
Because databases aren’t always designed efficiently, data is sometimes stored in ways that make sorting and searching extremely difficult. Requests for meaningful, informative reports from such data, however, still must be fulfilled.
Note: This applies to SQL Server 2012 and higher.
SCENARIO
I have a preexisting table of 96 rows of company store locations and their respective phone contact numbers. There is one record for each store, each having a single ‘PhoneNumbers’ field that contains three separate phone numbers: the main store number with or without an extension, a secondary store number, and a mobile phone number. The phone data is very messy (all three numbers are crammed together into one field) and cannot easily be searched or sorted.
|
1 2 3 4 |
USE COMPANY; SELECT TOP 10 * FROM Locations; |
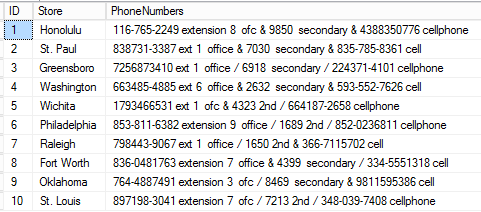
As you can see, the store numbers are delimited by either a slash (/) or an ampersand (&). The ‘main’ phone numbers are followed by one (or none) of the following text: ‘x’, ‘ext’, ‘extension’; an extension number; and then the text ‘ofc’, ‘main’, or ‘office’. The ‘secondary’ phone numbers are trailed by either the text ‘2nd’ or ‘secondary’; while the final ‘mobile’ numbers are followed by the text ‘cell’ or ‘cellphone’.
Our objective is to parse the three separate kinds of phone numbers, implement consistency, and return the parsed data so that each phone number is on a separate row (unpivoting).
PARSENAME
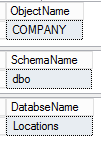
Our first step will be to parse the phone numbers on the delimiters. One method that neatly accomplishes this is the using the PARSENAME function. The PARSENAME function is logically designed to parse four-part object names – distinguishing between server name, database name, schema name, and object name:
|
1 2 3 4 5 |
SELECT PARSENAME('COMPANY.dbo.Locations',3) AS 'ObjectName'; SELECT PARSENAME('COMPANY.dbo.Locations',2) AS 'SchemaName'; SELECT PARSENAME('COMPANY.dbo.Locations',1) AS 'DatabseName'; |
The syntax to use for PARSENAME is:
|
1 2 3 |
PARSENAME ( 'object_name' , object_piece ) |
The first parameter is the object to parse, and the second is the integer value of the object piece to return. The nice thing about PARSENAME is that it’s not limited to parsing just SQL Server four-part object names – it will parse any function or string data that is delimited by dots:
|
1 2 3 4 |
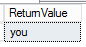
USE COMPANY; SELECT PARSENAME('Whatever.you.want.parsed',3) AS 'ReturnValue'; |
|
1 2 3 4 5 |
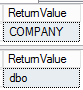
DECLARE @FourPartName NVARCHAR(100) = SCHEMA_NAME()+'.'+DB_NAME(); SELECT PARSENAME(@FourPartName,1) AS 'ReturnValue'; SELECT PARSENAME(@FourPartName,2) AS 'ReturnValue'; |
Let’s use PARSENAME to separate the three types of phone numbers. To simplify things, let’s use a bit of code with the REPLACE function to replace the delimiters with the expected ‘object part’ separator (dot):
|
1 2 3 4 5 6 |
--replace all delimiters with the object part separator (.) USE COMPANY; SELECT ID, Store, REPLACE(REPLACE(PhoneNumbers,'&','.'),'/','.') AS PhoneNumbers FROM Locations; |
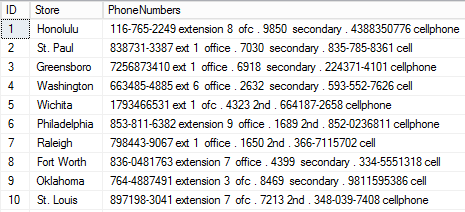
We should now have the PhoneNumbers field values returned in this format: [main number].[secondary number].[mobile number]. Now we can use PARSENAME against the table’s delimiter-replaced data. PARSENAME will see the PhoneNumbers string as follows: [main number] = ‘object name’, [secondary number] = ‘schema name’, and [mobile number] = ‘database name’ – because of the order of the delimited data positions. We’ll use a Common Table Expression (CTE) called ‘replaceChars’ to run PARSENAME against the delimiter-replaced values. A CTE is useful for returning a temporary view or result set. We’ll return the original PhoneNumbers field as well, for comparison purposes:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
USE COMPANY; WITH replaceChars (ID, Store, PhoneNumbers) AS ( --replace all separators with the object part separator (.) SELECT ID, Store, REPLACE(REPLACE(PhoneNumbers,'&','.'),'/','.') AS PhoneNumbers FROM Locations ) SELECT * FROM ( SELECT ID, Store, PhoneNumbers, PARSENAME(PhoneNumbers, 3) AS [Main], --returns 'object name' PARSENAME(PhoneNumbers, 2) AS [Secondary], --returns 'schema name' PARSENAME(PhoneNumbers, 1) AS [Mobile] --returns 'database name' FROM replaceChars )x; |
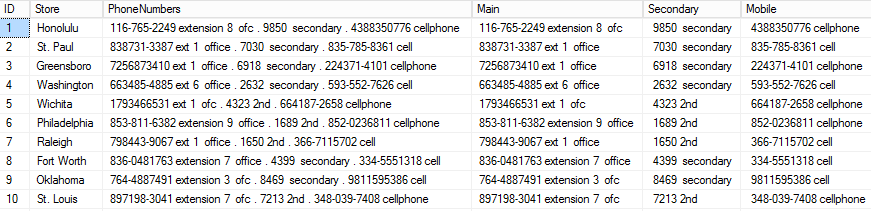
Based on the replaced delimiter values, PARSENAME returns each section of the PhoneNumbers field by its position in the data string. Each of the three types of numbers now has its own field.
