

SQL Server Always On Availability Groups are an enterprise-level high-availability and disaster-recovery feature introduced the first time in SQL Server 2012as an alternative to database mirroring. A set of user databases that fail over together forms the availability group. These availability databases are hosted by the availability replicas and can be readable- writable at the primary replica and up to eight sets of secondary replica databases that can be configured to be read-only databases. The availability groups fail over due to the availability replica’s level issues and not the ones caused due to database level issues such as data loss or database corruption.
Always On Availability Group replicas can work in two availability modes;Asynchronous-commit mode in which the primary replica will not wait for the secondary replica’s acknowledgement that the log is hardened completely, opposite to Synchronous-commit mode in which the primary replica waits for the secondary replica to acknowledge the log hardening completion, increasing the transaction latency.
An Always On Availability Group is built over Windows Server Failover Clustering (WSFC) including all replicas of the same availability group under the same cluster. An Always On Availability Group differs from database mirroring feature in that there is no witness role in Always On Availability Groups. On the other hand, you can bring the secondary replica databases online for read-only access in Always On Availability Groups in contrast to database mirroring, in which the secondary database is not accessible in restoring mode.
In SQL Server 2012 and 2014, initializing the secondary replica requires taking full and transaction log backups of the primary database to a network share and restore it to the secondary replicas. This operation can be performed manually or automatically via the availability group wizard after configuring the network share and the required permissions on that network share to the account that the SQL Server service runs with. Once the log backup file is restored to the secondary replicas, the data synchronization process, in which all changes applied on the primary replica will be applied to the secondary replica, will start until all replicas become synchronized.
Starting with SQL Server 2016, a new simple initialization method introduced, in which the databases in the secondary replica are initialized automatically by enabling Direct Seeding, reducing the amount of work required by the database administrator to add databases to the secondary replicas. Using direct seeding, you need to add the database to the availability group only, without the need to configure the network share or performing backup or restore operations, reducing the time required to initialize the secondary replica dramatically. Internally, a Microsoft SQL Server Virtual Device Interface (VDI) backup is performed to the secondary replica over the network. Using the direct seeding method, there is no need to create a dummy database before creating the availability group to proceed with the creation process.
A new parameter, SEEDING_MODE, is added to the CREATE and ALTER AVAILABILITY GROUP T-SQL statements to configure and enable the direct seeding per each replica. SEEDING_MODE takes two values; Manual seeding indicating that the old backup and restore secondary initialization method will be used, which is the default seeding method, and Automatic seeding which enables using the new automated secondary initialization method, that is the direct seeding method across the replication network. The SEEDING_MODE option is a replica level configuration, if you have multiple databases in your availability group, this setting will be applied to all databases in the availability group. It is also applicable to use mixed seeding within the availability group, by using automatic seeding for some replicas and use the legacy seeding with backup and restore for the other replicas. Until this moment, configuring the seeding mode to initialize the secondary replica is available using the T-SQL command only and not available via the wizard.
The Direct seeding method is not and technique for initializing the secondary replica if the database is very large, as it doesn’t use compression as a default setting, in contrast to the availability group wizard in which the backup operation can be performed using compression. Fortunately, compression can be enabled in direct seeding to reduce the network traffic while seeding by enabling the Trace Flag 9567 using DBCC TRACEON or as a startup parameter. The side effect for adding a large database using the direct seeding with compression enabled is the high CPU utilization that you will notice during the seeding.
Another thing that we should take into consideration when using the direct seeding method to initialize the secondary replica is that the transaction log of the added databases can’t be truncated during the direct seeding process, which will cause significant transaction log growth in high transactional databases. So, be aware of the workload amount, database size, the log growth rate and the replication distance that affect the seeding time.
A set of extended events introduced in SQL Server 2016 to monitor the direct seeding process both at the primary and secondary replicas such as hadr_physical_seeding_backup_state_change, hadr_physical_seeding_restore_state_change, hadr_physical_seeding_forwarder_state_change, hadr_physical_seeding_failure, hadr_physical_seeding_progress, hadr_automatic_seeding_start, hadr_automatic_seeding_success and hadr_automatic_seeding_timeout valuable events. You can collect the extended events that monitor the backup process from the primary replica and the ones related to the restore process from the secondary replica. As per Microsoft’s advice, you should be careful when collecting the extended events, as some events may impact SQL Server performance.
Direct seeding can be also monitored by querying the two new DMVs that are introduced in SQL Server 2016 both at the primary and secondary replicas to troubleshoot any failure occurred. The first DMV sys.dm_hadr_automatic_seeding is used to view successful or failed database seeding information and the error messages displaying the seeding failure reason. The second DMV sys.dm_hadr_physical_seeding_stats displays statistical information about the currently running and completed seeding.
Let’s start our demo to understand direct seeding practically. As mentioned previously, direct seeding is available only using T-SQL commands. We will create a new availability group with two replicas, without creating a dummy database during the creation process, using CREATE AVAILABILITY GROUP T-SQL command. What is new here is the additional SEEDING_MODE option which we will set it to AUTOMATIC in order to enable the direct seeding. The below script will be executed at the primary replica:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
USE master GO CREATE AVAILABILITY GROUP AG40VS FOR REPLICA ON N'DB41VS' WITH (ENDPOINT_URL = N'TCP:// DB41VS.TestDomain.COM:5022', FAILOVER_MODE = AUTOMATIC, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO), SEEDING_MODE = AUTOMATIC) , N'DB42VS' WITH (ENDPOINT_URL = N'TCP:// DB42VS.TestDomain.COM:5022', FAILOVER_MODE = AUTOMATIC, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO), SEEDING_MODE = AUTOMATIC); GO |
The below snapshot from SQL Server Management Studio shows the created availability group with the two replicas; the primary and the secondary:
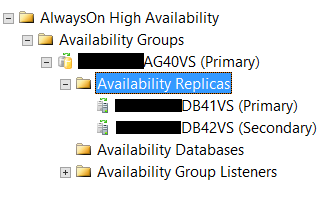
A new field is added to the sys.availability_replicas system table to list the seeding mode for all replicas, that can be joined with sys.availability_groups to include the availability groups information as in the below script:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT AVGrp.name as group_name, AVGRep.replica_server_name as replica_name, AVGRep.endpoint_url, AVGRep.availability_mode_desc, AVGRep.failover_mode_desc, AVGRep.seeding_mode_desc as seeding_mode FROM sys.availability_replicas as AVGRep JOIN sys.availability_groups as AVGrp ON AVGRep.group_id = AVGrp.group_id; |
The following result shows that the seeding mode used in our case is AUTOMATIC seeding mode, which means that we are using the direct seeding method in our demo as configured previously:

