
Database snapshot is a great feature that offers virtual read only consistent database copy. When we create the database snapshot in the live operational database, it takes a database point in time static view and Rollback all uncommitted transactions in the snapshot database so we will not be having any inconsistent data that is yet to be committed. Database snapshot always exists on the Source database server.
Database snapshot works on the pages (the fundamental unit of data storage in SQL server is the page). The disk space allocated to a data file in a database is logically divided into pages numbered contiguously from 0 to n. Disk I/O operations are performed at the page level. That is, SQL server reads or writes whole data pages.
Basically, it creates a sparse file and will be pointing to the original databases, written only in case of any insert, update and delete statement is in the source database.
Suppose there is no operation going into the server when we created a database snapshot so snapshot will look like
Source Database

Snapshot Database (Sparse File)

So we have the blank copy of the database here. Now, if any Read Operation occurs ,it will be pointing to the original database only as no page modification is done since snapshot creation.
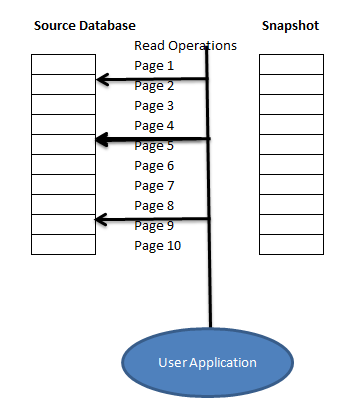
Now suppose due to a DML operation (insert\update\delete) Page 2, 5, and 8 has been modified and user operation requires page 1,2, 4 and page 8 so below picture shows how the snapshot will be and how the read operation will be performed.
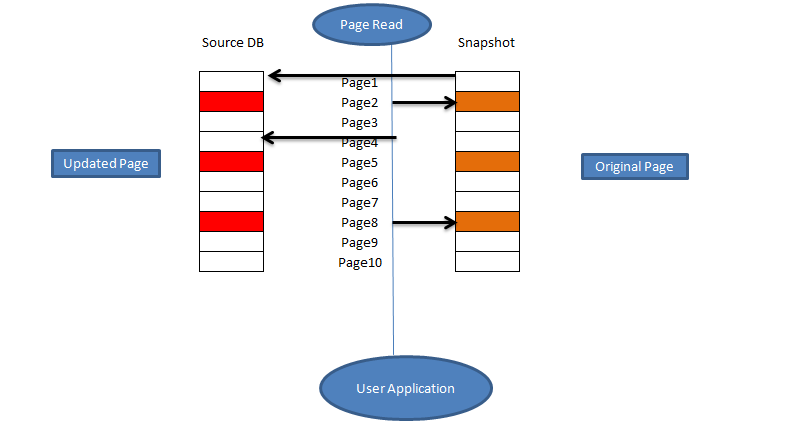
We can see here whichever page gets changed due to any operation, its original page (before modification) is copied into the sparse file (snapshot), so if user operation request to read the snapshot database it works in below ways
- If a page is modified, read operation occurs on sparse File
- If the page is not modified it still points to the source database page
This is the concept behind the snapshot, thus, its size is small compared to the original database but it all depends on the operation if there are too many operations in the database which gets page modified so the snapshot size will be kept increasing.
So whenever we create the snapshot following operation will be done
- 1. It creates an empty file, i.e. sparse file for each source database data file
- Uncommitted transactions are rolled back, thus having a consistent copy of the database
- All dirty pages will be returned to the disk
- The user can query the snapshot database now
Now let’s say there are many database pages being updated so now the snapshot will look like
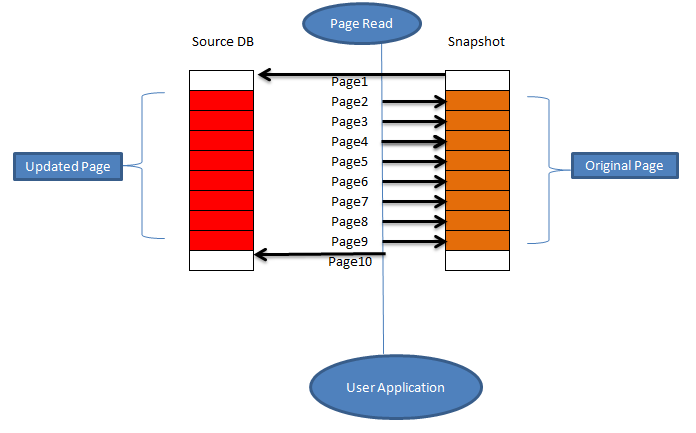
Here we can see the as there are many operations being performed all pages shown above are modified, thus the snapshot size will be increased. We should always keep an eye on the growth of the snapshot database.
The best use of Database snapshot can be during production changes\ upgrades\releases. Normally, database backup is taken and if the database size is big it is really time and space consuming since we will have to keep the backup copy apart from our regular backups. So instead of backup we can create the Database snapshot which is really quick and can perform the release, and once we have verified the changes are good we can easily drop the snapshot and also in some cases we require to see the values before changes we can view that as well.
Database snapshot and High availability
