
This article is a continuation of a guide where we are checking all the available backup preferences for a database contained in an Availability Group.
Following the analysis, we are studying the behaviour of the option “Secondary Only”. After testing a manual backup, while this option is set, the BACKUP DATABASE command ran with success, and the backup was made even being performed from the Primary replica, which is totally against the description of the option, which states that the backup MUST be made in the Secondary replica ONLY!
Let’s try to understand the reason behind this…
Checking the maintenance plan, created before (see part 1), I generated the backup code from the Backup Database task. This is the result:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
DECLARE @preferredReplica INT SET @preferredReplica = (SELECT [master].sys.Fn_hadr_backup_is_preferred_replica('AdventureWorks2016')) IF ( @preferredReplica = 1 ) BEGIN BACKUP DATABASE [AdventureWorks2016] TO DISK = N'E:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\Backup\AdventureWorks2016_backup_2015_11_23_200104_2781259.bak' WITH copy_only, noformat, noinit, NAME = N'AdventureWorks2016_backup_2015_11_23_200104_2781259', skip, rewind, nounload, stats = 10 END |
As you can see, this is exactly the same of the option “Prefer Secondary”. Knowing this, what is the real difference between “Prefer Secondary” and the “Secondary Only” option? The difference is in the availability.
Basically, on the “Prefer Secondary” option, if all the secondary replicas become offline, the backup will in the primary. In other hands, on the “Secondary Only” option, on the same situation, the backup would never run in the Primary replica. This would simply fail. So let’s test it.
In my lab, I have an Availability Group with two replicas, configured with the backup option “Secondary Only”. Using the generated code (above) I’ll try to execute the backup from the Primary replica, let’s see what is going to happen:
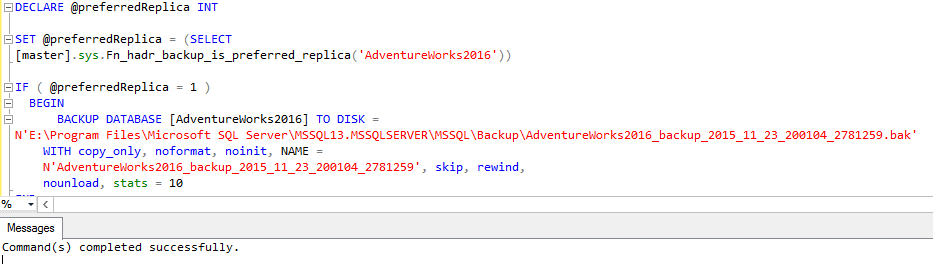
Well, the execution completed successfully… But the backup was not made (which makes sense…)!
Now I’m going to take the secondary instance offline and test the backup:

This was the result:
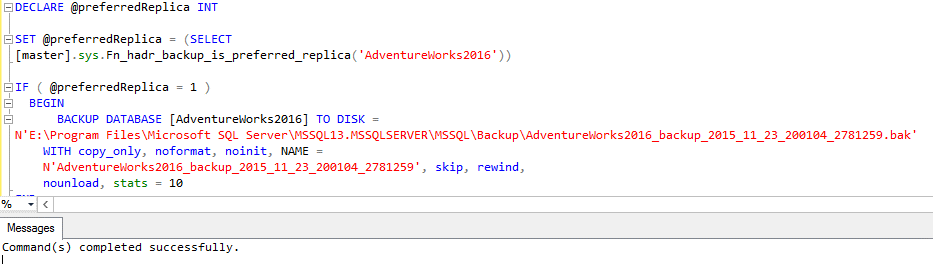
The result was exactly the same! In summary: Even with the primary offline, the backup won’t run. What’s the utility for this? Pretend that you have a very performance sensible database, and you just can’t run the backups from the primary replica, in order to avoid an extra load. This is the way to go.
Keep in mind that we are using the “smartly generated” code from the SQL Server Maintenance Plan. With the IF clause controlling the access to the BACKUP DATABASE command. What if we try to execute the backup directly, in the same conditions as before (only the primary is online):
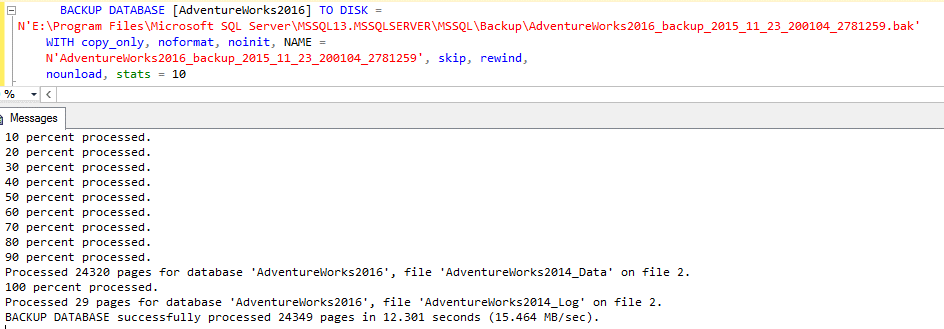
The BACKUP DATABASE command will succeed! One more prove that the “Backup Options” are nothing more than conceptual choices.
