
Introduction to Sequences
Sequence is a new object that was introduced in SQL Server 2012 for a key-generating mechanism. It has been made available across all editions of SQL Server 2012. It was added as an alternative to IDENTITY columns feature that has been prevalent in the previous versions of SQL Server. Despite being newly introduced in SQL Server 2012, sequences have long been prevalent in other database platforms such as Oracle and IBM’s DB2. Thus, the data migration into SQL Server 2012 from other database platforms is now more convenient and simplified.IDENTITY vs Sequence Objects
Sequence objects have been introduced as an alternative to the Identity feature, thus a better way of understanding the usefulness of sequences is by comparing them against the identity feature. Sequences and Identity share lots of similarities but they also differ. Table 1 illustrates some of the feature similarities and differences between sequences and identity.
-
Storage: IDENTITY vs Sequence Objects
One major difference between sequences and identity is in the way they are stored in a database. Identity relies on an existence of a table, thus they are stored along the properties of a table. On the other hand, sequences are stored independently of tables. In fact, SQL Server 2012 treats sequences as separate objects.
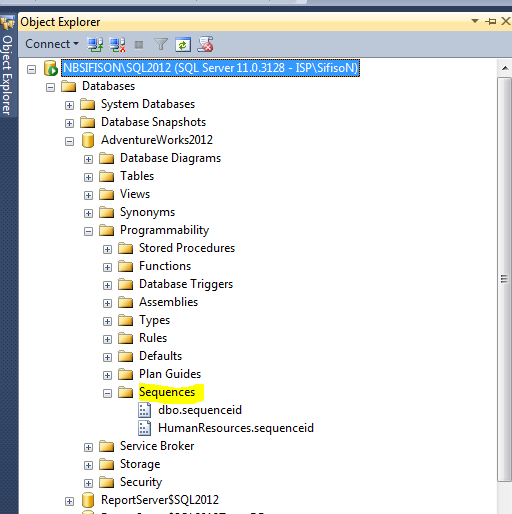
For example, in SQL Server 2012 Management Studio – there is a separate sub-node of Programmability titled ‘Sequences’ which can be used to view sequences within a given database. In the below image, AdventureWorks2012 has two (2) Sequence objects, namely, dbo.sequenceid as well as HumanResources.sequenceid. Noticeably too in this image is that although the names of these sequences are the same (i.e. sequenceid) they are stored in different schemas – dbo & HumanResources.

-
Generating values: IDENTITY vs Sequence Objects
The sequences are more flexible in the way they generate new values as compared to identity. For instance, while a new increment value for identity is only generated by inserting a new row into a given table, sequences allow for the generating of an increment value outside a table. Thus, Sequences can be generated and stored in a variable which in turn can then be used in an insert statement to append a row into a given table. Furthermore, sequences can be used as unique surrogate keys across multiple tables.
Sequences, unlike Identity, also have the advantage of generating new increment values during an UPDATE statement. Finally, because sequences can be generated outside an insert statement, their values can be used in multiple columns within a given table.
