
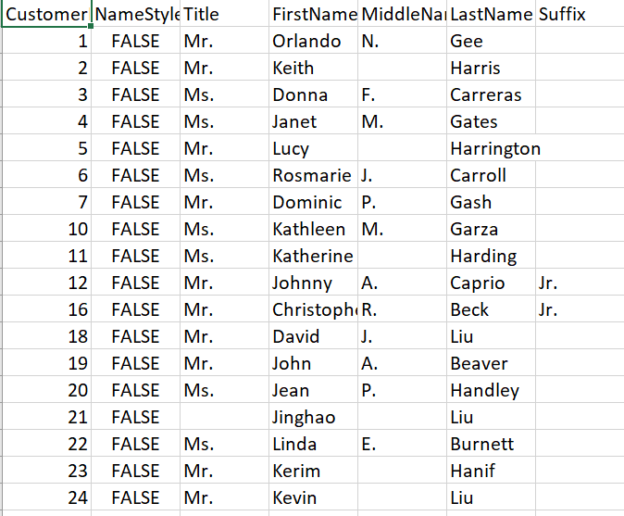
This article will provide an understanding of identifying duplicate values in SQL.
Introduction
SQL Server is one of the most widely used databases at the current time. Many huge organizations have been using it for decades now. Many Datawarehouse banks on storing data in SQL and processing it for advanced analytics and insights. Even visualization layers like Power BI also supports the greatest number of features and functionalities with SQL server. One of the common issues that come with any kind of data storage is the “Unnormalized form” of data. In simpler words, it deals with raw and unmanaged data which can have a lot of DUPLICATES in it. Let’s understand it with the below examples:
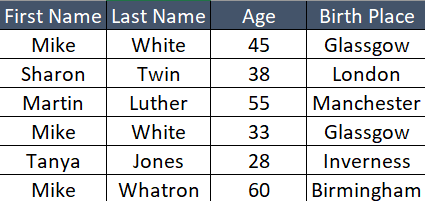
How to Identify Duplicates:
Now let’s say we have an informative table of “People Records”. We need to find duplicates with a combination of first name and last name. As you can see in the above table, we have two people with the name “Mike White”. However, they are NOT duplicates as we can see from age and birthplace.
However, they are duplicates in the following ways:
- Number of occurrences of more than 1
- Number of occurrences of more than 1 for a limited set of metadata
- Number of occurrences of more than 1 for a limited set of metadata for a single or combination of multiple columns
Let us understand point number 3 a little more elaboratively.
Single Column Duplicates:
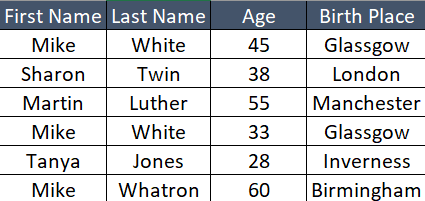
In the above image, let’s take the “First Name” column as an example. There are a total of five records in which records with “Mike” has three occurrences. At times, there would be a need to find out several records with many occurrences like:
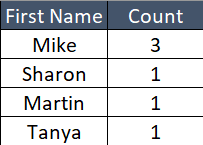
These can be called “Single Column Duplicates” with their occurrences count.
Multiple Column Duplicates:
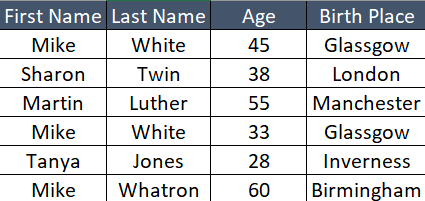
Taking the same example shown above, there will be a need at times to find duplicates with a combination of multiple columns. In the above example though there are three occurrences of “Mike”, however, there are only two occurrences of “Mike White” with a combination of “First Name” and “Last Name”.
SQL provides multiple ways to find out duplicates in a single column or multiple records. Below are the three ways:
DISTINCT and COUNT:
Distinct is a function provided by SQL to get the distinct values of any given column in SQL tables. COUNT is a function that gives the count of the number of records of a single or combination of columns. When DISTINCT and COUNT are used together, you can find out whether there are duplicates in the column or not.
