

In this article, we will explore configuring Read Scale Availability Group that does not require a failover clustering configuration. It helps to scale read-only connections to the secondary replica in a cluster less configuration.
Introduction
SQL Server Always On is a high availability and disaster recovery solution available starting from SQL Server 2012. It requires two or more replica servers configured in Windows Server Failover Cluster. Suppose we have a three replica node SQL Always On. In this case, each SQL Server should be a part of a failover cluster. SQL Server Always on Availability Groups uses failover clustering to determine the role of an available replica and determine the failover conditions. Each availability group is a resource in the failover cluster, and it continuously monitors the health of the primary replica.
Recently I came up with a scenario in which a client wants to use SQL Server Always on the feature but do not want to use failover clustering between replicas. It raises a question to me –
Can we configure Clusterless Availability group in SQL Server?
Let’s consider it is possible to create a clusterless availability group replica for SQL Server. Client further requires to redirect all read-only connections coming to primary replica to the secondary replica. It again raises a few questions. We might need multiple secondary replicas without failover clusters. Our motive is to offload the load from the secondary read-only replica as well.
- Can we redirect read-only connections to Secondary replica in a clusterless availability group configuration?
- Can we configure multiple replicas for reporting purpose in a clusterless availability group configuration?
- Can we configure Read Scale Availability Group?
SQL Server failover clustering increases the complexity to deploy and sometimes we do not want to configure it. For example, suppose we have a system in the demilitarized zone (DMZ) for reporting purpose. We do not want to configure failover clustering as it involves opening multiple ports between networks.
In SQL Server we can configure Read-Scale availability group which do not need failover clustering between servers. The point to consider is that it is not useful for high availability solution. We can use it to scale out a read-only workload.
Read-Scale availability group in a Clusterless Availability Group
In SQL Server 2017 we can configure clusterless Availability Group in SQL Server without failover cluster configuration on participating replicas. It can be done on both Windows as well as Linux based SQL Servers.
Suppose we have two standalone SQL Instances SQLA and SQLB. We want to configure Read Scale availability group in between these standalone SQL instances. We further want to redirect all read transactions on the secondary replica.

