
In this article, we will learn how to create a delta table format in Azure Databricks.
Introduction
In modern data engineering, various file formats are used to host data like CSV, TSV, parquet, json, avro and many others. With the proliferation of data lakes in the industry, data formats like delta and hudi also have become very popular. Data platforms like Databricks have positioned delta format at the center of their data lake paradigm and is popularly known as Delta Lake. Azure Databricks supports creating tables in a variety of formats mentioned above including delta. While Databricks supports many platforms, to consume the tables created on this platform with external Azure services, many of them require the table format to be of delta format.
What is a delta lake table in Azure Databricks?
Delta lake is an open-source data format that provides ACID transactions, data reliability, query performance, data caching and indexing, and many other benefits. Delta lake can be thought of as an extension of existing data lakes and can be configured per the data requirements. Azure Databricks has a delta engine as one of the core components that facilitates delta lake format for data engineering and performance. Delta lake format is used to create modern data lake or lakehouse architectures. It is also used to build a combined streaming and batch architecture popularly known as lambda architecture.
One of the unique advantages of data formats like delta lake or apache hudi is time travel. As data keeps changing, one may want to preserve the history of data. Typically to preserve history, methods like Slowly Changing Dimension or creating pools of archive table are being used. With large volumes of data, manually managing data versioning can become a challenge over time. Also hosting historical data as well as active data in the same repository can have an impact on the query