
In this article, we illustrate how to use the OFFSET FETCH feature as a solution for loading large volumes of data from a relational database using a machine with limited memory and preventing an out of memory exception. We describe how to load data in batches to avoid placing a large amount of data into memory.
This article is the first in the SSIS Tips and Tricks series which aims to illustrate some best practices.
Introduction
When searching online for problems related to SSIS data import, you’ll find solutions that can be used in optimal environments or tutorials for handling a small amount of data. Unfortunately, these solutions prove to be unsuitable in a real environment.
In reality, smaller companies can’t always adopt new storage, processing equipment, and technologies although they must still handle an increasing amount of data. This is especially true for social media analysis since they must analyze the behavior of their target audience (customers).
Similarly, not all companies can upload their data to the cloud due to the high cost along with data privacy and confidentiality issues.
OFFSET FETCH feature
OFFSET FETCH is a feature added to the ORDER BY clause beginning with the SQL Server 2012 edition. It can be used to extract a specific number of rows starting from a specific index. As an example, we have a query that returns 40 rows and we need to extract 10 rows from the 10th row:
|
1 2 3 4 5 |
SELECT * FROM Table ORDER BY ID OFFSET 10 ROWS FETCH NEXT 10 ROWS ONLY |
In the query above, OFFSET 10 is used to skip 10 rows and FETCH 10 ROWS ONLY is used to extract only 10 rows.
To get additional information about the ORDER BY clause and OFFSET FETCH feature, refer to the official documentation: Using OFFSET and FETCH to limit the rows returned.
Using OFFSET FETCH to load data in chunks (pagination)
