
One challenge we may face when using SQL bulk insert is whether we want to allow access during the operation or prevent access and how we coordinate this with possible following transactions. We’ll look at working with a few configurations of this tool and how we may apply them in OLAP, OLPT, and mixed environments where we may want to use the tool’s flexibility for our data import needs.
Considerations
The first point that we want to consider is whether our environment should lock transactions using SQL bulk inserts and loads or whether we should still allow access. OLAP and OLTP environments may have different requirements with the former allowing us to use locks more than the latter because OLTP environments tend to have a “live” requirement. If we have a schedule where we must load data over a period before reporting, we will have more flexibility to load data with hints that can increase performance. Also, for hybrid environments, we may have tables that we can use these hints on the table level or even during the actual insert.
The next consideration is whether we want to lock transactions on the transaction level or table level. If we use a table solely for a bulk load, we may have more flexibility here. If our table is involved in SQL bulk inserts and in data feeds, where frequent data are fed to the table, we may want to avoid locks. In data feeds, we also expect frequent reads to get the new data making locks a possible problem for live or delayed reporting.
Experiments with Load Configurations
We’ll look at an example by loading a file’s data into a table and experimenting with various lock techniques for the table. In our example, we will have a file of over 2 million lines with the sentence “The quick brown fox jumped over the lazy dogs” starting on line 2 and repeating. The first line (which we’ll skip in our SQL bulk insert) will have “Data” and we can create this file using any scripting language that allows a loop, or we can copy and paste the lines ourselves in batches. While this example uses this full sentence, we could also use one letter on each line or one word on each line.
As an alternative, if you already have a large custom text file for testing imports, you can use that file if the mappings involve one column or if you have a table that has identical mappings for the import. The timed results of the loads shown in the below examples may differ depending on the system and data you have.
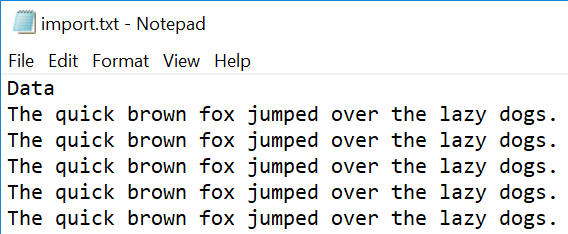
Example the first five lines of our test import file
Once our file is large enough (in my example over 2 million lines), we will then SQL bulk insert the file’s data into our table that created with one column. Since we’re mapping the one line of data to one column, we do not specify a field terminator. The below image shows the select from the first five results of our bulk load into the table we created. In the code, I include a drop table that can be used when everything is done being tested.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
CREATE TABLE tblImport( FileData VARCHAR(MAX) ) BULK INSERT tblImport FROM 'C:\Import\import.txt' WITH ( ROWTERMINATOR = '\n' ,FIRSTROW=2 ) SELECT * FROM tblImport ---- Remove table when finished --DROP TABLE tblImport |
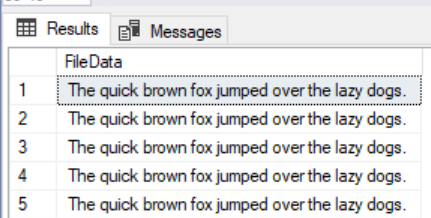
The first five results of our SQL bulk insert.
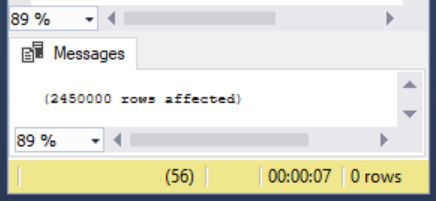
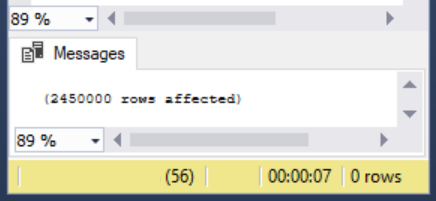
The load consumed 7 seconds for 2.45 million rows.
When I ran this SQL bulk insert, the execution time from start to finish required 7 seconds (within the 5 to 10-second range). Now, we’ll run the same insert and adding one specification of TABLOCK for our bulk load operation – locking the table during the load:
|
1 2 3 4 5 6 7 |
BULK INSERT tblImport FROM 'C:\Import\import.txt' WITH ( ROWTERMINATOR = '\n' ,FIRSTROW=2 ,TABLOCK ) |
The result of this is reduced time to insert the same amount of data.
