
Introduction
Data collection capabilities have been expanding at an exponential speed over the years, and so have data processing capabilities. With the advent of the cloud, it’s easy to assume that one would have the ability to process all the data every single time. But in practice, at times either all the data may be available or in certain use-cases, they may not be enough time or value in processing each data point. In such cases, one practice of mathematics comes to rescue which has been around forever. This branch of mathematics is called statistics. We use statistics in most of our day-to-day data processing logic using functions like mean which is also called aggregate. One of the important statistical functions that are often used by data developers is the standard deviation function.Where is standard deviation used in practical scenarios?
Almost every domain, has one or other application of standard deviation to understand how the dataset is positioned in comparison to each other. For example, in finance, there may be multiple stocks that may have the same average returns over a period of 10 years. But when we calculate their standard deviation, it may come significantly different. A higher standard deviation would mean higher volatility i.e., higher uncertainty which would translate into higher risk. In most machine learning applications, typically the analysis of the dataset starts with an exercise known as exploratory data analysis, which aims to create a balanced sample of the actual dataset. Here too standard deviation is one of the means that is used to understand the characteristics of the dataset and remove outliers. In this way, there are many applications of standard deviation and one can easily find a lot of reference material related to this on the web.How to derive or calculate Standard Deviation
While there is a ready-to-use SQL Standard Deviation function, to use this function, one needs to understand the logic behind the calculation. Else the function would emit values and one won’t be able to understand or explain whether the values calculated are making sense or even how to make use of the calculated values. Let’s start with some basic concepts to form the basis of the Standard Deviation function. To understand the calculations, we first need a sample dataset. Let’s say our dataset is formed of the following random numbers: 1, 2, 4, 9. The first step towards calculating standard deviation is calculating the mean i.e., the average value of the dataset. This is done by adding all the numbers and diving it by the total count of numbers. In this case, it would be 1+2+4+9 / 4 = 4. In the overall function formula, the mean is indicated by μ. The second step towards calculating the standard deviation is the distance of each data point from the mean that we calculated above. This is done by subtracting the mean value from the data point, taking the absolute value, and squaring it. It is represented by ∣x−μ∣ 2 In our case, the calculation would look as follows:- | 1 – 4 |2 = 32 = 9
- | 2 – 4 |2 = 22 = 4
- | 4 – 4 |2 = 02 = 0
- | 9 – 4 |2 = 52 = 25
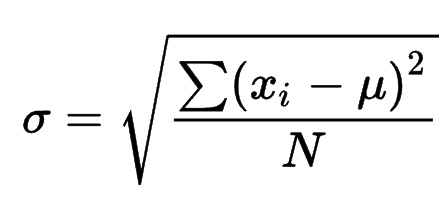 When we implement the above formula, the final value would be the root of 38 divided by 4, which would be 3.08. This is the way the standard deviation is calculated.
When we implement the above formula, the final value would be the root of 38 divided by 4, which would be 3.08. This is the way the standard deviation is calculated.
SQL Standard Deviation Function
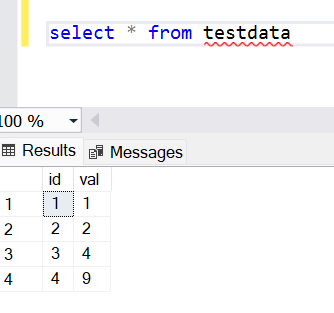
Now it’s time to put the SQL standard deviation function to use. For this, we would need any database that supports the standard deviation function. Almost all the databases support this function, so there is no need for a specific database only to use this function. In our case, to demonstrate the SQL standard deviation function, we would use the SQL Server database on Azure. It is assumed that an active Azure account or subscription is available, and SQL Azure is set up on this account. It is also assumed that the IDE that would be used to execute queries on this database is already in place and connected to the database. Now that the setup is in place, we need the test data to execute the Standard Deviation function. We have two choices for the test data. Either we can use any sample dataset that has numeric values, or we can create the same sample data that we used in the above example and apply the SQL Standard Deviation function to it. Here I have created a simple table with just two fields to keep the dataset simple and added the same values to this table. The data in this table looks as shown below.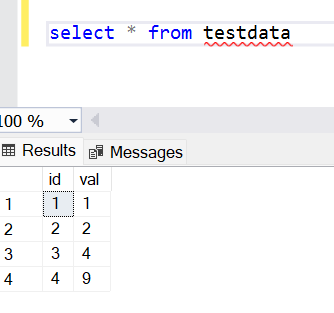 Now let’s apply the SQL Standard Deviation function on it. There are two varieties of the standard deviation function – STDEV and STDEVP. While using these functions, one won’t find any difference in terms of usage, and both returns the standard deviation as well. But there is still an important distinction between these two standard deviation functions, which we will understand shortly.
Let’s say that we consider that all the values in the field that we have selected for calculating the standard deviation are the total dataset. In statistical terms, it is called the population as it represents the entire dataset i.e., each data point is contained in this dataset. In that case, we want to calculate what is known as the population standard deviation. The formula that we used above is for the population standard deviation and should return the same value that we calculated manually earlier. Execute the query as shown below, where we are using the SQL standard deviation function stdev, which is usually used for calculating the standard deviation.
