
In this article, we will learn how to implement the median functionality and wrap it into a SQL median function
Introduction
Calculations are an integral part of data analysis. Often business logic implemented in programmable database objects involves numerous calculations using a variety of mathematical formulae and operators. When it comes to calculations, statistics play an important role. When the data is huge and an exact calculation is not possible for each data point, statistics come to the rescue. Statistics can be divided into two branches – descriptive and inferential. Often most basic calculations use descriptive statistics, and at advanced levels where things like machine learning are being employed, inferential statistics like regression, classification, and other methods come into the picture. Descriptive statistics involves the part of statistics where we perform data profiling or exploration to describe the characteristics of data. Some simple examples of statistical calculations are max, min, mean, median, mode, etc which almost everyone would know. To make it convenient for database developers to employ this functionality, databases often wrap this functionality in the form of statistical functions. It may come as a surprise to many that while functions like min, max, and average are commonly available in databases, the median function is not so commonly available. Be it SQL Server or Postgres, in many versions of such industry-leading databases, we won’t find a ready-to-use median function to employ the median functionality or calculation, and we will have to resort to SQL-based programming to do this calculation. Though it may like a complex calculation to perform, it’s not that hard to implement.
Setting up an Azure SQL Instance
To create our SQL Median function, we need a database in place with some sample data in it. If we do not have sample data, we can create some as well. To make things easier and faster from a setup perspective, if you already have a SQL Server instance, you can use it. If you don’t, using a cloud account and setting up an instance on the cloud is another alternative. For those who do not already have the database setup in place, we will quickly look at setting up an Azure SQL instance on the Azure cloud.
To create a new instance of Azure SQL, log on to the Azure portal and navigate to the Azure SQL service dashboard and click on the button the create a new instance. The wizard to create the instance would be activated and we would be presented with a screen as shown below.
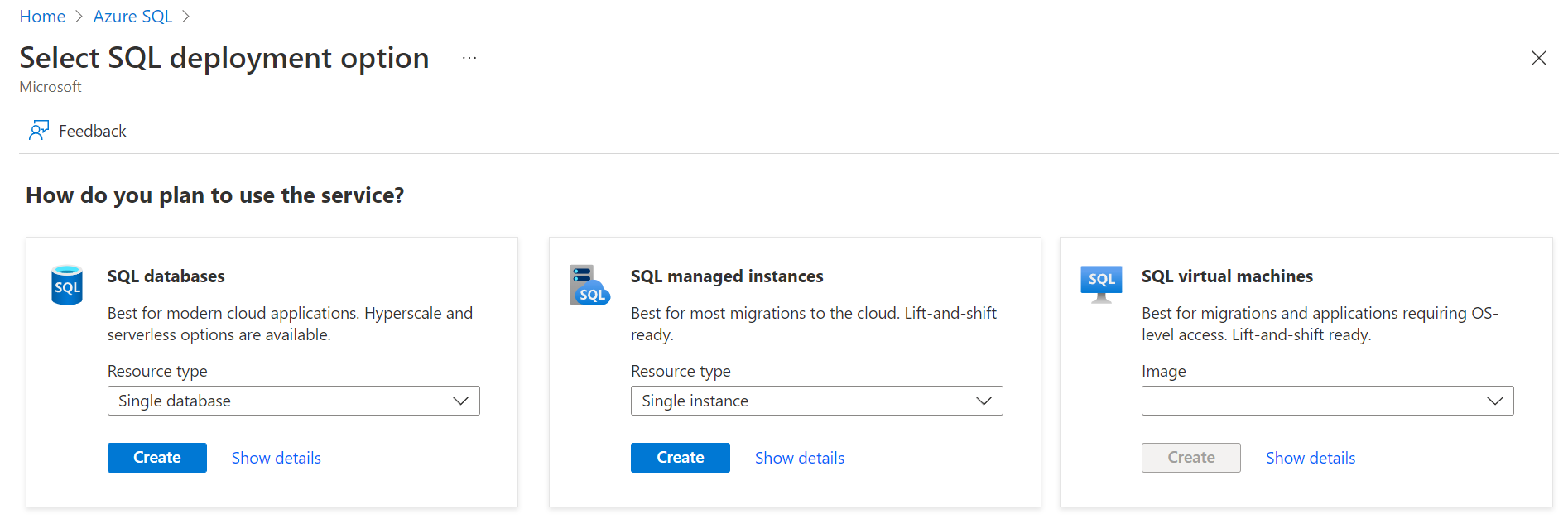
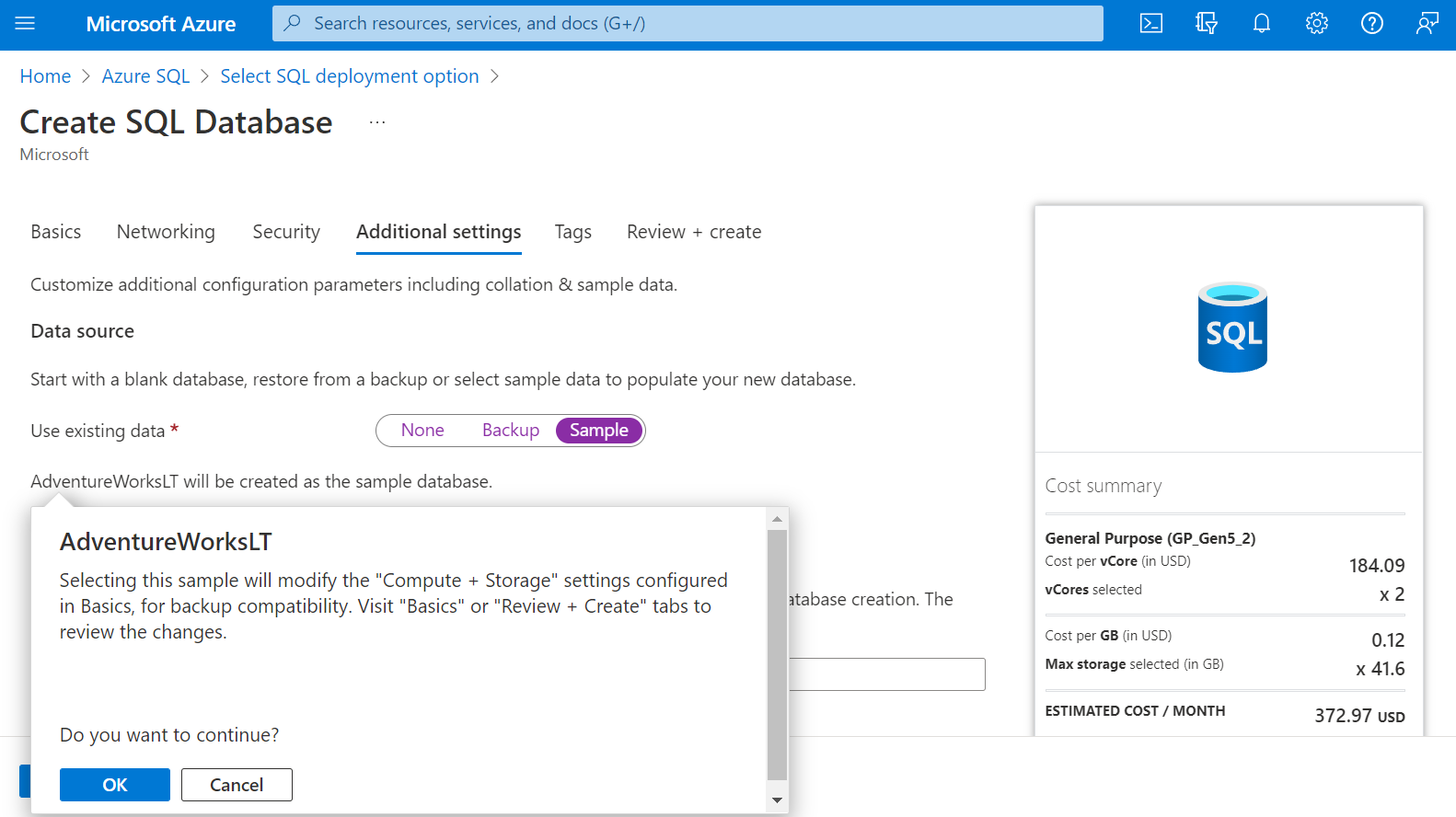
We intend to use the SQL Database option and we will use the resource type as a single database option. Click on the Create button to proceed to the next step. Now we would be taken to the actual wizard that has all the steps to create the new instance. Continue with the different steps and fill in the appropriate details. Once you reach the additional settings page, the option to use existing data should be set to the value of Sample as shown below. This will create the AdventureWorkLT sample data in the database. This is one of the easiest ways to create a database with sample data in it.