UNPIVOT
Our next task is to make sure each number for a given store is displayed on a separate record. Essentially, we want to convert some columns into rows. The UNPIVOT function was designed exactly for scenarios like this. Since we have three distinct types of values (Main, Secondary, and Mobile), we can designate them to be rotated and consolidated into a new field (‘Number’) and labeled by another new field (‘Precedence’) – all by using UNPIVOT:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
USE COMPANY; WITH replaceChars (ID, Store, PhoneNumbers) AS ( --replace all separators with the object part separator (.) SELECT ID, Store, REPLACE(REPLACE(PhoneNumbers,'&','.'),'/','.') AS PhoneNumbers FROM Locations ) SELECT * FROM ( SELECT ID, Store, PhoneNumbers, PARSENAME(PhoneNumbers, 3) AS [Main], --returns 'object name' PARSENAME(PhoneNumbers, 2) AS [Secondary], --returns 'schema name' PARSENAME(PhoneNumbers, 1) AS [Mobile] --returns 'database name' FROM replaceChars )x UNPIVOT ( [Number] for Precedence in ([Main], [Secondary], [Mobile]) --rotate the three phone fields into one )y ORDER BY ID; |
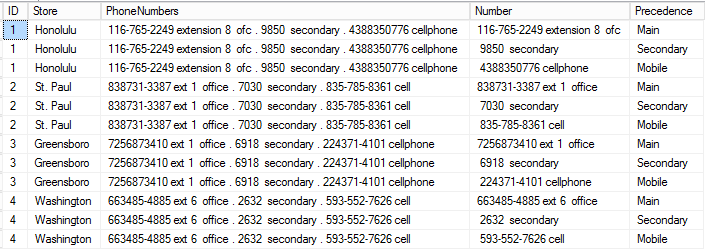
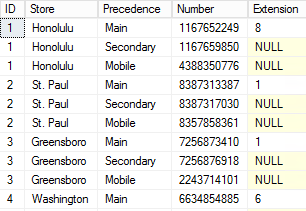
Note that each store now has three records to accommodate the three types of phone number. The UNPIVOT function has allowed us to effectively rotate the three new phone number columns into rows – facilitating a more normalized table structure.
CLEANING THE DATA
Now that we’ve done the heavy lifting needed to parse and rotate the phone numbers, let’s spend some time cleaning up the inconsistencies in the data.
One improvement that can be made is to pull out the extension numbers that are associated with the Main numbers. We know that all extensions are referenced by either ‘x’, ‘ext’, or ‘extension’, so we can use the SUBSTRING and CHARINDEX functions to extract the single-digit extension numbers. We’ll generate a new field (‘Extension’) for these values in the return statement:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
USE COMPANY; WITH replaceChars (ID, Store, PhoneNumbers) AS ( --replace all separators with the object part separator (.) SELECT ID, Store, REPLACE(REPLACE(PhoneNumbers,'&','.'),'/','.') AS PhoneNumbers FROM Locations ) SELECT ID, Store, PhoneNumbers, [Number], Precedence, CASE WHEN CHARINDEX('extension',[Number]) > 0 THEN SUBSTRING([Number],CHARINDEX('extension',[Number])+10,1) --extract the extension number WHEN CHARINDEX('ext',[Number]) > 0 THEN SUBSTRING([Number],CHARINDEX('ext',[Number])+4,1) --extract the extension number WHEN CHARINDEX('x',[Number]) > 0 THEN SUBSTRING([Number],CHARINDEX('x',[Number])+2,1) --extract the extension number END AS [Extension] FROM ( SELECT ID, Store, PhoneNumbers, PARSENAME(PhoneNumbers, 3) AS [Main], --returns 'object name' PARSENAME(PhoneNumbers, 2) AS [Secondary], --returns 'schema name' PARSENAME(PhoneNumbers, 1) AS [Mobile] --returns 'database name' FROM replaceChars )x UNPIVOT ( [Number] for Precedence in ([Main], [Secondary], [Mobile]) --rotate the three phone fields into one )y ORDER BY ID; |
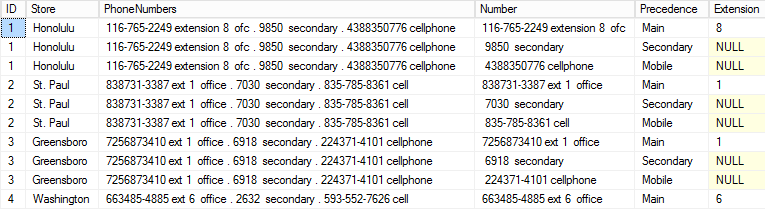
We’ve successfully extracted the extension numbers from the Main numbers into a new field. Remember, only Main numbers have an associated extension, so the others will be NULL.
