
Description
One of the best ways to optimize performance in a database is to design it right the first time! Making design and architecture decisions based on facts and best practices will reduce technical debt and the number of fixes that you need to implement in the future.
While there are often ways to tweak queries, indexes, and server settings to make things faster, there are limits to what we can accomplish in a cost-efficient and timely manner. Those limits are dictated by database architecture and application design. It may often seem that prioritizing good design up-front will cost more than the ability to roll features out quickly, but in the long-run, the price paid for hasty or poorly-thought-out decisions will be higher.
This article is a fast-paced dive into the various design considerations that we can make when building new databases, tables, or procedural TSQL. Consider these as ways to improve performance in the long-term by making careful, well thought-out decisions now. Predicting the future of an application may not be easy when we are still nursing it through infancy, but we can consider a variety of tips that will give us a better shot at doing it right the first time!
“Measure twice, cut once” applies to application development in that regard. We need to accept that doing it right the first time will be significantly cheaper and less time-consuming than needing to rearchitect in the future.
Understand the application
Learn the business need behind the application and its database. In addition to a basic understanding of what an app will do, consider the following questions:
- What is it used for? What is the app and its purpose? What kind of data will be involved?
- Who will access it? Will it be end-users on the web or internal employees? Will it be 5 people, 5,000 people or 5 million people?
- How will they access it? Will it be a web page? Mobile app? Local software on a computer or private cloud? A reporting interface?
- Are there specific times of day when usage is heavier? Do we need to accommodate busy times with extra resources? Will quiet times allow for planned maintenance or downtime? What sort of uptime is expected?
Getting a basic idea of the purpose of a database will allow you to better forecast its future and avoid making any major mistakes in the beginning. If we know about application quirks, such as busy or quiet times, the use of ORMs, or the use of an API, we can better understand how it will interact with the database and make decisions to accommodate that usage.
Often, a good understanding of the app allows us to make simplifying assumptions and cut through a lot of the decisions we need to make. This conversation may involve both technical folks (architects, developers, engineers, and other DBAs) or it may involve business reps that have a strong understanding of the purpose of the app, even if they may not know much about the technical implementation of it.
Here are some more details on the questions and considerations we should make when designing new database objects:
Scalability
How will the application and its data grow over time? The ways we build, maintain, and query data change when we know the volume will be huge. Very often we build and test code in very controlled dev/QA environments in which the data flow does not mirror a real production environment. Even without this, we should be able to estimate how much an app will be used and what the most common needs will be.
We can then infer metrics such as database size, memory needs, CPU, and throughput. We want the hardware that we put our databases on to be able to perform adequately and this requires us to allocate enough computing resources to make this happen. A 10TB database will likely not perform well (or at all) on a server with 2GB of RAM available to it. Similarly, a high-traffic application may require faster throughput on the network and storage infrastructure, in addition to speedy SSDs. A database will only perform as quickly as its slowest component, and it is up to us to make sure that the slowest component is fast enough for our app.
How will data size grow over time? Can we easily expand storage and memory easily when needed? If downtime is not an option, then we will need to consider hardware configurations that will either provide a ton of extra overhead to start or allow for seamless expansions later on. If we are not certain of data growth, do we expect the user or customer count to grow? If so, we may be able to infer data or usage growth based on this.
Licensing matters, too as licensing database software isn’t cheap. We should consider what edition of SQL Server will function on and what the least expensive edition is that we are allowed to use. A completely internal server with no customer-facing customer access may be able to benefit from using Developer edition. Alternatively, the choice between Enterprise and Standard may be decided by features (such as AlwaysOn) or capacity (memory limitations, for example). A link is provided at the end of this article with extensive comparisons between editions of SQL Server.
High availability and disaster recovery are very important considerations early-on that often are not visited until it is too late. What is the expected up-time of the app? How quickly are we expected to recover from an outage (recovery time objective/RTO)? In addition, how much data loss is tolerated in the event of an outage or disaster (recovery point objective,/RPO)? These are tough questions as businesses will often ask for a guarantee of zero downtime and no data loss, but will back off when they realize the cost to do so is astronomically high. This discussion is very important to have prior to an application being released as it ensures that contracts, terms of service, and other documentation accurately reflect the technical capabilities of the systems it resides on. It also allows you to plan ahead with disaster recovery plans and avoid the panic often associated with unexpected outages.
Data types
One of the most basic decisions that we can make when designing a database is to choose the right data types. Good choices can improve performance and maintainability. Poor choices will make work for us in the future 🙂
Choose natural data types that fit the data being stored. A date should be a date, not a string. A bit should be a bit and not an integer or string. Many of these decisions are holdovers from years ago when data types were more limited and developers had to be creative in order to generate the data they wanted.