Now let’s apply the SQL Standard Deviation function on it. There are two varieties of the standard deviation function – STDEV and STDEVP. While using these functions, one won’t find any difference in terms of usage, and both returns the standard deviation as well. But there is still an important distinction between these two standard deviation functions, which we will understand shortly.
Let’s say that we consider that all the values in the field that we have selected for calculating the standard deviation are the total dataset. In statistical terms, it is called the population as it represents the entire dataset i.e., each data point is contained in this dataset. In that case, we want to calculate what is known as the population standard deviation. The formula that we used above is for the population standard deviation and should return the same value that we calculated manually earlier. Execute the query as shown below, where we are using the SQL standard deviation function stdev, which is usually used for calculating the standard deviation.
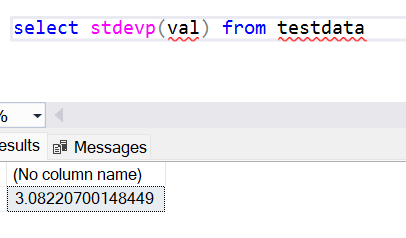 Now let’s consider another case, where we may have a sample set of data. It can be the case that data is continuously being generated and accumulated, and any at given point in time, we may only have a sample of the data. So, we may want to calculate the standard deviation based on the sample of data available at hand. In that case, we would intend to calculate the sample standard deviation. For this, we should use the SQL standard deviation function stdev. Execute the following query as shown below to use the stdev.
Now let’s consider another case, where we may have a sample set of data. It can be the case that data is continuously being generated and accumulated, and any at given point in time, we may only have a sample of the data. So, we may want to calculate the standard deviation based on the sample of data available at hand. In that case, we would intend to calculate the sample standard deviation. For this, we should use the SQL standard deviation function stdev. Execute the following query as shown below to use the stdev.
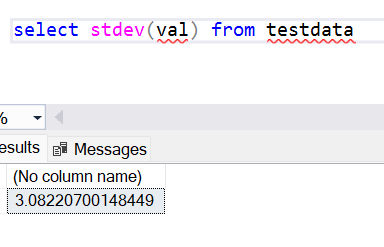 If we observe carefully, the value of the standard deviation is a little different. The reason for the same is that as we are calculating the standard deviation over a sample of data, to remove the bias, we subtract 1 from the denominator. That means that instead of N, we would be using N – 1 in the formula. Considering this, if we manually calculate the standard deviation as we did above, we will end up dividing 38 / 3 and calculating the square root. The answer would be the same as shown above.
The syntax of the SQL standard deviation function is shown below. By default, the function would be applied to all the values. Let’s say we want to apply the function only on distinct values, we can use the keyword distinct before the column name that is passed as a parameter in the function. This function like other SQL functions can be applied in various parts of the query, like in the WHERE clause, HAVING clause, subquery, etc.
If we observe carefully, the value of the standard deviation is a little different. The reason for the same is that as we are calculating the standard deviation over a sample of data, to remove the bias, we subtract 1 from the denominator. That means that instead of N, we would be using N – 1 in the formula. Considering this, if we manually calculate the standard deviation as we did above, we will end up dividing 38 / 3 and calculating the square root. The answer would be the same as shown above.
The syntax of the SQL standard deviation function is shown below. By default, the function would be applied to all the values. Let’s say we want to apply the function only on distinct values, we can use the keyword distinct before the column name that is passed as a parameter in the function. This function like other SQL functions can be applied in various parts of the query, like in the WHERE clause, HAVING clause, subquery, etc.
 In this way, we can use the SQL Standard Deviation function and easily calculate an important metric to understand the characteristics of any given dataset.
In this way, we can use the SQL Standard Deviation function and easily calculate an important metric to understand the characteristics of any given dataset.
Conclusion
In this article, we learned how to calculate the standard deviation function manually as well as using the SQL standard deviation function. Also, we learned the difference between two different types of Standard Deviation functions.
Gauri is a SQL Server Professional and has 6+ years experience of working with global multinational consulting and technology organizations. She is very passionate about working on SQL Server topics like Azure SQL Database, SQL Server Reporting Services, R, Python, Power BI, Database engine, etc. She has years of experience in technical documentation and is fond of technology authoring.
She has a deep experience in designing data and analytics solutions and ensuring its stability, reliability, and performance. She is also certified in SQL Server and have passed certifications like 70-463: Implementing Data Warehouses with Microsoft SQL Server.
View all posts by Gauri Mahajan
She has a deep experience in designing data and analytics solutions and ensuring its stability, reliability, and performance. She is also certified in SQL Server and have passed certifications like 70-463: Implementing Data Warehouses with Microsoft SQL Server.
View all posts by Gauri Mahajan
Latest posts by Gauri Mahajan (see all)
- Oracle Substring function overview with examples - June 19, 2024
- Introduction to the SQL Standard Deviation function - April 21, 2023
- A quick overview of MySQL foreign key with examples - February 7, 2023