
In this article, we will learn how to populate delta lake tables into Azure Databricks from Azure SQL Database using Azure Data Factory.
Introduction
Azure Databricks is a popular data engineering and data science platform that enables the creation of delta lake tables and other data-related constructs for a variety of data engineering, machine learning and other purposes. Azure Data Factory is Azure’s primary data integration and ETL offering that offers almost a hundred connectors to a variety of data sources to facilitate data movement to and from Azure cloud to various supported services. In a typical data life cycle, data flows from different sources like data stream, files, transactional databases, IoT devices and many other sources of data. To perform robust data processing operations on the variety of data that lands on the Azure cloud, one of the options is to use the Azure Databricks platform and build a Delta Lake to effectively build a Data Lake on it or use the data for data science-related workloads. One of the popular sources of transactional data on Azure is Azure SQL Database. One of the most common use-cases is to populate data from Azure SQL Database to Azure Databricks delta table. There are different ways to populate the tables in Azure Databricks. One of the most straightforward ways of populating delta lake tables is by using Azure Data Factory.
Pre-requisites
As we are going to populate data from source to destination using an integration service, we need the three to be in place. To start with, we need an Azure account in place as all the three services in question are hosted on Azure. It is assumed that one has an active Azure account with the required privileges to execute this exercise.
The first step is to have an Azure SQL Database with some sample data in it. Navigate to the Azure SQL service dashboard and create this instance. An easy way to create some sample data is to enable the sample data option while creating the Azure SQL Database. This would complete the creation of the data source.
The second step is to have an Azure Databricks workspace instance in place. Navigate to the Azure Databricks service and create a new workspace in the same region where the Azure SQL database is hosted. We are going to use the Azure Data Factory Delta Lake connector which required a specific configuration on the Azure Databricks cluster. Consider carefully reading the pre-requisites section from this link and configure the cluster so that it can access Azure Blob storage as well as Azure Data Lake Storage Gen 2. We also need to have a table of “delta” format created in a cluster hosted on the Azure Databricks workspace. This is crucial as Data Factory won’t create a new table neither would it populate tables that are not of delta lake format. So, ensure that there is a table whose schema would coincide with a table in the Azure SQL database, so we can smoothly populate it without any complex transformation.
The third and final pre-requisite is to have the integration service that would facilitate the data movement i.e., the Azure Data Factory instance. Navigate to the Data Factories service dashboard and create this instance. Once these three pre-requisites are met, we are ready to start with our exercise.
Populating Delta Tables in Azure Data Factory
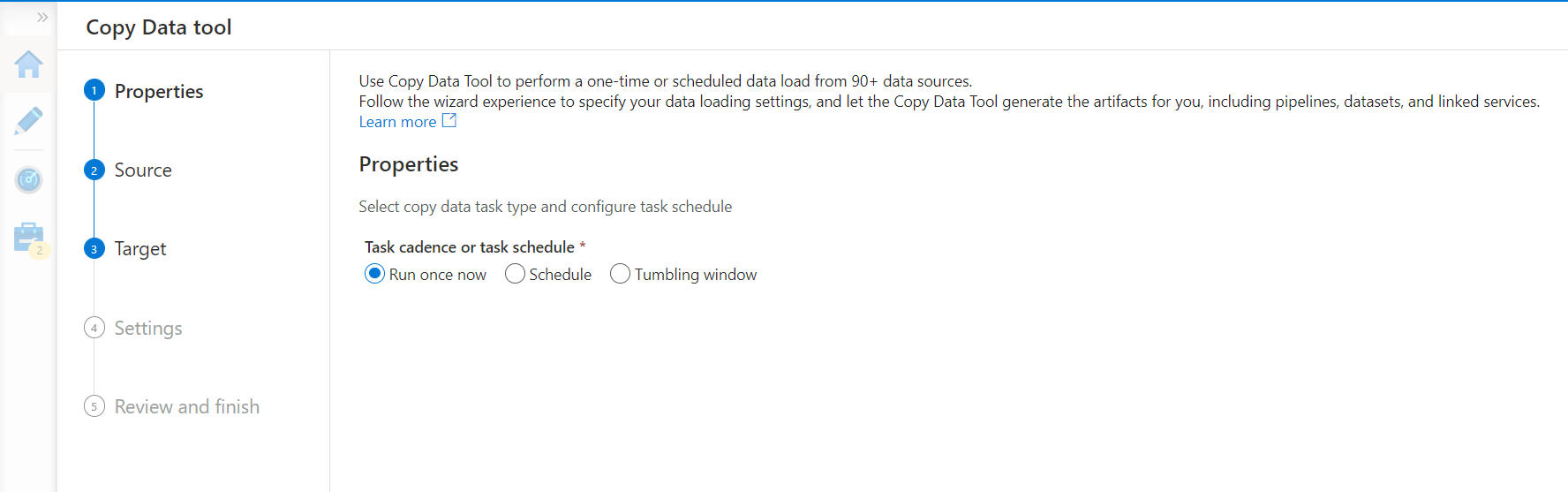
Open the Azure Data Factory instance and click on the Author and Monitor link to launch the Data Factory portal. On the home page click on the Copy button and it would launch a wizard as shown below. In this step, we need to define the task schedule and frequency of execution. The default frequency is to Run once. For now, we would proceed with the same.