Choose length, precision, and size that fits the use case. Extra precision may seem like a useful add-on, but can be confusing to developers who need to understand why a DECIMAL(18,4) contains data with only two digits of decimal detail. Similarly, using a DATETIME to store a DATE or TIME can also be confusing and lead to bad data.
When in doubt, consider using a standard, such as ISO5218 for gender, ISO3166 for country, or ISO4217 for currency. These allow you to quickly refer anyone to universal documentation on what data should look like, what is valid, and how it should be interpreted.
Avoid storing HTML, XML, JSON, or other markup languages in the database. Storing, retrieving, and displaying this data is expensive. Let the app manage data presentation, not the database. A database exists to store and retrieve data, not to generate pretty documents or web pages.
Dates and times should be consistent across all tables. If time zones or locations will matter, consider using UTC time or DATETIMEOFFSET to model them. Upgrading a database in the future to add time zone support is much harder than using these conventions in the beginning. Dates, times, and durations are different. Label them so that it is easy to understand what they mean. Duration should be stored in a one-dimensional scalar unit, such as seconds or minutes. Storing duration in the format “HH:MM:SS.mmm” is confusing and difficult to manipulate when mathematical operations are needed.
NULLs
Use NULL when non-existence of data needs to be modelled in a meaningful fashion. Do not use made-up data to fill in NOT NULL columns, such as “1/1/1900” for dates, “-1” for integers, “00:00:00” for times, or “N/A” for strings. NOT NULL should mean that a column is required by an application and should always be populated with meaningful data.
NULL should have meaning and that meaning should be defined when the database is being designed. For example, “request_complete_date = NULL” could mean that a request is not yet complete. “Parent_id = NULL“ could indicate an entity with no parent.
NULL can be eliminated by additional normalization. For example, a parent-child table could be created that models all hierarchical relationships for an entity. This may be beneficial if these relationships form a critical component of how an app operates. Reserve the removal of NULLable columns via normalization for those that are important to an app or that may require additional supporting schema to function well. As always, normalization for the sake of normalization is probably not a good thing!
Beware NULL behavior. ORDER BY, GROUP BY, equalities, inequalities, and aggregate functions will all treat NULL differently. Always SET ANSI_NULLS ON. When performing operations on NULLable columns, be sure to check for NULL whenever needed. Here is a simple example from Adventureworks:
|
1 2 3 4 5 6 7 8 9 |
SELECT * FROM Person.Person WHERE Title = NULL SELECT * FROM Person.Person WHERE Title IS NULL |
These queries look similar but will return different results. The first query will return 0 rows, whereas the second will return 18,963 rows:
The reason is that NULL is not a value and cannot be treated like a number or string. When checking for NULL or working with NULLable columns, always check and validate if you wish to include or exclude NULL values, and always use IS NOT NULL or IS NULL, instead of =, <, >, etc…
SET ANSI NULLS ON is a default in SQL Server and should be left as a default. Adjusting this will change how the above behavior works and will go against ANSI standards. Building code to handle NULL effectively is a far more scalable approach than adjusting this setting.
Object names
Naming things is hard! Choosing descriptive, useful names for objects will greatly improve readability and the ability for developers to easily use those objects for their work and not make unintended mistakes.
Name an object for what it is. Include units in the name if they are not absurdly obvious. “duration_in_seconds” is much more useful than “duration”. “Length_inches” is easier to understand than “length”. Bit columns should be named in the positive and match the business use case: “is_active”, “is_flagged_for_deletion”, “has_seventeen_pizzas”. Negative columns are usually confusing: “is_not_taxable”, “has_no_pizzas”, “is_not_active” will lead to mistakes and confusion as they are not intuitive. Database schema should not require puzzle-solving skills to understand ?
Other things to avoid:
- Abbreviations & shorthand. This is rarely not confusing. If typing speed is a concern for slower typists, consider the many tools available that provide Intellisense or similar auto-completion features.
- Spaces & special characters. They will break maintenance processes, confuse developers, and be a nuisance to type correctly when needed. Stick to numbers, letters, and underscores.
- Reserved words. If it’s blue, white, or pink in SSMS, don’t use it! This only causes confusion and increases the chances of logical coding errors.
Consistency is valuable and creating effective naming schemes early will pay dividends later when there is no need to “fix” standards to not be awful. As for the debate between capitalization and whether you should use no capitals, camel case, pascal case, etc…, this is completely arbitrary and up to a development team. In databases with lots of objects, prefixes can be used to allow objects of specific types, origins, or purposes to be easily searchable. Alternatively, different schemas can be used to divide up objects of different types.
