

If you are working on SQL programming or learning SQL or how to write queries and looking to test your knowledge or prepare for any SQL interview, the below article can help you.
The objective of today’s article is to help you prepare for an Interview or test the knowledge you gain in your learning of SQL language. It covers the basic knowledge and advanced knowledge of SQL language and common scenario-based Interview questions that the Interviewer may expect you to answer.
Q1: What is Database Management System (DBMS)?
A database management system (or DBMS) is a computerized data-storing system. Users can perform various operations on this system to manage or manipulate the data structure. DBMSs are categorized in common categories as Relational databases, Object-oriented databases, Hierarchical databases, and Network databases.
Q2: What is RDBMS and difference between DBMS & RDBMS?
A relational Database Management System (RDBMS) is an advanced version of a DBMS. It provides the functionality of accessing the data more efficiently. It stores the data in the table in the form of rows and columns.
There are multiple differences between the DBMS and RDBMS systems, a few of which are listed in the below table.
DBMS | RDBMS |
|---|---|
Stores Data as a file | It stores data in table form |
DBMS, stores data either hierarchical or navigational. | RDBMS store data in tabular form with a column and rows format. |
DBMS supports one user. | It supports many users at the same time. |
Normalization not supported | RDBMS we can implement normalization. |
Suitable for small data sizes. | It can handle large amounts of Data. |
client-server architecture not supported | Supports client-server architecture. |
Data redundancy is common in this model. | Keys and indexes do not allow Data redundancy. |
No relationship between data | The foreign key concept for the relationship between tables |
Examples of DBMS are a file system, XML, Windows Registry, etc. | Example of RDBMS is MySQL, Oracle, SQL Server, etc. |
Q3: What are Primary and Composite Keys?
The primary Key is the key or column in a table that uniquely identifies each row or record in a table. For Example, the employee ID in the employee master table can be a primary key as there will be one employee id for one employee in the table.
Composite key: It is made of two or more columns or attributes that can uniquely identify the record in the table.
Q4: What is the Identity column?
The numeric column in a table that populates automatically by the database at the time of inserting the new record in the table is called the Identity column.
IDENTITY [ (seed, increment) ] is the syntax to declare a identity column. In this Seed is the first value which will be inserted in the table and Increment is the value by which every time the next value will increase.
Q5: What is the difference between WHERE and HAVING clauses?
Below are the major differences between the Where and Having clause
WHERE | HAVING |
It is used to filter data directly on the table. | It is used to filter the data of groups created on a table. |
It is applied as a row operation. | It is applied as a column operation. |
The WHERE clause pulls only the filter data based on the condition. | The HAVING clause fetches all data before applying the filter condition. |
You cannot use aggregate functions on the WHERE condition. | It is used on aggregate function on which group has performed. |
WHERE works with SELECT, UPDATE, and DELETE statement. | The HAVING works only with select statements. |
WHERE doesn’t need a GROUP BY clause? It can execute with or without GROUP BY. | Using HAVING GROUP BY is compulsory. |
Q6: What are Joins and Explain different types of Joins?
Join is used to fetch data between two or multiple tables as per the logical relationship in the table. These relationships are defined on basis of key columns. Below are different Types of Joins available in SQL Server as follows.
Inner join: Returns the row common between two tables. |
Left Join: In this, all the data from the left and matching records from the other (right) tables are returned |
Right Join: In this, all the data from the Right and matching records from the other (left) tables are returned |
Cross Join: it is the cartesian product of the table. It returns all the rows with all possible combinations. |
Q7: What is a Self-Join? Explain with an example.
Self-join is to join a table itself I.e., using a normal join condition we can join a table with the same table again on basis of columns. It is generally used for getting a hierarchal kind of data or comparing rows with the same table.
The general scenario of this join is getting the manager details of the employee. For example, in the employee table for an employee, we have a column for manager id which again has the employee id of a different employee who is the manager of this employee. Using self-join we can retrieve this kind of hierarchical data.
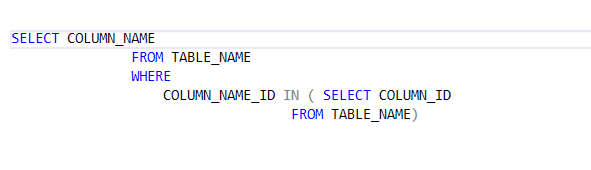
Q8: What is a subquery in SQL Server?
A subquery is a query which generally used within the main Query. It is generally embedded with a where clause. Below is the syntax of a subquery. The subquery executes before the main query.
