This article will show how to catalog data assets and then tag business glossaries at the attribute level of data assets in Azure Purview.
Read more »

This article will show how to catalog data assets and then tag business glossaries at the attribute level of data assets in Azure Purview.
Read more »
DBA may import, export regularly within a different environment. You might receive data in a specified format for importing it into database tables.
Read more »
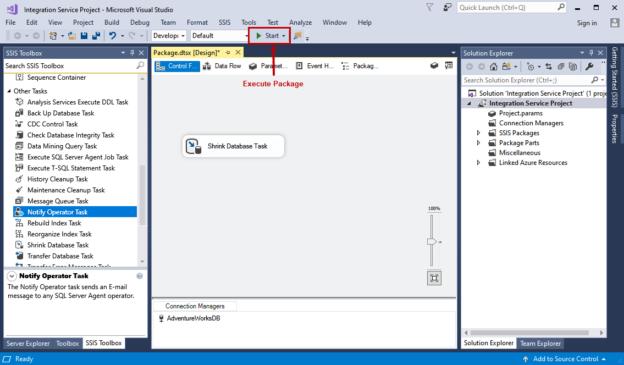
In this article, we are going to learn how we can install and configure the SSDT 2017 on Windows 10. The SQL Server data tools 2017 (SSDT 2017) is a development tool used for database development, SQL Server analysis service data models, SQL Server report service reports, and Integration service packages.
Read more »

In this article, we will explore Azure Purview capability and understand it with a practical walkthrough.
Read more »
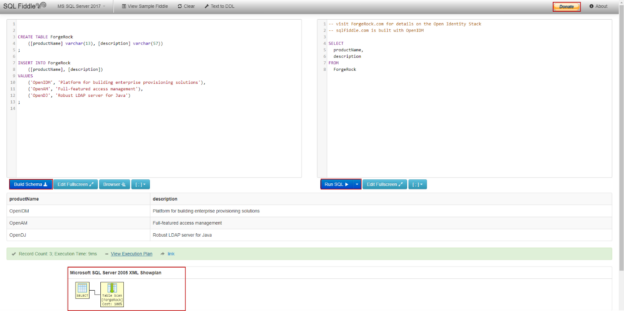
In this article, we will look at the 2 different SQL syntax checker tools that help to find the syntax errors of the queries without executing them.
Read more »
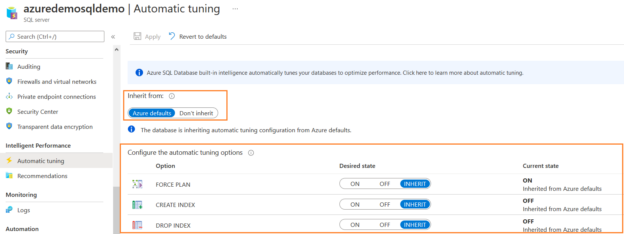
This article will explore automatic index advisor (CREATE_INDEX, DROP_INDEX) for Azure SQL Database.
Read more »

This article will help you to learn and prepare SQL Server interview questions and answers. If you are looking for a job change or want to improve your interview skills, then you must go through with this article along with questions & answers given in this article. I have tried to answer each question in a very precise manner which most interviewers want to listen to these days.
Read more »
In this article, we will learn how to build metadata-driven pipelines using Azure Data Factory.
Read more »
In this article, we are going to understand the process to configure the ODBC driver for PostgreSQL. For the demonstration, I have installed PostgreSQL on my workstation. The details of the server and database are following:
Read more »
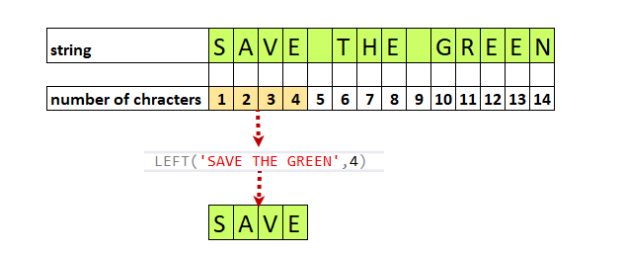
In this article, we will learn how to use SQL LEFT function with straightforward examples.
Read more »
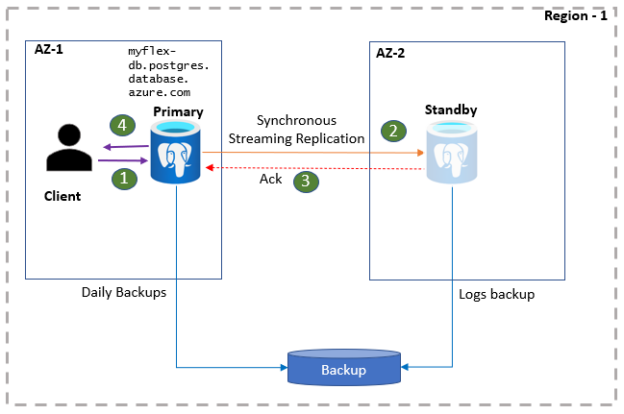
In this article, we will learn about the high availability features recently introduced in Azure Database for PostgreSQL.
Read more »

