
What is static data
Static data (aka Code, Lookup, List or Reference data), in the context of a relational database management system, is generally data that represents fixed data, that generally doesn’t change, or if it does, changes infrequently, such as abbreviations for US states for example e.g. ME, MA, NC. This data is typically referenced, extensively, by transactional type data. For example, an customer table would have references to static table for City name, State or province, Country, Payment terms e.g. NET 30 etc.
Other examples of static data would be lists of things like Guitar manufacturers, internal abbreviations for company departments, names of all of the countries in the EU.
Static data usually isn’t large and in some cases, can be as little as two or three rows like surnames Mr. Mrs., Ms. etc.
A closer look
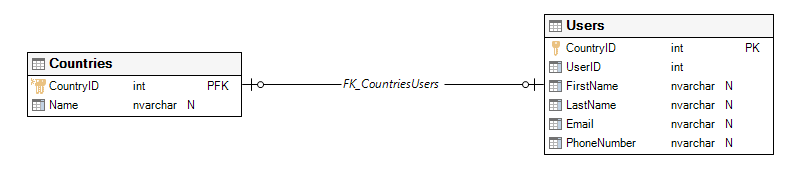
Static data is a key part of any normalized data structure. Rather than using data repetitively in a table, like “United States”, it is more efficient to create a table called countries, and assign an ID to each country, and reference the ID in transactional data, where it might be implemented thousands or even millions of times. Thus, the Country table becomes static data, referenced by other, transactional type tables whenever needed.
Sure, new countries are created from time to time e.g. Southern Sudan, but in general the list is fairly static over time, particularly with lists like the names of the states in America, which hasn’t changed since 1959 *
Here is an example of a Static data table:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
CREATE TABLE [dbo].[Countries] ( [CountryID] [int] IDENTITY(1, 1) NOT NULL, [Name] [nvarchar](1) NULL, CONSTRAINT [PK__Countrie__10D160BF81AE8538] PRIMARY KEY CLUSTERED ([CountryID]) ON [PRIMARY] ) ON [PRIMARY] GO |
Static data can usually be found from drilling down from the user interface via picklists. Anything demonstrated to the user as a Literal e.g. Alabama, Arkansas etc., will have a corresponding Value that is actually stored with the record. In our example, the picklist will show the Literal e.g. Ireland but store the Value e.g. 107 in the users table
* Images courtesy of ApexSQL Doc
Why version control static data?
As we know that not having static data in our database, isn’t a possibility, for the purpose of this article we assume that the alternatives would be generating synthetic test data for the static tables and/or in using data from production. Versioning static data will be compared to these options and advantages listed.
To manage tight coupling with business logic, static data referenced in business logic
Static data is often considered akin to the database structure itself, because, rightly or wrongly, static data is often coupled with database logic, particularly with poorly designed databases and clients.
If we want to calculate the amount of money we’ll pay in Sales tax, we would normally have a table by states, grouped by rates.
But we might have a scenario where some logic references states by their IDs directly E.g. 44 for “North Carolina”. Worse, we may have someone using a “magic number” (although it isn’t actually a number) in the code of “NC”.
In either of these two scenarios, forgetting for a moment the potential problems that could happen with changes to tax rates, etc. or the general brittleness of the system, a test plan that implements synthetic data could break the first scenario (if only 40 states were generated) and would most certainly break it if the random value of “NC” wasn’t by luck, created by the test data plan.
You could easily set up logic to ensure exactly 50 states were generated, or import the list of states into your test generation plan. But other scenarios can be more complicated and more difficult to simulate with test data. A simple solution might be to just use the actual static data itself.
Although these are kind of extreme examples, using poor design and coding practices, many other examples exist (see below).
Here is one I found on StackOverflow
“my users can change their setting, and their configuration is stored on the server. However, there’s a system-wide default value for each setting that is used in case the user didn’t override it. The table containing those default settings grows as more options are added to the program. This means that when a new feature/option is checked in, the system-wide default setting is usually created in the database as well.”
In general, we don’t want any chance of our test data breaking our application or database in QA e.g. false negatives. We want to be generating only real bugs.
To avoid breaking hard coded unit tests
Even on a system that is well designed, with no hard coded “magic” numbers in the business logic, we can still run into problems when the database is reviewed and tested as part of a continuous integration workflow using SQL Server unit tests. Writing good Unit tests for SQL Server is hard, and resisting the temptation to test vs hard coded values in the test phase of a deployment is even harder. So even the most well intentioned DBA, can wind up with broken unit tests, if static data isn’t managed properly during continuous integration process, by testing against production static data vs automatically generated, synthetic test data.
Because we can; Static data is generally smaller data
Static data going to be smaller in volume than transactional data due to the fact that it is based on some finite list. The number of transactions your company processes in a day might be in the millions, but the number of states in America has remained at 50 since 1959 *
The fact that static data sets are usually small, make it possible to version them in source control repositories, that aren’t designed to store large amounts of data, like a typical database is.