Steps to configure Read-Scale availability groups in a clusterless availability group configuration
Step 1: We need to enable SQL Always On feature on both standalone SQL instances. To do so, RDP to each server and Open SQL Server Configuration Manager. In this go to SQL Server instance properties and Enable Always On Availability Groups.
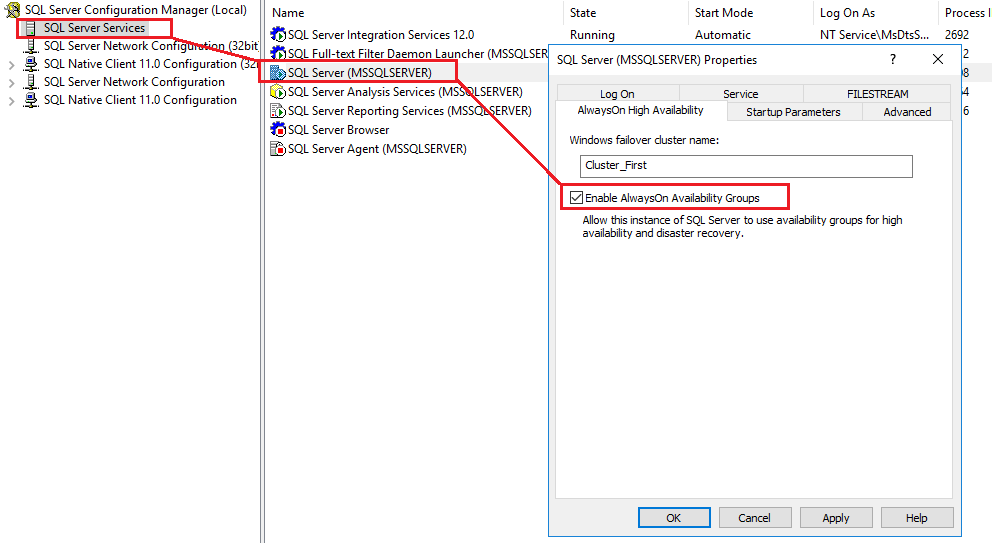
We do not have a failover cluster between SQLA and SQLB instances. In the screenshot also, you can see that it asks for Windows failover cluster name. We can enable it in SQL Server 2017 or above without failover cluster. SQL Server takes SQL instance name by default in this clusterless availability group replica for Read Scale Availability Group.
Step 2: In this step, we need to configure SQL Server Availability Groups between both instances. Connect to the instance which will work as a Primary replica.
- Note: I am using SSMS v18 in this article. You should use the latest SSMS version else you might not get all options in GUI mode.
Go to Always On High Availability and click on New Availability Group Wizard.
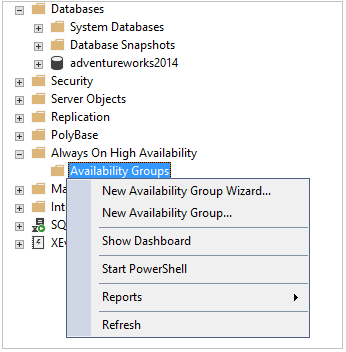
It launches a wizard to configure the availability group.
- Availability group name: Specify a suitable name for the availability group
-
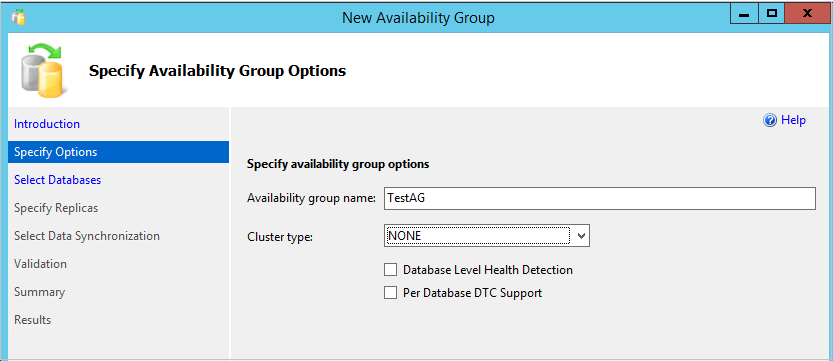
Cluster type: It provides a drop-down option to choose appropriate values
- Windows Server Failover Cluster: Choose this value if SQL instances (replicas) are in a failover cluster configuration
- External: if we use external cluster topology for SQL instances, we need to select this value. Example: Linux
None: If SQL instances are not configured in a failover cluster and we need to configure Read Scale Availability Group, select the cluster type as NONE