performance. At times, when there is a need to revert to an older version of data for different business or technical reasons, it would need a significant backup and restore operation. To add to the complexity, if one needs to view the older version of data or the chronological change in data over time, it is hard to facilitate the solution without a use-case specific setup with required additional times and resources. This feature is one of the many spectacular features in storage formats like delta lake where one can seamlessly execute time-travel queries that are facilitated by advanced data versioning provided by delta engine on delta lake format.
Creating Delta Lake tables
In this exercise, we would be using a sample CSV file as the source to create a delta format table in Azure Databricks. For this purpose, we first need an Azure account with the required privileges to create an Azure Databricks workspace. It is assumed that an Azure account is already in place.
Open the Azure portal, navigate to the Azure Databricks service dashboard, and click on the Create button to create a new instance. Provide the required details like subscription, resource group, pricing tier, workspace name and the region in which the instance will be created. Using the standard tier, we can proceed and create a new instance.
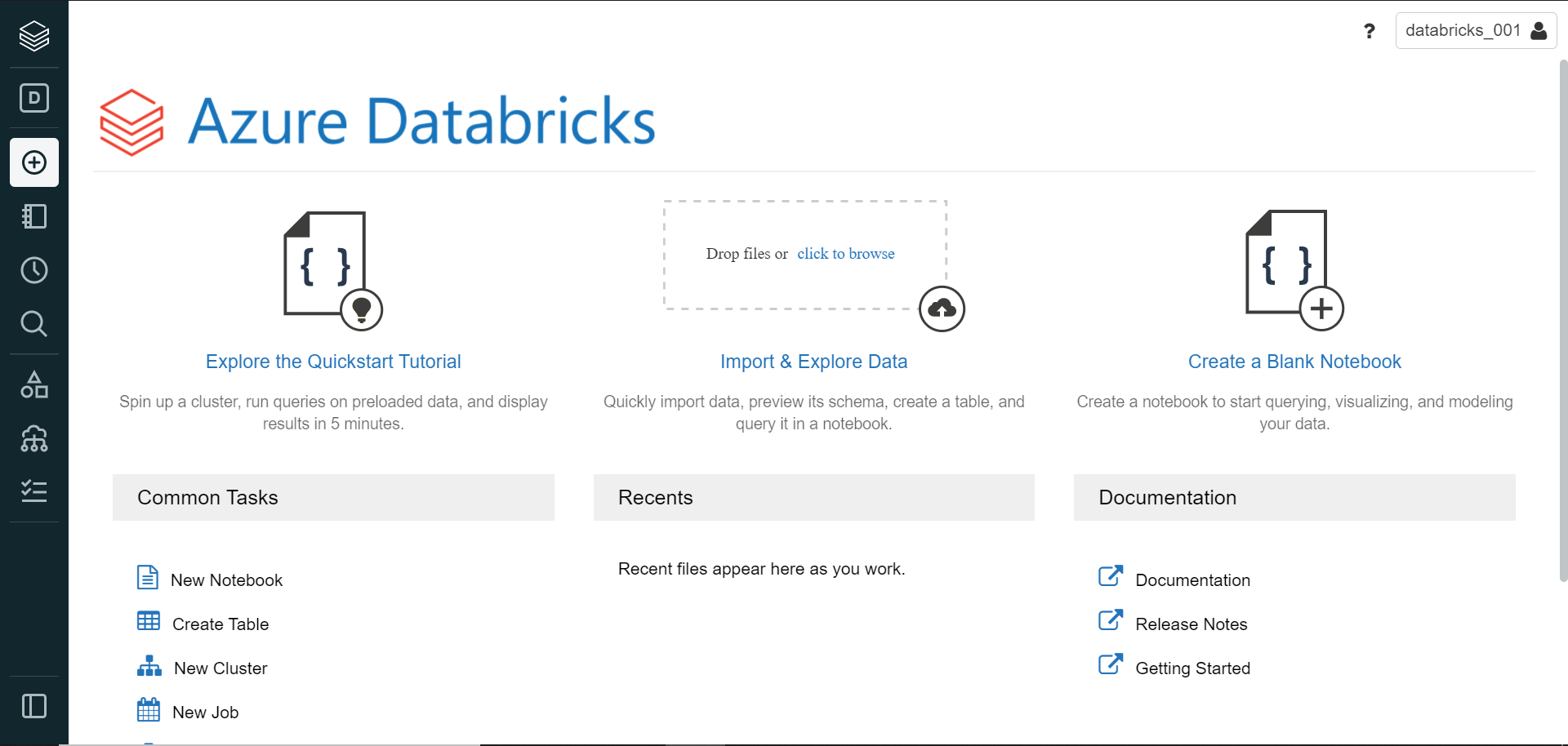
Once the Azure Databricks instance is created, launch the workspace which would open in a new window with the home page as shown below.
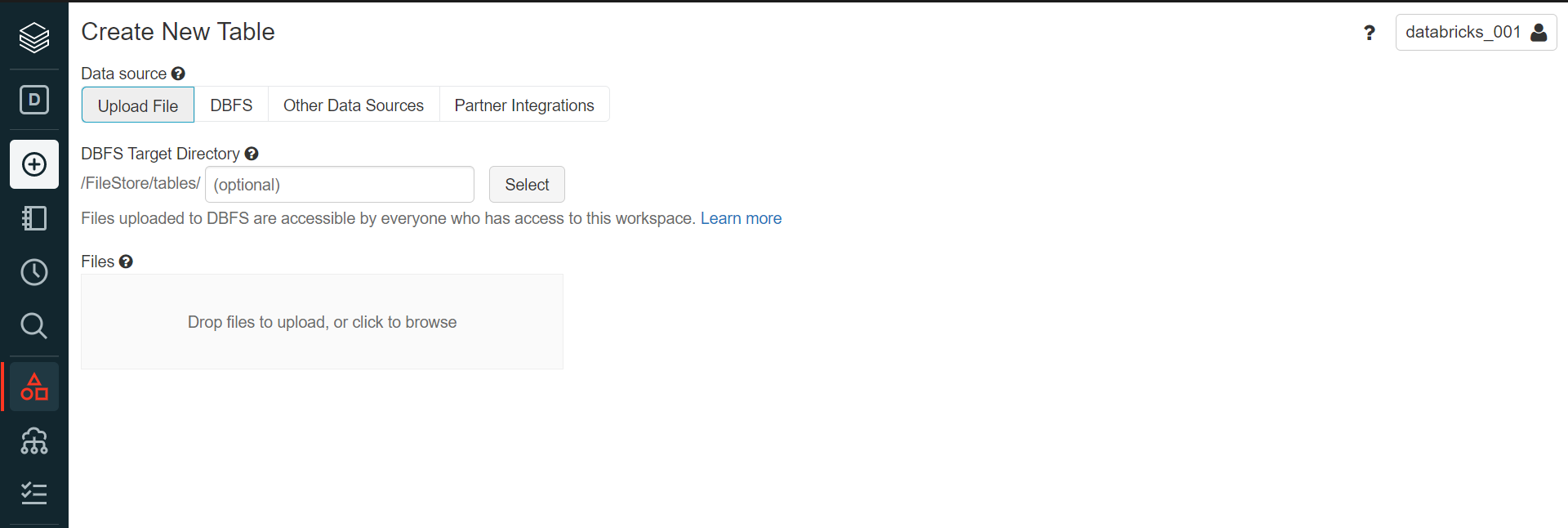
After having the workspace in place, we need to create a new table in Azure Databricks using an existing CSV file. We can use any CSV file with a few fields and at least one record in it. Click on the Create menu option and select the Table option, which would open the interface as shown below. Click on the Upload File option and upload the sample file here.