So, in this case, one strong reason for versioning static data is that we can
To track and audit changes
It is called static data, not because it doesn’t change, but because it doesn’t change often. There is a large spectrum from data that won’t ever change e.g. the list of Roman emperors to data that changes infrequently, but still does change, like the names of countries e.g. South Sudan.
Based on the fact that static data is so critical to a database processing correctly, tracking changes is also important. We want to know when our static data changes, who changed it and when, just like we want to know when a stored procedure was updated. Version controlling allows us to do that.
Production data might be pulled down to QA to load up static tables, but key information about changes wouldn’t be tracked. By version controlling static data, you gain the benefits of “real” production data but also layer on change tracking and auditing. All changes are tracked by date, user etc. and can easily be rolled back, if needed
To see realistic data
When building a QA database from scratch, 100% synthetic test data can be used, the operative word being “can”. Depending on the sophistication of the tool you use, you might have names like “Axd Bemioyz” or “Sam Shepherd”. The former may be Ok for transactional data, but even if your client software and database are designed well, without hard coded references, you may still want your test environments to reflect data that is as close to “real world” as possible. By synthetically generating static data, you may confuse or distract your testers with unfamiliar and strange data strings that are ubiquitous in your app, showing up in all picklists, reports etc.
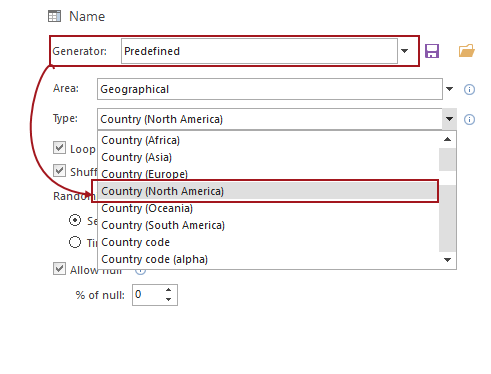
SQL Server test data generators like ApexSQL Generate can narrow the gap between unrealistic data like “Aud Bemioyx” and realistic values like “Sam Shepherd”. It can even apply generators with realistic data like country names or user’s information to mimic real production data:
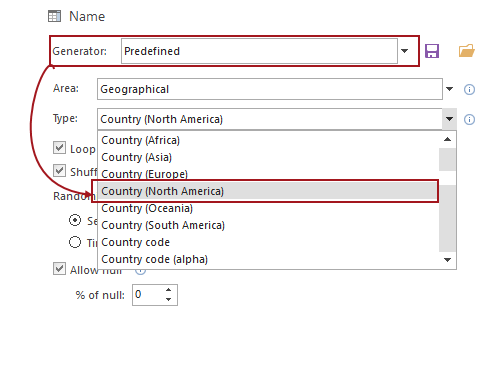
After using the predefined generator, the overview of the static data prepared to be inserted is as follows:
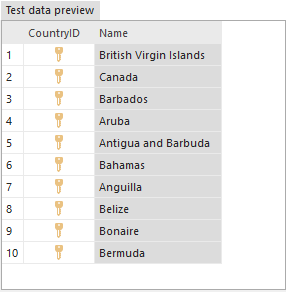
Even though these tools are fast and easy to use, in most cases, it may be marginally less time to simply work with the real data itself, at least in the case of static data. The optional test plan uses version controlled static data in combination with automatically generated test data
How to version control static data
Now that we’ve reviewed static data and why it can be such an important part of a continuous integration and delivery process, and therefore why it should be versioned in source control, we can look at ways to implement it. We’ll look at ways to Get static data into a repository, managing changes and getting it out when you want
To do this I’ll link to articles showing, literally, the ins and outs of Static data using a variety of tools from ApexSQL
Get in – The first challenge is getting static data into a source control repository
- How to link and initially commit SQL Server database static data
- How to commit and/or update SQL Server database static data to a source control repository
- How to commit SQL Server table static data to a source control repository
Get it changed – Once it is in, you’ll want to know how to manage changes by checking out scripts, changing them and checking them back into the repository
Get it out – Finally, once static data has been successfully committed, and all changes has been updated, you’ll want to know how to get it out when you need to, to synchronize against a QA or PROD database or integrate into a Continuous integration or delivery workflow process
- How to pull version controlled SQL Server database static data from a repository
- How to deploy static data from SQL source control to database
- How to apply static data under source control to a SQL Server database
* The last state added to the U.S was Hawaii. Hawaii was declared a state on August 21, 1959.

He uses his spare time to play guitar, ride a bike and hang out with his friends. During winter, he likes skiing the most, but all other snow activities, too.
He is also author of various SQL Shack articles about SSIS packages and knowledgebase articles about ApexSQL Doc.
View all posts by Marko Radakovic