Good object naming reduces mistakes and errors while speeding up app development. While nothing is truly self-documenting, quality object names reduce the need to find additional resources (docs or people) to determine what something is for or what it means.
Old Data
Whenever data is created, ask the question, “How long should it exist for?”. Forever is a long time and most data does not need to live forever. Find out or create a data retention policy for all data and write code to enforce it. Many businesses have compliance or privacy rules to follow that may dictate how long data needs to be retained for.
Limiting data size is a great way to improve performance and reduce data footprint! This is true for any table that stores historical data. A smaller table means smaller indexes, less storage use, less memory use, and less network bandwidth usage. All scans and seeks will be faster as the indexes are more compact and quicker to search.
There are many ways to deal with old data. Here are a few examples:
- Delete it. Forever. If allowed, this is an easy and quick solution.
- Archive it. Copy it to a secondary location (different database, server, partition, etc…) and then delete it.
- Soft-delete it. Have a flag that indicates that it is no longer relevant and can be ignored in normal processes. This is a good solution when you can leverage different storage partitions, filtered indexes, or ways to segregate data as soon as it is flagged as old.
- Nothing. Some data truly is needed forever. If so, consider how to make the underlying structures scalable so that they perform well in the future. Consider how large the tables can grow.
Data retention doesn’t only involve production OLTP tables, but may also include backup files, reporting data, or data copies. Be sure to apply your retention policies to everything!
Cartesian Products (Cross Joins/No Join Predicate)
All joins occur between some data set and a new data set. In bringing them together, we are connecting them via some set of keys. When we join data sets without any matching criteria, we are performing a CROSS JOIN (or cartesian product). While this can be a useful way to generate data needed by an application, it can also be a performance and data quality issue when done unintentionally.
There are a variety of ways to generate CROSS JOIN conditions:
- Use the CROSS JOIN operator
- Enter incorrect join criteria
- Unintentionally omit a join predicate
- Forget a WHERE clause
The following query is an example of the second possibility:
|
1 2 3 4 5 6 7 8 |
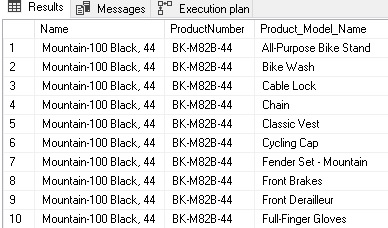
SELECT Product.Name, Product.ProductNumber, ProductModel.Name AS Product_Model_Name FROM Production.Product INNER JOIN Production.ProductModel ON ProductModel.ProductModelID = ProductModel.ProductModelID WHERE Product.ProductID = 777; |
What we expect is a single row returned with some product data. What we get instead are 128 rows, one for each product model:
We have two hints that something has gone wrong: An overly large result set, and an unexpected index scan in the execution plan:
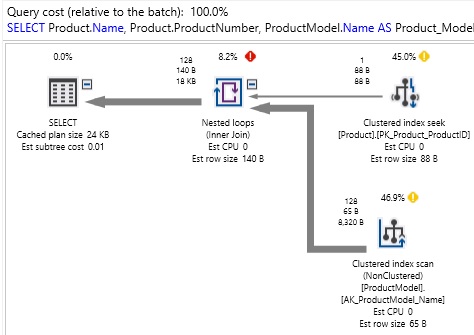
Upon closer inspection of our query, it becomes obvious that I fat-fingered the INNER JOIN and did not enter the correct table names:
|
1 2 |
INNER JOIN Production.ProductModel ON ProductModel.ProductModelID = ProductModel.ProductModelID |
By entering ProductModel on both sides of the join, I inadvertently told SQL Server to not join Product to ProductModel, but instead join Product to the entirety of ProductModel. This occurs because ProductModel.ProductModel will always equal itself. I could have entered “ON 1 = 1” for the join criteria and seen the same results.
The correction here is simple, adjust the join criteria to connect Product to ProductModel, as was intended:
|
1 2 |
INNER JOIN Production.ProductModel ON Product.ProductModelID = ProductModel.ProductModelID |
Once fixed, the query returns a single row and utilizes an index seek on ProductModel.
Situations in which a join predicate is missing or wrong can be difficult to detect. SQL Server does not always warn you of this situation, and you may not see an error message or show-stopping bad performance that gets your immediate attention. Here are some tips on catching bad joins before they cause production headaches:
- Make sure that each join correlates an existing data set with the new table. CROSS JOINs should only be used when needed (and intentionally) to inflate the size/depth a data set.