Our next challenge is to do the following:
- Remove the intermittent dashes (-) from all numbers for standardization.
- Remove leading whitespaces.
- Separate the numbers from all trailing text.
- Prepend the four-digit Secondary numbers with the first six numbers from its respective store’s Main number – it can be assumed that each Secondary phone has the same area code and exchange as its associated Main number does.
For steps one and two, we’ll employ the REPLACE and LTRIM functions:
|
1 2 3 |
LTRIM(REPLACE([Number],'-','')) |
This combination removes leading whitespaces and eliminates dashes.
For step three, we’ll wrap the above solution in the SUBSTRING function:
|
1 2 3 |
SUBSTRING(LTRIM(REPLACE([Number],'-','')),1,10) |
For Secondary numbers, we’ll use a different ‘length’ argument value, since they have only four digits:
|
1 2 3 |
SUBSTRING(LTRIM(REPLACE([Number],'-','')),1,4) |
LAG
For our fourth step, we can use the LAG function (new for SQL Server 2012) – it allows referencing of previous records (exactly what we need to do to grab the first six characters from each store’s Main number):
|
1 2 3 |
LAG(SUBSTRING(LTRIM(REPLACE([Number],'-','')),1,6)) OVER (ORDER BY ID) |
We’ll append those results with the extracted Secondary number. Putting it all together, we have a complete solution. We can now also eliminate the original PhoneNumbers field:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
USE COMPANY; WITH replaceChars (ID, Store, PhoneNumbers) AS ( --replace all separators with the object part separator (.) SELECT ID, Store, REPLACE(REPLACE(PhoneNumbers,'&','.'),'/','.') AS PhoneNumbers FROM Locations ) SELECT ID, Store, Precedence, CASE WHEN Precedence = 'Secondary' THEN LAG(SUBSTRING(LTRIM(REPLACE([Number],'-','')),1,6)) OVER (ORDER BY ID) + SUBSTRING(LTRIM(REPLACE([Number],'-','')),1,4) --prepend Secondary numbers with the first six numbers of the store’s Main number ELSE SUBSTRING(LTRIM(REPLACE([Number],'-','')),1,10) END AS [Number], CASE WHEN CHARINDEX('extension',[Number]) > 0 THEN SUBSTRING([Number],CHARINDEX('extension',[Number])+10,1) --extract the extension number WHEN CHARINDEX('ext',[Number]) > 0 THEN SUBSTRING([Number],CHARINDEX('ext',[Number])+4,1) --extract the extension number WHEN CHARINDEX('x',[Number]) > 0 THEN SUBSTRING([Number],CHARINDEX('x',[Number])+2,1) --extract the extension number END AS [Extension] FROM ( SELECT ID, Store, PhoneNumbers, PARSENAME(PhoneNumbers, 3) AS [Main], --returns 'object name' PARSENAME(PhoneNumbers, 2) AS [Secondary], --returns 'schema name' PARSENAME(PhoneNumbers, 1) AS [Mobile] --returns 'database name' FROM replaceChars )x UNPIVOT ( [Number] for Precedence in ([Main], [Secondary], [Mobile]) )y ORDER BY ID; |
ANALYSIS & FINAL STEPS
The Locations table’s data has now been parsed, rotated, cleaned, and standardized to the given requirements. It is now in a highly searchable and sortable format, and can be easily inserted to a new, permanent table that could replace the original.
Some remaining steps that could be tackled would be to
- Normalize the data further – for example, if a ‘Store’ table exists, we could replace the Store field in the Locations data with one containing Store IDs, and establish referential integrity with a foreign key to the primary key of the Stores table.
- Add appropriate indexes to the tables based on historical or anticipated queries.
See more
Consider these free tools for SQL Server that improve database developer productivity.


His hobbies include American Constitutional studies, musicianship, and blog writing.
View all posts by Seth Delconte
- Parsing and rotating delimited data in SQL Server - December 9, 2015