
This article describes the data synchronization process on SQL Server Always On Availability Groups in both Synchronous, and Asynchronous data commit mode.
High data availability is an important aspect of every DBA’s life. We need to minimize and mitigate the issues related to database unavailability.
In the production environment, we want to achieve RPO (Maximum allowed downtime) and RTO (Maximum acceptable data loss) goals of a production database service. Data should be available to business round the clock to avoid any business loss.
In the following table, we can get a glimpse of the maximum allowed downtime based on availability percentage. We get a very strict maximum of downtime per year as we move towards a strict availability percentage.
Availability percentage | Maximum downtime per year |
99% | 3.65 Days |
99.9% | 8.77 Hours |
99.99% | 52.60 Minutes |
99.999% | 5.26 Minutes |
99.9999% | 31.56 seconds |
99.99999% | 3.16 seconds |
99.999999% | 315.58 Milliseconds |
In SQL Server, we can achieve high availability using SQL Server Always On Availability Groups feature. Let’s get a quick overview of SQL Server Always on Availability Groups before we go in deeper.
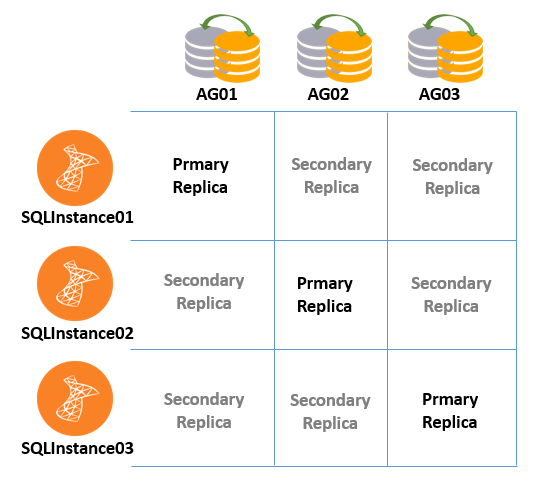
In the following screenshot, we have three SQL instances participating in SQL Server Always On.
We can have a Primary instance and multiple secondary instances (depending upon SQL Version and Edition).
Few important terms of SQL Server Always on Availability Groups are as follows.
- Availability group: It is a logical group of user databases that should failover together on the secondary replica
- Replica: Each availability group should contain two or more participating instance. Each participating instance is known as Replica in SQL Server Always On
- Primary Replica: It hosts the primary database and available for all users for read-write connections
- Secondary Replica: It hosts a copy of a database from the primary replica. It works as a failover target in case of any issues with the primary replica
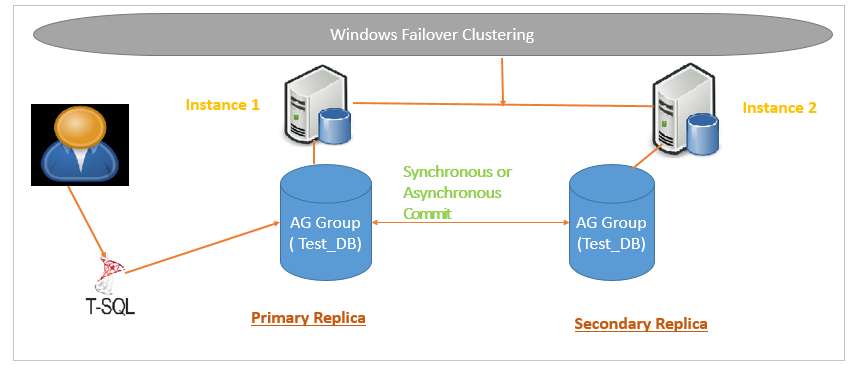
In the SQL Server Always On, Primary replica sends transaction log to secondary databases for all databases defined in the availability group.
We can have two types of data commit modes.