Pros:
Easier ways to find out duplicates in column
Cons:
Lack of options to show it with the number of occurrences.
Lack of options to show other metadata of records with occurrences.
Let’s take an example. I have created a database and I am using the “AdventureWorks” sample database as shown below (a few records):
Now let’s say, I want to find whether FirstName has duplicate records or not, then below steps must be followed:
-
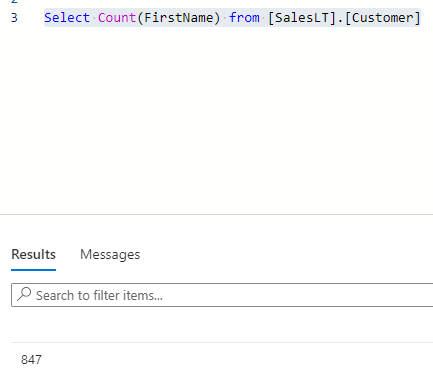
Find the Total Count of FirstName
To do so, we can use the below query:
123Select COUNT (FirstName) from (Customer)
As shown, in the above image shows 847 as the count of records
-
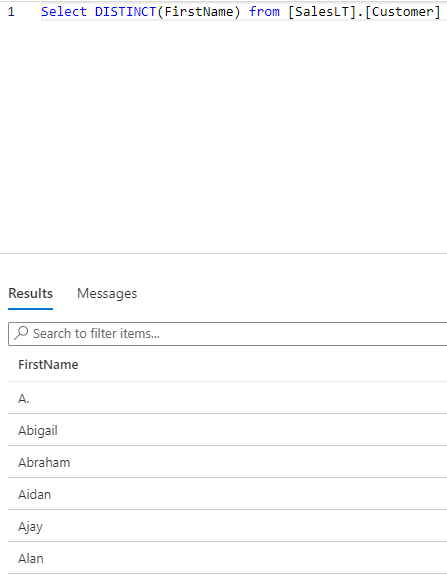
Find a Distinct Count of FirstName
Before we get a distinct count, I would like to show how the DISTINCT function gives unique values of a column. To do so, use the below query:
123Select DISTINCT(FirstName) from (Customer)
In the above image, we can see various values being pulled in. These all are unique “FirstNames”. However, we aim to find out a total of such unique names. To do so, you can write the below query:
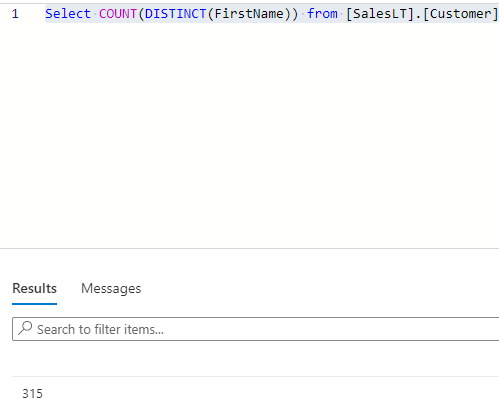
123Select COUNT(DISTINCT(FirstName)) from (Customer)
We can see there are only 315 unique First Names.
-
Subtract the Total Count of FirstName from the Distinct Count of FirstName from
Now the last step is the easiest to subtract the total from distinct. To do so, write a query as below:
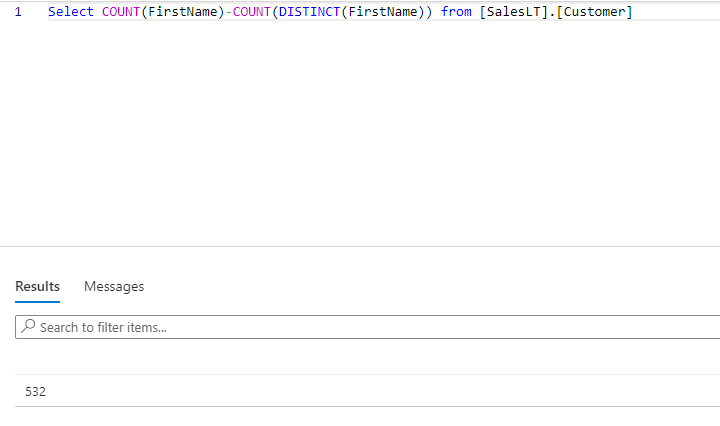
123Select COUNT(FirstName)-COUNT(DISTINCT(FirstName)) from (Customer)
As per the above result, we can see there are 532 duplicate records in total. However, the challenge is in case of we need to know how many duplicates exist in each duplicate record, then it would be a little complex to write a query. There is where our second options come into the picture
GROUP BY AND COUNT
Group By is a function that groups all the unique values of single or multiple columns and gets the result. It is a way of consolidating and summarizing unique data to get a unique summary. COUNT function as well saw earlier provides the number of occurrences; however, it differs a little when used with the Group By function. When Count is used with the Group By function, it provides the number of occurrences individually for Each unique value.