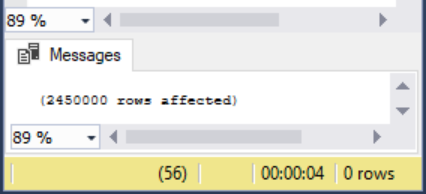
The same transaction with a table lock on the actual insert, consuming 4 seconds.
The advantage of specifying a table lock on the bulk load level is that if this table was used for both a reporting schedule and a feed, we wouldn’t be locking the table on every load – only the large insert that would require a table lock, if that’s the specification. This means that if we had 100 SQL bulk inserts on the table throughout the day and 1 of those load required a performance boost along with locking access on the table due to the nature of the load, we could use the TABLOCK specification for the 1 load while the other 99 loads would be unaffected. This is useful in these mixed contexts.
According to Microsoft’s notes on specifying this option, this lock only occurs for the length of the actual bulk load – in other words, if we had further transformed following this in the same transaction, this lock would not apply to these further transactions (we would want to specify lock hints for them as well, if this was the desired behavior). Likewise, we can simultaneously bulk load the same table even if this option if specified, provided the destination table of the load has no indexes (columnstore indexes being the exception here).
What about the scenario where the table is only for a reporting schedule where any SQL bulk insert must be locked during any load. We could still specify the TABLOCK option in our code during the actual insert or on the transaction level, but we can also add this option on the table level. In the below code, we set the lock on the table level using the Microsoft procedure sp_tableoption and perform a check to ensure that this option was saved successfully.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT [name] TableName , CASE WHEN lock_on_bulk_load = 0 THEN 'False' ELSE 'True' END AS SBILock FROM sys.tables WHERE [name] = 'tblImport' EXEC sp_tableoption 'tblImport' , 'table lock on bulk load' , '1' SELECT [name] TableName , CASE WHEN lock_on_bulk_load = 0 THEN 'False' ELSE 'True' END AS SBILock FROM sys.tables WHERE [name] = 'tblImport' |
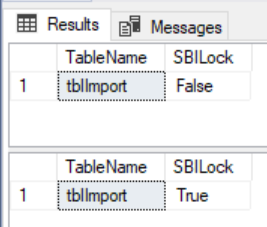
The results of our query checking the lock on bulk load option for the specific table.
Now, when I run the bulk load transaction with this option set on the table level from the execution above code and removing the TABLOCK option, I get a similar time with the lock set on the table level:
|
1 2 3 4 5 6 |
BULK INSERT tblImport FROM 'C:\Import\import.txt' WITH ( ROWTERMINATOR = '\n' ,FIRSTROW=2 ) |
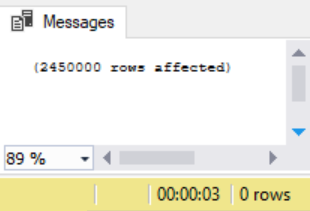
With a lock on the table level, we see a similar result to the TABLOCK option specified on the SQL bulkinsert
The advantage here in appropriate development contexts is that we wouldn’t need to specify the TABLOCK option on each of our SQL bulk insert calls. This would also mean that during loads, the table would be locked.
As a note, to disable this option on the table, we would run the below call to the Microsoft stored procedure sp_tableoption:
|
1 2 3 |
EXEC sp_tableoption 'tblImport' , 'table lock on bulk load' , '0' |
Final Thoughts
- Do we have regular reports with live data or scheduled reports with SQL bulk inserts? We may use locks in situations where we have scheduled reports that must be completed by a time whereas if we use bulk loads with live data, they may require consistent access
- With some exceptions, we may find it most appropriate to lock a table during a bulk load on the load itself or on the transaction if we have transforms that immediately follow and we want no access granted during this time
- While we’ve looked at adding locks on a table in situations where we don’t want anyone to access the table while we SQL bulk insert data (increasing the performance), we can also apply additional performance measures such as removing indexes or dropping and re-creating the table, if we do not require the table’s existence before loading data

He has spent a decade working in FinTech, along with a few years in BioTech and Energy Tech.He hosts the West Texas SQL Server Users' Group, as well as teaches courses and writes articles on SQL Server, ETL, and PowerShell.
In his free time, he is a contributor to the decentralized financial industry.
View all posts by Timothy Smith
- Data Masking or Altering Behavioral Information - June 26, 2020
- Security Testing with extreme data volume ranges - June 19, 2020
- SQL Server performance tuning – RESOURCE_SEMAPHORE waits - June 16, 2020