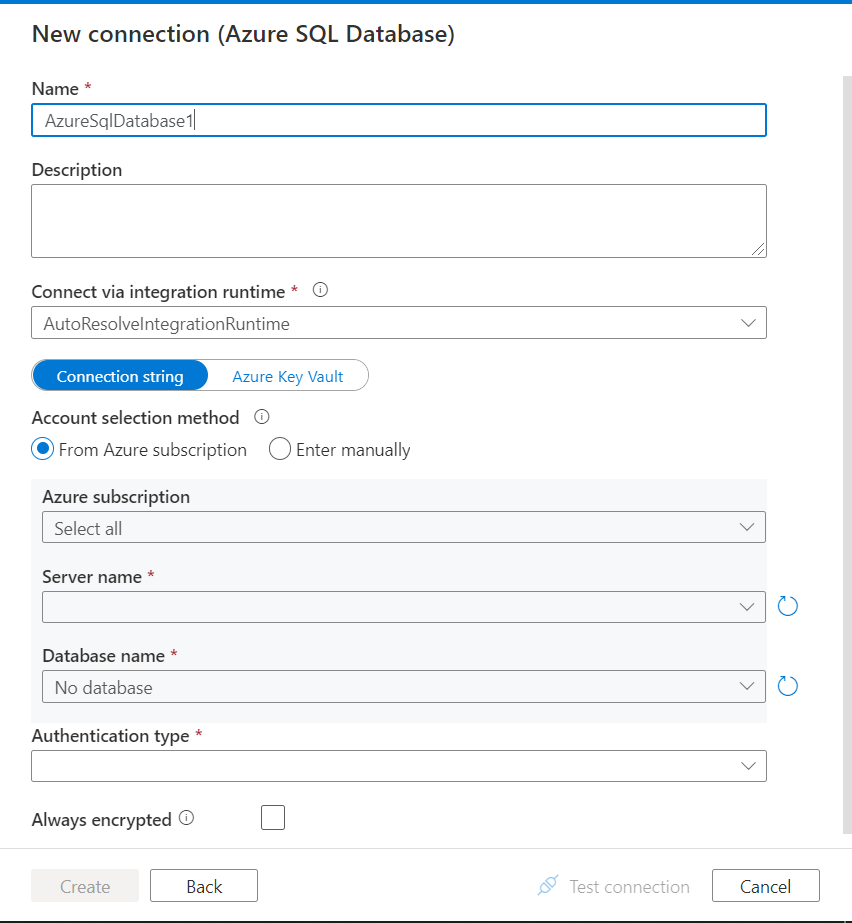
In the next step, we need to register a new connection of Azure SQL Database type as shown below by providing the required credentials. After providing the required credentials, when you click on the Test Connection button, you may receive an error in connecting to the Azure SQL Database. One of the most common reasons is that the Azure Data Factory IP or private endpoint is not added in the firewall settings of the Azure SQL Database. From the error message, once you add the IP of the Data Factory that fails to connect to the SQL database, the connectivity would go smooth.