- An execution plan may indicate a “No Join Predicate” warning on a specific join in the execution plan. If so, then you’ll know exactly where to begin your research.
- Check the size of the result set. Is it too large? Are any tables being cross joined across an entire data set, resulting in extra rows of legit data with extraneous data tacked onto the end of it?
- Do you see any unusual index scans in the execution plan? Are they for tables where you expect to only seek a few rows, such as in a lookup table?
For reference, here is an example of what a “No Join Predicate” warning looks like:
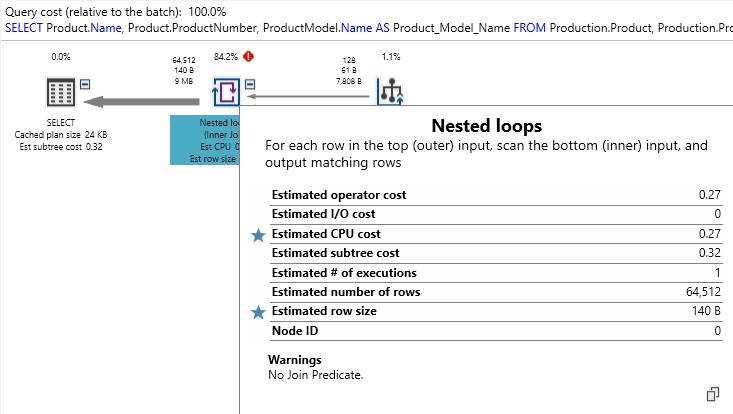
We’ll follow the standard rule that yellow and red exclamation marks will always warrant further investigation. In doing so, we can see that this specific join is flagged as having no join predicate. In a short query, this is easy to spot, but in a larger query against many tables, it is easy for these problems to get buried in a larger execution plan.
Iteration
SQL Server is optimized for set-based operations and performs best when you read and write data in batches, rather than row-by-row. Applications are not constrained in this fashion and often use iteration as a method to parse data sets.
While it may anecdotally seem that collecting 100 rows from a table one-at-a-time or all at once would take the same effort overall, the reality is that the effort to connect to storage and read pages into memory takes a distinct amount of overhead. As a result, one hundred index seeks of one row each will take far more time and resources than one seek of a hundred rows:
|
1 2 3 4 5 6 7 8 9 10 |
DECLARE @id INT = (SELECT MIN(BusinessEntityID) FROM HumanResources.Employee) WHILE @id <= 100 BEGIN UPDATE HumanResources.Employee SET VacationHours = VacationHours + 4 WHERE BusinessEntityID = @id AND VacationHours < 200; SET @id = @id + 1; END |
This example is simple: iterate through a loop, update an employee record, increment a counter and repeat 99 times. The performance is slow and the execution plan/IO cost abysmal:
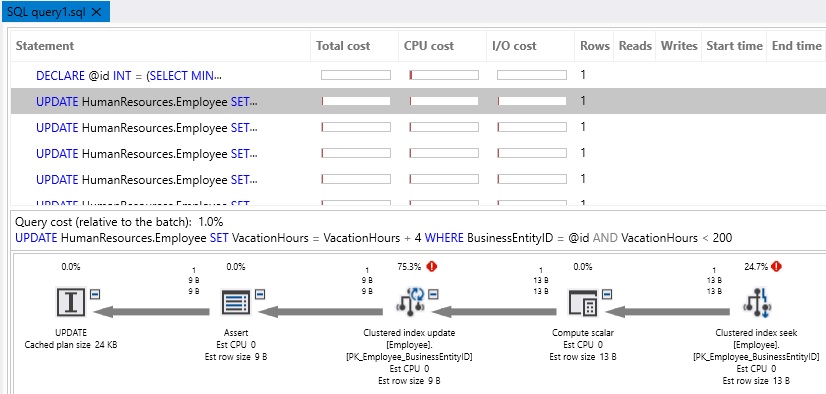
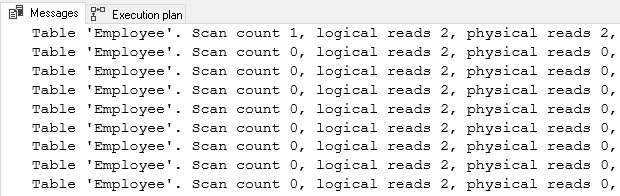
At first glance, things seem good: Lots of index seeks and each read operation is inexpensive. When we look more closely, we realize that while 2 reads may seem cheap, we need to multiply that by 100. The same is true for the 100 execution plans that were generated for all of the update operations.