Pros:
Easily able to get unique and duplicate records with individual occurrence count
Cons:
A little complex to get the additional metadata of duplicate records
Let’s take the sample example we were using earlier. We will use the same AdventureWorks database and customer table to fetch all unique “FirstName” along with their duplicate counts. To do so, please write below the query
|
1 2 3 4 |
Select FirstName, COUNT(*) from [SalesLT].[Customer] Group By FirstName |
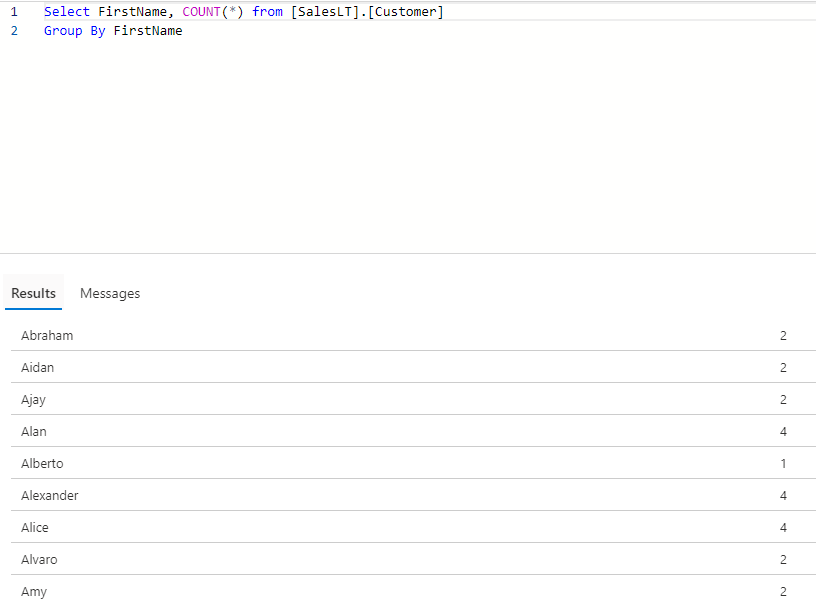
Below is a subset of all the unique “FirstNames” along with their count. We can see many records have more than 1 total occurrence. However, there are records like “Alberto” which has only 1 occurrence which means it doesn’t have any duplicate records. To exclude such records for us to see the actual duplicate records, we need to use the Having keyword with Group By clause. Having a keyword is as equivalent to the Where Clause in which you mention your criteria. In our current example, we will mention criteria as the count of occurrences should be greater than 1. To do so, please update the query to:
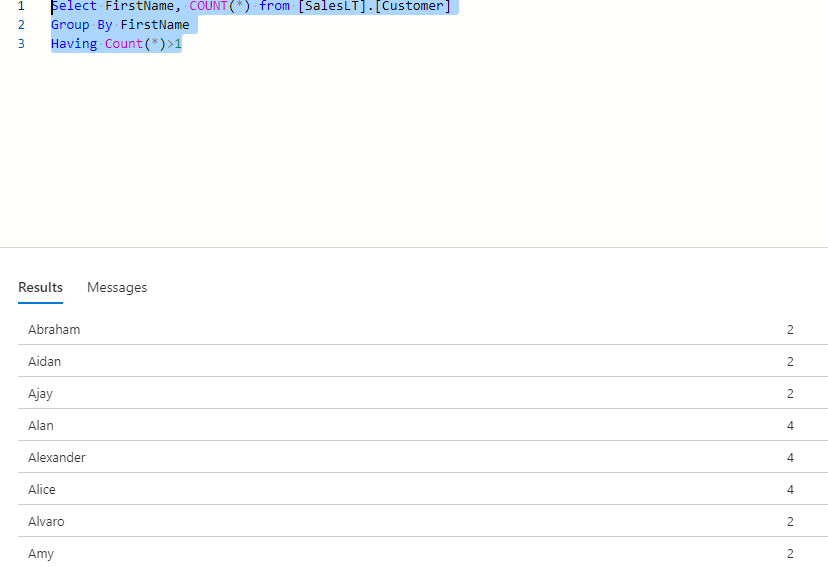
We can see now in the above results that only the records which have multiple occurrences appear in the results. This will be the way to find the duplicate values for a single column. In case you want to see unique records, then all you need to do is change the having clause to meet the count of records to 1.
