
In this article, we will learn how to build metadata-driven pipelines using Azure Data Factory.
Introduction
The data management approach has evolved over the years in many iterations like Online Transactional Processing (OLTP), Data warehousing and Data Marts, Online Analytical Processing (OLAP), Data Lakes, and finally Data Lakehouse concept that is gaining popularity in the era of cloud. While there are varied types of data management platforms and products and equally varied approaches to align these tools and technologies to manage data, one artifact that is central to all of these is intelligent data pipelines. As data grows out of the bounds of relational and structured data models, there is an increased need for data pipelines to be metadata-driven which will be particularly useful to deal with the variety and volume of data that is typically found on data lakes on the cloud.
One primary challenge with data pipelines that manifest with time is that data pipeline development starts at a modest level with point-to-point connectivity from source to destination. As the scale of data grows and the schema of the data objects changes over time, it becomes increasingly challenging and inefficient to match the pace of developing new point-to-point data pipelines as well as maintain existing data pipelines. At the least, data pipelines that deal with just ingesting data from newer data objects can be made metadata-driven as a starting point to reduce the number of identical data pipelines that are just different in terms of source and destination. Azure cloud supports a variety of data management products and platforms, which can be a source or destination from a data pipeline perspective. Azure Data Factory is the primary offering from Azure to build data pipelines and we will see how can create metadata-driven pipelines using it.
Pre-Requisites
Let’s say that we have a use-case where we have a bootstrap data lake on Azure cloud that is formed of just Azure Blob store or Azure Data Lake Storage where data from multiple sources is collated, cataloged, and curated. We have an Azure SQL server as one of the downstream systems that need part of the data from this data lake for a certain type of data processing. These destinations can be anything like Azure Synapse, Azure Databricks Delta Lake or any third-party data management products that are not native to Azure. For simplicity, we are considering Azure SQL Server as the data source. We intend to build metadata-driven pipelines that will source data files of interest from the data lake to the Azure SQL Database using Azure Data Factory.
As a pre-requisite, it is assumed that one has an Azure cloud account with the required privileges to administer the services that will be used in this article. We need to have an Azure Blob Storage account created with at least of data file hosted in a folder on this account. We also need an Azure SQL Server account created with one Azure SQL Database created in it, which will act as the destination in this case. We need to have an Azure Data Factory workspace created using which we will access the Azure Data Factory Studio from where we will author our metadata-driven data pipeline. It is assumed that this setup is in place with all the services configured with firewall rules to allow access to each other.
Developing Metadata Driven Data Pipelines
Once we are on the Azure Data Factory portal, we would be able to see the home page as shown below. We intend to develop a data pipeline to ingest data from the data lake, so we will select the option of Ingest as shown below.
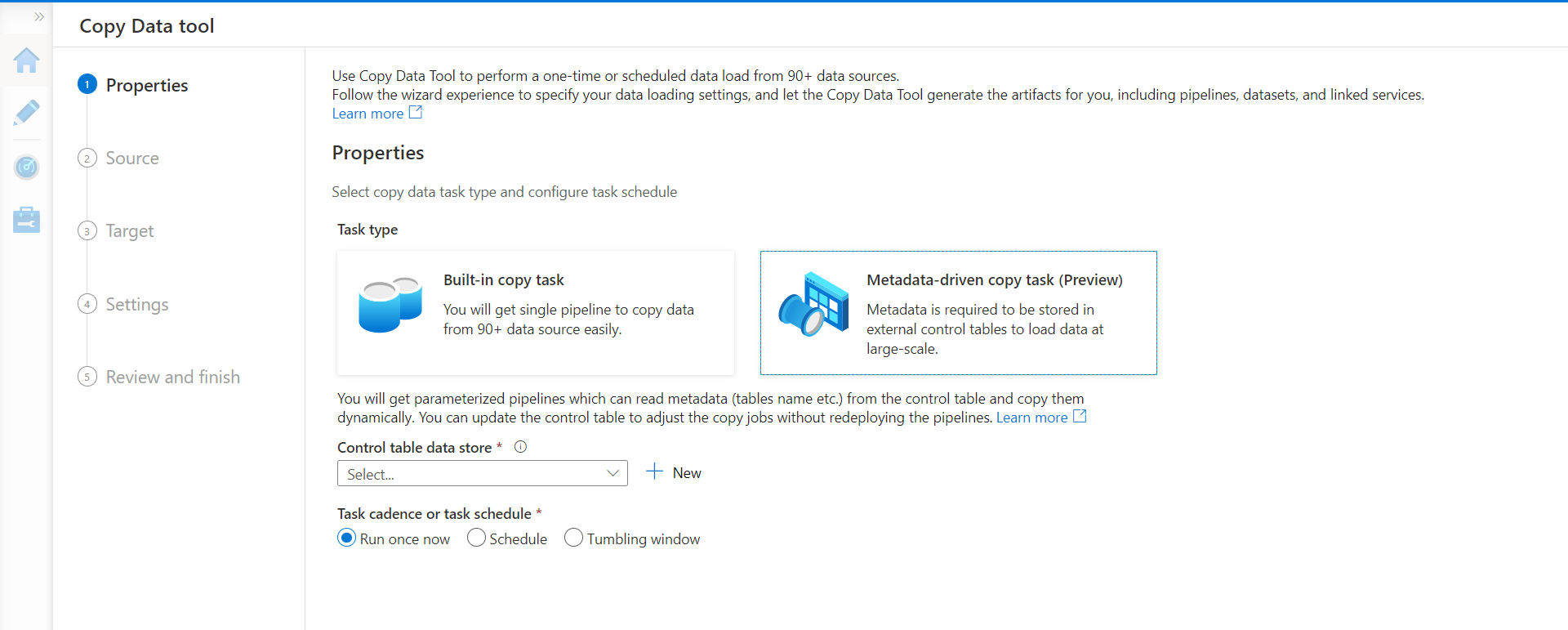
It will invoke the copy task wizard as shown below. We will get the option of authoring a data pipeline or data task using the built-in copy task that is ideal for importing data or data objects from data sources. But this will create a point-to-point data pipeline. In our case, we wish to create a metadata driven data pipeline in Azure Data Factory, so we will go with the metadata-driven copy task as shown below.
