
In this article, we will learn about the high availability features recently introduced in Azure Database for PostgreSQL.
Introduction
Databases host transactional, analytical, relational, structured, semi-structured, key-value, document, and various types of data formats. Despite the varied data types that can be hosted in databases, there are some aspects of databases that are common from a data consumption perspective like data security, data governance, data availability etc. Depending on the nature of data and the nature of consumption, some types of data availability are not too time-critical and can be processed as well as provisioned with the luxury of time. But many types of data typically transactional data or data that is critical for decision making can be very time critical and requires high availability. Any downtime caused by events like server failure, connectivity failure etc. which makes the data unavailable can be unacceptable as well as can cause high business impact. For this reason, high availability remains one of the top priority features while designing data solutions.
To address high availability, different types of approaches are used like data replication and synchronization, server failover, DNS swapping etc., to address the event when the primary server hosting the data is unavailable. The general solution employed by almost all the databases is to create one or more replicas that are made available when the primary falls out of place. Azure cloud platform offers a variety of database services like Azure SQL, Azure Database for MySQL, Azure CosmosDB, Azure Database for PostgreSQL and others. This article will help us understand high availability features for Azure Database for PostgreSQL.
Creating an Azure Database for PostgreSQL instance
The first step towards exploring the high-availability features in Azure Database for PostgreSQL is creating an instance of it. It is assumed that one has the required access to the Azure cloud platform with the privileges to administer Azure Database for PostgreSQL service. Navigate to the dashboard of Azure Database for PostgreSQL and click on the Create button. This will invoke a new wizard for database creation as shown below. The first step is to select the edition of the PostgreSQL server which we intend to create. Four editions are offered to create PostgreSQL instances – Single server, Flexible server, Hyperscale server, and Azure Arc enabled PostgreSQL as shown below.
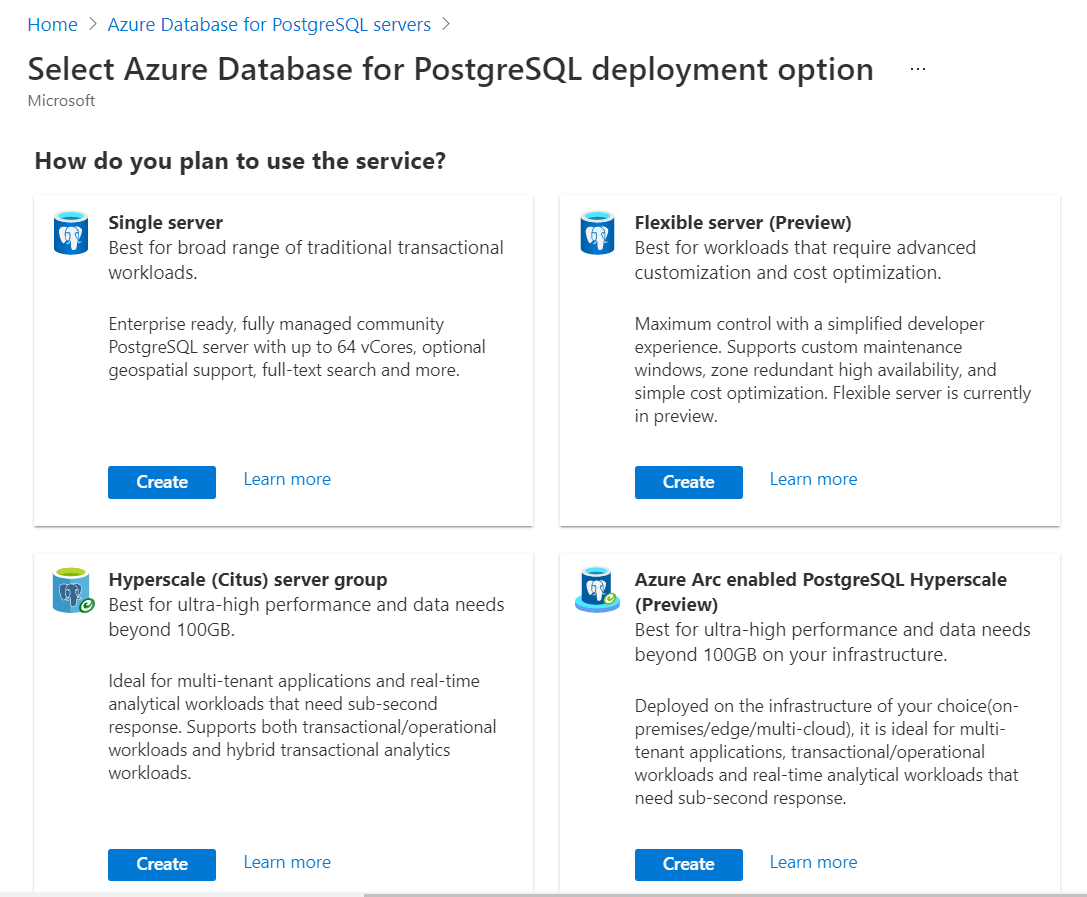
We intend to create a high-availability configuration, so we need to select the Flexible Server option. If we select the Single Server option, it does not offer high availability features as of the draft of this article. Once we select this option, we would be navigated to a screen as shown below. Provide the primary details of the instance like subscription, resource group, server name and region. For our use case, we can continue with Development as the option as well. By default, the selected option is Production as shown below.