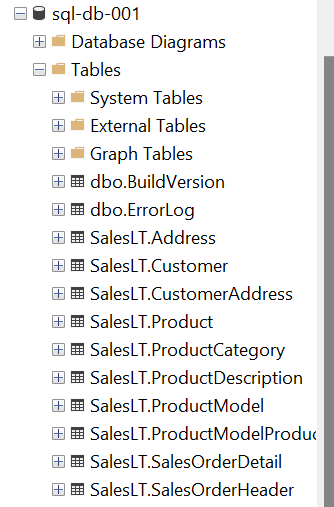
Once the database instance is created, we would need an editor to access this instance. SQL Server Management Studio (SSMS) is the freely available editor from Microsoft, that can be used to access the database instance hosted on the Azure SQL database. It’s assumed that you have this setup already in place and can access the database instance. Once you access this instance, it would look as shown below with the sample data already created.
What is a median?
In simple words, the median is the middle value of a range of values in sorted order. Let’s say that if we have a range of values from 1 to 11, the number 6 will be the median as it’s the middle value that sits between the upper half and lower half of the range. If the range is an even number, i.e., let’s say 1 to 10, then the median would be 5.5.
Creating a SQL Median Function – Method 1
We learned above how the median is calculated. If we simulate the same methodology, we can easily create the calculation for the median functionality. Let’s create a new table for the sake of simplicity and add a few random values to it as shown below.
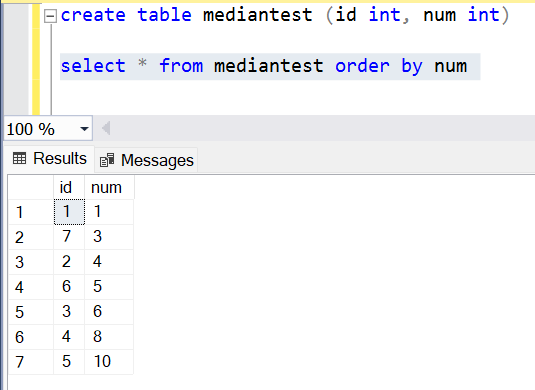
Once the table is created, we can now query this data in multiple parts and combine it using the RANK function and a CTE. Firstly, we would query the 50 percent of data in ascending order and select the maximum value, which would be the middle value. And then we would query another 50 percent of data in descending order and select the minimum value, which would again be the middle value. Either we would get the same value twice or we would get two values sitting on the border of the first half and second half. So, the two max and min values that we would query, dividing them by half would give us the median. This logic can be implemented for a SQL median function as shown below.