At times, architects use multiple columns to define a sub-primary key or unique identifier of a table. For example, let’s say in the below table a combination of “FirstName + LastName” makes unique records. So sometimes, you need to find duplicates with a combination of FirstName and LastName. To do so, simply extend the Group By clause query as below:
|
1 2 3 4 5 |
Select FirstName, LastName, COUNT(*) from [SalesLT].[Customer] Group By FirstName, LastName Having Count(*)>1 |
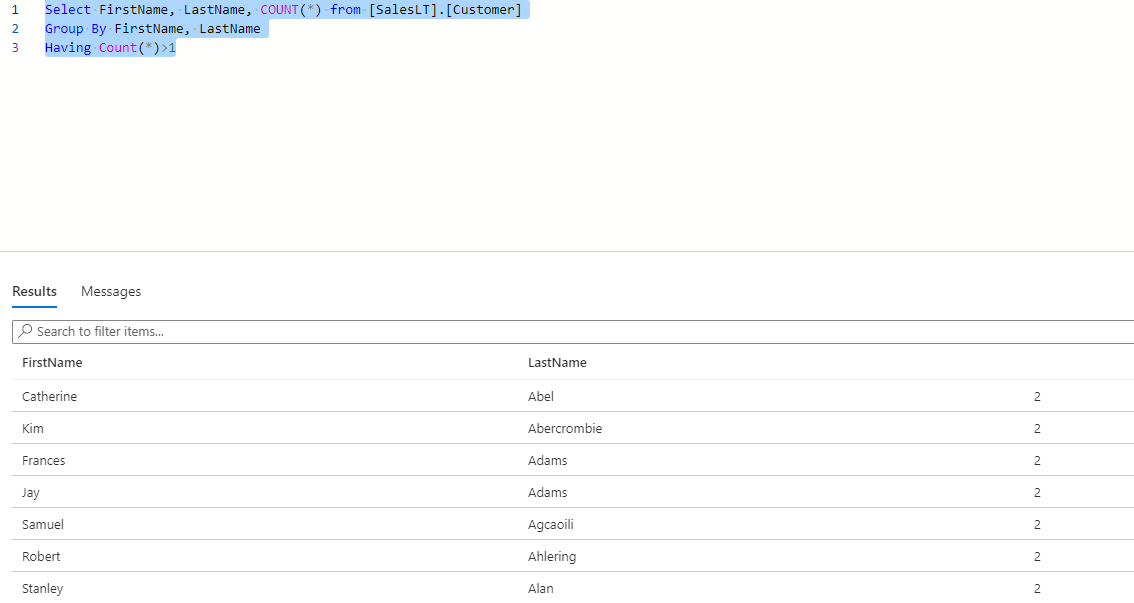
Few things to observe in the above results:
- The duplicate records are considered with a combination of “FirstName” and “LastName”
- In the query, we must mention all the column names in the “Group By” clause which needs to be in combination
- When Count(*) is mentioned in the Having clause, it means it will take a count of a combination of all the columns mentioned in the Group By clause.
Thus, in this way we can use Group By clause could be used to find duplicates in multiple columns. However, still, let’s say we need to get additional metadata along with duplicate values, it will be a little hard in Group By clause. That is where ROW_NUMBER functions come into the picture.
