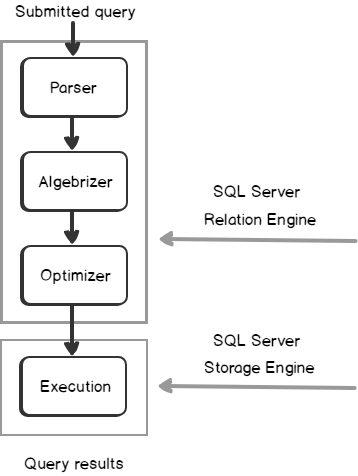
When you submit a T-SQL query, you tell the SQL Server Engine what you want, but without specifying how to do it for you. Between submitting the T-SQL query to the SQL Server Database Engine and returning the query result to the end user, the SQL Server Engine will perform four internal query processing operations, to convert the query into a format that can be used by the SQL Server Storage Engine easily use to retrieve the requested data, using the processes assigned to the SQL Engine from the Operating System to work on the submitted query.
Read more »
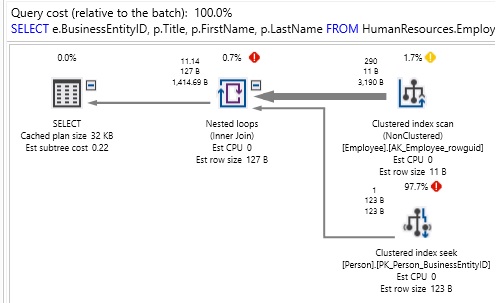
Fixing bad queries and resolving performance problems can involve hours (or days) of research and testing. Sometimes we can quickly cut that time by identifying common design patterns that are indicative of poorly performing TSQL.
Read more »
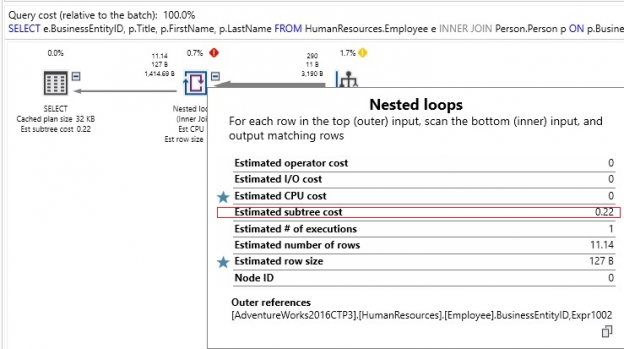
Fixing and preventing performance problems is critical to the success of any application. We will use a variety of tools and best practices to provide a set of techniques that can be used to analyze and speed up any performance problem!
Read more »© Quest Software Inc. ALL RIGHTS RESERVED. | GDPR | Terms of Use | Privacy