Let’s say we rewrite this to update all 100 rows in a single operation:
|
1 2 3 4 |
UPDATE HumanResources.Employee SET VacationHours = VacationHours + 4 WHERE VacationHours < 200 AND BusinessEntityID <= 100; |


Instead of 200 reads, we only need 5, and instead of 100 execution plans, we only need 1.
Data in SQL Server is stored in 8kb pages. When we read rows of data from disk or memory, we are reading 8kb pages, regardless of the data size. In our iterative example above, each read operation did not simply read a few numeric values from disk and update one, but had to read all of the necessary 8kb pages needed to service the entire query.
Iteration is often hidden from view because each operation is fast an inexpensive, making it difficult to locate it when reviewing extended events or trace data. Watching out for CURSOR use, WHILE loops, and GOTO can help us catch it, even when there is no single poor-performing operation.
There are other tools available that can help us avoid iteration. For example, a common need when inserting new rows into a table is to immediately return the IDENTITY value for that new row. This can be accomplished by using @@IDENTITY or SCOPE_IDENTITY(), but these are not set-based functions. To use them, we must iterate through insert operations one-at-a-time and retrieve/process the new identity values after each loop. For row counts greater than 2 or 3, we will begin to see the same inefficiencies introduced above.
The following code is a short example of how to use OUTPUT INSERTED to retrieve IDENTITY values in bulk, without the need for iteration:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
CREATE TABLE #color (color_id SMALLINT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED, color_name VARCHAR(50) NOT NULL, datetime_added_utc DATETIME); CREATE TABLE #id_values (color_id SMALLINT NOT NULL PRIMARY KEY CLUSTERED, color_name VARCHAR(50) NOT NULL); INSERT INTO #color (color_name, datetime_added_utc) OUTPUT INSERTED.color_id, INSERTED.color_name INTO #id_values VALUES ('Red', GETUTCDATE()), ('Blue', GETUTCDATE()), ('Yellow', GETUTCDATE()), ('Brown', GETUTCDATE()), ('Pink', GETUTCDATE()); SELECT * FROM #id_values; DROP TABLE #color; DROP TABLE #id_values; |
In this script, we insert new rows into #color in a set-based fashion, and pull the newly inserted IDs, as well as color_name, into a temp table. Once in the temp table, we can use those new values for whatever additional operations are required, without the need to iterate through each INSERT operation one-at-a-time.
Window functions are also very useful for minimizing the need to iterate. Using them, we can pull row counts, sums, min/max values, and more without executing additional queries or iterating through data windows manually:
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT SalesOrderHeader.SalesOrderID, SalesOrderDetail.SalesOrderDetailID, SalesOrderHeader.SalesPersonID, ROW_NUMBER() OVER (PARTITION BY SalesOrderHeader.SalesPersonID ORDER BY SalesOrderDetail.SalesOrderDetailID ASC) AS SalesPersonRowNum, SUM(SalesOrderHeader.SubTotal) OVER (PARTITION BY SalesOrderHeader.SalesPersonID ORDER BY SalesOrderDetail.SalesOrderDetailID ASC) AS SalesPersonSales FROM Sales.SalesOrderHeader INNER JOIN Sales.SalesOrderDetail ON SalesOrderDetail.SalesOrderID = SalesOrderHeader.SalesOrderID WHERE SalesOrderHeader.SalesPersonID IS NOT NULL AND SalesOrderHeader.Status = 5; |
The results of this query show us not only a row per detail line, but include a running count of orders per sales person and a running total of sales:
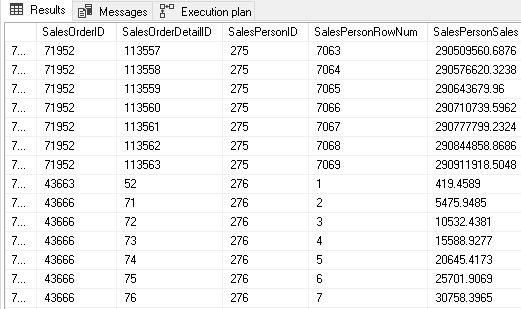
Window functions are not inherently efficient: The above query required some hefty sort operations to generate the results. Despite the cost, this is far more efficient that iterating through all sales people, orders, or some other iterative operation over a large data set:

In addition to avoiding iteration, we also avoid the need for aggregation within our query, allowing us to freely select whatever columns we’d like without the typical constraints of GROUP BY/HAVING queries.