Once the file is uploaded one can explore it in the DBFS tab as shown below. Here we have uploaded the file, after we select it, we would get the option to create a new table using the UI or using a notebook.

To create the tables using either option, we need to have a cluster in place. Click on the Create menu option and select Cluster and it would open a new page as shown below. Provide the relevant cluster details and create a new cluster.
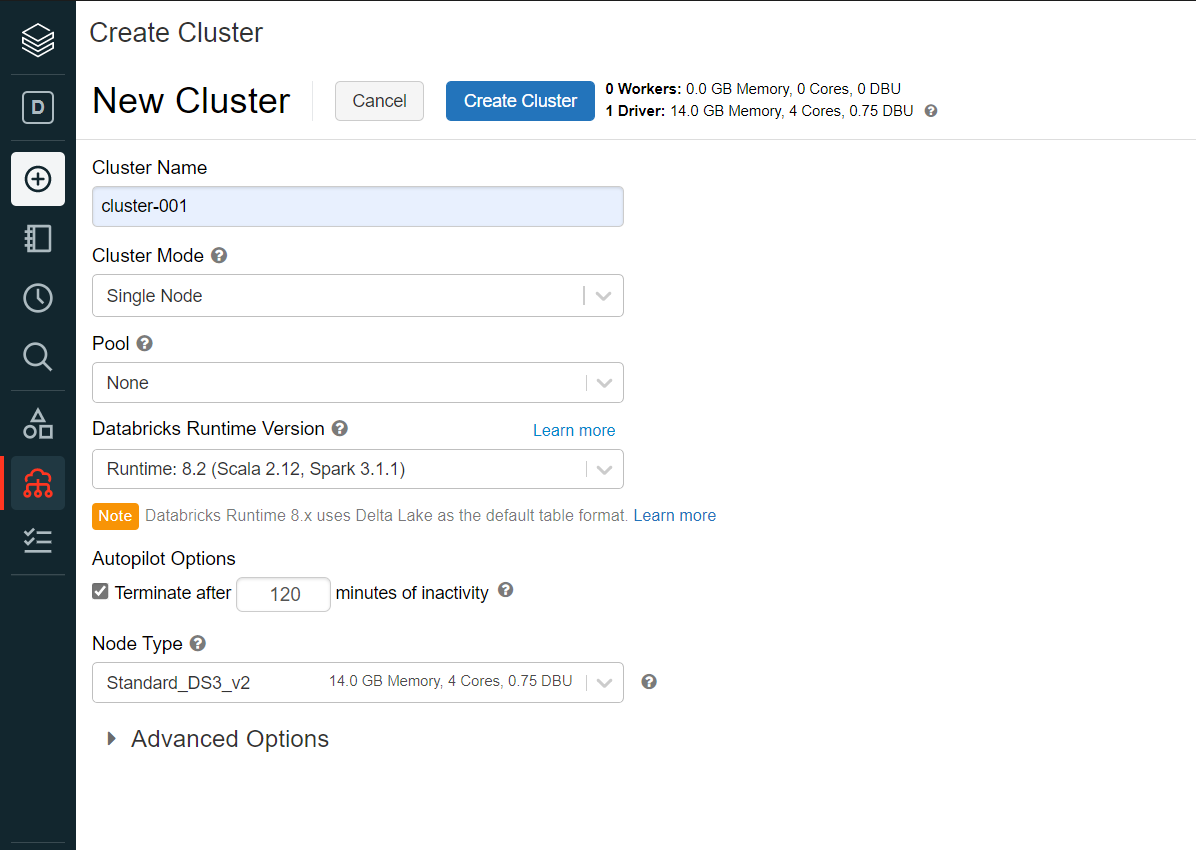
Once the cluster is created, follow the steps shown below to navigate to the uploaded file in DBFS and click on the button to create a new table using the notebook. You can change the value of infer_schema and first_row_is_header to “true” if required.