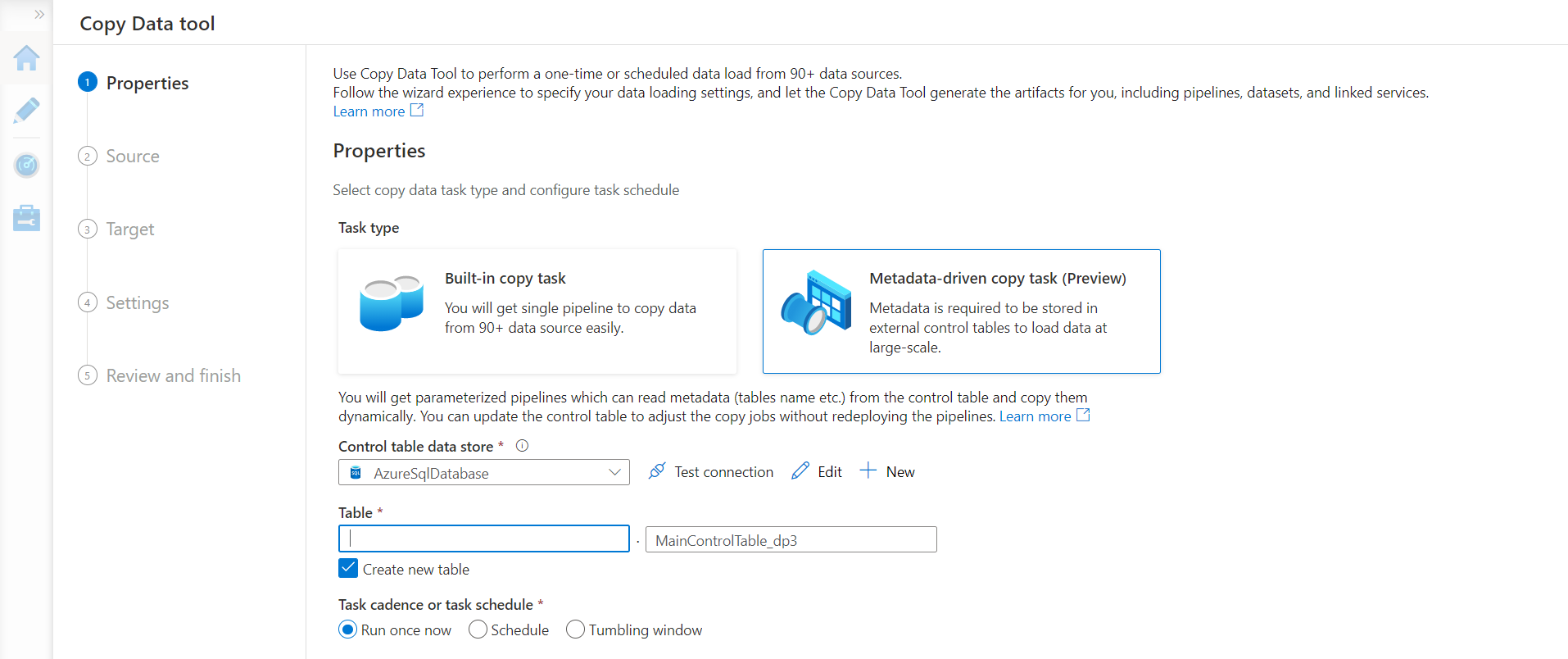
After selecting metadata-driven option, next, we need to create a control table that will hold the metadata definition of the database objects that we intend to source. When our pipeline will get created, it will be parameterized that will read the definition of objects from this table and dynamically source data as well as data objects from the source, making it metadata-driven. Provide the datastore where we intend to create the new table. We can click on the new button, register the Azure SQL Database that we have in place and use it as a data store for the control table as shown below. We intend to create a new table, so we can provide the schema name as well as the name of the table. Provide the appropriate name and schedule and navigate to the next step.
