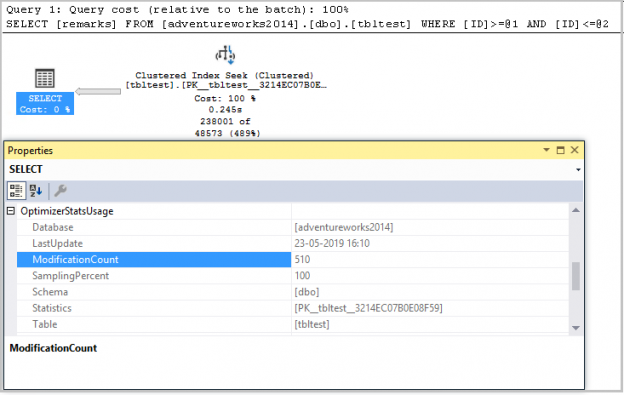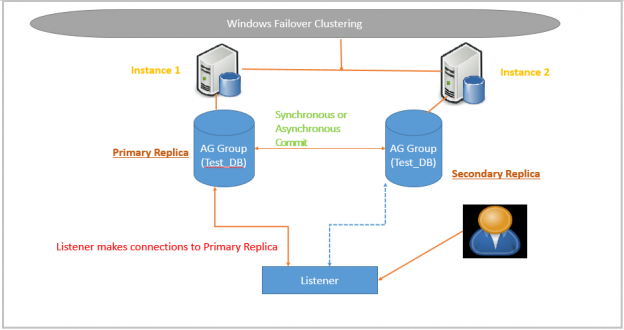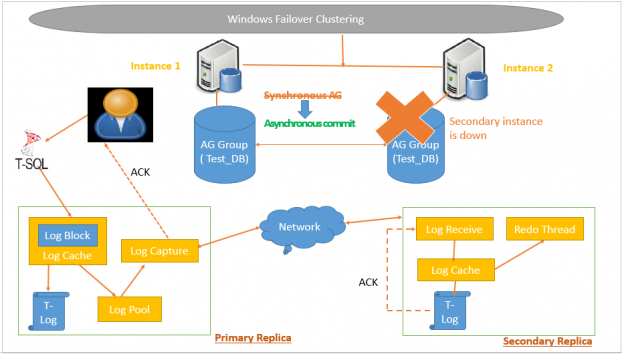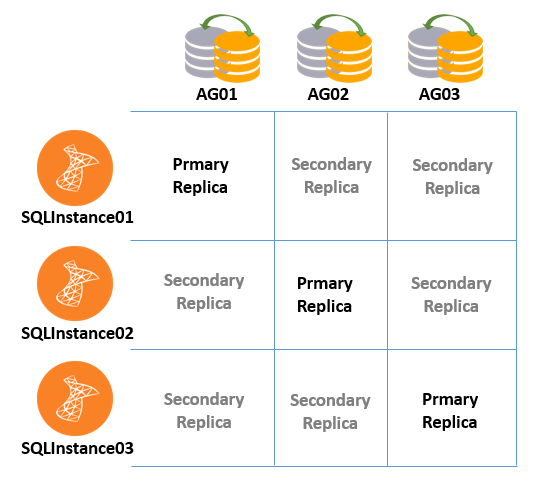
Introduction
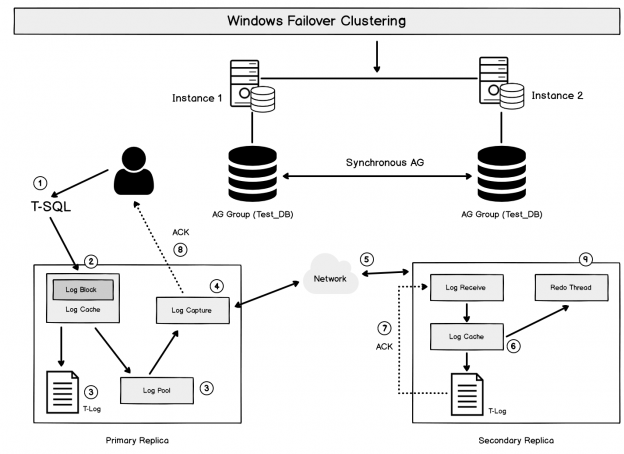
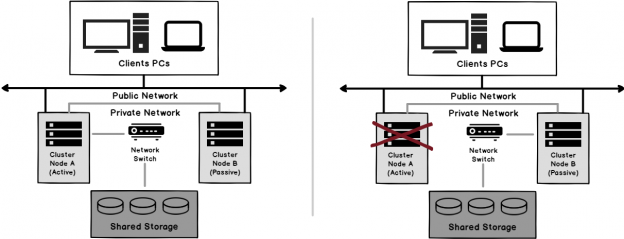
SQL Server Always On Availability Groups provides HADR solutions for the SQL databases. Here HA refers to high availability and DR refers to disaster recovery. The priority of this feature is to keep the database highly available and then provide Disaster recovery. Due to this reason, if the secondary replica goes down in a synchronous data commit mode, SQL Server changes commit mode to Asynchronous so that users can continue run the transactions and a secondary replica can be in sync later once it bought up. SQL Listener also points to the primary replica and continues redirects connection to the primary replica.
Read more »