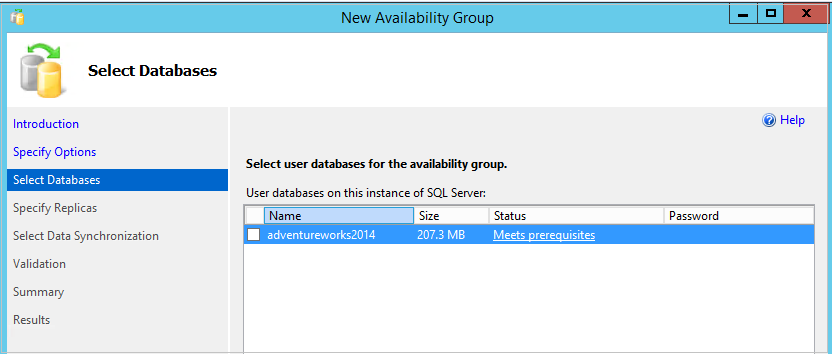
In the next page, we need to select a database for the Read Scale Availability Group. It should meet following pre-requisites.
- It should be a user database in read-write mode
- It should be in full recovery model
- We should have taken at least one full backup
- It should not be configured with Auto_close option
If database meets prerequisites, we get status Meets prerequisites.
Step 3: In the next page, we specify the following things for Read Scale Availability Group.
- Availability Replicas: Specify all available replicas we want to add in an availability group
- Initial Role: Specify the initial role (primary or secondary) on each replica. We can have only one primary replica
- Failover Mode: We can have only Manual failover mode for Read Scale Availability Group
- Availability Mode: Select the data synchronization mode between both replicas. We can choose either Synchronous or Asynchronous data commit availability mode
Readable Secondary: In the secondary role of a replica, we can allow all connections for read access with Readable Secondary- Yes
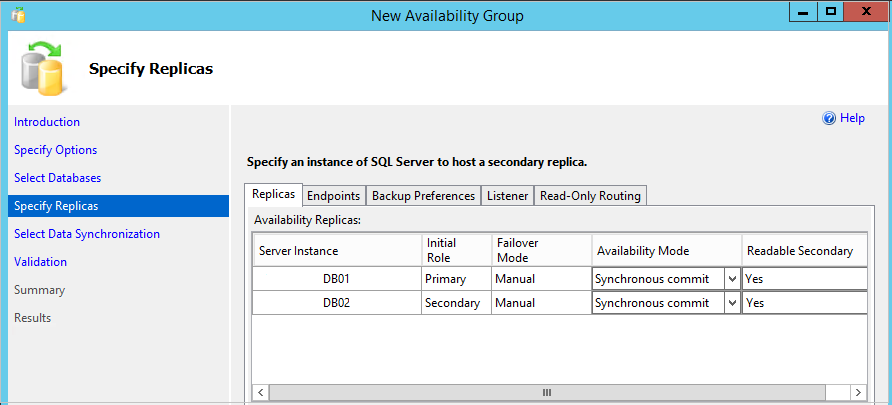
SQL Server automatically creates the Endpoints for both replicas automatically using this wizard. The default format for endpoints is TCP://[SQL Instance Name]: Port.
- Note: SQL Server services should be running with a service account. This service account acts as an Endpoint owner also.
We will skip other options as of now. We need to configure them in the later part of this article.
Step 4: In the next step, we configure initial data synchronization for Read Scale Availability Group. We will choose Automatic Seeding in Read Scale Availability Group. In this SQL Server automatically creates a database on secondary replica and sync it with the primary replica. You should have similar database drives (default path) on both instances. You can read more about automatic seeding in SQL Server 2016 Always On Availability Group with Direct Seeding article.

Step 5: It performs certain validation checks such as free disk space on the secondary replica, the existence of a secondary database, compatibility of database file locations. If there are any errors, we need to fix them before we move on.
In the following screenshot, we have a warning for SQL listener configuration because we have not created it yet. We can proceed with this warning at this point for Read Scale Availability Group.