In this step, we need to register the data source. Shown below are the variety of data sources that are supported by Azure Data Factory.
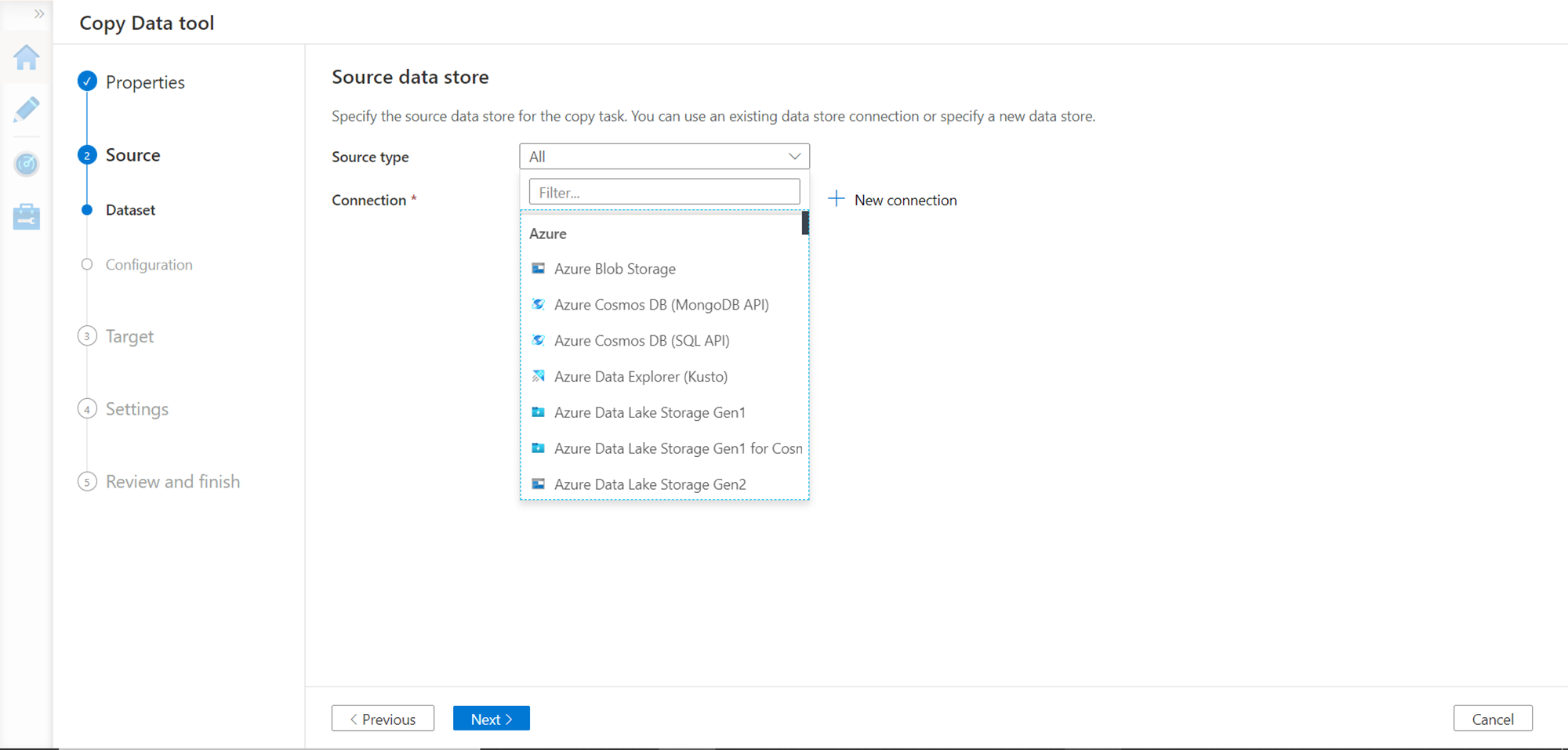
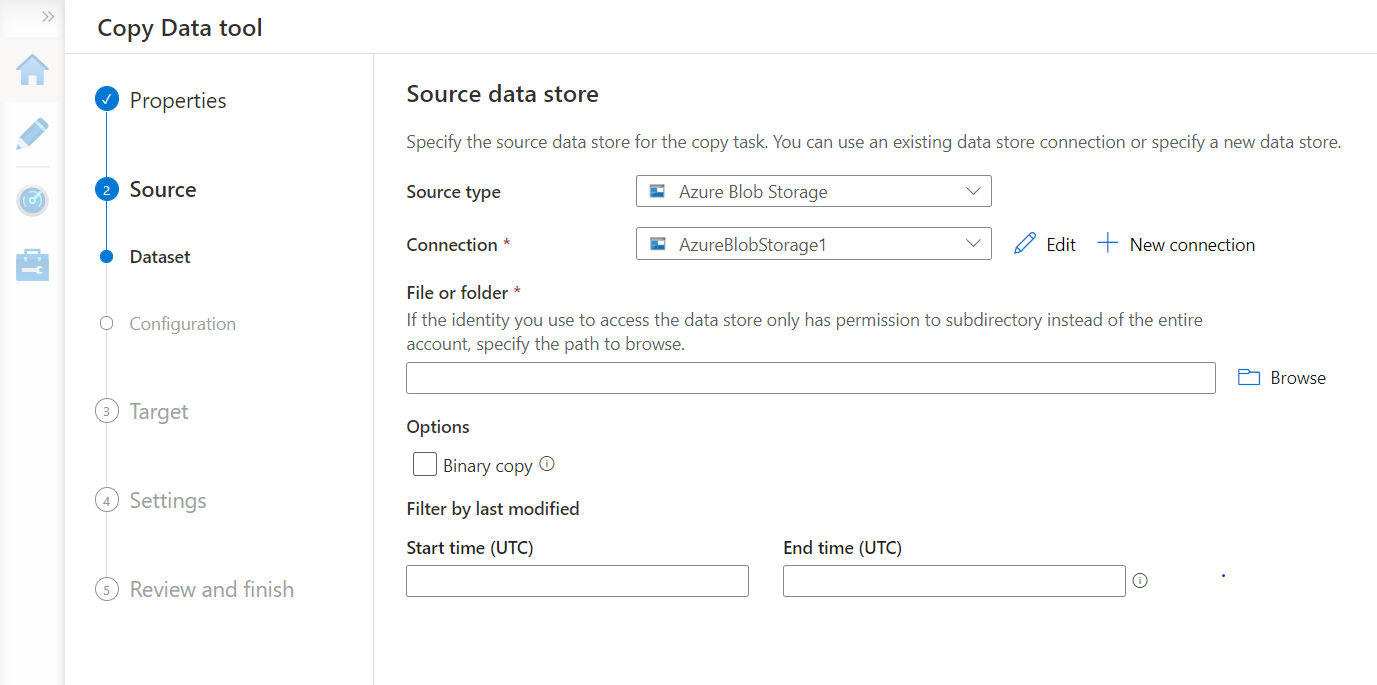
Let’s say we intend to use Azure Blob Storage as our data source where we may have a large volume of data files. Select the same as source type, register the address of the Azure Blob Storage by creating a new connection, and then we would be presented with the details to specify the address of the file or folder from where we intend to source data objects. Select the data file by clicking on the browse button and click on the Next button.
