
Introduction
Importing and exporting CSV files is a common task to DBAs from time to time.
For import, we can use the following methods
- BCP utility
- Bulk Insert
- OpenRowset with the Bulk option
- Writing a CLR stored procedure or using PowerShell
For export, we can use the following methods
- BCP utility
- Writing a CLR stored procedure or using PowerShell
But to do both import and export inside T-SQL, currently, the only way is via a custom CLR stored procedure.
This dilemma is changed since the release of SQL Server 2016, which has R integrated. In this article, we will demonstrate how to use R embedded inside T-SQL to do import / export work.
R Integration in SQL Server 2016
To use R inside SQL Server 2016, we should first install the R Service in-Database. For detailed installation, please see Set up SQL Server R Services (In-Database)
T-SQL integrates R via a new stored procedure: sp_execute_external_script.
The main purpose of R language is for data analysis, especially, in statistics way. However, since any data analysis work naturally needs to deal with external data sources, among which is CSV file, we can use this capability to our advantage.
What is more interesting here is SQL Server R service is installed with an enhanced and tailored for SQL Server 2016 R package RevoScaleR package, which contains some handy functions.
Environment Preparation
Let’s first prepare some real-world CSV files, I recommend to download CSV files from 193,992 datasets found.
We will download the first two dataset CSV files, “College Scorecard” and “Demographic Statistics By Zip Code”, just click the arrow-pointed two links as shown below, and two CSV files will be downloaded.
After downloading the two files, we can move the “Consumer_complain.csv” and “Most-Recent-Cohorts-Scorecard-Elements.csv” to a designated folder. In my case, I created a folder C:\RData and put them there as shown below

These two files are pretty typical in feature, the Demographic_Statistics_By_Zip_Code.csv are all pure numeric values, and another file has big number of columns, 122 columns to be exact.
I will load these two files to my local SQL Server 2016 instance, i.e. [localhost\sql2016] in [TestDB] database.
Data Import / Export Requirements
We will do the following for this import / export requirements:
- Import the two csv files into staging tables in [TestDB]. Input parameter is a csv file name
- Export the staging tables back to a csv file. Input parameters are staging table name and the csv file name
- Import / Export should be done inside T-SQL
Implementation of Import
In most of the data loading work, we will first create staging tables and then start to load. However, with some amazing functions in RevoScaleR package, this staging table creation step can be omitted as the R function will auto create the staging table, it is such a relief when we have to handle a CSV file with 100+ columns.
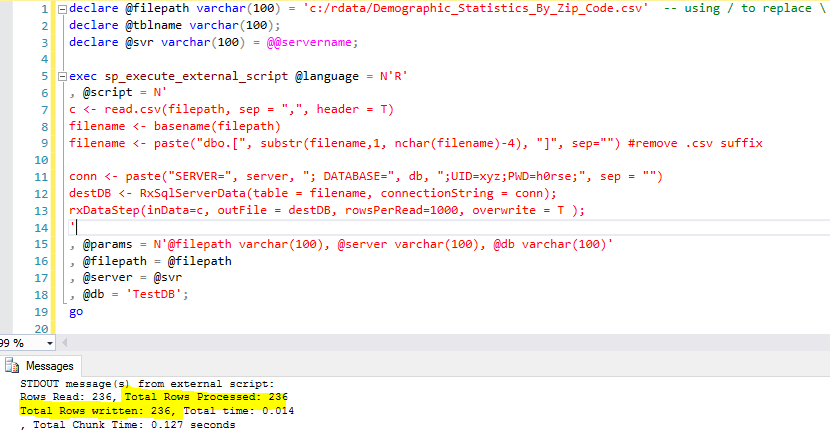
The implementation is straight-forward
- Read csv file with read.csv R function into variable c, which will be the source (line 7)
- From the csv file full path, we extract the file name (without directory and suffix), we will use this file name as the staging table name (line 8, 9)
- Create a sql server connection string
- Create a destination SQL Server data source using RxSQLServerData function (line 12)
- Using RxDataStep function to import the source into the destination (line 13)
- If we want to import a different csv file, we just need to change the first line to assign the proper value to @filepath
One special notd here, line 11 defines a connection string, at this moment, it seems we need a User ID (UID) and Password (PWD) to avoid problems. If we use Trusted_Connection = True, there can be problems. So in this case, I created a login XYZ and assign it as a db_owner user in [TestDB].