- Asynchronous-commit mode: In this mode, Primary replica sends the transaction log blocks to a secondary replica, but it does not wait for the acknowledgement for transaction commit. It is suitable for disaster recovery solutions
- Synchronous-commit mode: In synchronous-commit mode, the primary replica waits for the transaction commit from a secondary replica. Once it receives the confirmation, SQL Server confirms to the client
In the following screenshot, we can see an overview of two node SQL Server Always On Availability groups
We might be interested to know the internals of SQL Server Always On. In the next section, let’s see how actually data synchronization happens in both Synchronous and Asynchronous data commit mode.
Data Synchronization in Synchronous data commit mode
In the following image, we can see the overall working of data synchronization in Synchronous commit.
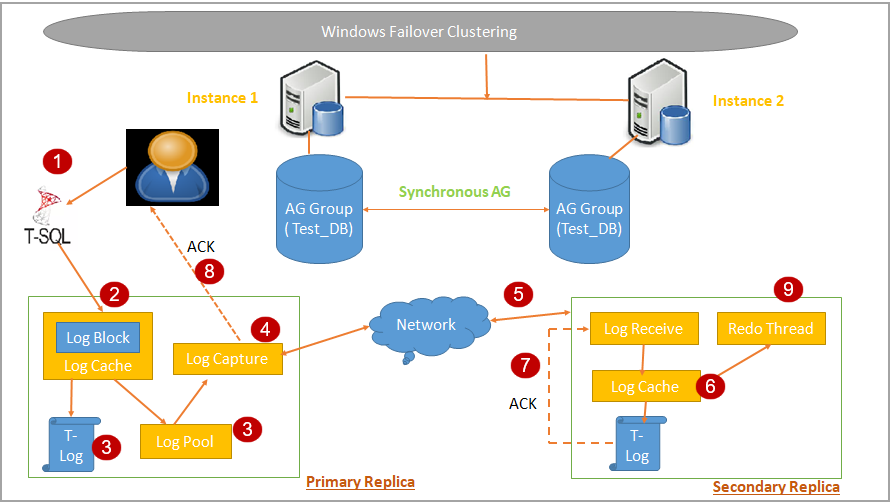
Let’s go through in detail with each step on the above diagram.
- A client connects to the primary replica (either using a listener or SQL instance name) and issues a DML transaction
- In Primary replica, transaction log block is generated. These transaction log records get stored in the log cache of the primary replica
- SQL Server regular performs an automatic checkpoint. It flushes log data into the disk for a primary replica. At the same time, it also copies the log records to Log Pool
-
In this step, a thread Log capture reads Log pool data. The Log Capture process continuously scans the logs from the Log Capture and sends to each secondary replica. If we have multiple secondary replicas, we have individual threads for each replica, and its responsibility is to send a log block for the corresponding replica
Note: SQL Server encrypts log records before sending it to secondary replicas.
- In the secondary replica, Log Receive gets the log records from the primary replica and writes to Log cache. This process is repeated on each secondary replica participating in synchronous-commit mode
- On each secondary replica, Redo thread exists, and it writes all changes mentioned in log records to the data page and index page. It flushes the log for hardening on secondary database log
- As stated earlier, in synchronous data commit, primary replica waits for the acknowledgement from the secondary replica. At this stage, secondary replica sends an acknowledgement that transaction hardening is completed on secondary
- Once Primary replica, receives an acknowledgement from the secondary replica, it sends the transaction completion message to the client
- The secondary replica also contains a redo thread, and it is independent of the log block process in SQL Server Always on. Redo threads reads the logs from log cache. There might be a delay in processing by redo thread and log records might not be available in log cache because it is already hardened to disk. In this case, redo thread read log blocks from the log disk
Data Synchronization in Asynchronous data commit mode
We can understand data synchronization in Asynchronous data commits mode with the following image.