In the last step, we can review the configuration and click on finish to start setting up read- scale availability groups. We can also generate scripts to review. Let’s generate script and see the action with the t-SQL.
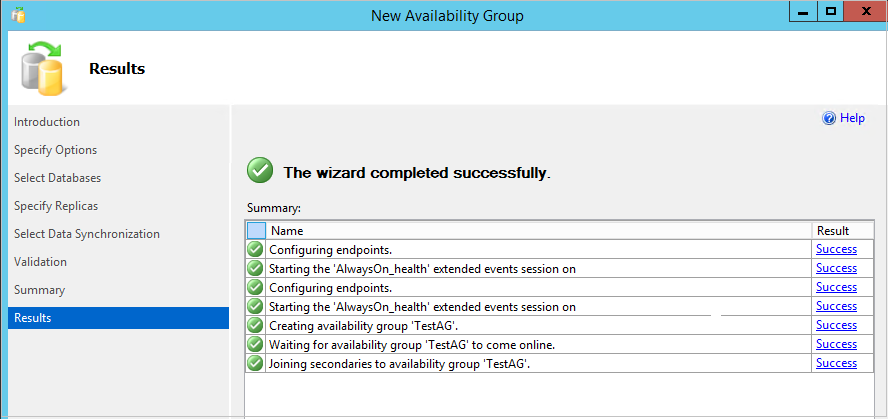
Now you can open right click on availability group and view dashboard to look database synchronization in a read-scale availability group. We can check synchronization status using the following query on primary replica also.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
SELECT ar.replica_server_name, adc.database_name, ag.name AS ag_name, drs.is_local, drs.is_primary_replica, drs.synchronization_state_desc, drs.is_commit_participant, drs.synchronization_health_desc, drs.recovery_lsn, drs.truncation_lsn FROM sys.dm_hadr_database_replica_states AS drs INNER JOIN sys.availability_databases_cluster AS adc ON drs.group_id = adc.group_id AND drs.group_database_id = adc.group_database_id INNER JOIN sys.availability_groups AS ag ON ag.group_id = drs.group_id INNER JOIN sys.availability_replicas AS ar ON drs.group_id = ar.group_id AND drs.replica_id = ar.replica_id ORDER BY ag.name, ar.replica_server_name, adc.database_name; |
We can see that both the replicas in Read Scale Availability Group are synchronized and healthy.

As of now, we have created Read Scale Availability groups in a clusterless configuration. In this cluster less availability group, we cannot have automatic or planned manual failover. If we try to do failover using failover wizard (right click on primary replica and failover), we get the following error message.

We need to initiate force failover with allow data loss in a clusterless availability group. We might have data loss in this depending upon the lag between the primary and secondary replica.
To initiate forced failover in a Read Scale Availability Group, connect to secondary replica and execute the following command.
|
1 |
ALTER AVAILABILITY GROUP TestAG FORCE_FAILOVER_ALLOW_DATA_LOSS; |
It does the force failover from a primary replica to secondary replica with possible data loss. Execute the command to check synchronization on the primary replica, and we can see the status as Not Synchronizing.

Once failover is done for clusterless availability group, connect to the secondary replica and expand Availability Databases.
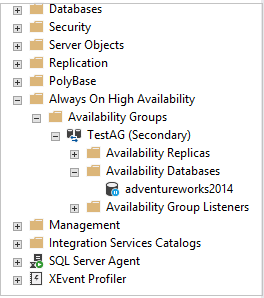
Right click on the availability database and Resume Data Movement to synchronized data again between both replicas in a clusterless availability group.
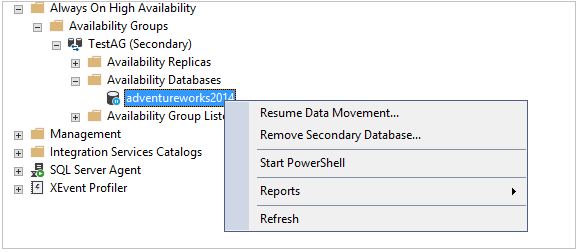
It opens Resume Data Movement wizard. Click on Continue executing after error and Ok.
Rerun the query and we can see the status is Synchronized again.