ROW_NUMBER
The ROW_NUMBER() is a window function that assigns a sequential integer to each row within the partition of a result set. In our scenario, we need to use this function to bifurcate the columns we want to find duplicates for and mention the rest of the columns as additional metadata to provide more information. To do so, use the below query
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
WITH customerdata AS ( SELECT CustomerID, FirstName, LastName, CompanyName, ROW_NUMBER() OVER ( PARTITION BY FirstName,LastName ORDER BY FirstName, LastName ) As Occurrences FROM [SalesLT].[Customer] ) SELECT * FROM customerdata WHERE Occurrences > 1; |
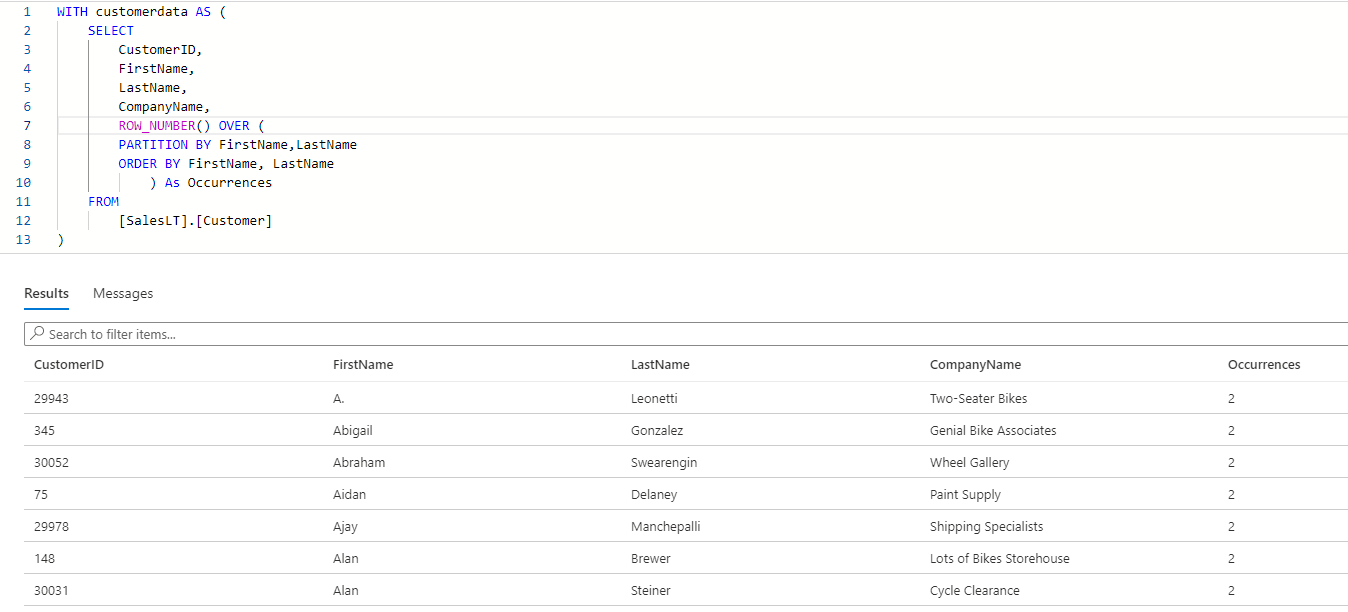
Few points to observe:
- The result set shows additional metadata along with the number of occurrences in it.
- We have used ROW_NUMBER Function to get the partition data where the combination of the FirstName and LastName columns has more than 1 occurrence
-
ROW_NUMBER function should have:
- An Over clause mentioning the partition
- An Order BY clause mentioning the column names
- An Alias name for the entire subset to match the count
Please note that we have used all the options independently. But we can use it with different combinations in more complex scenarios.
Conclusion
In this article, we have learned:
- Different ways to find duplicate values in SQL.
- How to use the DISTINCT, GROUP BY, COUNT, and ROW_NUMBER functions.
- How to use these functions in query, functions, and other objects to get unique values.

He has worked internationally with Fortune 500 clients in various sectors and is a passionate author.
View all posts by Rahul Mehta
- Finding Duplicates in SQL - February 7, 2024
- MySQL substring uses with examples - October 14, 2023
- MySQL group_concat() function overview - March 28, 2023