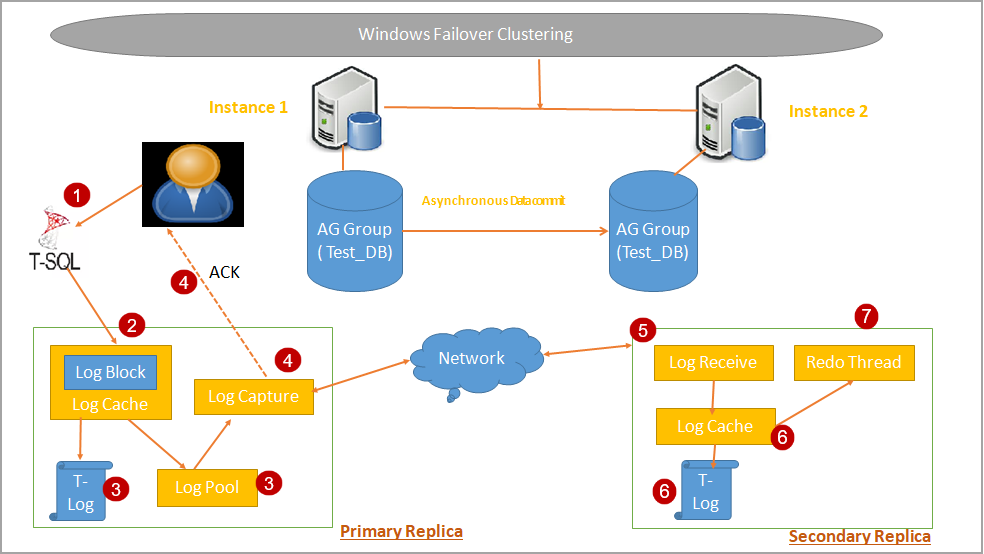
- A client connects to the primary replica (either using a listener or SQL instance name) and issues a DML transaction
- In Primary replica, transaction log block is generated. These transaction log records get stored in the log cache of the primary replica
- SQL Server regular performs an automatic checkpoint. It flushes log data into the disk for a primary replica. At the same time, it also copies the log records to Log Pool
- In Asynchronous data commit mode, the primary replica does not wait for the acknowledgement from participating secondary replica. It sends the acknowledgement to the client for transaction commit
- In the secondary replica, Log Receive gets the log records from the primary replica and writes to Log cache. This process is repeated on each secondary replica participating in asynchronous-commit mode
- On each secondary replica, Redo thread exists, and it writes all changes mentioned in log records to the data page and index page. It flushes the log for hardening on secondary database log
- The secondary replica also contains a redo thread, and it is independent of the log block process in SQL Always On. Redo threads reads the logs from log cache. There might be a delay in processing by redo thread and log records might not be available in log cache because it is already hardened to disk. In this case, redo thread read log blocks from the log disk
Synchronized AlwaysON with Secondary replica down
Suppose we have two synchronous node data commit AlwaysOn in our environment. As stated earlier, Primary replica waits for the acknowledgement from Secondary replica and then only sends an acknowledgement. If Secondary AG instance is down, SQL Server will not be able to deliver transaction log records to the secondary replica.
Think about it. We can get a few questions such as following.
- What will be the transaction behavior in this case?
- Do users get transaction commit message?
We can view this scenario in the following screenshot.