This article explains upgrading SQL Server Management Studio (SSMS) and Azure Data Studio (ADS) to their latest version with a single installation.
Read more »
This article will walk you through some SQL interview questions and answers to help you with a job change or if you want to improve your interview skills. I have also tried to attach supporting articles for each question to help you learn more in-depth about the specified topics. I tried to answer each question in a very precise manner which most the interviewers want to listen to these days. If you want to learn more about the topic asked, you can visit the attached link given for that question.
Read more »

In this article, we understand how to create a new database in Oracle 19c using a database configuration assistant. The database configuration assistant allows us to create a new database using a pre-defined template or create a database with various configuration options. In this article, we are going to learn both methods.
Read more »

In a typical database, we have multi lines or page SQL statements in a view, SQL statement or the stored procedure. Also, multiple developers change the T-SQL, and it becomes difficult to track who altered the code and for what reason.
Read more »
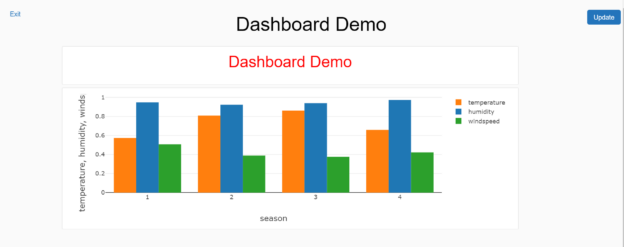
In this article, we will learn how to create dashboards using the data that is typically processed using notebooks in Azure Databricks.
Read more »
This article intends to give comprehensive information about the usage and other details of SQL check constraints.
Read more »

This article explores the Causality tracking option in the SQL Server Extended Events session(XEvents) and its usefulness in troubleshooting performance issues.
Read more »
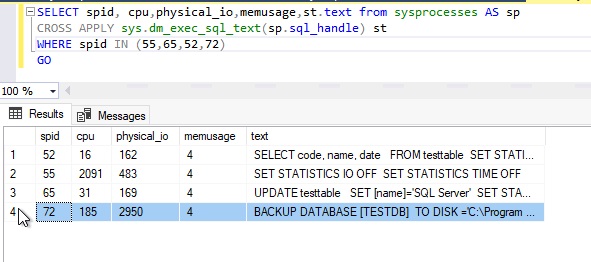
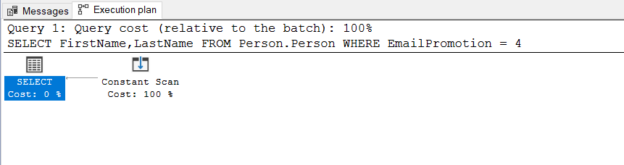
Transparent Data Encryption (TDE) encrypts database files to secure your data. It also encrypts the tempdb database to secure your data in a temporary space. The process of encryption and decryption adds additional overhead to the database system. Even non-encrypted databases hosted on the same SQL Server instance would have some performance degradation because of tempdb encryption. Today I will show you performance impact analysis using few simple T-SQL statements by comparing their stats gathered before and after enabling TDE.
Read more »
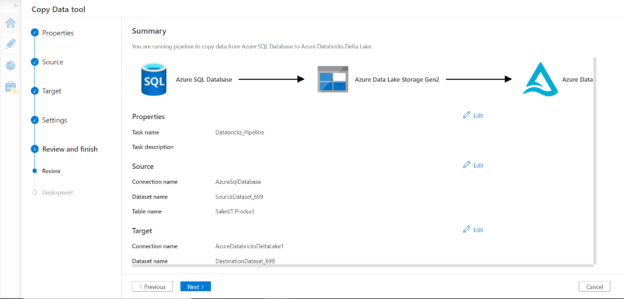
In this article, we will learn how to populate delta lake tables into Azure Databricks from Azure SQL Database using Azure Data Factory.
Read more »

In this article, we understand the step-by-step installation process of Oracle 19c on Windows Server 2019. The minimum hardware requirement to install an Oracle database server is following:
Read more »
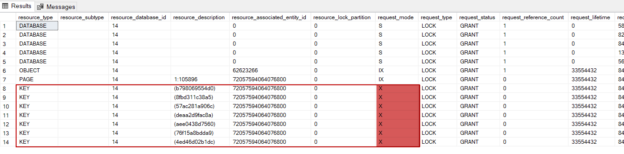
In this article, we will learn how to monitor SQL Server blocking issues with different methods.
Read more »
In this article, we will learn how to create a delta table format in Azure Databricks.
Read more »

In this article, we are going to understand the various types of Power BI time calculations and how to implement these calculations. We will also understand the reason behind implementing such time-based calculations and the importance of these in the real world. The Power BI time calculations are also known as Time Intelligence functions that can be applied in DAX. There are a lot of functions available under Time Intelligence and you can read about it in detail from the official documentation from Microsoft.
Read more »

This article covers an overview of SQL Server logs for monitoring and troubleshooting issues in SQL Server.
Read more »© Quest Software Inc. ALL RIGHTS RESERVED. | GDPR | Terms of Use | Privacy