Q9: Difference between correlated query and subquery in SQL Server.
Correlated Queries are one of the types of subqueries where it output of the query is dependent on the outer query. In this case, the outer query executes first and on basis of the correlated query executes.
Q10: What are ranking functions in SQL Server Explain.
Ranking functions are the functions that return the rank of a row in a particular partition. These are non-deterministic functions. There are four ranking functions available in the SQL Server as described below.
RANK: Returns the rank of each row for partition. The rank is defined as one plus the rank or number of previous rows. When two rows in the partition are the same then they are assigned the same rank and the next rows will be having increased rank.
NTILE: it distributes the rows of an ordered partition in a specified number of groups.
DENSE_RANK: This function returns the rank of each row within a result set partition, with no gaps in the ranking values. For the same rows, it returns the same rank, and the next rank will be the next number without skipping any.
ROW_NUMBER: Returns the sequential number to each row of a partition of the result set. RANK and ROW_NUMBER are the same where rank provides the same number for ties for example (12245) while row number provide a number to each row like (1,2,3,4,5)
Q11: What are temporary tables in the SQL server?
Temporary tables are the tables created in the SQL server temporarily. These tables are used when we need to access some data multiple times in our code. These tables are having # as the suffix.
You can create temporary tables using the syntax
Create Table #table_name(Id Int, Emp_name varchar(100)) and also by using into command.
Q12: Difference between temporary table and table variable in SQL server.
Below are a few differences between temporary table and table variable:
Temp table results can be used till the SQL query window session is open. | A table variable can be used in a single query session. |
The temp table gets created in TempDB. | The table variable gets created in memory and it moves to TempDB when holds the large dataset. |
The temp table allows the DDL and DML operation and creation of the index. | In the table variable, you can create a clustered index. |
The temp table cannot be used in UDF. | Table Variables can be used in UDF. |
Temp table can be accessed in nested stored procedures. | Table variables can’t be accessed in the nested stored procedure. |
Q13: What is the difference between Delete and Truncate?
There are many differences between delete and truncate, a few of them are listed in the below table.
The DELETE command in SQL deletes the rows on basis of the condition provided. | Truncate purges all the rows. |
Delete is a DML operation | Truncate is a DDL operation |
Delete rows one by one | removes row in one go |
it records the transaction in the log file | It doesn’t record transactions in log files as it deallocates pages, not individual rows. |
Delete doesn’t re-seed the identity column to its seed value. | Its re-seed identity column to its seed value |
It is slower for large tables or records | It is faster for tables |
Q14.What is materialized view? Difference between materialized view and a view?
A materialized view is the view that physically has the data. It works like a table. Views are the virtual table where content is defined by a query i.e., you can write a query selecting different columns and store that query in the database as a view. It doesn’t hold any data.
You can also read about the updateable view to prepare for an interview in deep.
Q15.What is Common Table Expression or CTE?
A Common Table Expression also called CTE in short form is a temporary named result set that you can reference within a SELECT, INSERT, UPDATE, or DELETE statement. Read in more detail for other answers.
Q16.What is the Stored procedure?
A stored procedure is a group of SQL statements or programs that perform the required business logic. This is stored as a database object in the database server.
Q17.Difference between stored procedure and UDF.
A function has a return type and returns a value | A procedure does not have a return type. But it returns values using the OUT parameters |
DML can’t be part of User Defined function | While the procedure support DML queries |
No output parameter for the function | The procedure can have input and out parameters |
Transactions cannot be part of UDF | The transaction can be part of the Procedure |
Functions can’t call a stored procedure | the stored procedure can use UDF |
The function can be used in select statements | The stored procedure cannot be a part of the function |
Q18. What are Indexes in SQL Server?
Indexes are special data structures that help fast retrieval of data and optimize the query. These are the same as an index in a book using which SQL server can reach the page directly where queried data is stored.
There are mainly two types of indexes in SQL Servers Clustered Index and Non-Clustered Index.
Conclusion
Above is the list of common interview questions which you can expect as an SQL server developer. The answers are for your reference you can read them in detail using other sources or articles available.

Skill summary:
1. SQL Server DB Administration
2. SQL Server DB Model Development
3. SQL Server TSQL or complex query writing
4. MSBI SSIS, SSRS, and SSAS expertise
5. Various other BI tool Expertise
- Understanding the Scalability in Oracle Database - March 9, 2023
- Migrating Oracle Database to Azure SQL Database - February 9, 2023
- Common SQL Interview Questions and Answers - January 6, 2023