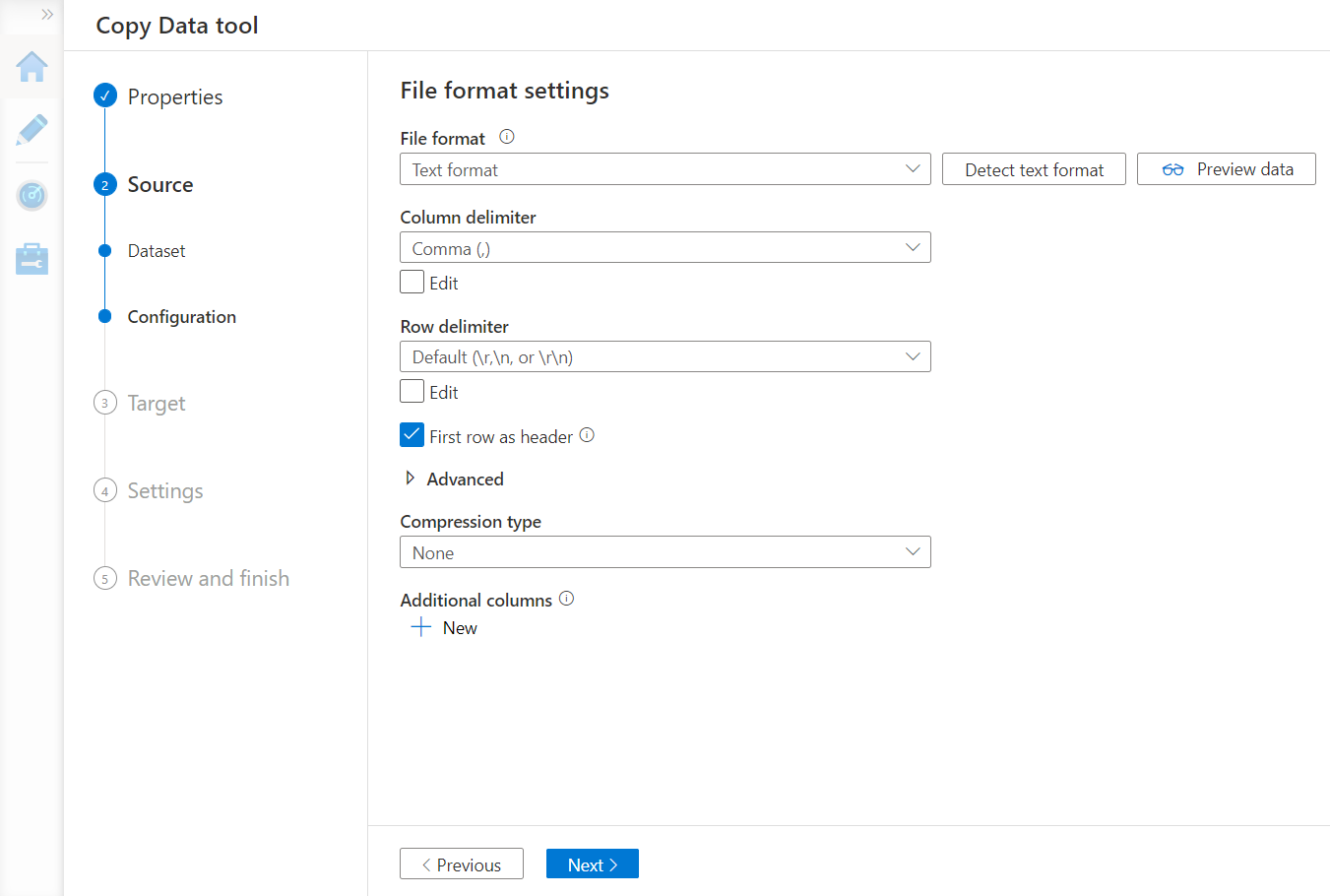
In this step, assuming we selected the data file in the last step, the format of this file should get auto detected and we should be able to preview the data as well. If the data is not being read as intended, we can configure additional settings like delimiters, compression types etc. Once we ascertain that data is being read as desired, we can navigate to the next step.
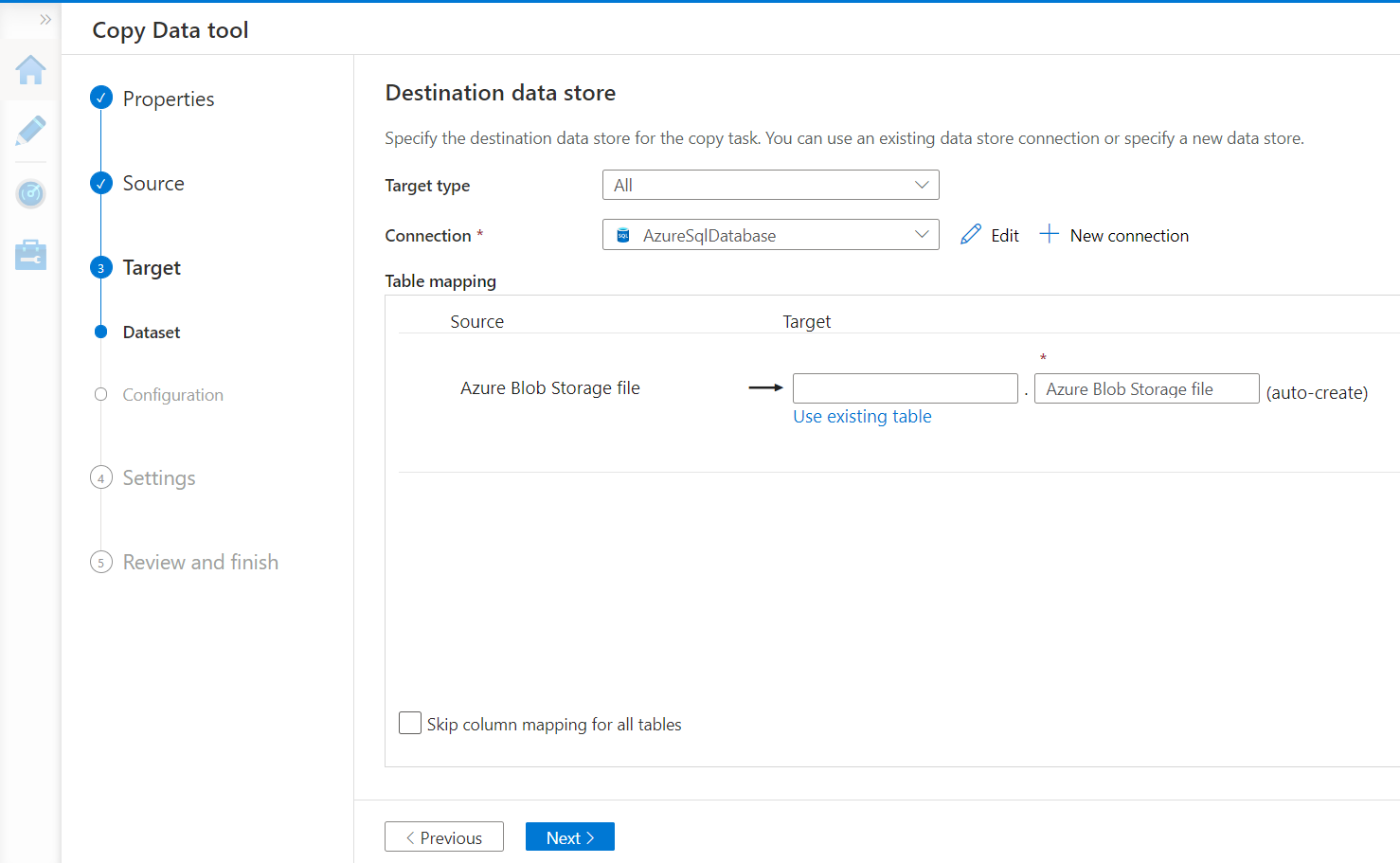
Now we need to register the destination datastore which is Azure SQL Database in our case. Select the relevant destination type and register its address by creating a new connection as we did in the previous step. Once done, it would look as shown below. We intend to create a new table in the Azure SQL Database as every time a new type of data object or data file may land on the data lake, we may want to create a new table in the Azure SQL Database. Provide the schema and name of the new table that should get created in the Azure SQL Database to host the data being imported. Once done, navigate to the next step.