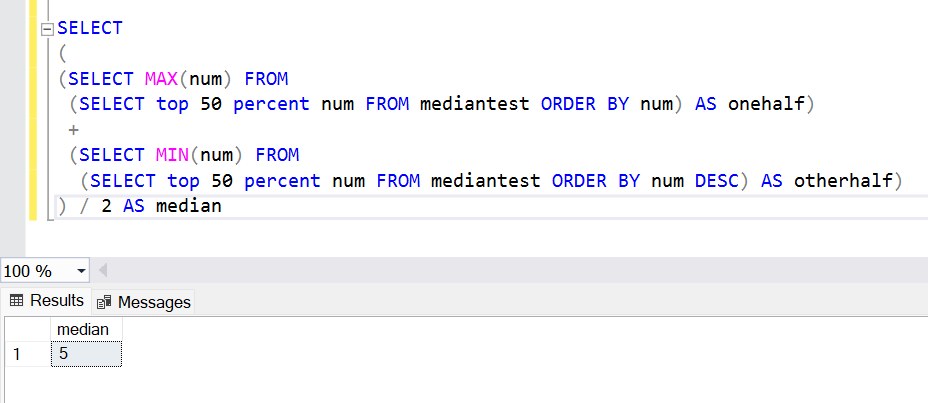
In this way, we can easily create the SQL median function using this logic and wrapping it in a function. While this is one way to do it, it may not be the most efficient way from a query engine perspective. SQL Server provides one another function, using which we can calculate the SQL median functionality. Let’s look at it.
Creating a SQL Median Function – Method 2
SQL Server consists of a function named percentile_cont, which calculates and interpolates the data based on the given percentile, which is an input parameter for this function. The syntax of the function is as shown below.

The numeric_literal parameter in the below syntax is the percentile value we want. In our case, the median is at the center of the range, so it must be 0.5 percentile. The group that we are going to use would be the id field as we want to find the percentile within a group of records. Within the group, this function would partition the data by a given key. If we have unique values in the key for every record, we will not get the desired output. In our case, we want to find the median from the 7 records we have in our table. As the function would partition the data by a key, and we want all our records in the same partition, we can just update the records to have the same id, so that they become part of the same partition when the function executes. After updating the key to make it common for all records, it would look like the one shown below.

Now that we have the data in place, it’s time to form the query. The query would look as shown below. Here we are selecting the actual fields and adding a new field to calculate the median using the percentile_cont system function. We are passing the parameter value of 0.5 to this function. We are ordering the data by the numeric values from which we intend to find the median, and we are partitioning the data by the id field. As all the records have the same id, they would fall in the same partition, and then the median would be calculated from this partition.
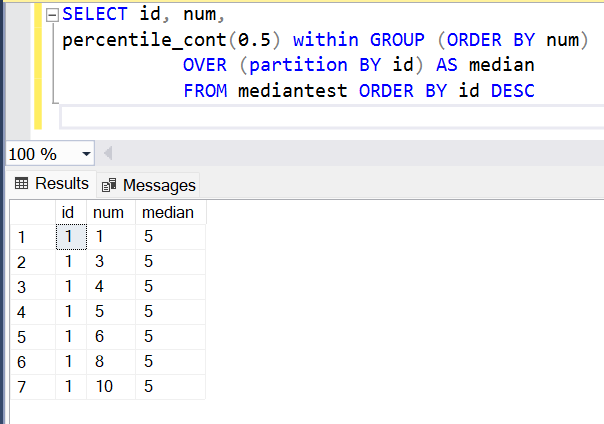
Once the query executes, the result would look as shown above in the results pane. The median value from the given range of data is 5. This logic can be easily wrapped up in a function using the create function command with a parametrized value to create a SQL Median function.
Conclusion
In this article, we learned the concept of a median and practically learned two methods with an example of how to create a SQL median function.

She has a deep experience in designing data and analytics solutions and ensuring its stability, reliability, and performance. She is also certified in SQL Server and have passed certifications like 70-463: Implementing Data Warehouses with Microsoft SQL Server.
View all posts by Gauri Mahajan
- Oracle Substring function overview with examples - June 19, 2024
- Introduction to the SQL Standard Deviation function - April 21, 2023
- A quick overview of MySQL foreign key with examples - February 7, 2023