
In the previous article, we talked about the first set of operators you may encounter when working with SQL Server Execution Plans. We described the Non Clustered Index, Seek Execution Plan operators, Table Scan, Clustered Index Scan, and the Clustered Index Seek. In this article, we will discuss the second set of these SQL Server execution plan operators.
Let us first create the below table and fill it with 3K records to use it in the examples of this article. The table can be created and filled with data using the T-SQL script below:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
CREATE TABLE ExPlanOperator_P2 ( ID INT IDENTITY (1,1), EmpFirst_Name VARCHAR(50), EmpLast_name VARCHAR(50), EmpAddress VARCHAR(MAX), EmpPhoneNum varchar(50) ) GO INSERT INTO ExPlanOperator_P2 VALUES ('AB','BA','CB','123123') GO 1000 INSERT INTO ExPlanOperator_P2 VALUES ('DA','EB','FC','456456') GO 1000 INSERT INTO ExPlanOperator_P2 VALUES ('DC','EA','FB','789789') GO 1000 |
SQL Server RID Lookup Operator
Assume that we have a Non-Clustered index on the EmpFirst_Name column of the ExPlanOperator_P2 table, that is created using the CREATE INDEX T-SQL statement below:
|
1 |
CREATE INDEX IX_ExPlanOperator_P2_EmpFirst_Name ON ExPlanOperator_P2 (EmpFirst_Name) |
If you try to run the below SELECT statement to retrieve information about all employees with a specific EmpFirst_Name values, after including the Actual SQL Server execution plan of that query:
|
1 |
SELECT * FROM ExPlanOperator_P2 WHERE EmpFirst_Name = 'BB' |
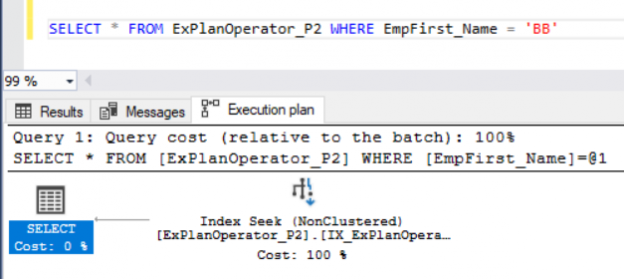
Checking the SQL Server explain plan generated after executing the query, you will see that the SQL Server Query Optimizer will use the Non-Clustered index to seek for all the employees with the EmpFirst_Name values equal to ‘BB’, without the need to scan the overall table for these values. On the other hand, the SQL Server Engine will not be able to retrieve all the requested values from that Non-Clustered index, as the query requests all columns for that filtered records. Recall that the Non-Clustered index contains only the key column values and a pointer to the rest of the columns for that key in the base table.
To dive deeply into the Non-Clustered index subject, see the article Designing effective SQL Server non-clustered indexes.
Due to the fact that this table contains no Clustered index, the table will be considered a heap table that has no criteria to sort its pages and sort the data within the pages.
For more information about the heap table structure, check SQL Server table structure overview.
Because of this, the SQL Server Engine will use the pointers from the Non-Clustered index, that points to the location of the rest of the columns on the base table, to locate and retrieve the rest of columns from the underlying table, using a Nested Loops operator to join the Index Seek data with the set of data retrieved from the RID Lookup operator, also known as a Row Identifier operator, as shown in the SQL Server execution plan below:
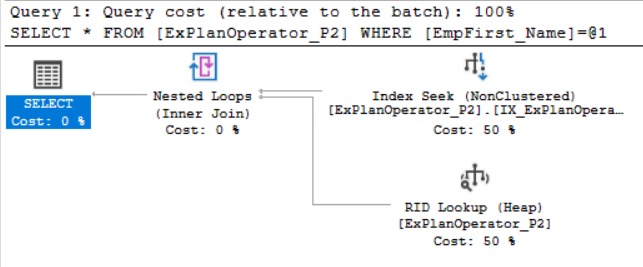