We can optionally modify the column mappings if required. For now, we can continue with the default mappings as we are creating a new table and the columns in the destination table would be identical as the source.
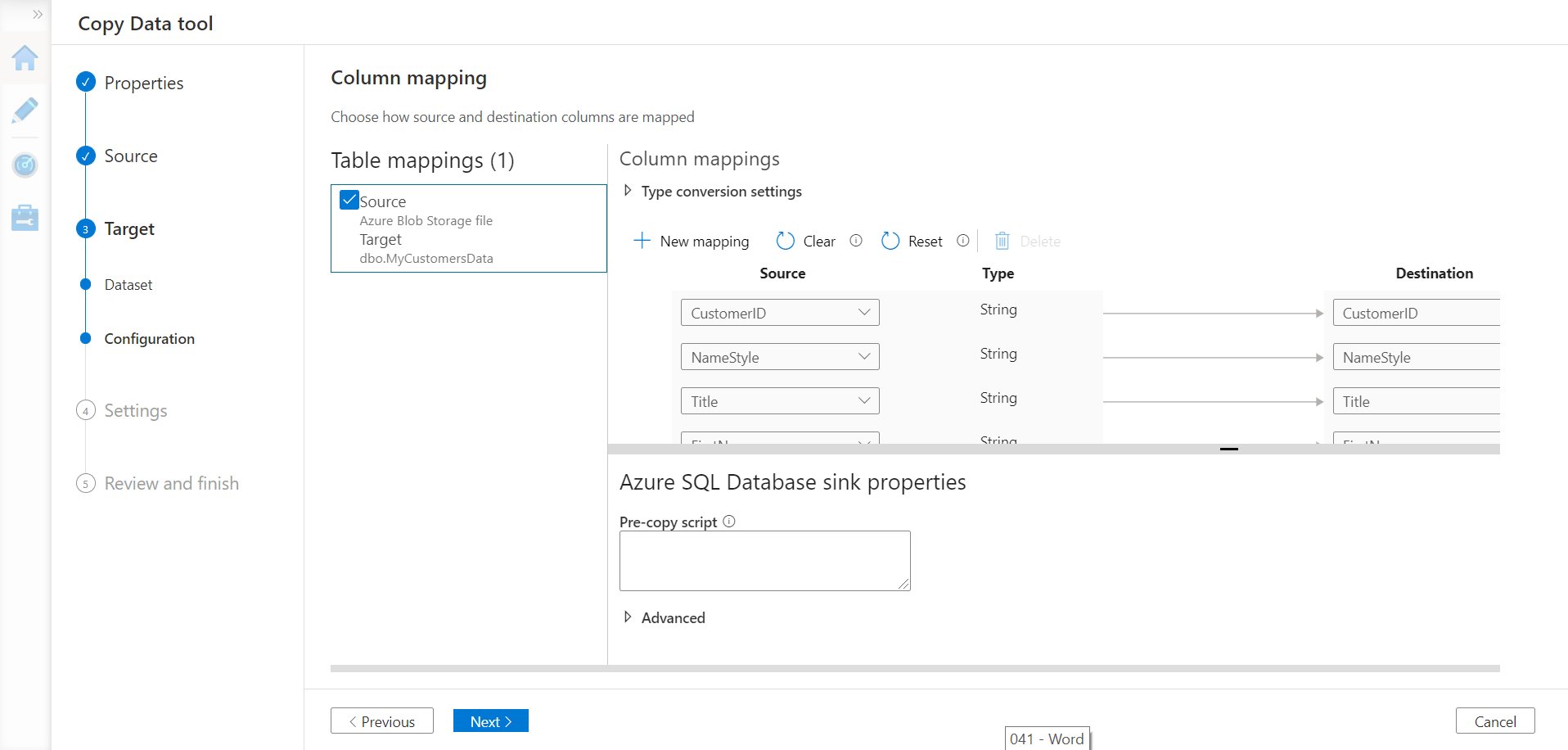
Now we need to configure the settings to provide a name to the task being created with some optional description. From the advance settings, we can also configure data consistency checks that the pipeline can perform after the core part of data pipeline execution is complete.