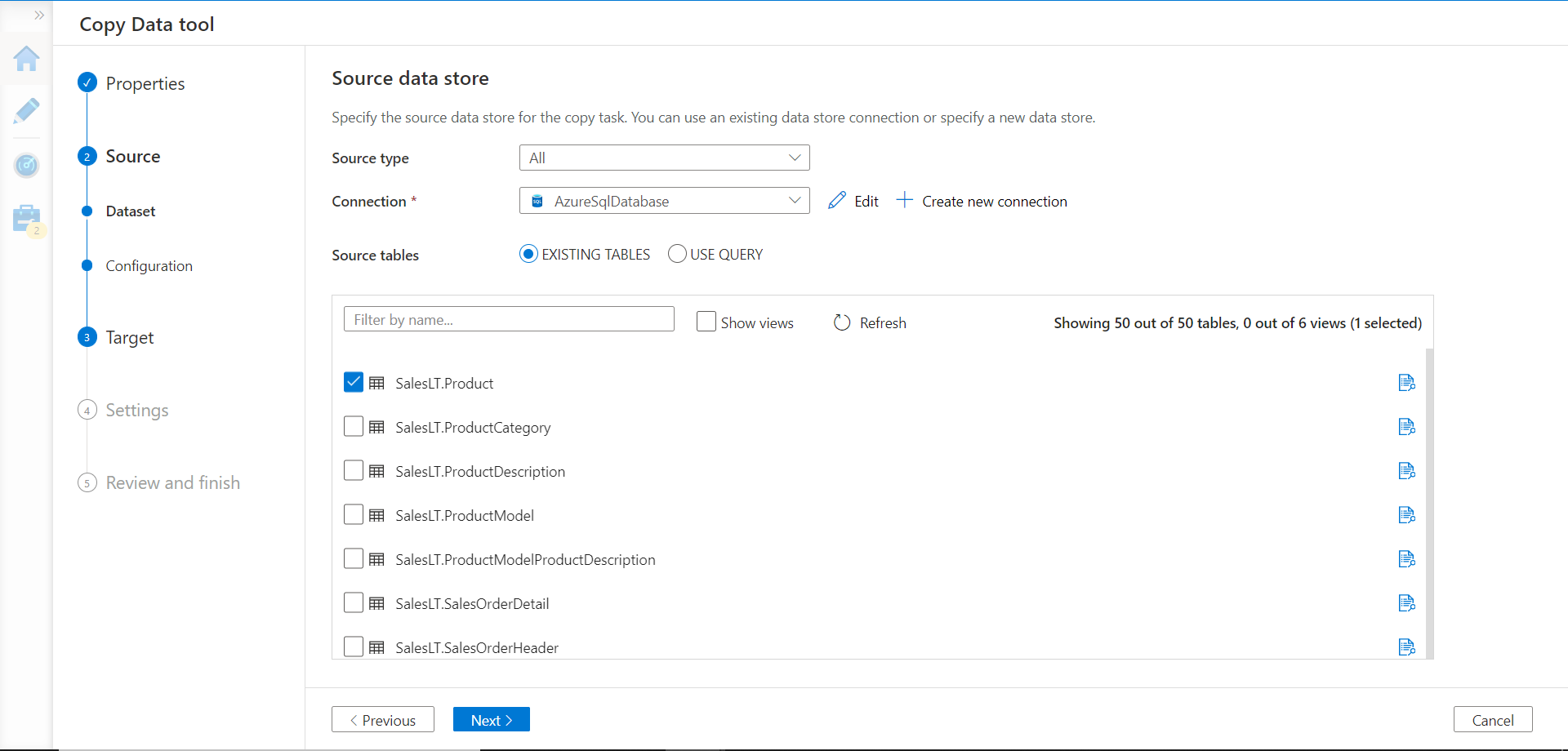
Once the linked service is registered, select one or more tables that we intend to use as the source. For now, in this exercise, we would select one table as the source as shown below. Keep in view that we have created an identical delta format table using the same schema in the Azure Databricks instance as well.
In the next step, we can preview the data as shown below. After ascertaining that the data meets the expectations, we can move to the next step.