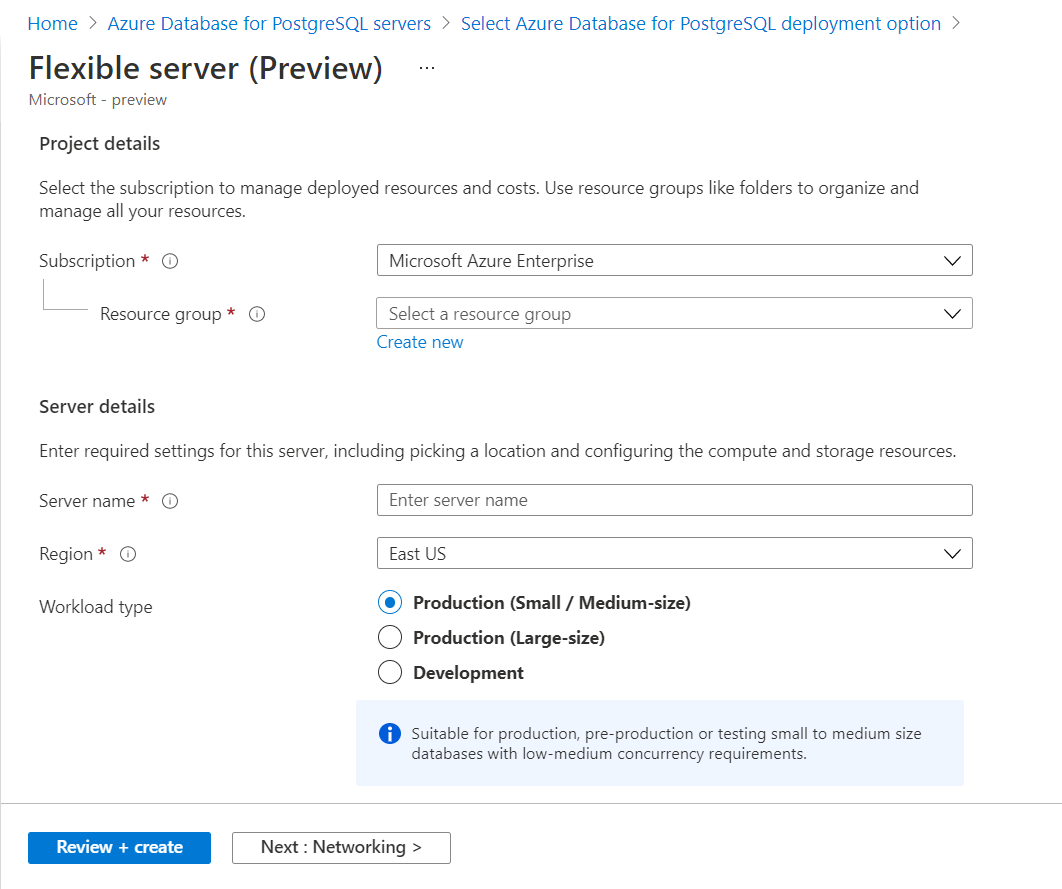
Scroll down and you would find the rest of the details as shown below. We can select the compute and storage capacity as desired. For now, we can continue with the default options for capacity, availability zone, and PostgreSQL version.