A RID is a row locator that includes information about the location of that record such as the database file, the page, the slot numbers that helps to identify the location of the row quickly. If you move the mouse to point to the RID Lookup on the generated SQL Server execution plan to view the tooltip of that operator, you will see in the Output List, the list of columns that are requested by the query and returned by this operator, as these columns are not located in the Non-Clustered index, as shown below:
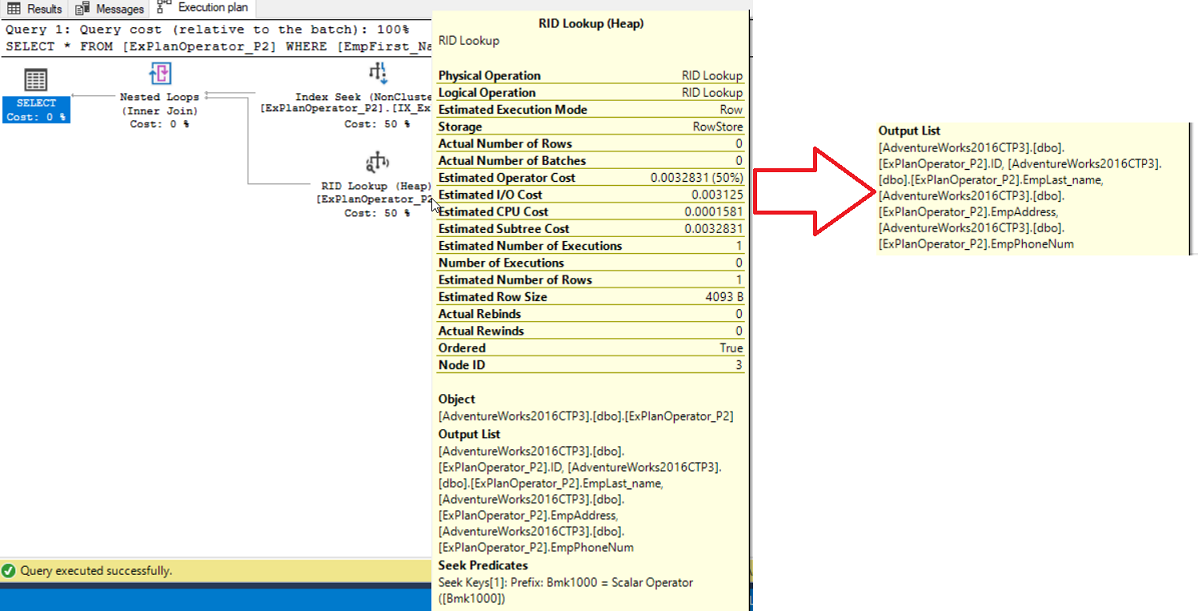
If you look at the RID Lookup operator in the SQL Server execution plan, you will see that the cost of that operator is high related to the overall weight of the plan, which is 50% in our example. This is due to the additional I/O overhead of the two different operations that are performed instead of a single one, before combining it with a Nested Loops operation. This overhead can be neglected when processing small number of rows. But if you are working with huge number of records, it is better to tune that query, rewrite the query by limiting the retrieved columns or create a covering index for that query. If the RID Lookup is eliminated by creating a covering index, the Nested Loops operator would not be needed in this SQL Server execution plan. To dig deeply in the covering index concept, check Working with different SQL Server indexes types.
SQL Server Key Lookup Operator
The Key Lookup operator is the Clustered equivalent of the RID Lookup operator described in the previous section. Assume that we have the below Clustered index that is created on the ID column of the EmpFirst_Name table, using the CREATE INDEX T-SQL statement below:
|
1 |
CREATE CLUSTERED INDEX IX_ExPlanOperator_P2_ID on ExPlanOperator_P2 (ID) |
If you try to run the previous SELECT statement that retrieves information about all employees with a specific EmpFirst_Name values, after including the Actual SQL Server execution plan of that query:
|
1 |
SELECT * FROM ExPlanOperator_P2 WHERE EmpFirst_Name = 'BB' |
Checking the SQL Server Execution Plan generated after executing the query, you will notice that the SQL Server Engine performed a seek operation on the Non-Clustered index to retrieve all the employees with the EmpFirst_Name column values equal to ‘BB’. But again, not all the columns can be retrieved from that Non-Clustered index. Therefore, the SQL Server Engine will derive benefits from the pointers existing on that Non-Clustered index that point to the rest of columns in the underlying table. And also due to the fact that this table is a Clustered table, that has a Clustered index that sorts that table’s data, the Non_Clustered index pointers will point to the Clustered index instead of pointing to the underlying table. The rest of columns will be retrieved using a Nested Loops operator to join the Index Seek data with the data retrieved from the Key Lookup operator, as the SQL Server Engine is not able to retrieve the rows in a shot. In other words, the SQL Server Engine will use the clustered index key as a reference to look up for the data that is stored in the clustered index using the clustered key values stored in the Non-Clustered index, as shown in the SQL Server execution plan below:
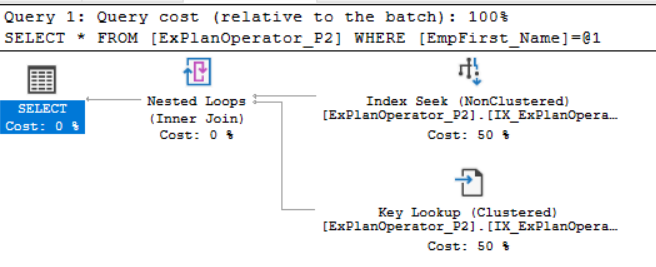
Similar to the RID Lookup operator, the Key Lookup is very expensive as it requires additional I/O overhead, depending on the number of records. In addition, the Key Lookup operator is an indicator that a covering or included index is required and may enhance the performance of that query by eliminating the need of the Key Lookup and Nested Loops operators. For example, if we include all the required columns in the existing Non-Clustered index, using the CREATE INDEX T-SQL statement below:
|
1 |
CREATE INDEX IX_ExPlanOperator_P2_EmpFirst_Name ON ExPlanOperator_P2 (EmpFirst_Name) INCLUDE (ID,EmpLast_name, EmpAddress, EmpPhoneNum) WITH (DROP_EXISTING = ON) |
Next run the previous SELECT statement with including the Actual Execution Plan. You will see that the Key Lookup and the Nested Loops operators are no longer used as the SQL Server Engine will retrieve all the requested data by seeking the Non-Clustered index, as shown below:
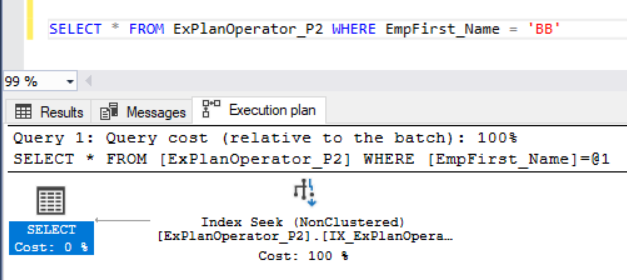
SQL Server Sort Operator
Assume that we run the below SELECT statement that returned the list of employees with a specific EmpFirst_Name value from the ExPlanOperator_P2 table, sorted by the EmpLast_Name column values descending, using the ORDER BY clause:
|
1 |
SELECT * FROM ExPlanOperator_P2 WHERE EmpFirst_Name = 'BB' ORDER BY EmpLast_name desc |
Checking the SQL Server execution plan generated after executing the query, you will see that the SQL Server Engine seeks the Non-Clustered index to retrieve the requested data, then the output of the Index Seek operator will be flown to the to the SORT operator to sort the data as specified in the ORDER BY clause, with the default ASC sorting direction if not specified. The SQL Server execution plan in our case will be like:

If you move the mouse to point to the SORT operator, you will see that the output of the SORT operator is the same input columns but sorted by the specified column, as in the Tooltip shown below:
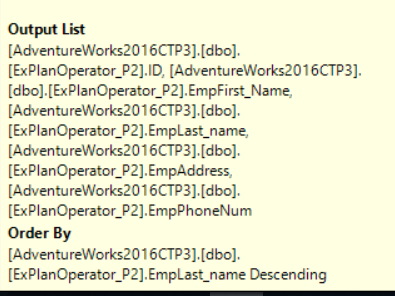
The SORT operator is an expensive operator as you can see from the SQL Server execution plan. Where the cost of the SORT operator in our case is 78% of the overall query cost. This cost is due to that, the column specified in the ORDER BY clause has no index defined on it on the requested order. So that, you need always to think if this sort operation is really required, if you can live without it, it is better not to use it or create an index to have a sorted copy of this column, eliminating the SORT operator overhead.
Stay tuned for the next article, in which we will discuss the third set of the SQL Server execution plan operators.
Table of contents

He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers - February 11, 2021
- How to monitor Azure Data Factory - January 15, 2021
- Using Source Control in Azure Data Factory - January 12, 2021