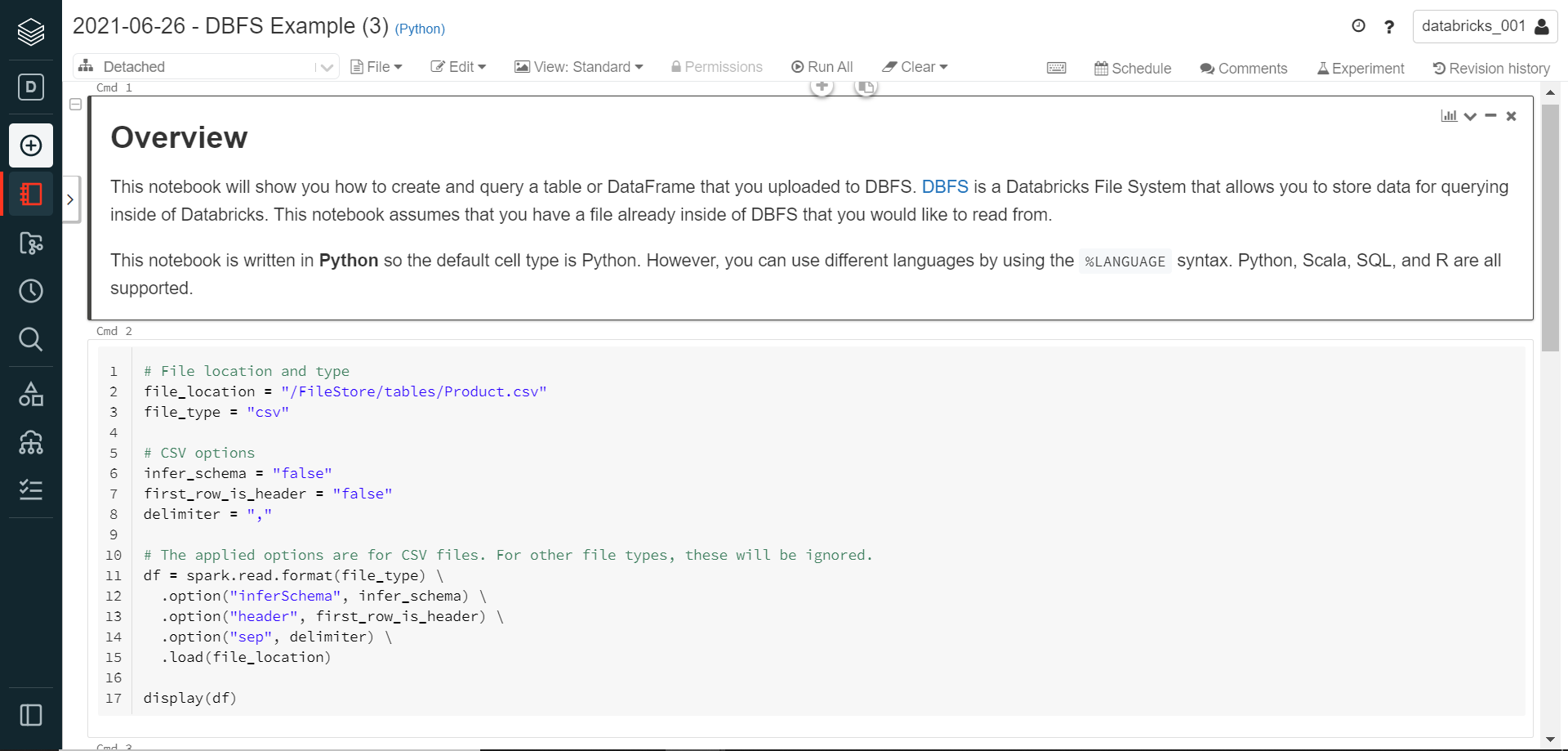
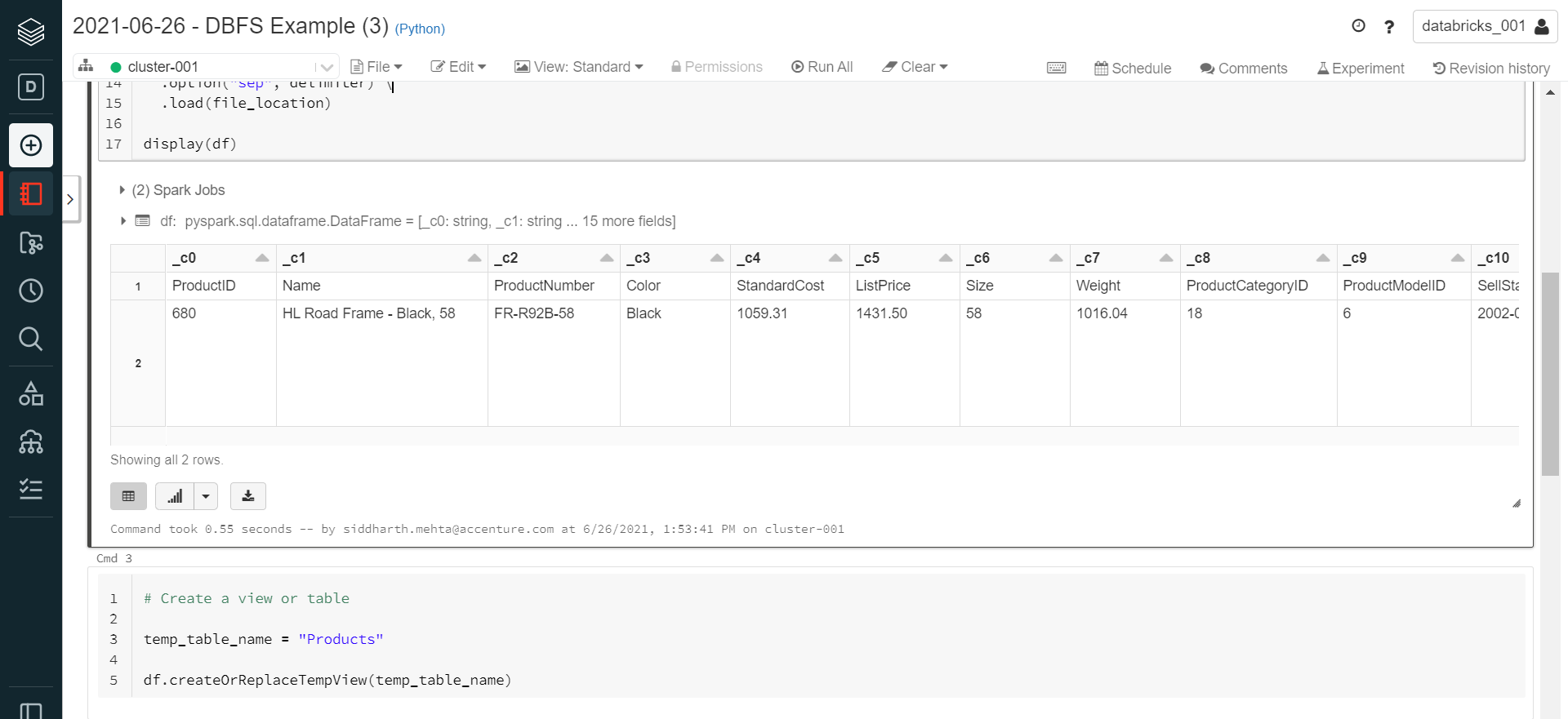
Execute the cell and it would look as shown below. In the next cell, we need to provide an appropriate temporary table name that will create a view in the data frame. Provide an appropriate name and execute this cell.
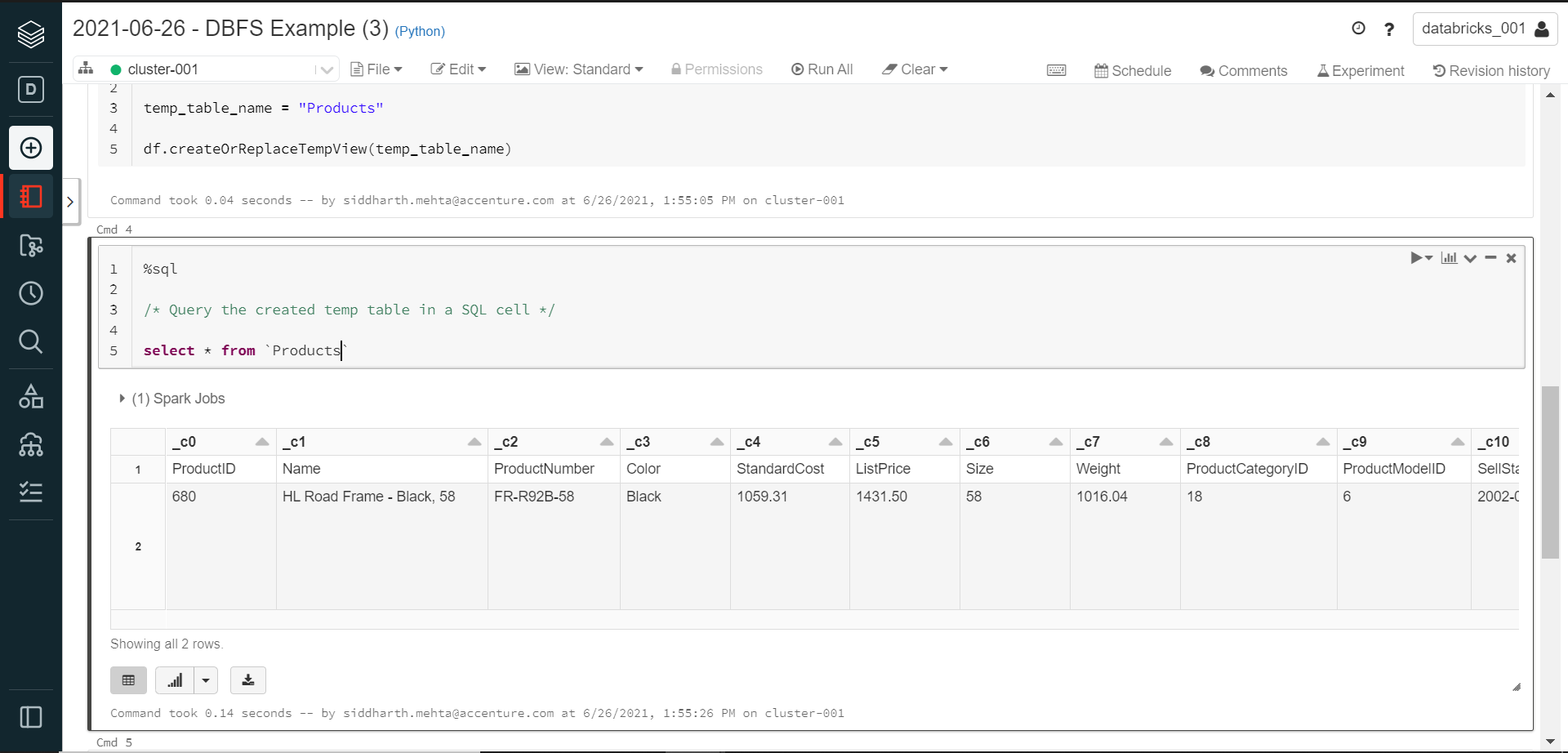
In the next step, we can execute the sample SQL query to ensure that the table can be queried, and the