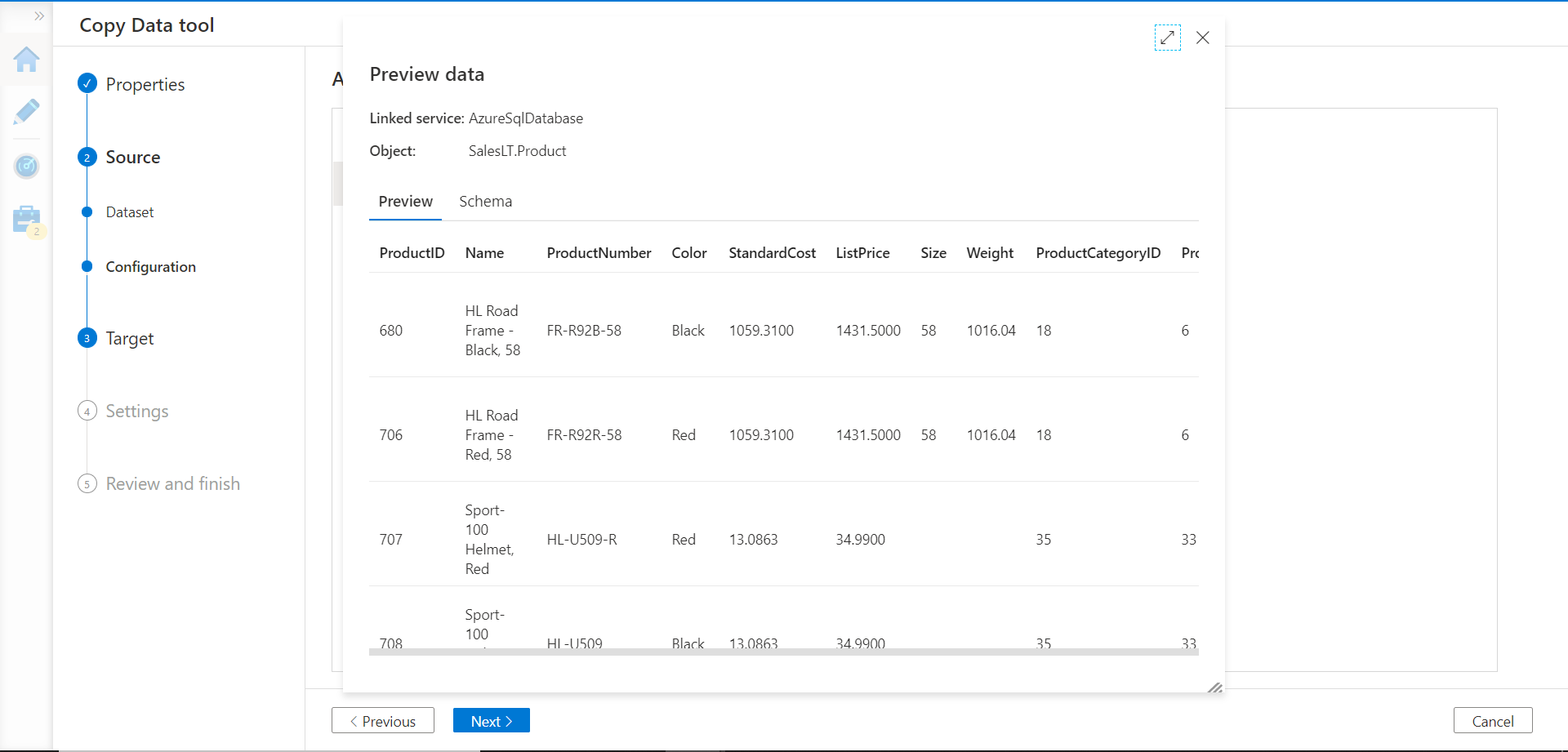
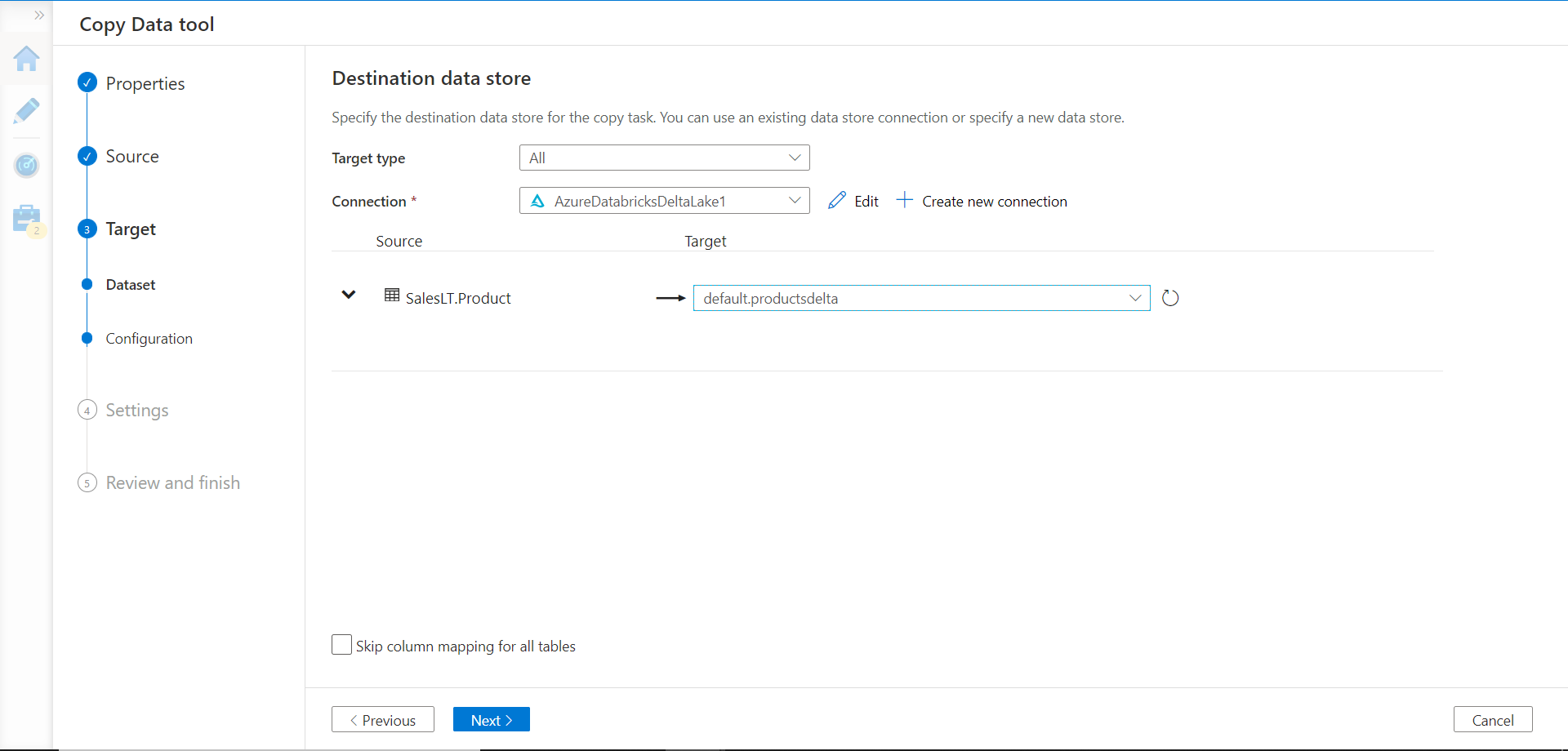
In the next step, we need to register a new connection of Azure Databrick Delta Lake type as shown below, by providing the required credentials. Once registered, we can select the delta table that we have already created in the Azure Databricks instance. Keep in view that the dropdown would list all formats of tables from the Azure Databricks instance. But we can select only the delta lake format /tables, as the Azure Data Factory connection that we have created supports only this format.
