
This article talks about the commonly used scenarios of SQL Select Distinct in an easily understandable format equally suitable for beginners and professionals.
The article also brings into light some of the data analysis performed based on the Distinct keyword.
Additionally, the readers of the article are going to get hands-on experience in implementing the common use cases discussed in this article by simply copying and running the scripts against the sample database of their choice.
Understanding SQL Select Distinct
Let us try to get a clear understanding of using distinct with SELECT statements in SQL with the help of simple examples first.
Setup Sample Database
Please build a simple sample database called StudentExamDemo currently with one table named Student to see even the simplest of our examples in action.
We are using an on-premises SQL instance to build the database and its objects (tables) while you are free to build an Azure SQL database or on-premises SQL database.
Run the following script against the master database (to create a database):
|
1 2 3 4 5 |
USE master; CREATE DATABASE StudentsExamDemo; GO |
Next, create a Student table by running the following script against the sample database:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
USE StudentsExamDemo -- Create a Student table DROP TABLE IF EXISTS dbo.Student CREATE TABLE [dbo].[Student] ( [StudentId] INT IDENTITY (1, 1) NOT NULL, [Name] VARCHAR (50) NOT NULL, [Detail] VARCHAR (200) NULL ); -- Populate student table SET IDENTITY_INSERT [dbo].[Student] ON INSERT INTO [dbo].[Student] ([StudentId], [Name], [Detail]) VALUES (1, N'Atif', N'This is Atif') INSERT INTO [dbo].[Student] ([StudentId], [Name], [Detail]) VALUES (2, N'Atif', N'This is Atif') INSERT INTO [dbo].[Student] ([StudentId], [Name], [Detail]) VALUES (3, N'Sarah', N'This is Sarah') SET IDENTITY_INSERT [dbo].[Student] OFF |
SELECT Statement vs SELECT ALL Statement
Before we jump to SQL SELECT Distinct, we must understand that the SELECT statement itself simply returns the rows of a table based on the columns you mention with your select statement.
However, there is one more important thing to know about the SELECT statement, it, by default returns all the records of a table including duplicate values of the columns.
So, technically in all SELECT statements by default the keyword ALL is included unless stated otherwise.
Let us view all the rows of the Student table (which we just build earlier) by using the SELECT statement as follows:
|
1 2 3 4 |
-- View student table data SELECT s.StudentId,s.Name,S.Detail FROM dbo.Student s |
The output is as follows:
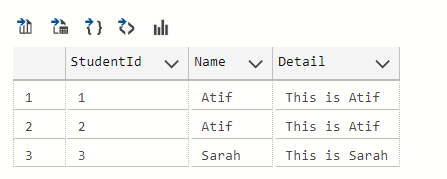
Now we will run the same script with an additional ALL keyword at the start:
|
1 2 3 4 |
-- View student table data using ALL keyword SELECT ALL s.StudentId,s.Name,S.Detail FROM dbo.Student s |
The results are as follows:
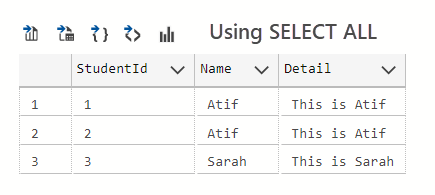
So, we can see that SELECT without the mention of any specific clause is using the ALL keyword as we have seen in the above two examples.
We also discovered one more thing a student record seems to be a duplicate as we assume it was inserted twice by mistake.
SQL SELECT Distinct Statement vs SELECT ALL Statement
The Distinct keyword in the SELECT statement can help us to show only distinct records based on a column and this means we are not going to see duplicate rows that we saw earlier in the first example.
Let us see it in action by running the following script:
|
1 2 3 4 |
-- View Student tables with distinct Names (Name column values) SELECT DISTINCT(s.Name),s.Detail from dbo.Student s |
The query output is as follows:
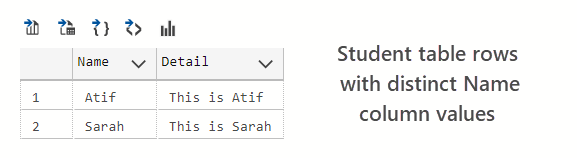
We don’t see the student Atif record twice this time because we are looking at distinct names (Name column values) and as a result, we have temporarily prevented the duplicate row to show up in the result set.
About the position of the distinct keyword
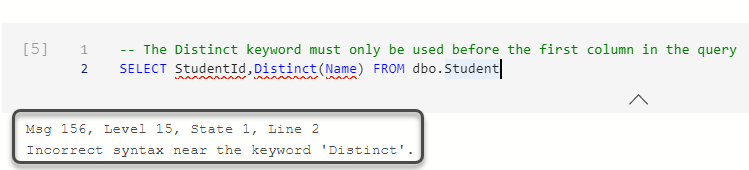
Please note that in a T-SQL script (SQL query) Distinct should be the first word after SELECT as you cannot use distinct with the second column leaving the first column as it is.