records are being returned. If the query execution is successful, we should be able to see the results as shown below.
In the next step, you would find a cell with the code as shown below. In this step, the last line of code would be commented. This line of code converts the table to parquet format. We need the table to be created in delta format.

Uncomment this line of code and instead of the keyword parquet, replace it with the keyword delta. This line of code uses the data view held in the data frame and saves it as a table in delta format. Execute this cell and the result would look as shown below.
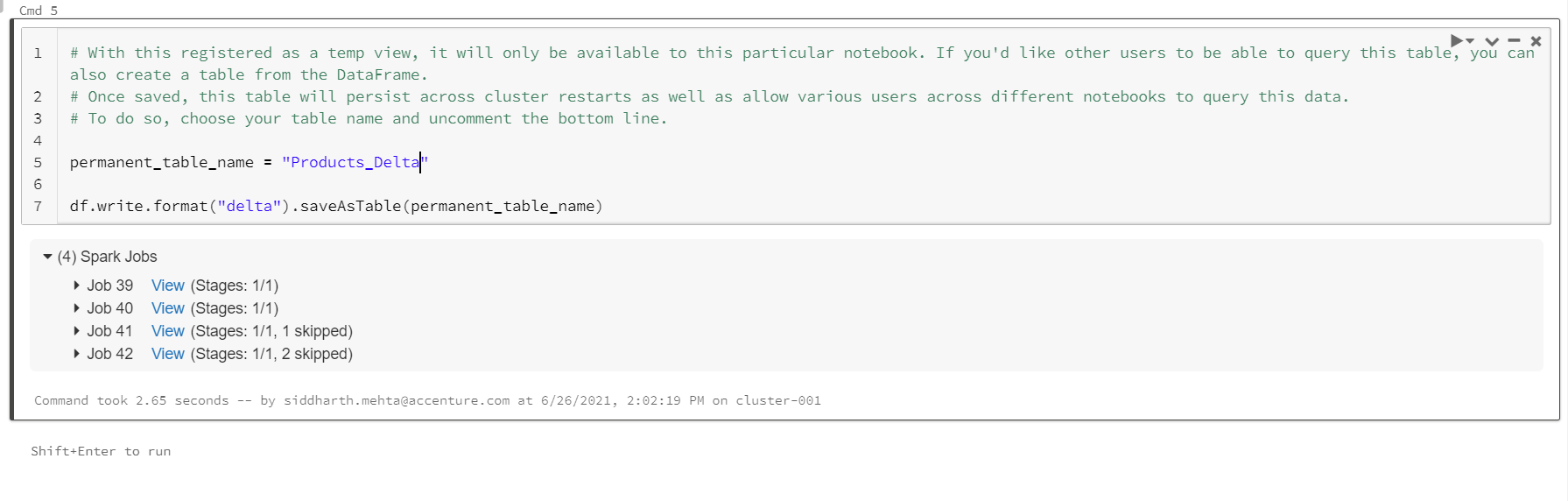
Once this delta table is created, we need to ensure that it’s appearing in the list of tables. Click on the Data menu option on the left-hand pane and you should be able to view the newly created table in the table list as shown below.