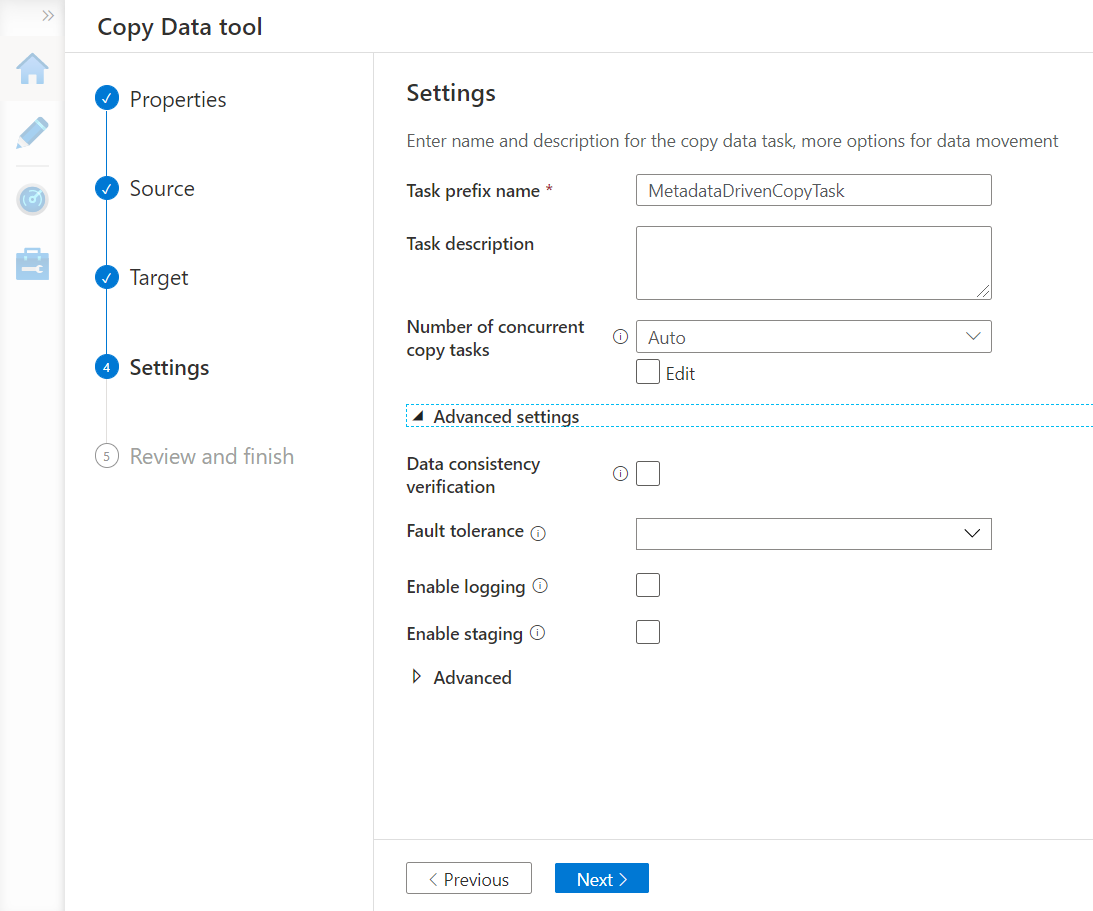
In the summary section, we can now review all the details that we have configured so far. Once done, we can navigate to the next step.
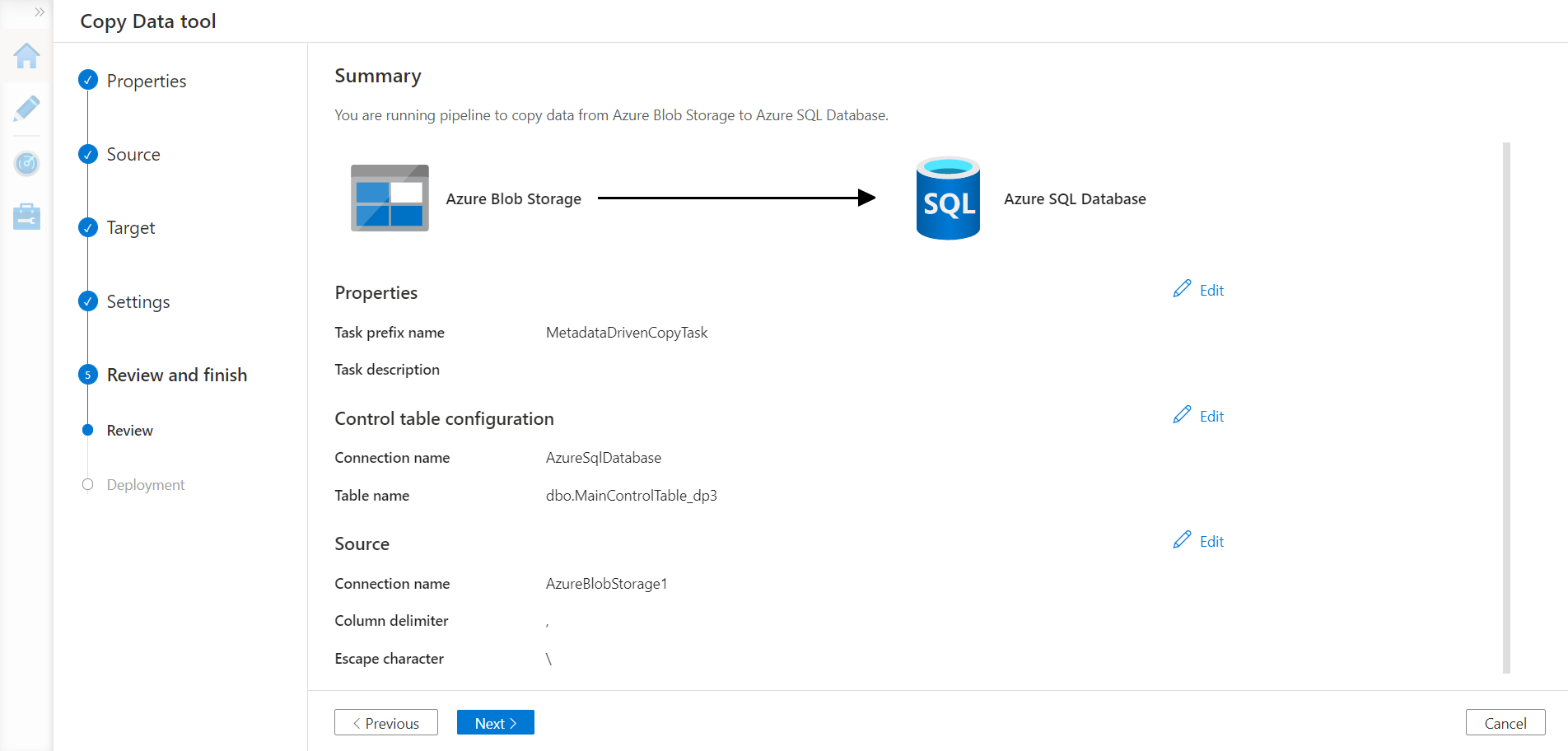
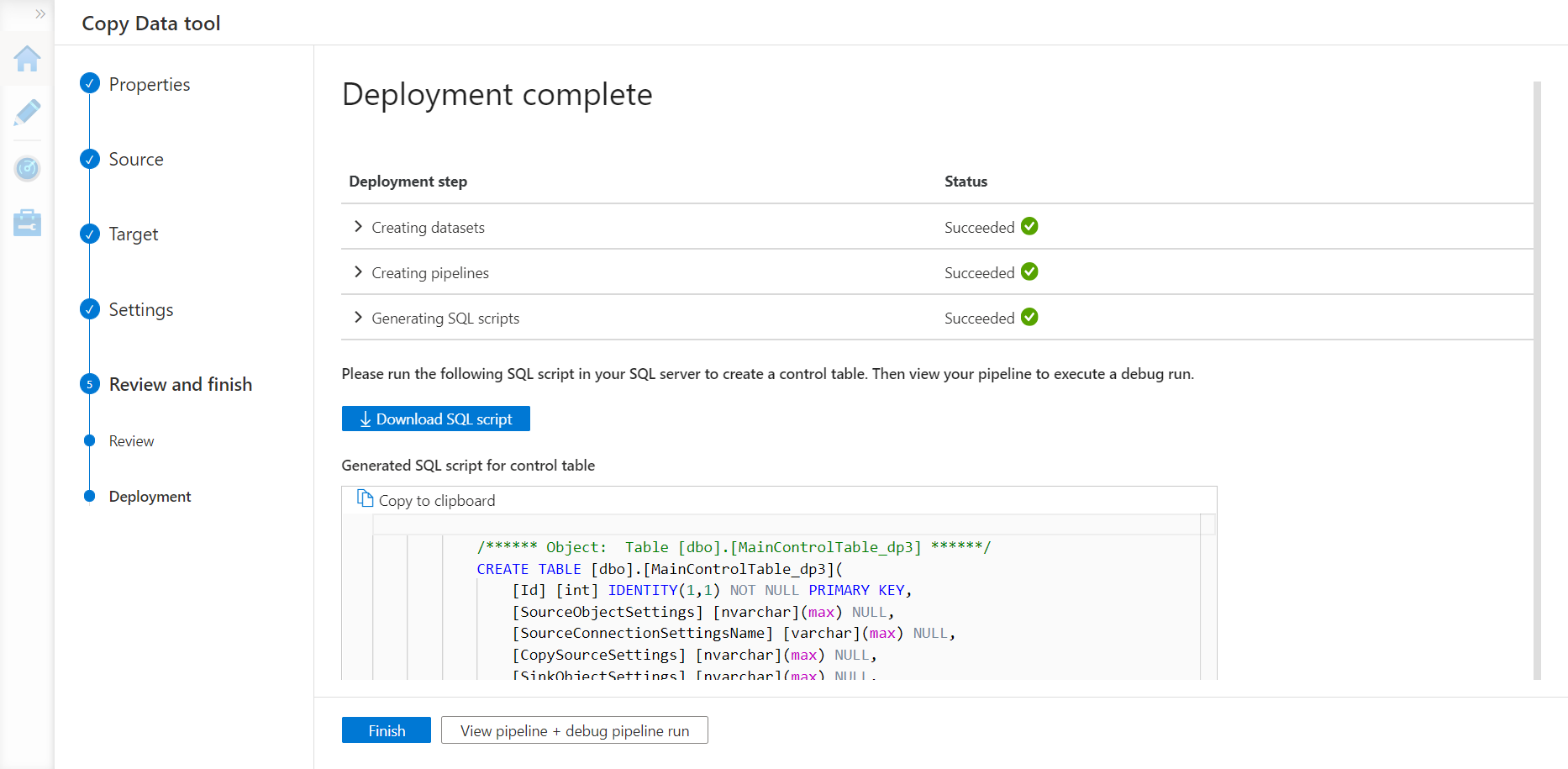
In this step, the wizard would register new datasets, data pipelines and generate SQL scripts to create the control table in the Azure SQL Database with the script generated as shown below.