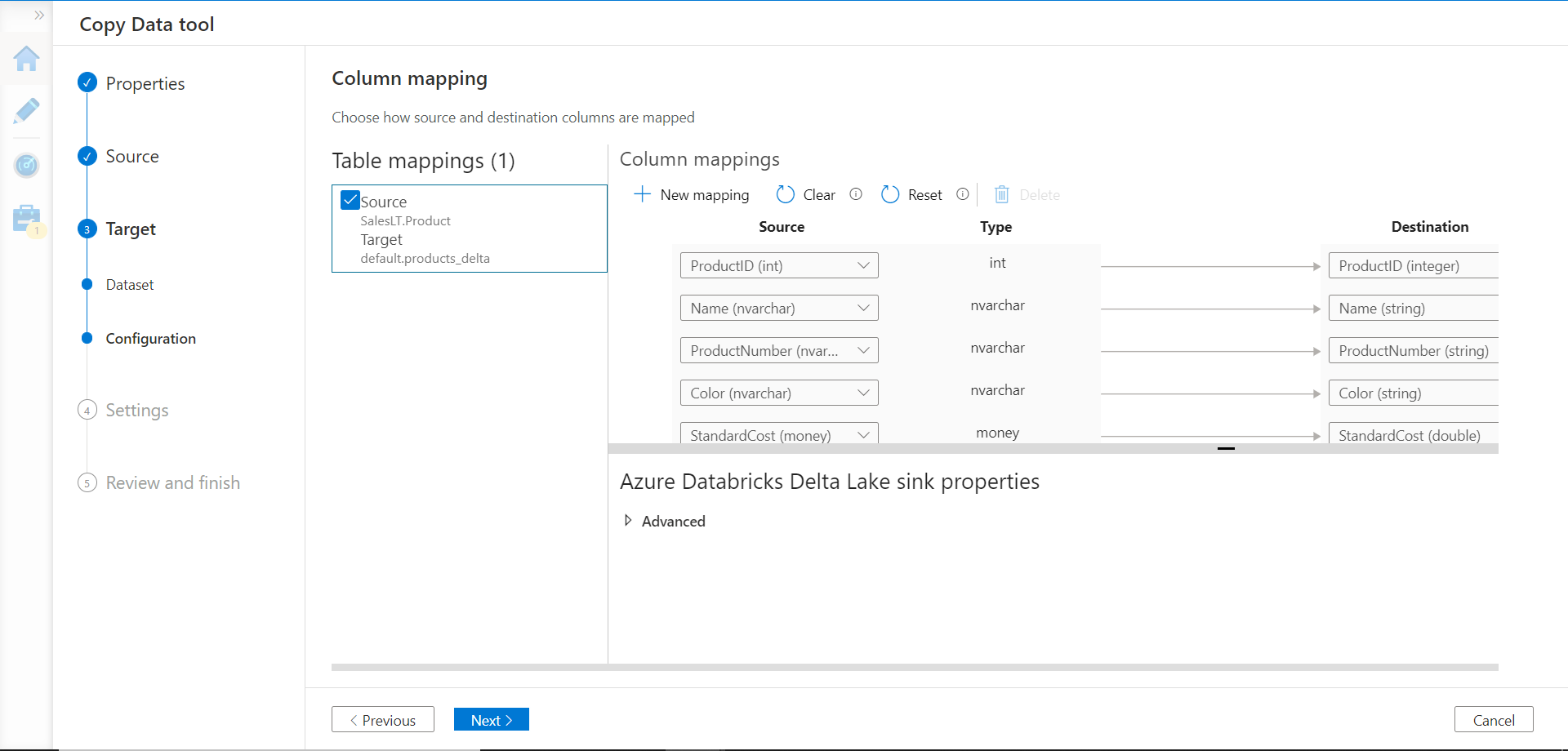
In the next step, optionally we can configure the data mapping of the source fields of the Azure SQL Database table with the destination fields in the Azure Databricks table as shown below. As we have identical schemas in source and destination, we do not need to perform any mapping changes and we can move to the next step.
In the settings, we can provide an appropriate name for the data pipeline being created, and optionally configure or fine-tune the settings related to the pipeline as shown below. For this exercise, we do not need to make any changes except one. Try to proceed to the next step using default values and you would find an error listed at the bottom of the page as shown below.