For example, running the following script shows an error:
|
1 2 3 4 |
-- The Distinct keyword must only be used before the first column in the query SELECT StudentId,Distinct(Name) FROM dbo.Student |
Common use cases
Let us now discuss the common use cases of SQL SELECT Distinct statement.
Analyzing and Improving data accuracy based on distinct values
Suppose we are doing some crucial analysis of the data and during the analysis, we would like to understand the accuracy of the data that is being analyzed.
Now let us say our accuracy depends on the uniqueness of column Name in the Student table so we are going to make use of the SQL SELECT Distinct command to understand how good our data is in terms of accuracy.
One way is to count distinct values against the total values of the table and if they are not the same that means some duplicate records are present which can impact our analysis results.
Let us run the following script to prove this:
|
1 2 3 4 5 6 7 8 9 10 |
-- View Student data with duplicate names SELECT Name, Detail FROM dbo.Student -- Counting all rows SELECT (COUNT((Name))) as Total_Names FROM dbo.Student -- Counting rows with unique/distinct names SELECT (COUNT(DISTINCT(Name))) as Total_Unique_Names FROM dbo.Student |
The queries output is as follows:
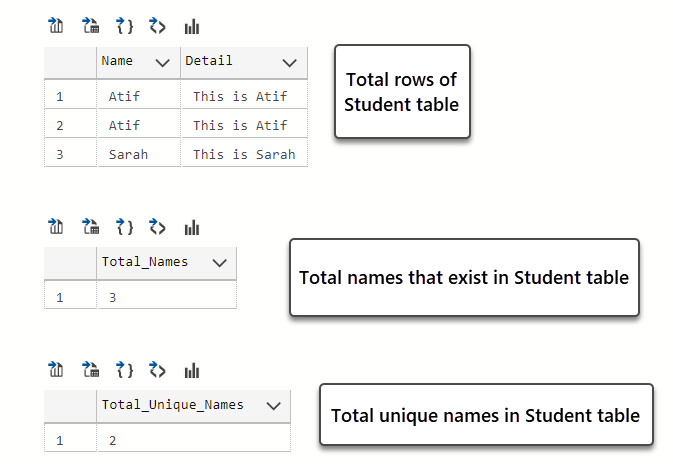
From the output it is clear that we have fewer unique names (two) than expected (three) so this can affect the results of our analysis if we think that this is because a record has been inserted twice by mistake.
Similarly, we can use this information to remove duplicates as a means to improve our data analysis outcome. Let us fix the issue by replacing the duplicate name with another name to ensure that we have three unique rows and there is no duplicate data in our table.
|
1 2 3 4 5 6 7 8 9 |
-- Fix the problem by replacing the duplicate name Atif with Adil UPDATE dbo.Student SET Name='Adil', Detail='This is Adil' WHERE StudentId=2 -- View Student table SELECT [StudentId],[Name],[Detail] FROM dbo.Student |
The final output is as follows:
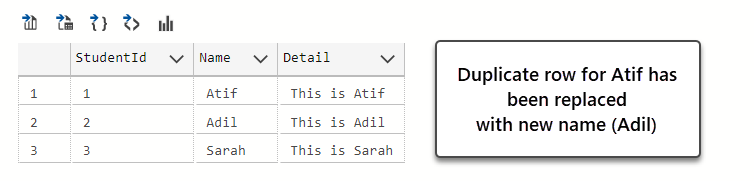
Finding Unique References of Data
We can use SQL SELECT Distinct to find unique references of data. For example, we have a result set that shows different rows of a table and each row consists of columns. Now sometimes we are more interested in unique patterns of the data rather than the data itself which is one of the key things in investigative analysis.