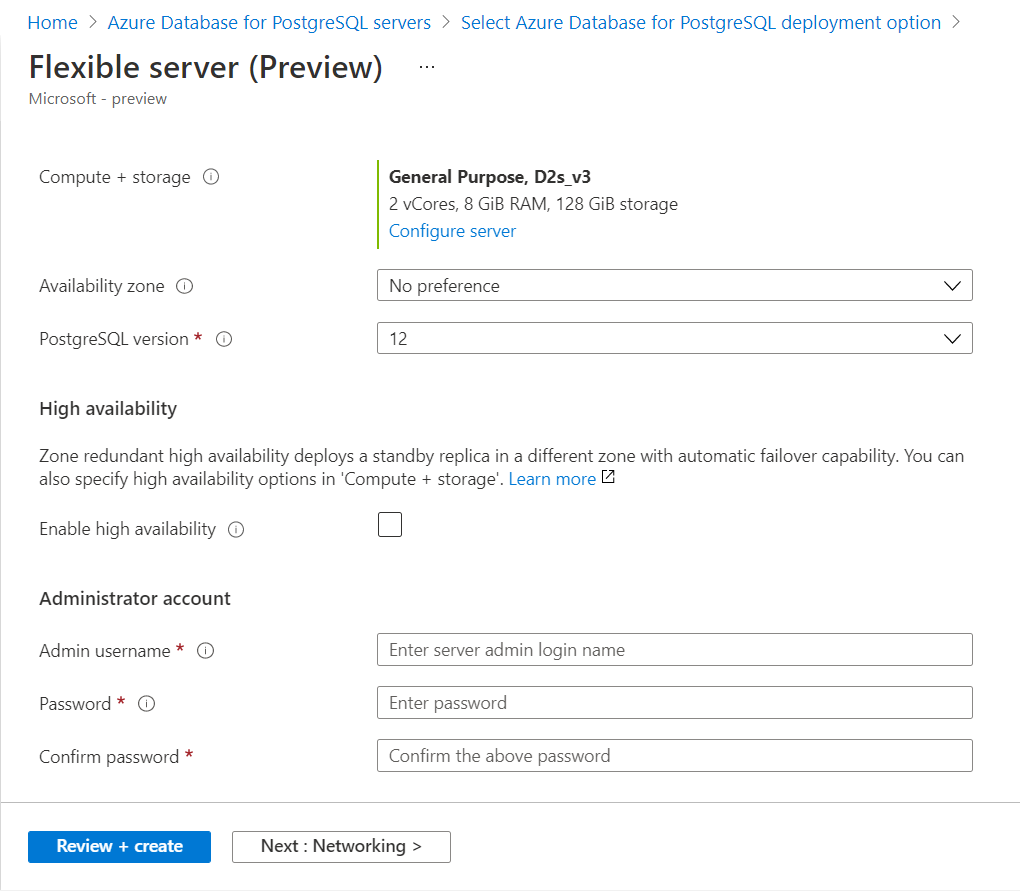
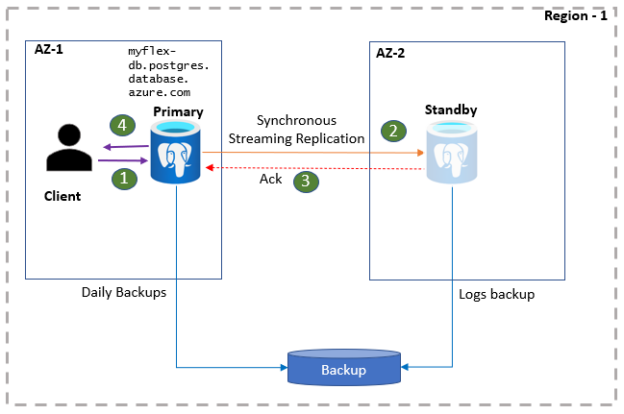
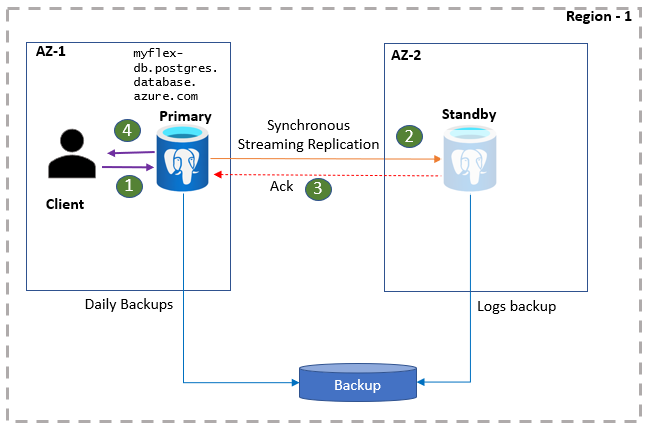
The next section of configuration is the High Availability section. It is not enabled by default as shown above. If we choose the enable the high availability configuration, it will create a standby replica of the primary instance in a separate availability zone with an automatic failover configuration. This means that the replication and synchronization between primary instances, as well as standby instances, are managed by Azure Database for PostgreSQL service. The monitoring of the primary instance for availability and switching over to the standby instance which is also known as failover is also performed by the Azure Database for PostgreSQL server. We do get the option to choose when to perform failover, as well as test the failover experience to understand what to expect and how to manage the systems that are dependent on the database instance when failover happens. We will understand that in the latter part of this article. A diagrammatic representation of the high-availability and failover process is shown below.