We can view the three different tasks as well as the parameterized data pipeline that got created from the wizard by navigating to the data pipelines section as shown below.
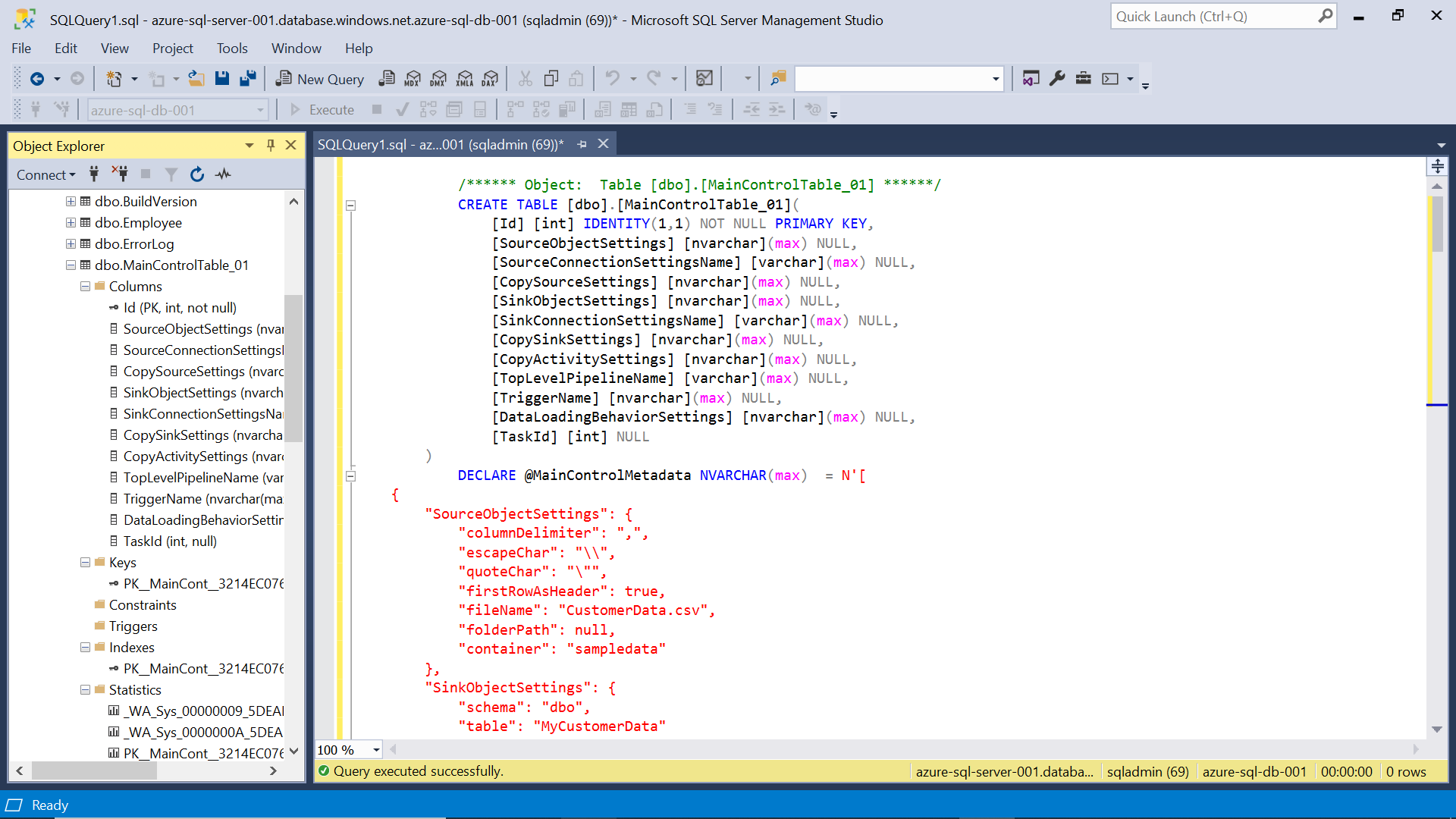
Copy the script that got generated earlier and execute the same script on your Azure SQL Database instance by using SQL Server Management Studio (SSMS). Once executed, it would create a new control table as shown below in the browser pane.