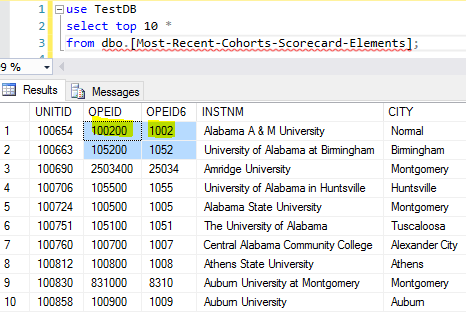
After this done, we can check what the new staging table looks like
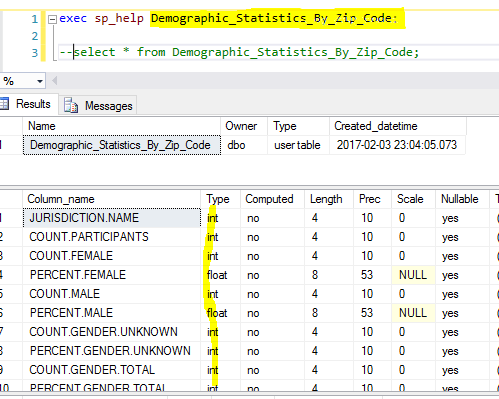
We notice that all columns are created using the original names in the source csv file with the proper data type.
After assigning @filepath = ‘c:/rdata/Most-Recent-Cohorts-Scorecard-Elements.csv’ , and re-running the script, we can check to see a new table [Most-Recent-Cohorts-Scorecard-Elements] is created with 122 columns as shown below.
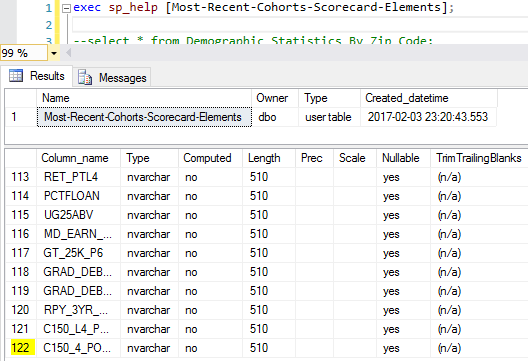
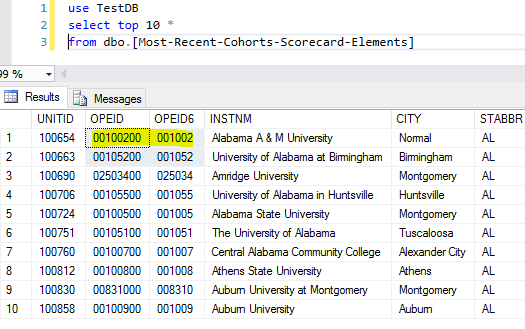
However, there is a problem for this csv file import because some csv columns are treated as integers, for example, when for [OPEID] and [OPEID6], they should be treated as a string instead because treating them as integers will drop the leading 0s.
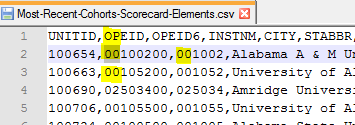
When we see what is inside the table, we will notice that in such scenario, we cannot rely on the table auto creation.