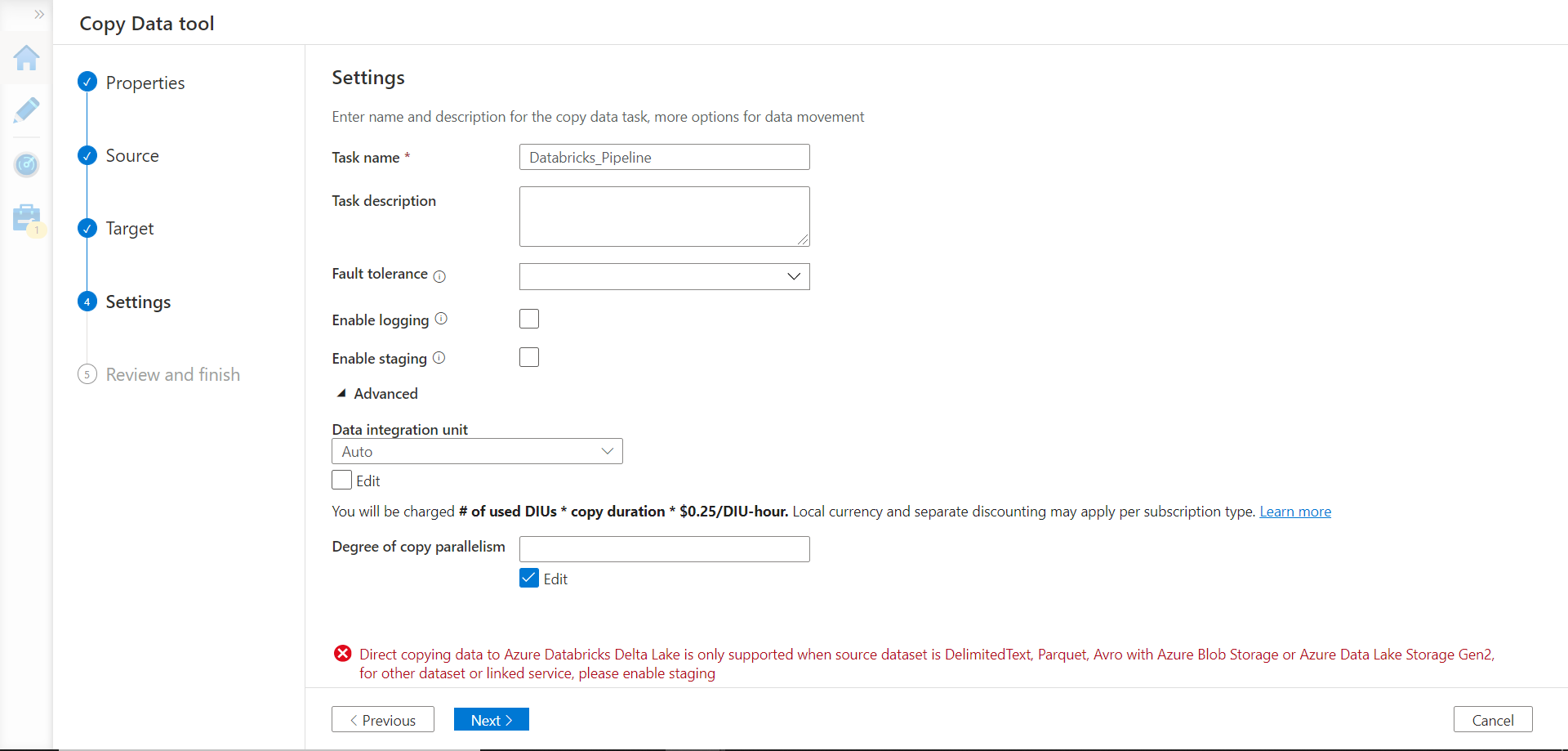
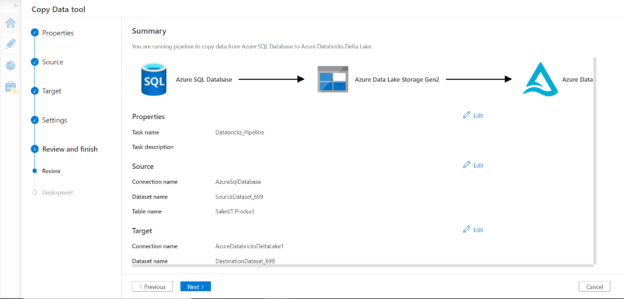
To address this issue, check the enable staging option and provide an Azure Data Lake Storage Gen 2 account. This would stage the data on this account before populating the delta table in Azure Databricks. In the final step, we just need to review the summary of the