Iteration is not always a bad thing. Sometimes we need to query all databases on a server or all servers in a list. Other times we need to call a stored procedure, send emails, or perform other operations that are either inefficient or impossible to do in a set-based fashion. In these scenarios, make sure that performance is adequate and that the number of times that a loop needs to be repeated is limited to prevent unexpected long-running jobs.
Encapsulation
When writing application code, encapsulation is used as a way to reuse code and simplify complex interfaces. By packaging code into functions, stored procedures, and views, we can very easily offload important business logic or reusable code to a common place, where it can be called by any other code.
While this sounds like a very good thing, when overused it can very quickly introduce performance bottlenecks as chains of objects linked together by other encapsulated objects increases. For example: a stored procedure that calls a stored procedure that uses a function that calls a view that calls a view that calls a view. This may sound absurd but is a very common outcome when views and nested stored procedures are relied on heavily.
How does this cause performance problems? Here are a few common ways:
- Unnecessary joins, filters, and subqueries are applied, but not needed.
- Columns are returned that are not needed for a given application.
- INNER JOINs, CROSS JOINs, or filters force reads against tables that are not needed for a given operation.
- Query size (# of tables referenced in query) results in a poor execution plan.
- Logical mistakes are made due to obfuscated query logic not being fully understood.
Here is an example of an AdventureWorks query in which simple intentions have complex results:
|
1 2 3 4 5 6 7 |
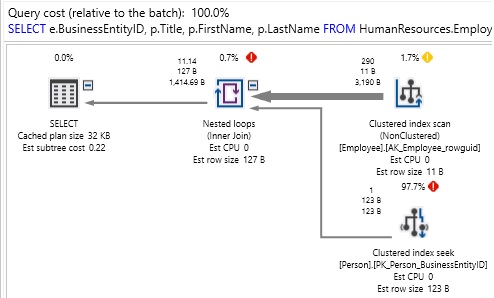
SELECT BusinessEntityID, Title, FirstName, LastName FROM HumanResources.vEmployee WHERE FirstName LIKE 'E%' |
At first glance, this query is pulling only 4 columns from the employee view. The results are what we expect, but it runs a bit longer than we’d want (over 1 second). Checking the execution plan and IO stats reveals:
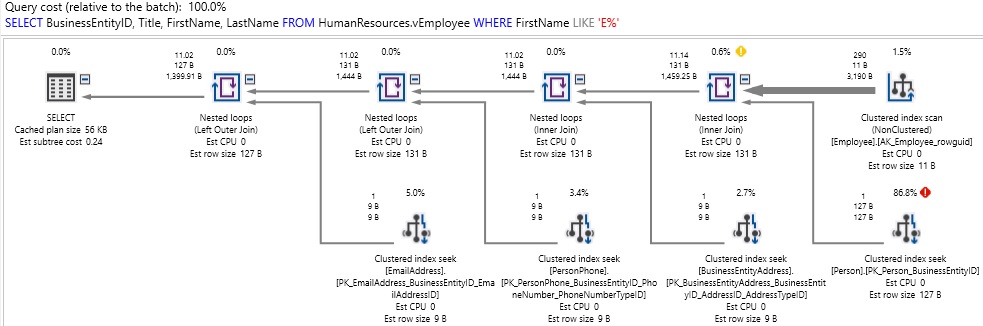

What we discover is that there was quite a bit going on behind-the-scenes that we were not aware of. Tables were accessed that we didn’t need, and excess reads performed as a result. This leads us to ask: What is in vEmployee anyway!? Here is the definition of this view:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
CREATE VIEW [HumanResources].[vEmployee] AS SELECT e.[BusinessEntityID] ,p.[Title] ,p.[FirstName] ,p.[MiddleName] ,p.[LastName] ,p.[Suffix] ,e.[JobTitle] ,pp.[PhoneNumber] ,pnt.[Name] AS [PhoneNumberType] ,ea.[EmailAddress] ,p.[EmailPromotion] ,a.[AddressLine1] ,a.[AddressLine2] ,a.[City] ,sp.[Name] AS [StateProvinceName] ,a.[PostalCode] ,cr.[Name] AS [CountryRegionName] ,p.[AdditionalContactInfo] FROM [HumanResources].[Employee] e INNER JOIN [Person].[Person] p ON p.[BusinessEntityID] = e.[BusinessEntityID] INNER JOIN [Person].[BusinessEntityAddress] bea ON bea.[BusinessEntityID] = e.[BusinessEntityID] INNER JOIN [Person].[Address] a ON a.[AddressID] = bea.[AddressID] INNER JOIN [Person].[StateProvince] sp ON sp.[StateProvinceID] = a.[StateProvinceID] INNER JOIN [Person].[CountryRegion] cr ON cr.[CountryRegionCode] = sp.[CountryRegionCode] LEFT OUTER JOIN [Person].[PersonPhone] pp ON pp.BusinessEntityID = p.[BusinessEntityID] LEFT OUTER JOIN [Person].[PhoneNumberType] pnt ON pp.[PhoneNumberTypeID] = pnt.[PhoneNumberTypeID] LEFT OUTER JOIN [Person].[EmailAddress] ea ON p.[BusinessEntityID] = ea.[BusinessEntityID]; |
This view does not only contain basic Employee data, but also many other tables as well that we have no need for in our query. While the performance we experienced might be acceptable under some circumstances, it’s important to understand the contents of any objects we use to the extent that we can use them effectively. If performance were a key issue here, we could rewrite our query as follows:
|
1 2 3 4 5 6 7 8 9 |
