
When talking about performance and scalability inside SQL Server, I don’t see anyone missing out on the fact to mention how locks get involved. I often see DBA’s complain to developers that their code is not scalable and they are experiencing heavy locks in the system because of the way the code has been written. The more I work with SQL Server, the more I start to understand some of these nuances.
In a recent conversation with one of the DBA’s in a conference where I was presenting, I was told the way SQL Server handles locks even in large databases (VLDBs) is to be improved. This was sort of generic statement and then I asked the gentleman to explain me why they thought so.
Even after doing some great work around partitioning their tables, they are still seeing large amount of locking and lock escalations to table are happening on database. This got me curious to why this can even happen on first place. SQL Server has done tons of optimizations from time to time to enhance this capability.
I thought to bring this topic into a digestible form in this blog so that we get the basics right. There are options enabled at the database level that can help enhance this capability. I have seen many a times people go ahead and use generic recommendations and enable the wrong settings and get into a pitfall of misconfigurations.
Hence for this blog, I am going to do the following:
- Setup the initial database configurations and Setup the tables
- Check how Lock escalations happen based on database properties
- Look at the Locking information and waits
- Change the settings at DB level
- See the effect of the same on lock escalations
- Wrap up and clean the script
Let us first create our database for the experiment.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
USE MASTER; GO IF DATABASEPROPERTYEX ('LocksDB', 'Version') > 0 DROP DATABASE LocksDB; CREATE DATABASE LocksDB; GO -- Create partition functions ALTER DATABASE [LocksDB] ADD FILEGROUP FG10000; ALTER DATABASE [LocksDB] ADD FILE (NAME = LocksDB_Data_10000, FILENAME = 'C:\DATA\LocksDB_Data_10000.NDF', SIZE = 100MB, FILEGROWTH = 150MB) TO FILEGROUP FG10000; ALTER DATABASE [LocksDB] ADD FILEGROUP FG20000; ALTER DATABASE [LocksDB] ADD FILE (NAME = LocksDB_Data_20000, FILENAME = 'C:\DATA\LocksDB_Data_20000.NDF', SIZE = 100MB, FILEGROWTH = 150MB) TO FILEGROUP FG20000; ALTER DATABASE [LocksDB] ADD FILEGROUP FG30000; ALTER DATABASE [LocksDB] ADD FILE (NAME = LocksDB_Data_30000, FILENAME = 'C:\DATA\LocksDB_Data_30000.NDF', SIZE = 100MB, FILEGROWTH = 150MB) TO FILEGROUP FG30000; |
Once the database is created, let us next create the Partitioning Function and Partitioning Scheme for our experiment. The Partitioning Function defines the boundaries for our respective partitions and the Partitioning Scheme defines the way each of the partitions will be mapped to a logical filegroup (hence data files).
|
1 2 3 4 5 6 7 8 9 10 11 12 |
USE [LocksDB] GO IF EXISTS (SELECT * FROM sys.partition_functions WHERE name = 'pf_thousand') DROP PARTITION FUNCTION [pf_thousand]; CREATE PARTITION FUNCTION [pf_thousand] (int) AS RANGE left FOR VALUES (10000,20000,30000); GO IF EXISTS (SELECT * FROM sys.partition_schemes WHERE name = 'ps_thousand_range') DROP PARTITION SCHEME ps_thousand_range; CREATE PARTITION SCHEME ps_thousand_range AS PARTITION pf_thousand TO ([PRIMARY],[FG10000],[FG20000],[FG30000]); GO |
Our LocksDB filegroups look like below:
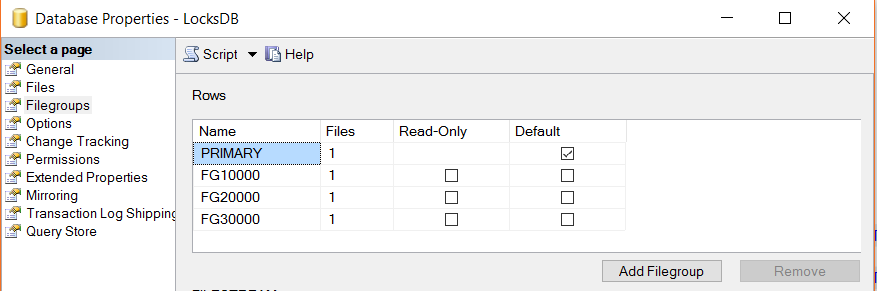
Our next logical step is to create a table, map the Partitioning Schema and add some data into the table to respective partitions.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