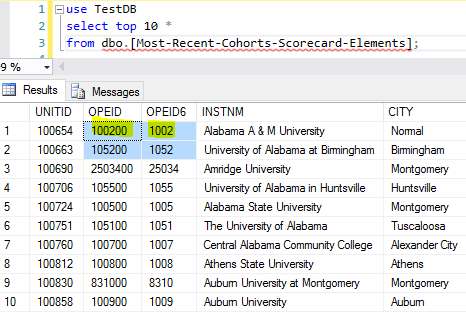
To correct this, we have to give the instruction to R read.csv function by specifying the data type for the two columns as shown below
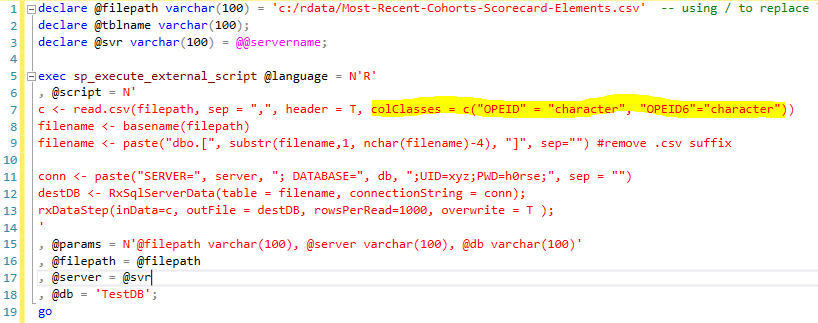
We can now see the correct values for [OPEID] and [OPEID6] columns
Implementation of Export
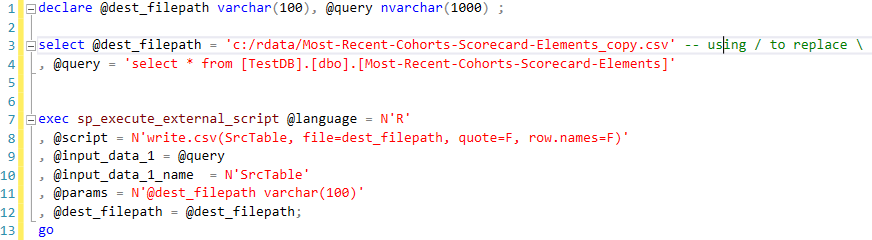
If we want to dump the data out of a table to csv file. We need to define two input parameters, one is the destination csv file path and another is a query to select the table.
The beautify of sp_execute_external_script is it can perform a query against table inside SQL Server via its @input_data_1 parameter, and then transfer the result to the R script as a named variable via its @input_data_1_name.
So here is the details:
- Define the csv file full path (line 3), this information will be consumed by the embedded R script via an input parameter definition (line 11 & 12 and consumed in line 8)
- Define a query to retrieve data inside table (line 4 and line 9)
- Give a name to the result from the query (line 10), in this case, the name is SrcTable, and it Is consumed in the embedded R script (line 8)
- In R script, use write.csv to generate the csv file.
We can modify @query to export whatever we want, such as a query with where clause, or just select some columns instead of all columns.