SELECT e.BusinessEntityID, p.Title, p.FirstName, p.LastName FROM HumanResources.Employee e INNER JOIN Person.Person p ON p.BusinessEntityID = e.BusinessEntityID WHERE FirstName LIKE 'E%' |
This version only accesses the tables we need, thereby generating half the reads and a much simpler execution plan:
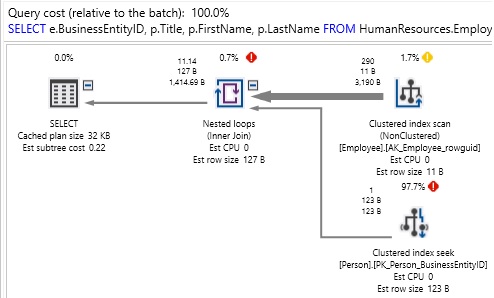

It is important to note that encapsulation is in no way a bad thing, but in the world of data, there are dangers to over-encapsulating business logic within the database. Here are some basic guidelines to help in avoiding performance problems resulting from the nesting of database objects:
- When possible, avoid nesting views within views. This improves visibility into code and reduces the chances of misunderstanding the contents of a given view.
- Avoid nesting functions if possible. This can be confusing and lead to challenging performance problems.
- Avoid triggers that call stored procedures or that perform too much business logic. Nested triggers are equally dangerous. Use caution when operations within triggers can fire more triggers.
- Understand the functionality of any defined objects (functions, triggers, views, stored procedures) prior to use. This will avoid misunderstandings of their purpose.
Storing important and frequently used TSQL in stored procedures, views, or functions can be a great way to increase maintainability via code reuse. Exercise caution and ensure that the complexity of encapsulated objects does not become too high. Performance can be inadvertently impacted when objects are nested many layers deep. When troubleshooting a problem query, always research the objects involved so that you have full exposure to any views, functions, stored procedures, or triggers that may also be involved in its execution.
OLTP vs. OLAP
Data is typically accessed either for transactional needs or analytical (reporting) needs. A database can be effectively optimized to handle either of these scenarios very well. The ways in which we performance tune for each is very different and needs some consideration when designing database elements.
OLTP
Online transaction processing refers to workloads in which data is written to and read for common interactive business usage. OLTP workloads are typically characterized by the following patterns:
- More writes, such as adding new data, updating rows, or deleting rows.
- More interactive operations in which people are logging into apps or web sites and directly viewing or modifying data. This comprises common business tasks.
- Operations on smaller row counts, such as updating an order, adding a new contact, or viewing recent transactions in a store. These operations often operate on current or recent data only.
- More tables and joins involved in queries.
- Timeliness is important. Since users are waiting for results, latency is not tolerated.
- High transaction counts, but typically small transaction size.
OLTP environments tend to be more relational, with indexes targeted at common updates, searches, or operations that are the core of an application. OLTP processes generally ensure, and rely on data integrity. This may necessitate the use of foreign keys, check constraints, default constraints, or triggers to assist in guaranteeing real-time data integrity.
OLAP
Online analytical processing generally refers to reporting or search environments. These are used for crunching large volumes of data, such as in reporting, data mining, or analytics. Common features of OLAP workloads are:
- Typical workloads are read-only, with writes only occurring during designated load/update times.
- Many operations are automated or scheduled to run and be delivered to users at a later time. These processes are often used to gain insight into a business and to assist in decision making processes.
- Operations can run on very large quantities of data. This can be crunching data year-over-year, trending spending over the past quarter, or any other task that may require pulling a longer history to complete.
- Tables tend to be wider and fewer, allowing for reports to be generated with less joins or lookups.