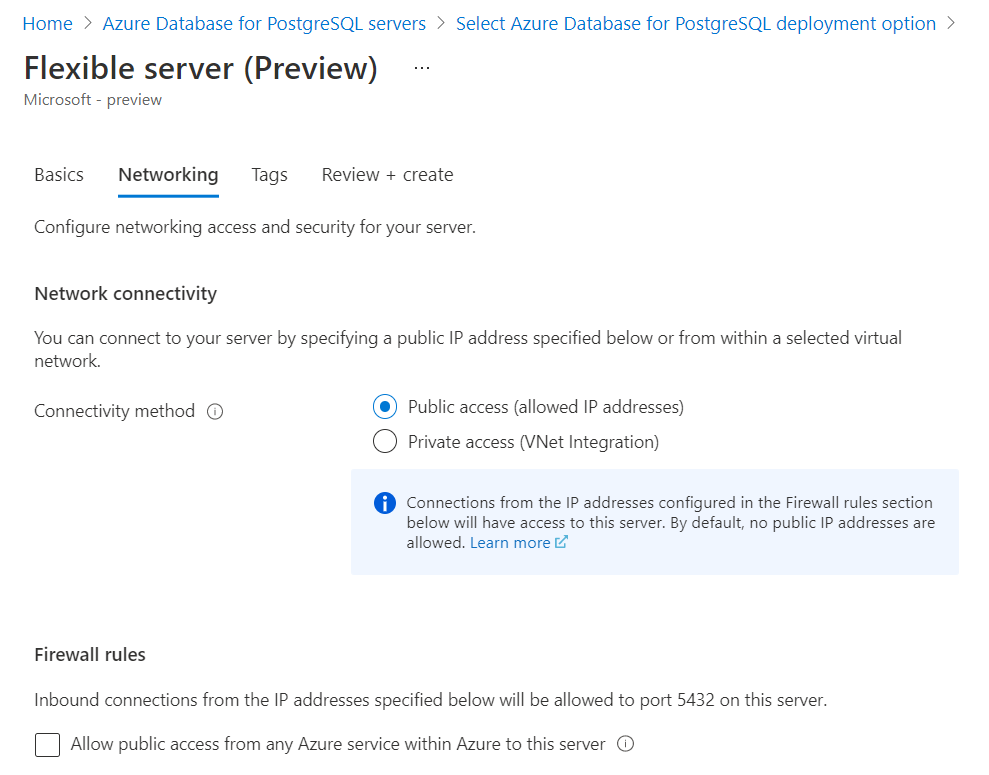
After enabling the high availability configuration, provide the username and password-related details for the instance and click on the Networking button. In this section, we need to configure the network connectivity. By default, public access is selected. We can continue with this mode of connectivity as for our exercise we need to connect to this instance possibly from a local machine. We would also need to add our machine i.e., the client IP to the firewall settings to allow incoming connections from our local machine to the instance being created. After this configuration is done, we can optionally add tags to the instance configuration and finally review the configuration and initiate the creation of the new instance.