One of the main purposes of using the OFFSET FETCH feature is to load data in chunks. Let’s imagine we have an application that executes a SQL query and needs to show the results on several pages where each page contains only 10 results (similar to the Google search engine).
The following query can be used as a paging query where @PageSize is the number of rows you need to show in each chunk and @PageNumber is the iteration (page) number:
|
1 2 3 4 5 |
SELECT <some columns> FROM <table name> ORDER BY <some columns> OFFSET @PageSize * @PageNumber ROWS FETCH NEXT @PageSize ROWS ONLY; |
This article is not intended to illustrate all use cases of the OFFSET FETCH feature, nor does it discuss best practices. There are many articles online that you can refer to for more information:
Implementing the OFFSET FETCH feature within SSIS to load a large volume of data in chunks
We’ve often been asked to build an SSIS package that loads a huge amount of data from SQL Server with limited machine resources. Loading data using OLE DB Source using Table or View data access mode was causing an out of memory exception.
One of the easiest solutions is to use the OFFSET FETCH feature to load data in chunks to prevent memory outage errors. In this section, we provide a step-by-step guide on implementing this logic within an SSIS package.
First, we must create a new Integration Services package, then declare four variables as follows:
- RowCount (Int32): Stores the total number of rows in the source table
- IncrementValue (Int32): Stores the number of rows we need to specify in the OFFSET clause (similar to @PageSize * @PageNumber in the example above)
- RowsInChunk (Int32): Specifies the number of rows in each chunk of data (Similar to @PageSize in the example above)