Nr Property/Feature Identity Sequence Object 1 Ability to specify minimum and/or maximum increment values NO YES
i.e. use MINVALUE, MAXVALUE options in a create or alter sequence object statement2 Ability to reset the increment value NO YES 3 Ability to cache increment value generating NO YES 4 Ability to specify starting increment value YES YES 5 Ability to specify increment value YES YES
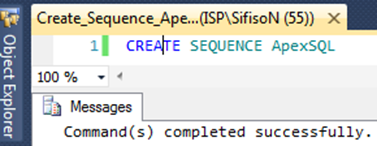
Create Sequence Object Syntax
The only mandatory parameter value in a create sequence statement is the sequence name – the rest of the arguments are optional. Thus, the simplest way to create a sequence would be as shown in below:
There is also an option of providing more arguments in your create sequence script. According to Microsoft’s TechNet site, the complete syntax for create sequence is as follows:
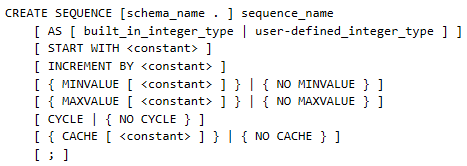
Noticeable from this above complete script is the number of additional arguments that can be specified. We take a look at these arguments in the below:
-
AS Argument
The sequence can either be based in one of the SQL Server 2012 built-in integer data type (i.e. tinyint, smallint, int, bigint, decimal, and/or numeric data type) or it can be based off a SQL Server 2012 user-defined integer data type. If this argument is not specified as part of the create sequence script, then a bigint built-in integer data type is used. -
START WITH Argument
Similarly to the seed argument in the IDENTITY property, this argument indicates the initial value to be retrieved by the sequence object. -
INCREMENT BY Argument
This is similar to the increment argument in the IDENTITY property and it refers to the value that is used to increase or decrease the next value of the sequence object. The sequence object can either be in an ascending or descending order. Ascending and descending sequence objects have positive and negative increment values, respectively. If this argument is not specified as part of the create sequence script, then one (1) is used by default as an increment value. -
MINVALUEAS Argument
This argument specifies the minimum value in a sequence object. If this argument is not specified as part of the create sequence script, then the minimum value used is that of the data type chosen for a given sequence. -
MAXVALUE Argument
On the contrary to the MINVALUE argument, this argument specifies the maximum value in a sequence object. If this argument is not specified as part of the create sequence script, then the maximum value used is that of the data type chosen for a given sequence. -
CYCLE | NO CYCLE Argument
This argument brings the advantage of sequences over identity by allowing for the resetting of the increment value back to the minimum value upon exceeding of its maximum value. If this argument is not specified as part of the create sequence script, then NO CYCLE is used by default. -
cache Argument
Another advantage over IDENTITY property, cache refers to the storage in memory of latest sequence value as well as the number remaining values left within a given cache. For instance, for a sequence object that starts at 1 and has a cache size of 20 – values 1 through 20 are stored in memory and made available as next range of increments.
Administering Sequence Objects
Every database in SQL Server 2012 has a system view titled ‘sys.sequences’ which can be used to retrieve information about sequences of a given database.
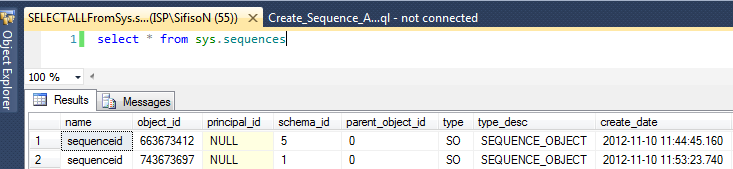
In order to be able to create the sequence object, CREATE SEQUENCE permission is required. CREATE SEQUENCE permission has also been introduced in SQL Server 2012. For more information around this new permission, run the following script:
|
1 2 3 |
select * from sys.fn_builtin_permissions (DEFAULT) ORDER BY class_desc, permission_name; |
Limitations of Sequence Objects
Unfortunately, in spite of the aforementioned benefits and flexibility to using sequences when planning for an auto-number generating mechanism, there are limitations to this new SQL Server 2012 feature:
- SQL Server 2012 database engine specifies its own cache size in instances whereby the cache is enabled but has no cache size. The database engine method used to generate such a cache size is only known to Microsoft and is subject to change without any notice.
- Unexpected SQL Server 2012 shutdowns, such as power failures, are likely to cause a loss of sequence numbers remaining in a given sequence cache.
- Unlike IDENTITY columns, sequence values can be updated which may lead to data integrity. A recommended way of preventing the update of sequences is by rolling-back the changes through an update trigger.
- Sequences do not automatically enforce unique values which mean that in a case of a sequence value cycling or updating of statements, duplicate sequence value can be generated. Again, update triggers and unique constraints can be further used to eliminate such a limitation.
- For sequences created with default values – there is a risk of unnecessary storage and performance issues that can occur. For instance, if you are creating a sequence to be used in a column that can sufficiently use a smallint value, a default integer data type for sequence object is BIGINT.
Conclusion
The new sequence object introduced in SQL Server 2012 has several advantages over IDENTITY columns. It also makes data migrations from non-Microsoft database platforms very convenient. However, some of the of the benefits such as updating of sequence object values may come at greater cost – such as data integrity and unique constraint violations. Consequently, sequences should never be used as a replacement for IDENTITY columns instead they should be used as alternatives to IDENTITY columns.
Resources:

Sifiso's LinkedIn profile
View all posts by Sifiso W. Ndlovu