configuration we have selected so far as shown below.
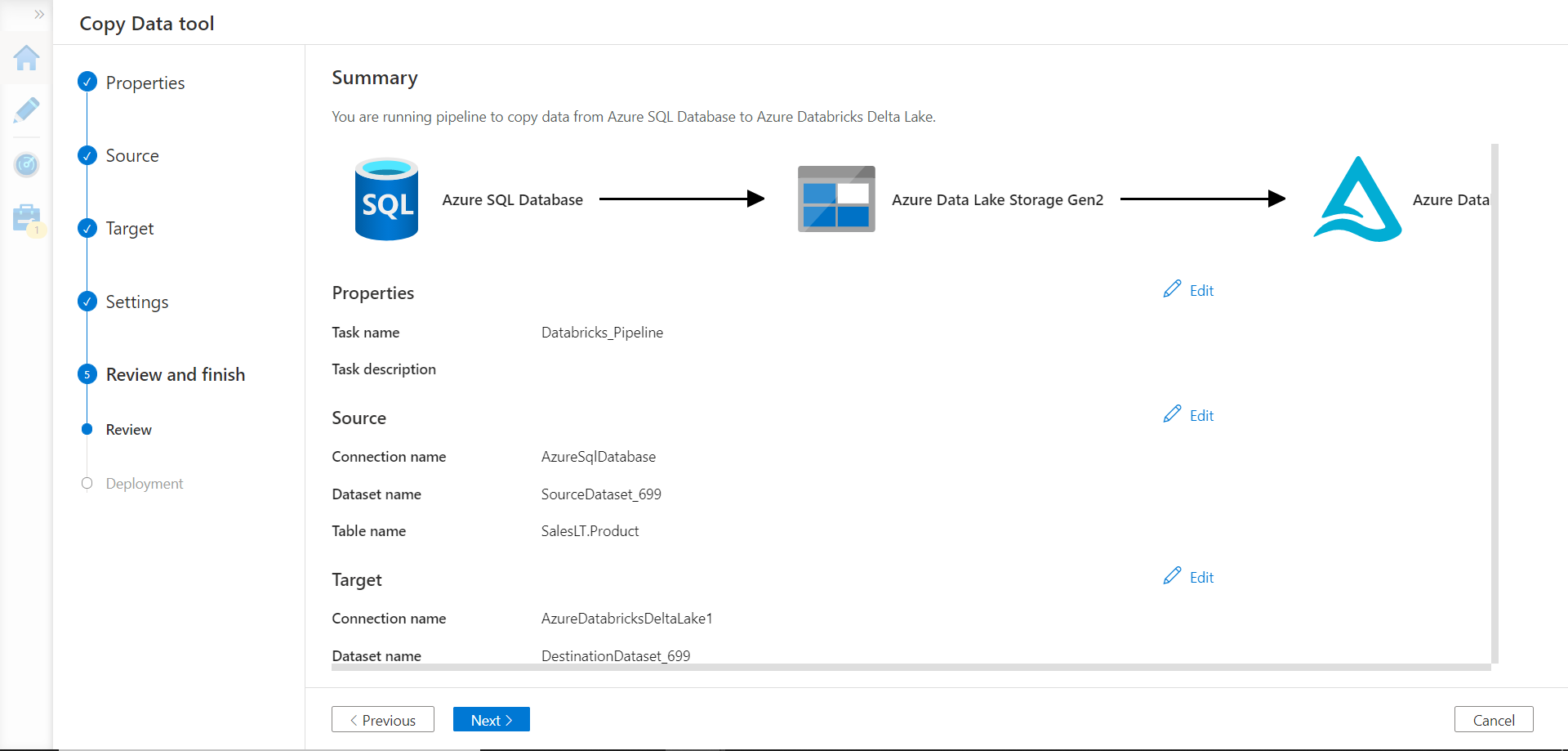
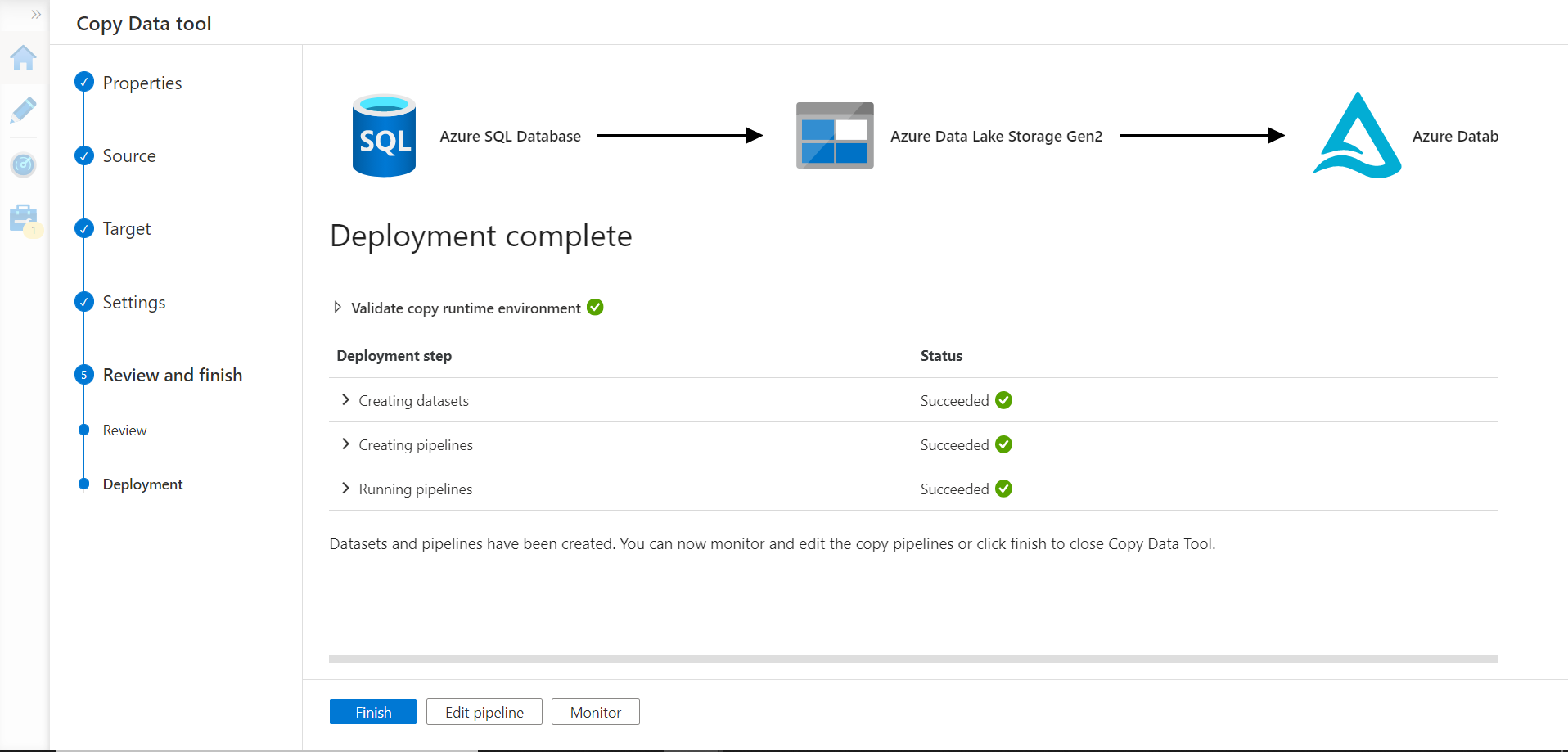
Once we proceed to the next step, it would start the deployment and the data pipeline would be executed. Once the execution is complete, data should get successfully populated in the Azure Databricks delta table.