- SourceQuery (String): Stores the source SQL command used to fetch data
After declaring the variables, we assign a default value for the RowsInChunk variable; in this example, we will set it to 1000. Furthermore, we must set the Source Query expression, as follows:
|
1 2 3 4 5 |
"SELECT * FROM [AdventureWorks2017].[Person].[Person] ORDER BY [BusinessEntityID] OFFSET " + (DT_WSTR,50)@[User::IncrementValue] + " ROWS FETCH NEXT " + (DT_WSTR,50) @[User::RowsInChunk] + " ROWS ONLY" |
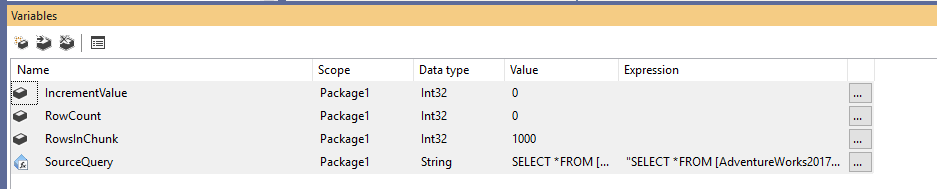
Figure 1 – Adding variables
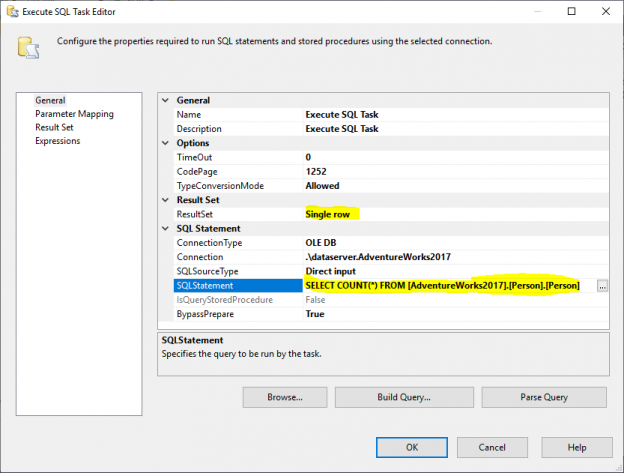
Next, we add an Execute SQL Task to get the total number of rows in the source table. In this example, we use the Person table stored in the AdventureWorks2017 database. In the Execute SQL Task, we used the following SQL Statement:
|
1 |
SELECT COUNT(*) FROM [AdventureWorks2017].[Person].[Person] |
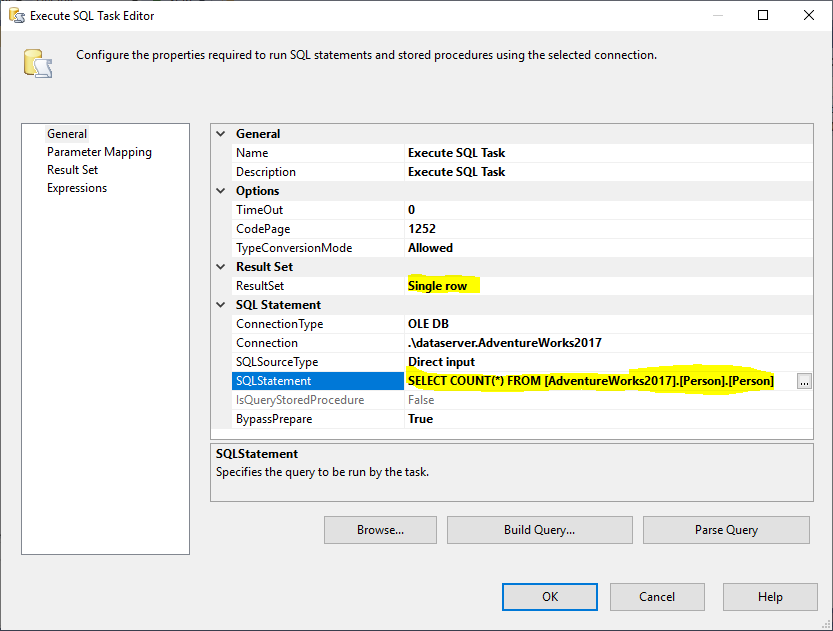
Figure 2 – Setting Execute SQL Task
And, we must change the Result Set property to Single Row. Then, in the Result Set Tab, we select the RowCount variable to store the result set as shown in the image below:
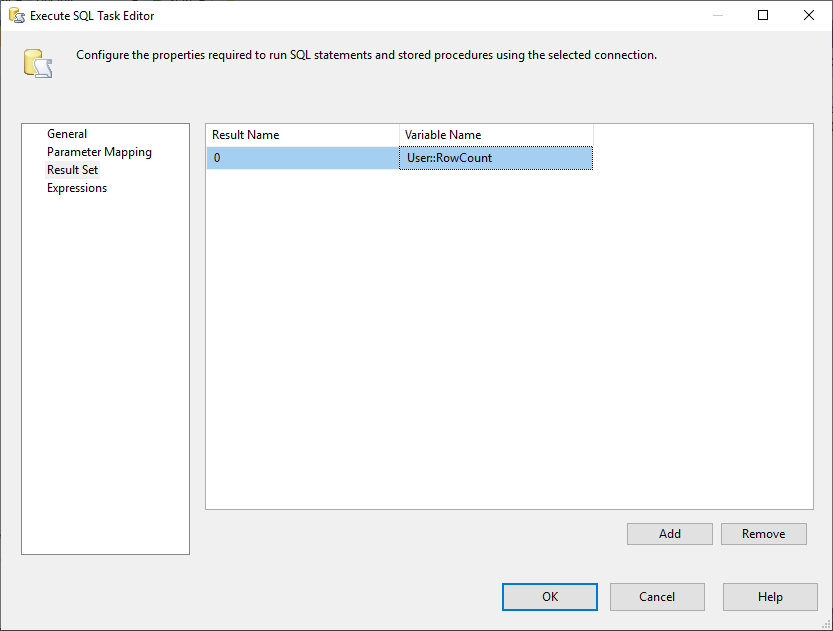
Figure 3 – Mapping result set to variable
After configuring the Execute SQL Task, we add a For Loop Container, with the following specifications:
- InitExpression: @IncrementValue = 0
- EvalExpression: @IncrementValue <= @RowCount
- AssignExpression: @IncrementValue = @IncrementValue + @RowsInChunk
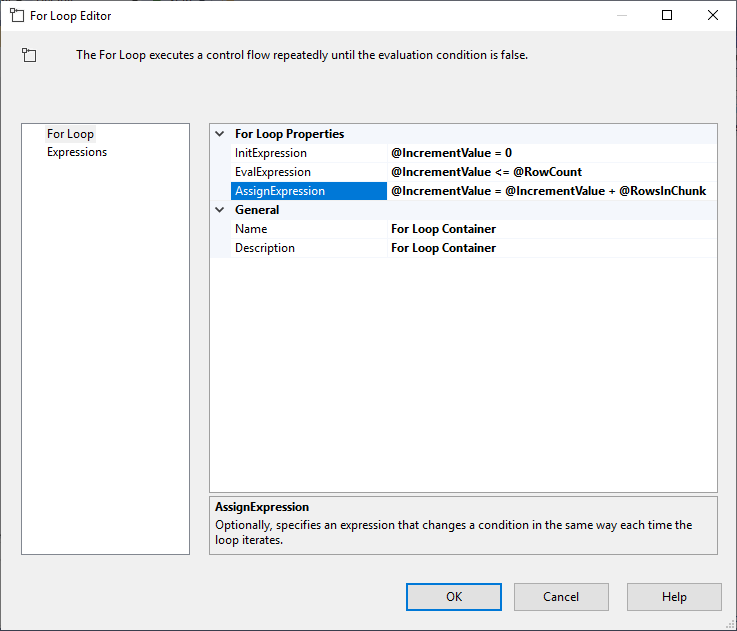
Figure 4 – Configuring for loop container
After configuring the For Loop Container, we add a Data Flow Task inside it. Then, within the Data Flow Task, we add an OLE DB Source and OLE DB Destination.
In the OLE DB Source we select SQL Command from variable data access mode, and select @User::SourceQuery variable as the source.