Database snapshot works well with the log shipping and database mirroring too. Normally log shipping databases are maintained in the no recovery model means no database connections can be made and it will be useful only when failover is made.
We can create a database snapshot for log shipping secondary database and use the database to run the queries.
In database mirroring, mirror database is always in no recovery mode, whether it is synchronous and asynchronous mode. By creating snapshots of the mirror database, we can easily query the mirror database so it is quite a useful feature to offload and use it for reporting purposes.
But there is some overhead if we are using synchronous mirror mode. As in synchronous mode, transactions have to be committed on both Principal and mirror servers before marking it complete so for a snapshot as it requires original page, it will add an extra task as copy database page from the mirror database to mirror Snapshot.
Benefits of Database snapshot
- A database snapshot is convenient, reliable, Read- only, point-in-time copy of the database.
- It is very beneficial when doing critical updates to the database as if anything goes wrong database can be restored to that point without any hassle.
- If we want to view database suppose at 7 pm, we can create database snapshot and easily query the database, however, without snapshot we have the option to take the database backup and restore using some different name but it requires considerable system resources especially disk space.
- Sparse file (snapshot) is small and easy to create however the size of snapshot depends upon the amount of operation and page updated.
- Multiple database snapshots are possible for a single database.
- There is no dependency for the recovery model, it works with full, bulk-logged and simple also.
- Snapshot creation is really quick, it takes a few seconds only for big databases too.
Limitations and cons of Database snapshot
- A database snapshot can be created onto the source server only. It cannot be moved to another server
- We can’t drop an Original Source Database as long as a referring snapshot exists in that database
- It cannot be Backed up and also detach \attach doesn’t work with database snapshots
- Snapshots can be created for only user databases, not for the master, model and msdb
- If we revert to a snapshot log Chain will get broken, thus we have to take a full or differential backup to bridge the log chain sequence
- Both the source DB and the snapshot will be unavailable when the actual reversion process is in progress
- If the source database is unavailable or corrupted we cannot use the database snapshot to revert it to the original state
- We cannot add new users for database since it is a read-only copy
- There is no graphical user interface for creating and reverting back the snapshot, this need to be done from query only
- There is some overhead for every DML operation as before operation page needs to be moved out
- If the drive in which snapshot exists is out of space which causes any DML to fail the snapshot will be in suspect mode and non-recoverable
- The full-text index is not available with a snapshot
- It is available with enterprise edition only
- Database files that were online during snapshot creation should be online during the snapshot revert also
Conditions where Database snapshot is not recommended
- It does not substitute for high availability solution such as mirroring, log shipping etc.
- Very high user based activity as it might have extra overhead
- Replacement of database backup as it is fully dependent on the source database

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023