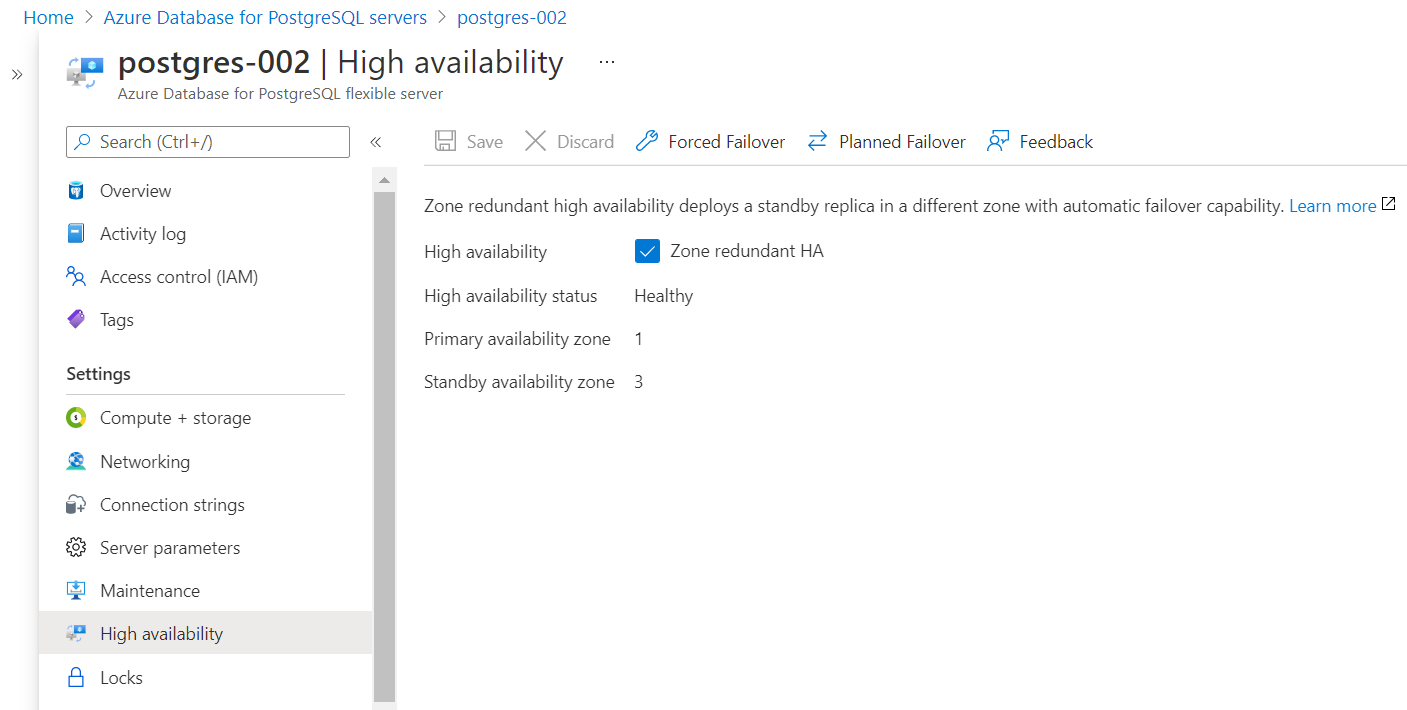
Create a button to create a new instance. It may take a few minutes for the database instance to get created with the high availability configuration activated. After the instance gets created, navigate to the dashboard of the instance and you would find a menu item on the left pane of the dashboard named High availability. Click on this item and you would find the details as shown below.
Once the high-availability configuration is in place, the focus shifts on planning the failover and building readiness of other systems to align during the failover process. Downtime can be planned as well as unplanned depending upon the circumstances that cause the downtime. When failover happens, the connection to the primary instance may cease after a while and the subsequent connections will be routed to the standby instance which would now become the primary instance. And a new standby instance would be created. This process is explained in the diagram shown below.