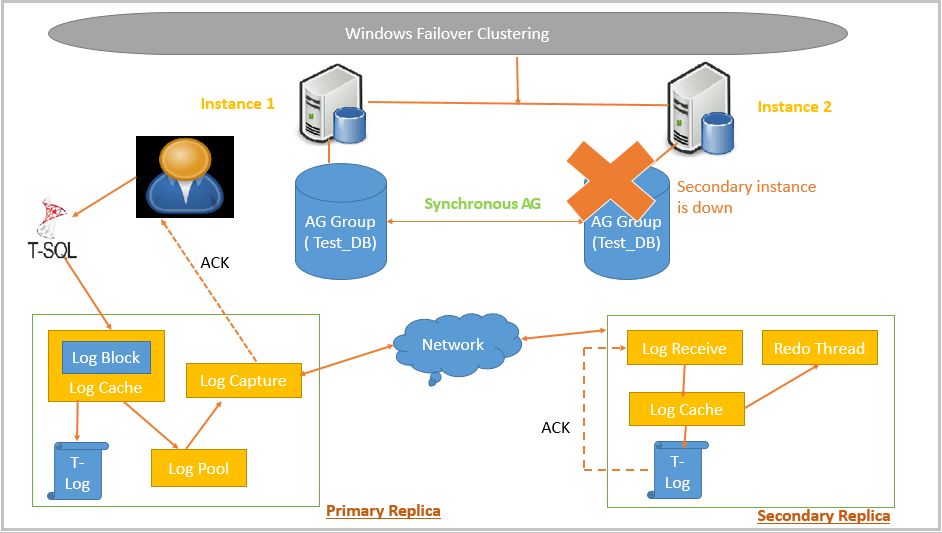
In SQL Server Availability groups checks the status of each replica based on a parameter Session-Timeout. By default, its value is 10 seconds. It shows that the Primary replica waits for 10 seconds for a ping response. If it does not receive any response from the secondary replica, SQL Server change Synchronous data commit to Asynchronous data commits as a temporary measure. Due to this change, users will not face any issues while executing DML. Users will receive commit acknowledgement as soon as it gets committed in Primary replica.
In the following screenshot, you can see this scenario.
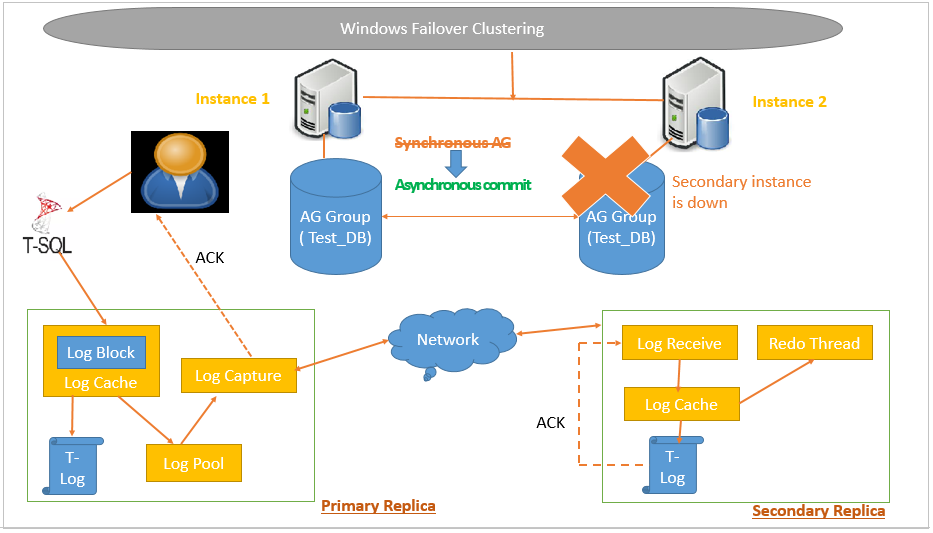
Once the secondary replica is available and connects with the Primary replica, it again starts Synchronous data commit. SQL Server maintains the log entries until the time secondary replica becomes available. Once it reconnects with Secondary replica, it sends all log blocks as per the usual process. It increases the transaction log size in Primary replica until the secondary replica is unavailable.
If you remove the Secondary database from the availability group, SQL Server does not hold any transaction log records. If it takes longer to fix issues with the secondary replica, it is good to remove the replica from the availability group.
Conclusion
In this article, we explored the internals of data synchronization for AlwaysOn availability groups. It will help to understand the end-to-end data flow. We will cover more on SQL Server Always on Availability Groups in upcoming articles.

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023