We need to build the Subject and StudentSubject table by running the following script:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 |
-- Create a new table called '[Subject]' in schema '[dbo]' -- Drop the table if it already exists IF OBJECT_ID('[dbo].[Subject]', 'U') IS NOT NULL DROP TABLE [dbo].[Subject] GO -- Create the table in the specified schema CREATE TABLE [dbo].[Subject] ( [SubjectId] INT NOT NULL PRIMARY KEY, -- Primary Key column [Name] NVARCHAR(50) NOT NULL, [Detail] NVARCHAR(50) NOT NULL ); GO -- Insert rows into table 'Subject' in schema '[dbo]' INSERT INTO [dbo].[Subject] ( -- Columns to insert data into SubjectId,Name,Detail ) VALUES ( -- First row: values for the columns in the list above 1, 'Data Structure', 'This is about Data Structure' ), ( -- Second row: values for the columns in the list above 2, 'Modern Databases','This is about Modern Databases' ), ( -- Second row: values for the columns in the list above 3, 'Business Intelligence (BI)','This is about Business Intelligence' ) GO -- Create a new table called '[StudentSubject]' in schema '[dbo]' -- Drop the table if it already exists IF OBJECT_ID('[dbo].[StudentSubject]', 'U') IS NOT NULL DROP TABLE [dbo].[StudentSubject] GO -- Create the table in the specified schema CREATE TABLE [dbo].[StudentSubject] ( [StudentSubjectId] INT NOT NULL PRIMARY KEY, -- Primary Key column [StudentId] INT NOT NULL, [SubjectId] NVARCHAR(50) NOT NULL, [MarksObtained] INT, [TotalMarks] INT -- Specify more columns here ); GO -- Insert rows into table 'StudentSubject' in schema '[dbo]' INSERT INTO [dbo].[StudentSubject] ( -- Columns to insert data into StudentSubjectId,StudentId,SubjectId,MarksObtained,TotalMarks ) VALUES ( -- First row: values for the columns in the list above 1,1,1,70,100 ), ( -- Second row: values for the columns in the list above 2,1,2,70,100 ), ( -- Third row: values for the columns in the list above 3,2,1,80,100 ), ( -- Fourth row: values for the columns in the list above 4,2,3,80,100 ), ( -- Fifth row: values for the columns in the list above 5,3,1,90,100 ), ( -- Sixth row: values for the columns in the list above 6,3,3,90,100 ) GO |
Let us now focus on the StudentSubject table which contains the records of all the students who obtained marks in the exam against their subjects.
So, we have the following items of interest in this scenario:
- Students
- Subjects
- Marks obtained
Please note that students are already defined in a reference table named Student and likewise we also have a reference table for Subjects. Now keeping in mind the reference tables we can say students showing up in the StudentSubject table actually originated in their reference table.
Let us run the script to view the StudentSubject data first:
|
1 2 3 4 5 |
-- View marks obtained in each subject by each student SELECT s.Name,ss.SubjectId,(ss.MarksObtained) FROM StudentSubject ss INNER JOIN Student s on ss.StudentId=s.StudentId |
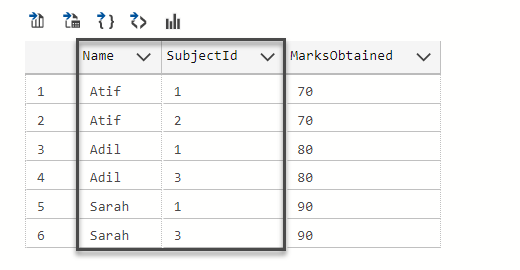
However, we are interested in a slightly different piece of information which we referred to as finding unique references or patterns of data. This means we want to know how many distinct marks were obtained by the students so far against any subject which will give us a distinct pattern of the obtained marks.
Let us find it out with the help of the SQL SELECT Distinct command as follows:
|
1 2 3 4 5 |
-- View unique marks obtained SELECT DISTINCT(ss.MarksObtained) FROM StudentSubject ss INNER JOIN Student s on ss.StudentId=s.StudentId |
The query output is as follows:
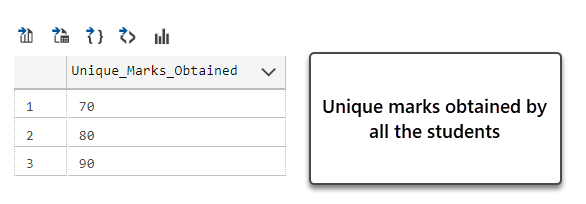
This information not only tells us students are brilliant but also see that the Marks column follows a unique pattern of 70, 80, 90. We can then use this pattern to build another table called Unique_Marks_Pattern and then investigate further.
Staging Data with Multiple Unique Columns in a Data Warehouse
This one is rather a rare or less common scenario but shows the tremendous power of SQL SELECT Distinct that changes your script to serve the purpose.
Assume you are a SQL/BI developer who is working on a staging data logic. Staging data logic means you are building SQL scripts to successfully pull the data from the sources for your data warehouse to be loaded initially into a staging environment which is quite a common practice in data warehouse business intelligence solutions.
The problem is you need to stage data from a table with multiple unique columns whereas in a standard practice you cannot introduce unique constraints on the staging tables as they should be free from any constraints for straightforward data transfer.