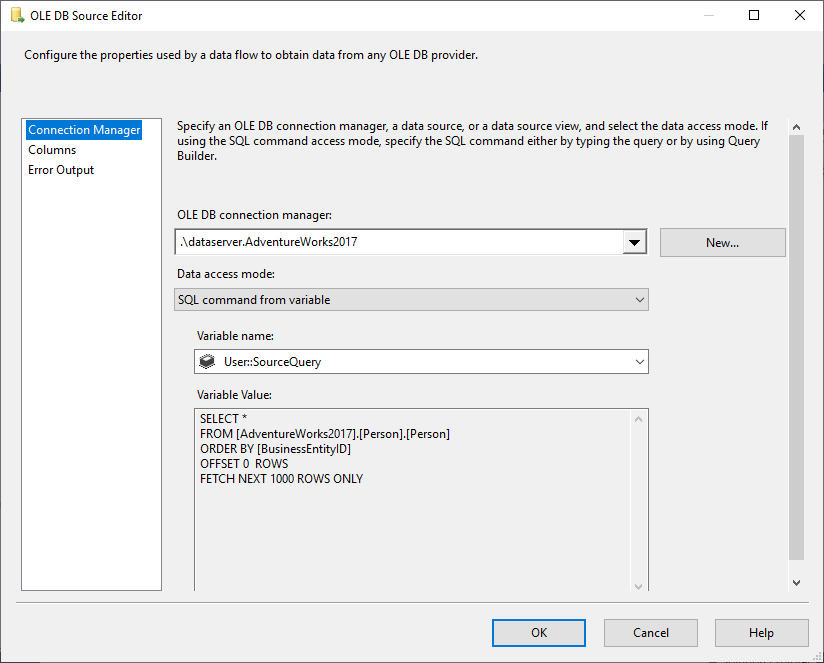
Figure 5 – Configuring OLE DB source
We specify the destination table within the OLE DB Destination component:
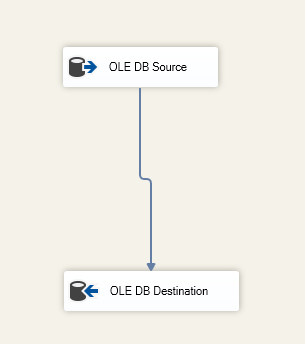
Figure 6 – Data flow task screenshot
The package control flow should look like the following:
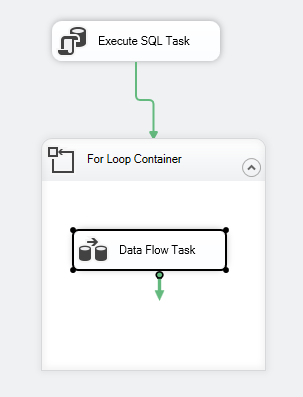
Figure 7 – Control flow screenshot
Limitations
After illustrating how to load data in chunks using the OFFSET FETCH feature in SSIS, we’ll note that this logic has some limitations:
- You always need some columns to be used in the ORDER BY clause (Identity or Primary key is preferred), since OFFSET FETCH is a feature of the ORDER BY clause and it cannot be implemented separately
- If an error occurs while loading data, all data exported to the destination is committed and only the current chunk of data is rolled back. This may require additional steps to prevent data duplication when running the package again
OFFSET FETCH using other database providers
In the following section, we briefly cover the syntax used by other database providers:
Oracle
With Oracle, you can use the same syntax as SQL Server. Refer to the following link for more information: Oracle FETCH
SQLite
In SQLite, the syntax is different from SQL Server, since you use the LIMIT OFFSET feature as mentioned below:
|
1 2 3 |
SELECT * FROM MYTABLE ORDER BY ID_COLUMN LIMIT 50 OFFSET 10 |
MySQL
In MySQL, the syntax is similar to SQLite, since you use LIMIT OFFSET instead of OFFSET Fetch.
DB2
In DB2, the syntax is similar to SQLite, since you use LIMIT OFFSET instead of OFFSET FETCH.
Conclusion
In this article, we’ve described the OFFSET FETCH feature found in SQL Server 2012 and higher. We illustrated how to use this feature to create a paging query, then provided a step-by-step guide on how to load data in chunks to allow extracting large amounts of data using a machine with limited resources. Finally, we mentioned some of the limitations and the syntax differences with other database providers.

Besides working with SQL Server, he worked with different data technologies such as NoSQL databases, Hadoop, Apache Spark. He is a MongoDB, Neo4j, and ArangoDB certified professional.
On the academic level, Hadi holds two master's degrees in computer science and business computing. Currently, he is a Ph.D. candidate in data science focusing on Big Data quality assessment techniques.
Hadi really enjoys learning new things everyday and sharing his knowledge. You can reach him on his personal website.
View all posts by Hadi Fadlallah
- An overview of SQL Server monitoring tools - December 12, 2023
- Different methods for monitoring MongoDB databases - June 14, 2023
- Learn SQL: Insert multiple rows commands - March 6, 2023