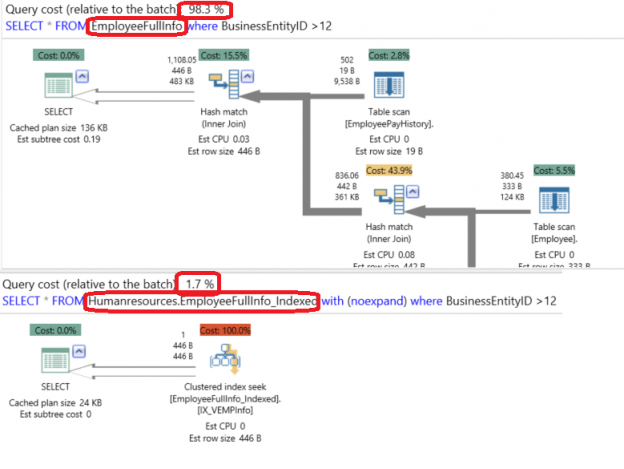
SQL Server Views are virtual tables that are used to retrieve a set of data from one or more tables. The view’s data is not stored in the database, but the real retrieval of data is from the source tables. When you call the view, the source table’s definition is substituted in the main query and the execution will be like reading from these tables directly.
Read more »