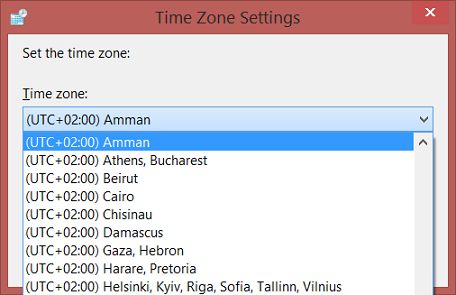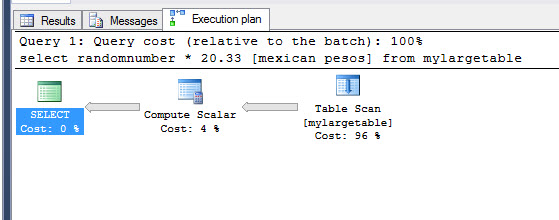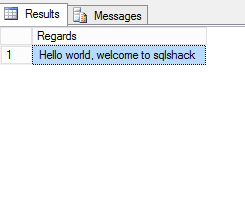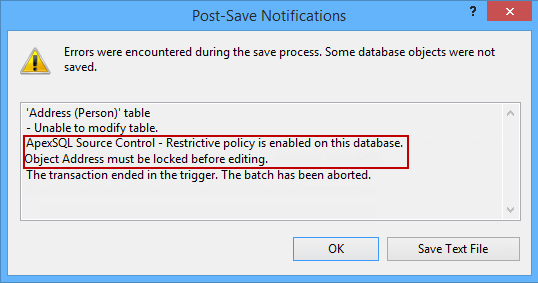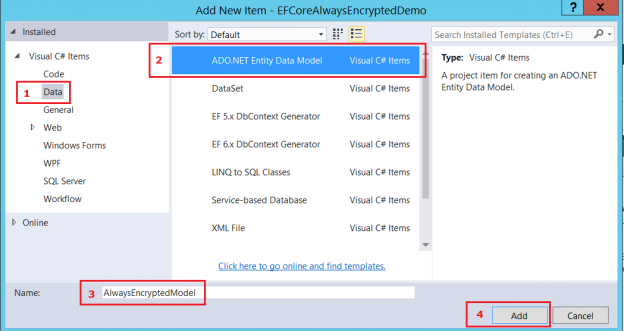
Introduction
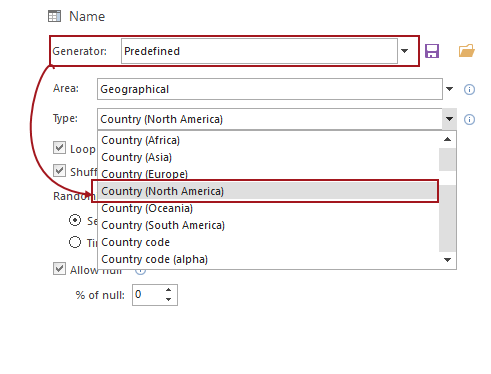
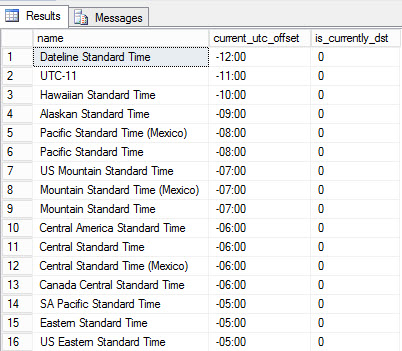
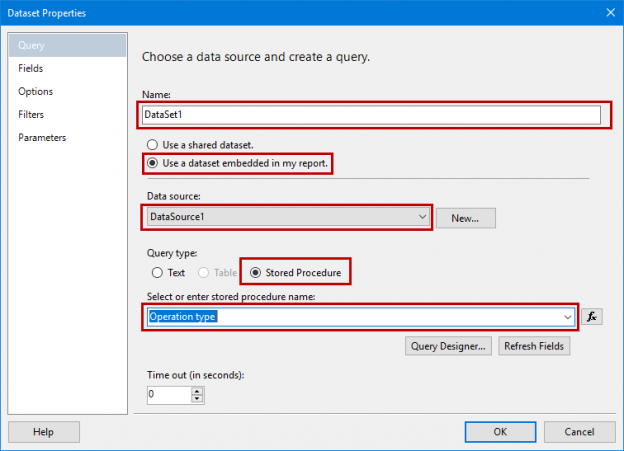
The title of this post should have been “How to implement wildcard search functionality with Always Encrypted, make deterministic encryption safer, and load initial data using SqlBulkInsert”, but as you understand, that’s just too long for a title.
Read more »