Let us see it in action by running the following script:
— Adding more rows to the StudentSubject table with existing subjects for the same students
|
1 2 3 4 5 6 7 8 9 |
-- Adding more rows to the StudentSubject table with existing subjects for the same students INSERT into dbo.StudentSubject (StudentSubjectId,StudentId,SubjectId,MarksObtained,TotalMarks) values (7,1,1,75,100), (8,2,1,85,100), (9,3,1,95,100) |
Now view the StudentSubject data:
|
1 2 3 4 5 6 |
-- View the updated student subject table SELECT ss.SubjectId,s.Name,sb.Name AS SubjectName,(ss.MarksObtained) FROM StudentSubject ss INNER JOIN Student s on ss.StudentId=s.StudentId INNER JOIN Subject sb on sb.SubjectId=ss.SubjectId order by s.name,sb.Name |
The results are shown below:
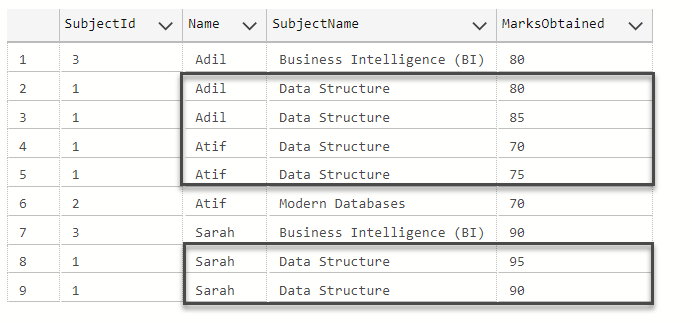
Now we are only keen to stage the data for student and subject from this table ignoring the marks obtained so a simple query will get us duplicates as follows:
|
1 2 3 4 5 6 |
-- Get all Student Subject rows SELECT s.Name,sb.Name as Subject FROM StudentSubject ss LEFT JOIN Student s on ss.StudentId=s.StudentId INNER JOIN Subject sb on sb.SubjectId=ss.SubjectId order by s.name,sb.Name |
The query output is as follows:
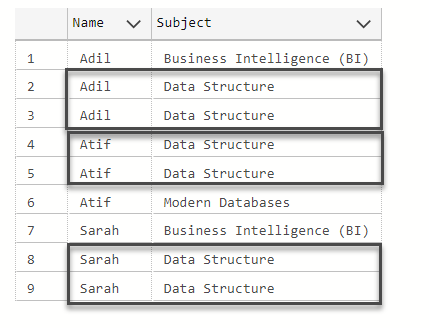
However, we need to build a staging script to only pull both unique student and subject and this is possible through SQL SELECT Distinct as follows:
|
1 2 3 4 5 |
-- Get both unique Student and Subject SELECT DISTINCT(s.Name) as Unique_Student_With,sb.Name as Unique_Subject FROM StudentSubject ss LEFT JOIN Student s on ss.StudentId=s.StudentId INNER JOIN Subject sb on sb.SubjectId=ss.SubjectId |
The result set is as follows:
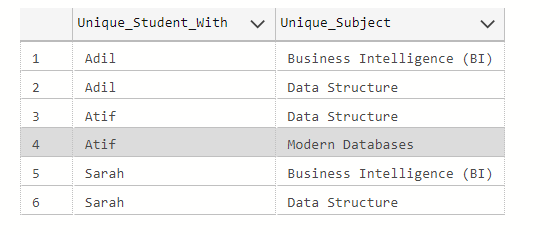
Finally, we can build a staging id column for further processing as follows:
|
1 2 3 4 5 |
-- Get staging id column based on both unique Student and Subject SELECT DISTINCT(CONCAT(s.Name,'-',sb.Name)) as Staging_Table_Id FROM StudentSubject ss LEFT JOIN Student s on ss.StudentId=s.StudentId INNER JOIN Subject sb on sb.SubjectId=ss.SubjectId |
The results are shown below:
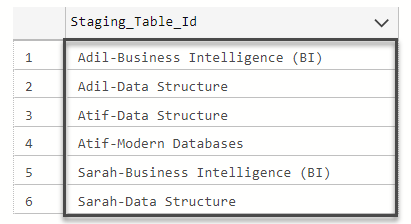
Conclusion
Congratulations, you have just learned the common use case scenarios of SQL SELECT Distinct with the help of examples.

He holds BSc and MSc Degrees in Computer Science and also received the OPF merit award.
He began his professional life as a computer programmer more than a decade ago, working on his first data venture to migrate and rewrite a public sector database driven examination system from IBM AS400 (DB2) to SQL Server 2000 using VB 6.0 and Classic ASP along with developing reports and archiving many years of data.
His work and interest revolves around Database-Centric Architectures and his expertise include database and reports design, development, testing, implementation and migration along with Database Life Cycle Management (DLM).
He has also received passing grade to earn DevOps for Databases verified certificate, an area in which he finds particular interest and potential.
View all posts by Haroon Ashraf
- How to create and query the Python PostgreSQL database - August 15, 2024
- SQL Machine Learning in simple words - May 15, 2023
- MySQL Cluster in simple words - February 23, 2023