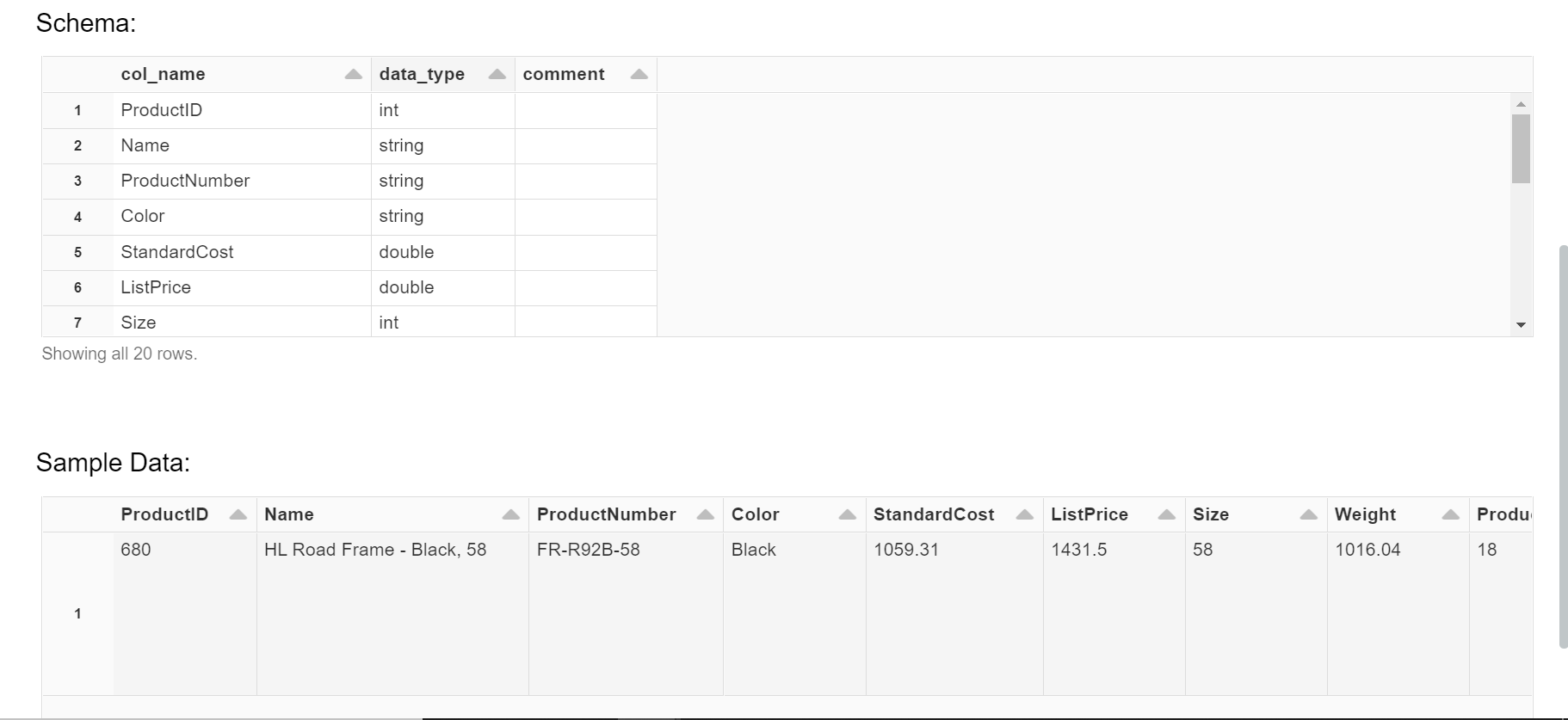
Once data is populated in the delta table, it should look like the table shown below.
In this way, we can use Azure Data Factory and Azure Databricks Delta Lake connector to populate delta tables hosted in Azure Databricks instance.
Conclusion
In this article, we created an instance of Azure SQL Database, Azure Data Factory and Azure Databricks. We created sample data on the SQL database as well as a blank delta table on the Azure Databricks instance as the source and destination. Then we used the Azure Data Factory instance to create a data pipeline that populates data from the SQL database to the delta table using the Delta Lake connector. We also understood the specific configuration required for using delta lake connector as well as populating delta tables.

She has a deep experience in designing data and analytics solutions and ensuring its stability, reliability, and performance. She is also certified in SQL Server and have passed certifications like 70-463: Implementing Data Warehouses with Microsoft SQL Server.
View all posts by Gauri Mahajan
- Oracle Substring function overview with examples - June 19, 2024
- Introduction to the SQL Standard Deviation function - April 21, 2023
- A quick overview of MySQL foreign key with examples - February 7, 2023