The complete T-SQL script is shown here:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 |
-- import data 1: import from csv file by using default configurations -- the only input parameter needed is the full path of the source csv file declare @filepath varchar(100) = 'c:/rdata/Demographic_Statistics_By_Zip_Code.csv' -- using / to replace \ declare @tblname varchar(100); declare @svr varchar(100) = @@servername; exec sp_execute_external_script @language = N'R' , @script = N' c <- read.csv(filepath, sep = ",", header = T) filename <- basename(filepath) filename <- paste("dbo.[", substr(filename,1, nchar(filename)-4), "]", sep="") #remove .csv suffix conn <- paste("SERVER=", server, "; DATABASE=", db, ";UID=xyz;PWD=h0rse;", sep = "") destDB <- RxSqlServerData(table = filename, connectionString = conn); rxDataStep(inData=c, outFile = destDB, rowsPerRead=1000, overwrite = T ); ' , @params = N'@filepath varchar(100), @server varchar(100), @db varchar(100)' , @filepath = @filepath , @server = @svr , @db = 'TestDB'; go -- import data 2: assign data type to some columns using colClasses in read.csv function -- the only input parameter needed is the full path of the source csv file declare @filepath varchar(100) = 'c:/rdata/Most-Recent-Cohorts-Scorecard-Elements.csv' -- using / to replace \ declare @tblname varchar(100); declare @svr varchar(100) = @@servername; exec sp_execute_external_script @language = N'R' , @script = N' c <- read.csv(filepath, sep = ",", header = T, colClasses = c("OPEID" = "character", "OPEID6"="character")) filename <- basename(filepath) filename <- paste("dbo.[", substr(filename,1, nchar(filename)-4), "]", sep="") #remove .csv suffix conn <- paste("SERVER=", server, "; DATABASE=", db, ";UID=xyz;PWD=h0rse;", sep = "") destDB <- RxSqlServerData(table = filename, connectionString = conn); rxDataStep(inData=c, outFile = destDB, rowsPerRead=1000, overwrite = T ); ' , @params = N'@filepath varchar(100), @server varchar(100), @db varchar(100)' , @filepath = @filepath , @server = @svr , @db = 'TestDB'; go -- export data: -- two input parameters are needed, one is the destination csv file path -- and the other is a query to select the source table declare @dest_filepath varchar(100), @query nvarchar(1000) ; select @dest_filepath = 'c:/rdata/Most-Recent-Cohorts-Scorecard-Elements_copy.csv' -- using / to replace \ , @query = 'select * from [TestDB].[dbo].[Most-Recent-Cohorts-Scorecard-Elements]' /* -- for the Demographic table, using the followng setting to replace the above two lines select @dest_filepath = 'c:/rdata/Demographic_Statistics_By_Zip_Code_copy.csv' , @query = 'select * from [TestDB].[dbo].[Demographic_Statistics_By_Zip_Code]' */ exec sp_execute_external_script @language = N'R' , @script = N'write.csv(SrcTable, file=dest_filepath, quote=F, row.names=F)' , @input_data_1 = @query , @input_data_1_name = N'SrcTable' , @params = N'@dest_filepath varchar(100)' , @dest_filepath = @dest_filepath go |
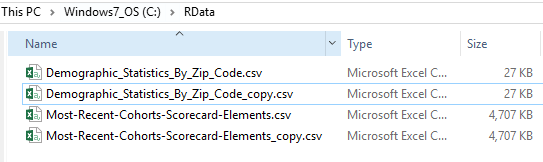
After the run the whole script, I can find the new files are created
Summary
In this article, we discussed how to execute a SQL Server table import / export via R inside T-SQL. This is totally different from our traditional approaches. This new method is easy and can handle tough CSV files, such as a CSV file with column values containing multiple lines.
This new approach does not require any additional R packages, and the script can run in SQL Server 2016 with default R installation, which already contains RevoScaleR package.
During my test with various CSV files, I notice that when reading big CSV file, we need very big memory, otherwise, there can be error. However, if run the R script directly, i.e. R script not embedded in T-SQL, like in RStudio, the memory requirement is still there, but R script can finish without error, while running the same R script inside sp_execute_external_script will fail.
No doubt, the current R integration with T-SQL is just Version 1, and there are some wrinkles in the implementation. But it is definitely a great feature which opens another door for DBAs / developers to tackle lots works. It is worth our while to understand and learn it.
Next Steps
R has lots of useful 3rd packages (most of them are open-sourced), and we can do lots of additional work with these packages, such as importing / exporting Excel files (esp. those .xlsx files), or regular expressions etc. It is really fun to play with these packages, and I will share my exploration journey in future.

- using data warehousing technology to manage big number of SQL Server instances for capacity planning, performance forecasting, and evidence mining
- doing data visualization and analysis with R
- doing T-SQL puzzles
He enjoys writing and sharing his knowledge
View all posts by Jeffrey Yao
- How to Merge and Split CSV Files Using R in SQL Server 2016 - February 21, 2017
- How to Import / Export CSV Files with R in SQL Server 2016 - February 9, 2017