Read-Only Routing in Clusterless Availability Group
In the article, How to Configure Read-Only Routing for an Availability Group in SQL Server 2016, we explored configuring Read-only routing for an availability group having a failover clustering. In the previous section, we configured cluster less Always On Availability Groups.
We need to have a SQL Listener to create the Read-Only Routing list. Usually, we require a cluster resource name to configure a SQL Listener. It creates a computer object in the active directory holding an IP address of replicas.
We can still configure a SQL Listener in a clusterless availability group. We need to use the following things in SQL Listener configuration.
- IP Address of primary replica
- Port number of the primary replica
Here is a catch. In an availability Group, SQL Listener contains the IP address and port number of the primary replica. If we do a force failover, we need to drop and create the SQL listener to have an IP address and port of the new primary replica. We might also need to register SQL Listener again in the DNS to point out the correct IP address.
Execute the command on the primary replica to configure SQL Listener with IP address and port of primary replica in Read-Scale Availability Group.
|
1 2 3 4 5 6 7 8 9 |
USE [master] GO ALTER AVAILABILITY GROUP [TestAG] ADD LISTENER N'ClusterLessAG' ( WITH IP ((N'10.xxx.xxx.xx', N'255.255.255.0') ) , PORT=1433); GO |
Configure Read-Only Routing to the secondary replica in Read Scale Availability Group
We need to configure Read-Only Routing URL and Routing List for redirecting read-only connections to the secondary replica in a clusterless Read Scale Availability Group. We can use Alter Availability Group command in this case.
In the following queries, you can notice the following things.
For a replica with a secondary role in Read-Scale Availability Group, it’s Read-Only Routing URL pointing to the same instance. We need to note here that the port in the routing URL is the port for SQL Services. You can verify that from the SQL Server configuration manager and TCP\IP properties. Do not put endpoint port number in this else you get following error message
- For a replica with a primary role, it’s Read-Only Routing URL pointing to secondary replica instance for Read Scale Availability Group

Execute the following command on Primary replica.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
Alter Availability Group [TestAG] Modify Replica On ‘DB01’ with(Secondary_Role(Read_Only_Routing_URL=N'TCP://DB01.Domain1.com:1433')) Alter Availability Group [TestAG]] Modify Replica On ‘DB01’ with(Secondary_Role(Read_Only_Routing_URL=N' N'TCP://DB02.Domain1.com:1433')) Alter Availability Group [TestAG]] Modify Replica On ‘DB01’ with(Primary_Role(Read_Only_Routing_List=(N'DB02'))) Alter Availability Group [TestAG]] Modify Replica On 'DB02' with(Primary_Role(Read_Only_Routing_List=(N'DB01'))) |
You can execute the following query to get a list of a replica (Primary, secondary), Read-only Replica and Routing URL.
|
1 2 3 4 5 6 7 8 9 |
SELECT AVGSrc.replica_server_name AS SourceReplica , AVGRepl.replica_server_name AS ReadOnlyReplica , AVGRepl.read_only_routing_url AS RoutingURL , AVGRL.routing_priority AS RoutingPriority FROM sys.availability_read_only_routing_lists AVGRL INNER JOIN sys.availability_replicas AVGSrc ON AVGRL.replica_id = AVGSrc.replica_id INNER JOIN sys.availability_replicas AVGRepl ON AVGRL.read_only_replica_id = AVGRepl.replica_id INNER JOIN sys.availability_groups AV ON AV.group_id = AVGSrc.group_id ORDER BY SourceReplica |
In the following query, you can see that for source replica DB01 (Primary replica) routes all DB connections to secondary replica DB02 using RoutingURL.
SourceReplica | ReadOnlyReplica | RoutingURL | RoutingPriority |
DB01 | DB02 | TCP://DB02.indigo.in:1433 | 1 |
DB02 | DB01 | TCP://DB01.indigo.in:1433 | 1 |
Let’s verify the connection redirection in read scale clusterless availability group. In this case, we cannot use SQL Listener to connect with the primary replica. We need to use the primary replica instance name to connect.
Open the command prompt and execute the following command to connect SQL Server with SQLCMD using windows authentication and Read-only mode.
|
1 |
>sqlcmd -S DB01,1433 -E -d adventureworks2014 -K Read-only |
Run the query Select @@Servername, and it returns the secondary server name because the connection redirects to the secondary replica.

Conclusion
In this article, we explored the configuration of Read Scale Availability Group on clusterless availability group. It is a useful enhancement available from SQL Server 2017 onwards. You should explore this scenario in your environment. If you had comments or questions, feel free to leave them in the comments below.

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023