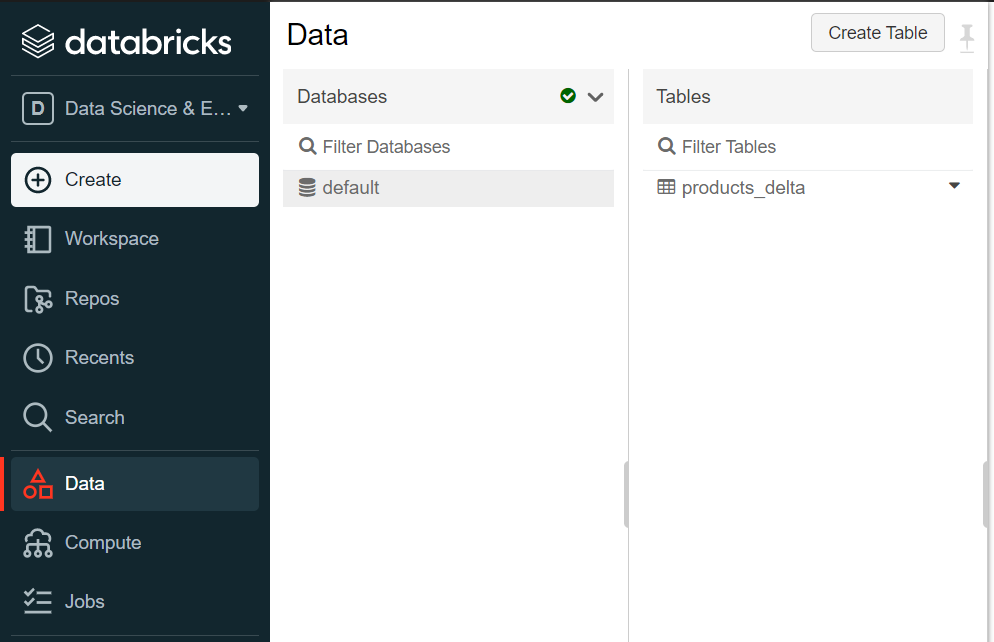
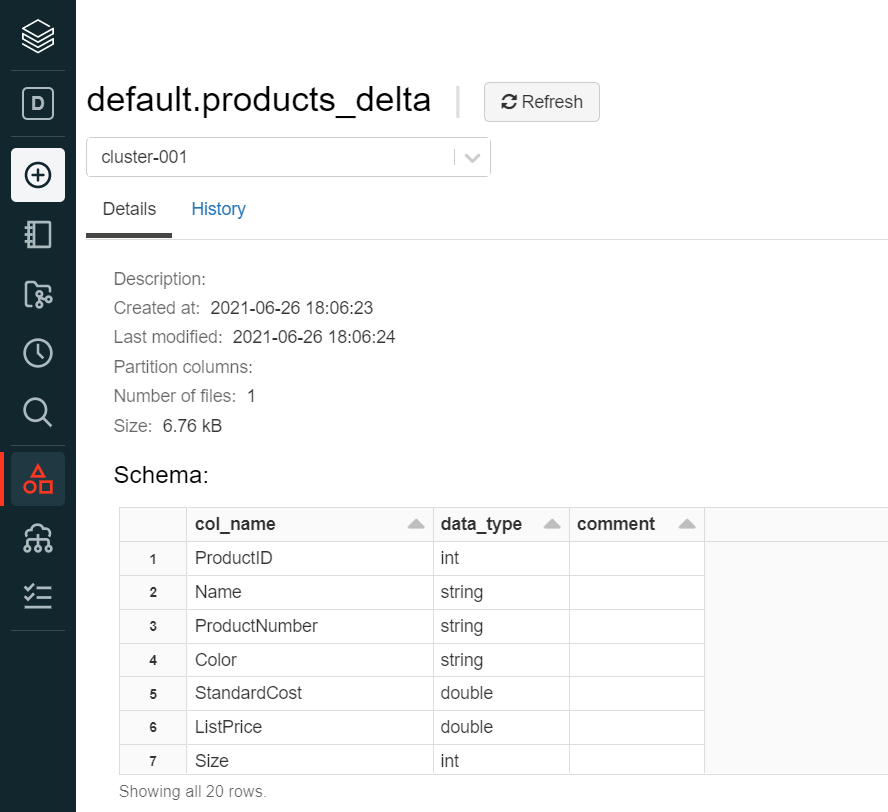
Click on this table name and it would open a new page where we can preview the data and preview the schema as shown below. It will also display any partitions on the table, the size of the data held in this table, and the history of changes and parameters for this table. For example, one would be able to find whether the table is a managed table by looking at the parameters that would be shown in the history tab of this table.