- Users may not be waiting for results, which can be delivered via email, file, or some other asynchronous means. If they are, there may be an expectation of delay due to the size of data. For reports where timeliness is important, the data can be crunched and staged ahead of time to assist in speedy results when requested.
- Low transaction count, but typically large transaction sizes.
OLAP environments are usually flatter and less relational. Data is created in OLTP applications and then passed onto OLAP environments where analytics can take place. As a result, we can often assume that data integrity has already been established. As a result, constraints, keys, and other similar checks can often be omitted.
If data is crunched or transformed, we can validate it afterwards, rather than real-time as with OLTP workloads. Quite a bit of creativity can be exercised in OLAP data, depending on how current data needs to be, how quickly results are requested, and the volume of history required to service requests.
Keeping them separated
Due to their vastly different needs, it behooves us to separate transactional and analytical systems as much as possible. One of the most common reasons that applications become slow and we resort to NOLOCK hints is when we try to run huge search queries or bulky reports against our transactional production application. As transaction counts become higher and data volume increases, the clash between transactional operations and analytical ones will increase. The common results are:
- Locking, blocking, and deadlocks when a large search/report runs and users are trying to update data.
- Over-indexing of tables in an effort to service all kinds of different queries.
- The removal of foreign keys and constraints to speed up writes.
- Application latency.
- Use of query hints as workarounds to performance problems.
- Throwing hardware at the database server in an effort to improve performance.
The optimal solution is to recognize the difference between OLAP and OLTP workloads when designing an application, and separate these environments on day 1. This often doesn’t happen due to time, cost, or personnel constraints.
Regardless of the severity of the problem or how long it has persisted, separating operations based on their type is the solution. Creating a new and separate environment to store OLAP data is the first step. This may be developed using AlwaysOn, log shipping, ETL processes, storage-level data copying, or many other solutions to make a copy of the OLTP data.
Once available, offloading operations can be a process that occurs over time. Easing into it allows for more QA and caution as a business grows familiar with new tools. As more operations are moved to a separate data store, you’ll be able to take remove reporting indexes from the OLTP data source and further optimize it for what it does best (service OLTP workloads). Similarly, the new OLAP data store can be optimized for analytics, allowing you to flatten tables, remove constraints and OLTP indexes, and make it faster for the operations that it services.
The more separated processes become, the easier it is to optimize each environment for its core uses. This results not only in far better performance, but also ease of development of new features. Tables built solely for reporting are far easier to write queries against than transactional tables. Similarly, being able to update application code with the knowledge that large reports won’t be running against the database removes many of the performance worries that typically are associated with a mixed environment.
Triggers
Triggers themselves are not bad, but overuse of them can certainly be a performance headache. Triggers are placed on tables and can fire instead of, or after inserts, updates, and/or deleted.
The scenarios when they can become performance problems is when there are too many of them. When updating a table results in inserts, updates, or deletes against 10 other tables, tracking performance can become very challenging as determining the specific code responsible can take time and lots of searching.
Triggers often are used to implement business/application logic, but this is not what a relational database is built or optimized for. In general, applications should manage as much of this as possible. When not possible, consider using stored procedures as opposed to triggers.
The danger of triggers is that they become a part of the calling transaction. A single write operation can easily become many and result in waits on other processes until all triggers have fired successfully.
To summarize some best practices:
- Use triggers only when needed, and not as a convenience or time-saver.
- Avoid triggers that call more triggers. These can lead to crippling amounts of IO or complex query paths that are frustrating to debug.
- Server trigger recursion should be turned off. This is the default. Allowing triggers to call themselves, directly or indirectly, can lead to unstable situations or infinite loops.
- Keep triggers simple and have them execute a single purpose.
Conclusion
Troubleshooting performance can be challenging, time-consuming, and frustrating. One of the best ways to avoid these troubles is to build a database intelligently up-front and avoid the need to have to fix things later.
By gathering information about an application and how it is used, we can make smart architecture decisions that will make our database more scalable and perform better over time. The result will be better performance and less need to waste time on troubleshooting broken things.
Table of contents
| Query optimization techniques in SQL Server: the basics |
| Query optimization techniques in SQL Server: tips and tricks |
| Query optimization techniques in SQL Server: Database Design and Architecture |
| Query Optimization Techniques in SQL Server: Parameter Sniffing |

In his free time, Ed enjoys video games, sci-fi & fantasy, traveling, and being as big of a geek as his friends will tolerate.
View all posts by Ed Pollack
- SQL Server Database Metrics - October 2, 2019
- Using SQL Server Database Metrics to Predict Application Problems - September 27, 2019
- SQL Injection: Detection and prevention - August 30, 2019