Now we will join the secondary replica to the availability group using ALTER AVAILABILITY GROUP statement and grant the availability group access to create database, so it will create the database at the secondary replica directly and seed it automatically once created:
|
1 2 3 4 5 |
ALTER AVAILABILITY GROUP AG40VS JOIN ER AVAILABILITY GROUP AG40VS GRANT CREATE ANY DATABASE; GO |
We will create a testing database at the primary replica to add it later to the availability group:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
CREATE DATABASE [DirectSeedTest] CONTAINMENT = NONE ON PRIMARY ( NAME = N'DirectSeedTest', FILENAME = N'F:\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\DirectSeedTest.mdf' , SIZE = 4096KB , FILEGROWTH = 1024KB ) LOG ON ( NAME = N'DirectSeedTest_log', FILENAME = N'F:\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\DirectSeedTest_log.ldf' , SIZE = 2048KB , FILEGROWTH = 10%) GO |
And take a dummy full backup for that database to meet the Always On Availability Group pre-requisites:
|
1 2 3 4 5 6 |
BACKUP DATABASE [DirectSeedTest] TO DISK = N'F:\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\Backup\DirectSeedTest.bak' WITH NOFORMAT, NOINIT, NAME = N'DirectSeedTest-Full Database Backup', SKIP, NOREWIND, NOUNLOAD, STATS = 10 GO |
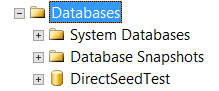
At the primary side, the testing database will be displayed without any addition like any normal user database:
Let’s add the database to the availability group using ALTER AVAILABILITY GROUP T-SQL command below:
|
1 2 3 4 |
ALTER AVAILABILITY GROUP AG40VS ADD DATABASE [DirectSeedTest]; GO |
That’s it!
Now the database will be added to the availability group at the primary replica, the database will be created at the secondary replica and will be seeded directly and automatically without any effort from the database administrator to take full or transactional log backup to synchronize the two replicas. If we check the primary replica, the database will be synchronized as in the following image:
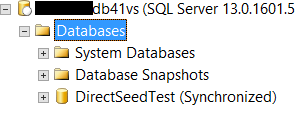
The one-line command to add the database to the availability group will synchronize it at the secondary replica too as below:
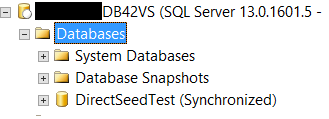
As mentioned previously, two new DMVs were introduced in SQL Server 2016 to monitor the direct seeding method. Querying the sys.dm_hadr_automatic_seeding DMV:
|
1 2 3 4 |
select start_time ,completion_time , current_state ,performed_seeding , failure_state_desc,error_code , number_of_attempts from sys.dm_hadr_automatic_seeding |
the result will show us all successful and failed database seeding information with clear error messages displaying the seeding failure reason:

Also we can use the sys.dm_hadr_physical_seeding_stats DMV:
|
1 2 3 4 5 6 |
select local_database_name , remote_machine_name,role_desc ,internal_state_desc ,transfer_rate_bytes_per_second ,transferred_size_bytes ,database_size_bytes,estimate_time_complete_utc ,failure_message ,failure_time_utc, is_compression_enabled from sys.dm_hadr_physical_seeding_stats |
To show the statistical information about the running seeding processes in addition to the completed ones as below:

The SQL Server error logs can be used also to trace and troubleshoot the direct seeding process. You need to check the backup process logs at the primary replica:

And the restore process logs at the secondary replica:

It is clear from the previous logs that the direct seeding process is completed successfully; started at 12:34:53 and finished at 12:34:57, taking 4 seconds to seed the secondary replica completely.
Conclusion
SQL Server 2016 introduced many new features and enhancements that make it the fastest SQL Server version to date. One of these enhancements is the Always On Availability Groups direct seeding option, that eases the secondary initialization and seeding process saving time and effort. Rather than taking full and transaction log backups to initialize and synchronize the secondary replica, just set the seeding mode to automatic and add the database to the availability group at the primary replica, it will be created and synchronized at the secondary replica directly without any extra effort. Direct seeding does not work well with huge databases due to the fact that the compression option is disabled by default in the direct seeding. If you can tolerate the high CPU utilization, you can enable it. Direct seeding also blocks the log truncation during the seeding process, that may fill the log file of the database with huge number of transactions. Like any new feature, test it in your development environment before using it at the production environment.

He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers - February 11, 2021
- How to monitor Azure Data Factory - January 15, 2021
- Using Source Control in Azure Data Factory - January 12, 2021