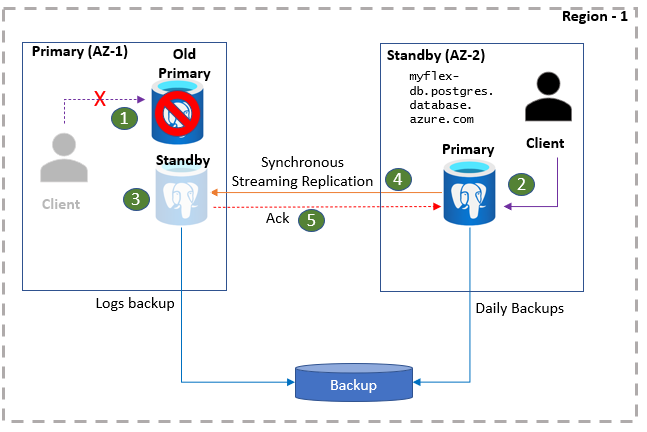
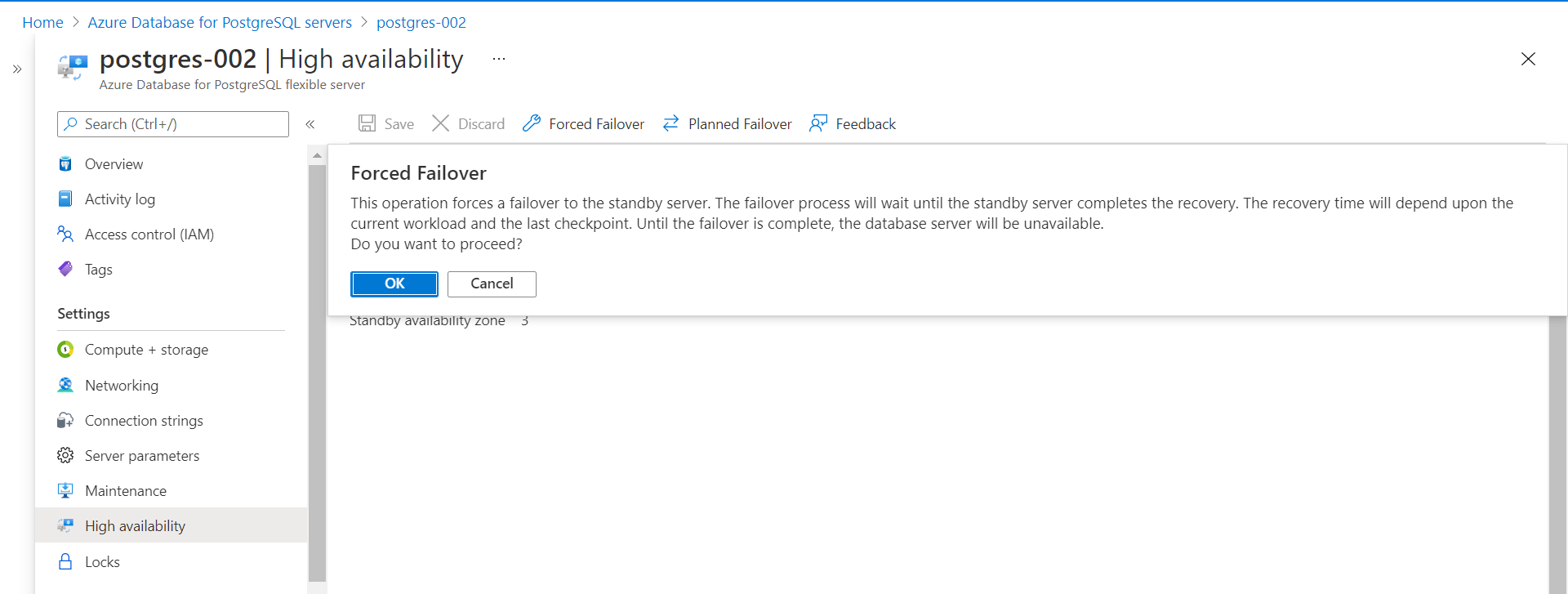
The above-shown failover process happens in case an unexpected event occurs that would take down the primary instance. But at times, one would want to failover in a planned manner as well – for the purpose of testing how to respond in the event of a failover or perform a failover during a scheduled time so that the rest of the systems are not impacted due to an untimely failover. These features are offered on the high availability page as shown above earlier. Let’s say that we want to initiate a forced failover to test the impact that how the upstream and downstream applications that integrate with data pipelines or directly with the instance will be impacted during failover. For such analysis, we can initiate a forced failover by clicking on the Forced Failover button. It would invoke a pop-up with information as shown below.
The pop-up would clearly state that the failover process would switch the primary instance to the standby instance. There would be downtime and the lead time for recovery may vary upon the ongoing operations and last database checkpoint, and the database will be unavailable in the meantime as well. Click Ok to experience what will happen when the failover is in progress and record the time it takes for the failover to complete. To test when the instance is reachable and unreachable, one can use a utility like pgAdmin to connect to the instance.