You should be wondering what happens if you do the same test using the option “Prefer Secondary”. Let’s check it out!
First test:
- Backup option “Prefer Secondary”
- Both Primary and Secondary replicas are online
- Using the “smart” code, generated by SQL Server Mantenance Plan.
Result:
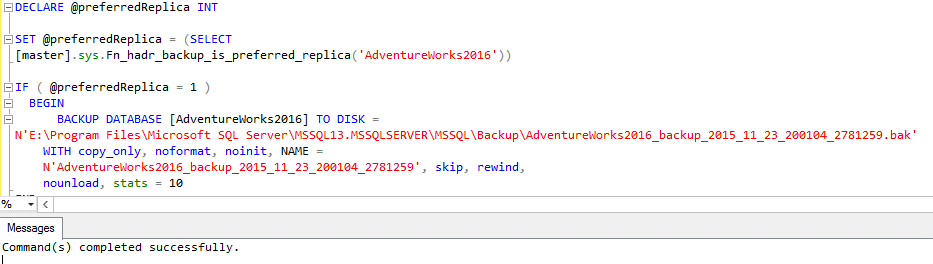
Here you go… Same thing again! The code run successfully, but the BACKUP DATABASE command was ignored!
Second test:
- Backup option “Prefer Secondary”
- Only the Primary replica is online
- Using the “smart” code, generated by SQL Server Maintenance Plan.
Result:
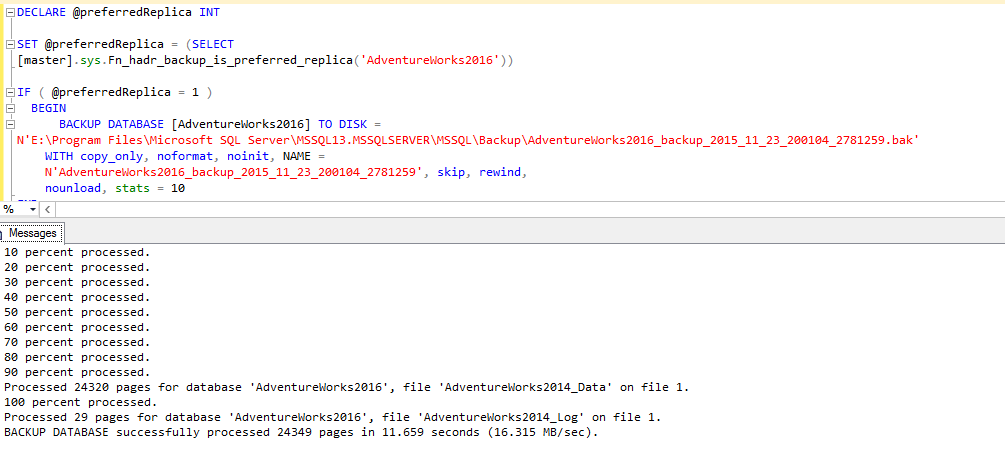
Now we are talking!! The command run with success and the backup was executed.
Based on the tests that we’ve just made, we can conclude the following:
Secondary Only (using the condition):
- The backup command will run always in the secondary, with no exceptions!
- Even if the Primary is the only online replica, the backup will be ignored.
Prefer Secondary (using the condition):
- The backup command will run always in the secondary, unless all the secondary replicas are offline. I this case, it will success in the Primary.
In both cases, if you issue the BACKUP DATABASE command directly, the backup will be started normally.
Now that both of the “Secondary backup” options were demystified, it is time to check the other two remaining options…
Primary
As it says, all the backups will be forced to run on the Primary replica. So let’s test it….
From the primary, I’m going to run the following BACKUP DATABASE command:
|
1 2 3 4 5 6 7 |
BACKUP DATABASE [AdventureWorks2016] TO DISK = N'E:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\Backup\AdventureWorks2016_backup_2015_11_23_200104_2781259.bak' WITH copy_only, noformat, noinit, NAME = N'AdventureWorks2016_backup_2015_11_23_200104_2781259', skip, rewind, nounload, stats = 10 |
Notice that I’m not using the IF condition. The backup ran with success:
10 percent processed.
20 percent processed.
30 percent processed.
40 percent processed.
50 percent processed.
60 percent processed.
70 percent processed.
80 percent processed.
90 percent processed.
Processed 24320 pages for database ‘AdventureWorks2016’, file ‘AdventureWorks2014_Data’ on file 3.
100 percent processed.