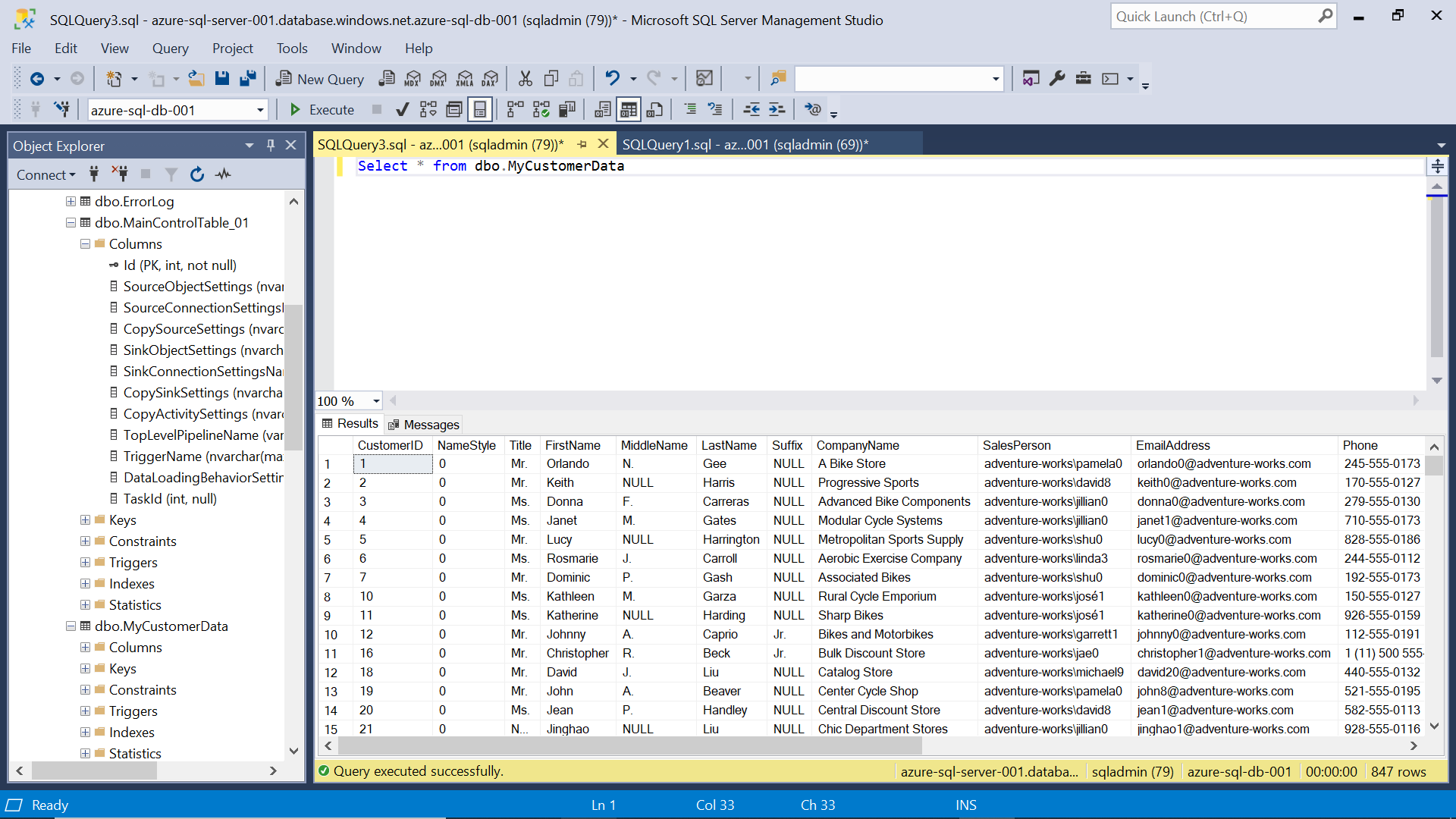
Navigate back to the Azure Data Factory portal, add a trigger to the data pipeline and execute the same. Once the execution is complete, you would find a new table created in the Azure SQL Database which would have identical schema and data as the source file hosted in Azure Blob Storage, as shown below.
For any subsequent database objects that we intend to source using this pipeline, we just need to add or update the relevant record in this control table, and the data pipeline would read the parameters from this table and perform the action accordingly. In this way, we can create metadata-driven data pipelines using Azure Data Factory.
Conclusion
In this article, we learned the importance and utility of developing metadata-driven data pipelines versus point-to-point data pipelines. We used Azure Blob Storage as the source and Azure SQL Database as the destination and learned to develop a metadata-driven data pipeline using Azure Data Factory.

She has a deep experience in designing data and analytics solutions and ensuring its stability, reliability, and performance. She is also certified in SQL Server and have passed certifications like 70-463: Implementing Data Warehouses with Microsoft SQL Server.
View all posts by Gauri Mahajan
- Oracle Substring function overview with examples - June 19, 2024
- Introduction to the SQL Standard Deviation function - April 21, 2023
- A quick overview of MySQL foreign key with examples - February 7, 2023