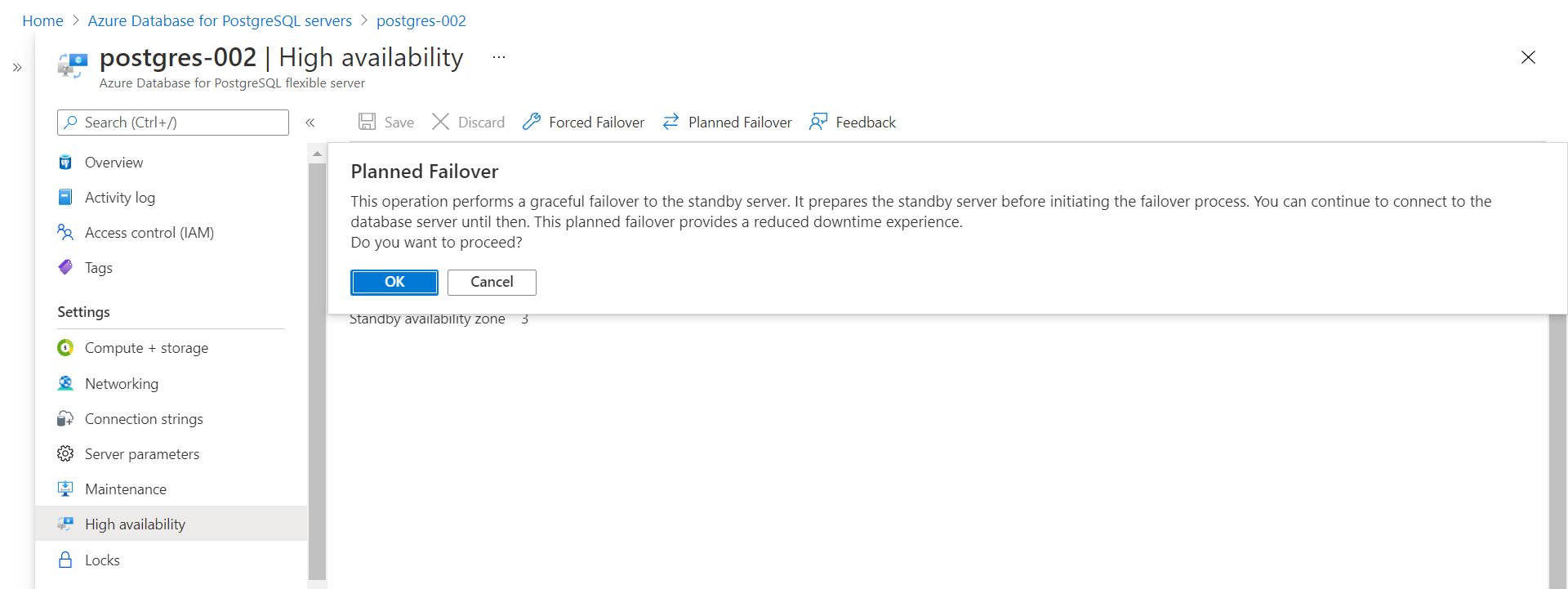
Another mode of planned failover is Planned Failover. We can click on the Planner Failover button and it would show a pop-up as shown below. This mode of failover is a more graceful form a failover and the failover does not need to happen instantly. The standby server will be prepared first and then the switch would happen. This helps in reducing the downtime as the primary instance will not be down instantly and as soon as the switch would happen, within seconds the instance should be available. Consider testing the downtime using a utility like pgAdmin to assess the difference in the downtime between Forced Failover which is a sudden failover versus Planned Failover which is a slower but more graceful failover.
These new failover options in Azure Database for PostgreSQL provide options to test the impact of a failover as well as plan the failover.
Conclusion
In this article, we learned the importance of high availability as well as database failover. We explored the way to configure high availability in Azure Database for PostgreSQL and learned about the new failover testing option that has been newly introduced in Azure Database for PostgreSQL to test and plan the failover process.

She has a deep experience in designing data and analytics solutions and ensuring its stability, reliability, and performance. She is also certified in SQL Server and have passed certifications like 70-463: Implementing Data Warehouses with Microsoft SQL Server.
View all posts by Gauri Mahajan
- Oracle Substring function overview with examples - June 19, 2024
- Introduction to the SQL Standard Deviation function - April 21, 2023
- A quick overview of MySQL foreign key with examples - February 7, 2023