Processed 29 pages for database ‘AdventureWorks2016’, file ‘AdventureWorks2014_Log’ on file 3.
BACKUP DATABASE successfully processed 24349 pages in 11.484 seconds (16.564 MB/sec).
By running the same command, but from the secondary, it also runs without issues:
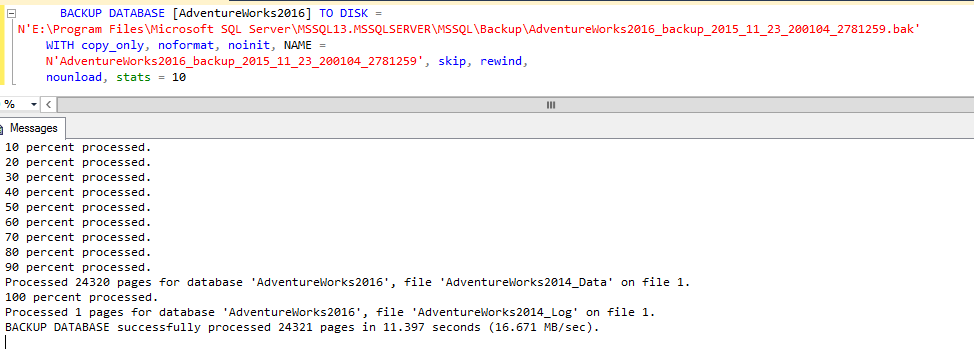
Now, let’s use the code generated by te SQL Server Maintenance Plan’s Backup task, first on the primary:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
DECLARE @preferredReplica INT SET @preferredReplica = (SELECT [master].sys.Fn_hadr_backup_is_preferred_replica('AdventureWorks2016')) IF ( @preferredReplica = 1 ) BEGIN BACKUP DATABASE [AdventureWorks2016] TO DISK = N'E:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\Backup\AdventureWorks2016_backup_2015_11_23_200104_2781259.bak' WITH copy_only, noformat, noinit, NAME = N'AdventureWorks2016_backup_2015_11_23_200104_2781259', skip, rewind, nounload, stats = 10 END |
The output confirms the expected success.
Now, the same code on the secondary:
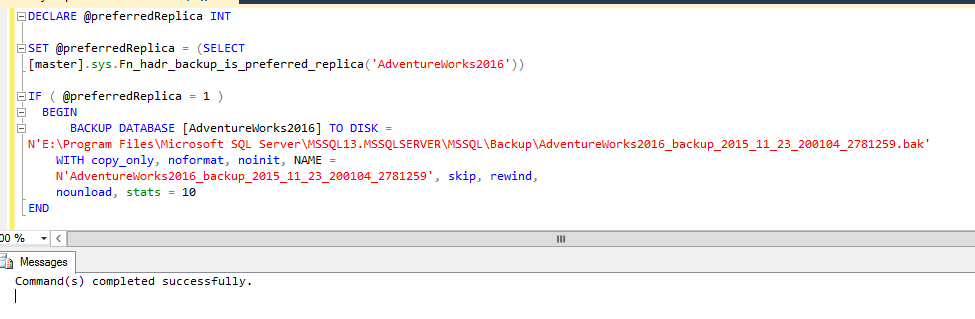
The command ran with success, but the backup didn’t run, as expected.
We already tested the behaviour of the Primary option, where we can set the backup to run only on the primary replica. As the other two options, this will be controlled, only if you use the IF clause, by calling the sys.Fn_hadr_backup_is_preferred_replica() function.
In this option, we don’t have a scenario where the Primary is offline, as we will always need a Primary replica to be running in order to keep the Availability Group working properly, differently from the secondary replicas.
Any Replica
We’ve reached the last available option, the “Any Replica” one. As the other options, the implementation of this one is not just dene it and click on the “Ok” button. In this case, this is a little bit more complex…
Looking for the name of the option, it might look like a very simple thing. After all, “any replica” mean, all the replicas! But if we stop to think, this would be useless!
The trick here is again on how you will implement the backup strategy. Basically, this option is very flexible, all because of the grid that we have just after the option:

This grid will allow us to be very flexible on how to define the backup strategy. In the case of my lab, I have only two replicas, but with more replicas, the prioritization could be very handy. Basically this is how the “Any Replica” option would work, based on the information of this grid.
One of the columns, the “Exclude Replica”, allow us to exclude replicas to be a backup target, if needed. The other column, ”Backup Priority” allow the referred prioritization between nodes, being 1 the lowest priority and 100 the highest one.
In the screenshot case, we have both replicas with the same weight, what is going to happen? Let’s test!
First of all, I’m going to generate the backup command from the SQL Server maintenance plan, as I did in the other options.