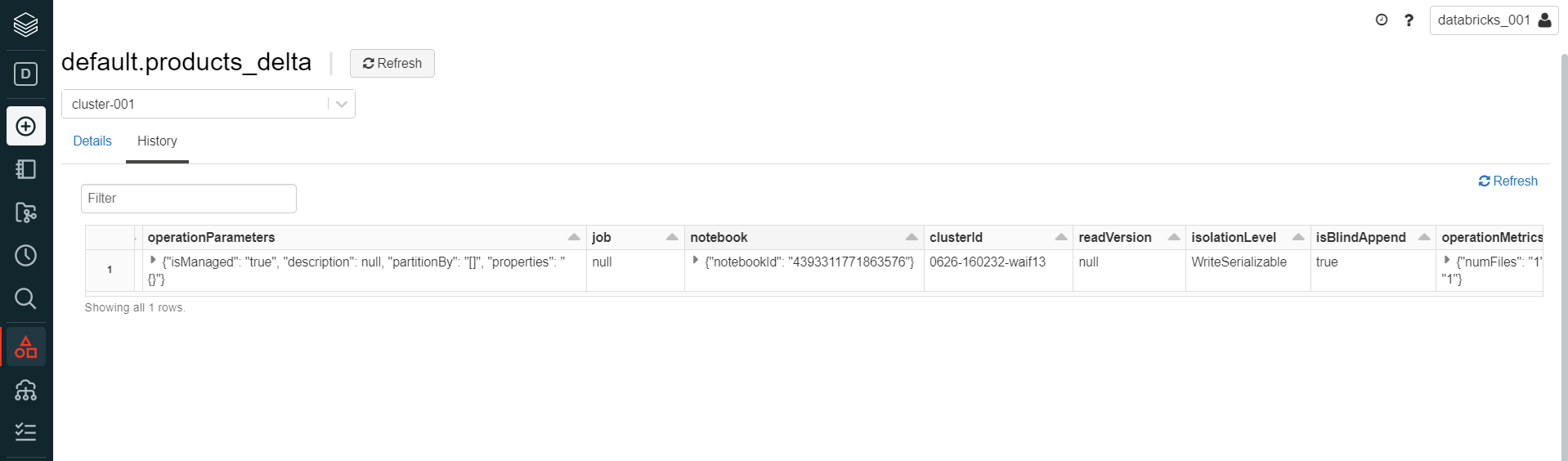
Click on the History tab to view more details as shown below. Here we would be able to find more table properties and metadata details like the option Parameters, the job or the notebook using which the table was created, the SQL command that was used to create the table, the cluster that was used to create the table, the table version, isolation level of the table, and many other properties some of which are shown below.
In this way, we can use different file formats that are hosted on the Azure Databricks instance and using either a notebook or directly using the UI, we can create tables in a variety of formats including the Azure Databricks Delta Lake format.
Conclusion
In this article, we understood the functionality of the Delta Lake format and its importance in the Azure Databricks platform. We created an Azure Databricks workspace instance first and then we created a cluster on this instance. We uploaded a sample CSV file and using the notebook option we created a table in delta format. We also explored the table metadata, properties and previewed the data held in this table.

She has a deep experience in designing data and analytics solutions and ensuring its stability, reliability, and performance. She is also certified in SQL Server and have passed certifications like 70-463: Implementing Data Warehouses with Microsoft SQL Server.
View all posts by Gauri Mahajan
- Oracle Substring function overview with examples - June 19, 2024
- Introduction to the SQL Standard Deviation function - April 21, 2023
- A quick overview of MySQL foreign key with examples - February 7, 2023