Here is the generated backup code:
|
1 2 3 4 5 6 7 8 9 10 |
DECLARE @preferredReplica int SET @preferredReplica = (SELECT [master].sys.fn_hadr_backup_is_preferred_replica('AdventureWorks2016')) IF (@preferredReplica = 1) BEGIN BACKUP DATABASE [AdventureWorks2016] TO DISK = N'E:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\Backup\AdventureWorks2016_backup_2015_11_24_022752_8151223.bak' WITH COPY_ONLY, NOFORMAT, NOINIT, NAME = N'AdventureWorks2016_backup_2015_11_24_022752_8151223', SKIP, REWIND, NOUNLOAD, STATS = 10 END |
Basically, the code is the same, calling the same function sys.fn_hadr_backup_is_preferred_replica(). So let’s check the behavior of this function, by executing it on both the Primary and the Secondary replicas.
The result was the following:
Server: W2016SRV06
Role: Primary
Weight: 50
Result: Preferred backup replica
Server: W2016SRV07
Role: Secondary
Weight: 50
Result: NON Preferred backup replica
I started to wonder, what was the criteria to choose the server W2016SRV06 to be the preferred backup replica, if the weight was the same for bot replicas, so I tested again the function execution and the result was the same!
Ok, maybe this is happening, because as the weight is the same for all the replicas, the Primary replica has priority by design – NOT!
I performed a failover and the result was:
Server: W2016SRV06
Role: Secondary
Weight: 50
Result: Preferred backup replica
Server: W2016SRV07
Role: Primary
Weight: 50
Result: NON Preferred backup replica
After that weird result and some research, without find a reason, I decided to investigate further, so I found a possible reason for this. Analyzing the code of the function I found the SELECT statement responsible to help the return of the preferred replica, and there’s something interesting there… Here is code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
SELECT Cast(ar.replica_id AS NVARCHAR(36)) AS replica_id, Cast(@ag_resource_id AS NVARCHAR(36)) AS resource_id, CASE ar.replica_server_name WHEN @primary_server_name THEN 1 -- primary ELSE 2 -- secondary END AS role, CASE ar.replica_server_name WHEN @local_server_name THEN 1 ELSE 0 END AS is_local FROM sys.availability_replicas ar WHERE ar.group_id = @ag_id AND ar.backup_priority > 0 AND -- 0 is a flag that backups are never desired on this replica. CONVERT (CHAR(1), (SELECT CASE ar2.replica_server_name WHEN @primary_server_name THEN 1 -- primary ELSE 2 -- secondary END FROM sys.availability_replicas ar2 WHERE ar2.replica_id = ar.replica_id)) LIKE CASE @ag_pref WHEN 0 THEN '1' -- Primary preferred WHEN 1 THEN '2' -- Secondary Only WHEN 2 THEN '2' -- Secondary Preferred WHEN 3 THEN '%' -- No Preference END ORDER BY ar.backup_priority DESC, ar.replica_server_name ASC; |
If you notice, there’s an ORDER BY clause, ordering the list of replicas by the “Backup priority” AND by the “Server Name”. Here is the tricky… The defined database server name will influence in the chosen preferred backup replica.
Summarizing the behavior of the “Backup Priority” setting:
- The replicas with the lower value will be in the end of the queue.
- Those replicas will only be used if no other is available.
- The replicas with the higher priority value will be on the top of the backup replica choice.
- In the case of have two or more replicas with the same priority value (weight) SQL Server will give priority based on the alphabetical order.
As we are all very smart people, we can customize the things, of course! If you think that your environment would follow another way to prioritize the backups, you can create a customized function in order to override the default SQL Server one. The following SELECT statement helps the start of this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
SELECT CASE ags.primary_replica WHEN ar.replica_server_name THEN 'PRIMARY' ELSE 'SECONDARY' END replica_type, ar.replica_server_name, ar.backup_priority, CASE WHEN backup_priority > 0 THEN 'INCLUDED' ELSE 'EXCLUDED' END used_for_backup FROM sys.availability_replicas ar INNER JOIN sys.dm_hadr_availability_group_states ags ON ags.group_id = ar.group_id ORDER BY ar.backup_priority DESC, ar.replica_server_name ASC; |
That statement is following the replica server name way to order, in case of the same priority, but your imagination can guide you! You can customize that query to pick the less loaded server, for example… This is not very easy, but feasible with some tricks 🙂
I hope you liked this article and if you have questions, suggestions or something weird, I’ll be very happy in receive your contact!
See you soon!

With experience working in Portugal, Holland, Germany and United Kingdom, he's always available to learn and share his knowledge, in order to contribute to SQL Server community,
View all posts by Murilo Miranda
- Understanding backups on AlwaysOn Availability Groups – Part 2 - December 3, 2015
- Understanding backups on AlwaysOn Availability Groups – Part 1 - November 30, 2015
- AlwaysOn Availability Groups – Curiosities to make your job easier – Part 4 - October 13, 2015