SET NOCOUNT ON -- Create partitioned table CREATE TABLE MyPartitionedTable( c1 int NOT NULL, c2 int NOT NULL, c3 VARCHAR(100)) ON ps_thousand_range (c1); GO ALTER TABLE MyPartitionedTable ADD CONSTRAINT [PK_MyPartitionedTable] PRIMARY KEY NONCLUSTERED (c1 ASC) WITH (ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON ps_thousand_range (c1) -- Populate partitioned table DECLARE @count int SET @count = 1 WHILE @count <> 28000 BEGIN INSERT INTO MyPartitionedTable SELECT @count, RAND(2), REPLICATE('a', 9) SET @count = @count + 1 CONTINUE END |
Let us take a step back to validate if the rows were inserted into the table. Let us query the partitions DMVs to find the same:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT OBJECT_NAME(object_id) AS [Table Name], partition_number, SUM(rows) AS [SQL RowCount] FROM sys.partitions WHERE index_id IN (0, 1) -- 0:Heap, 1:Clustered AND object_id = OBJECT_ID('MyPartitionedTable') GROUP BY object_id, partition_number |

Now that the basics are done, let us try to mimic the scenario our DBA friend had first got. The code that was in setup of database script had the following:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
USE LocksDB; GO SET STATISTICS IO ON; GO -- First select on partition 3 range to check if data exists SELECT MyPartitionedTable.c1 FROM MyPartitionedTable WHERE c1>16000 -- Enable LOCK ESCALATION on the table ALTER TABLE MyPartitionedTable SET (LOCK_ESCALATION = TABLE); --default |
Note the last statement in the code above. It mentions that the Lock Escalation needs to bubble to the Table level. Though there was no need to do it, this was done in one of their code. So let us see what the effect of this is.
|
1 2 3 4 5 6 7 |
-- Force lock escalation by updating all 10000 rows on 1st partition -- in a single transaction. BEGIN TRAN UPDATE MyPartitionedTable SET c1 = c1 WHERE c1 < 10000 GO |
Since we are updating close to 10000 rows in the 1st partition, the lock escalation would have happened and let us see if we can query any data from other partitions in a separate / new session.
|
1 2 3 4 5 6 7 8 |
-- Query partition 3 in a different window USE LocksDB; GO SELECT COUNT (*) FROM MyPartitionedTable WHERE c1 >= 21000; GO |
In this case you will see that the current query window is blocked and waiting indefinitely. This is very much the case to happen because our database has been misconfigured here. If we query the DMVs, we can find out:
|
1 2 3 4 5 6 7 8 9 |
-- Verify locks USE LocksDB; GO SELECT * FROM sys.dm_tran_locks WHERE [resource_type] <> 'DATABASE'; GO |

As you can see, the Table object has been granted [X] Lock (Exclusive) on one of the sessions and we are waiting on another session to take an IS (Shared) lock.
So what is the point of partitioning if we are bubbling our locks to the table level and not allowing other queries to execute. There must be something wrong right?
As I said earlier, ideally we would have wanted SQL Server to take the locks at the partition level and allowed us to query other partitions that are not affected. This is exactly what we will be doing in our code next.
|
1 2 3 4 5 |
-- ROLLBACK the transaction in the first session ROLLBACK TRAN; GO |
On the first session, execute the below code.
|
1 2 3 4 |
-- Enable LOCK ESCALATION = AUTO to enable partition level lock ALTER TABLE MyPartitionedTable SET (LOCK_ESCALATION = AUTO); |
Here we are going to change the Lock Escalation settings to Automatic and let us see how partitioning behavior changes because of this setting.
Again on session 1, change large amount of rows and let us see where this leads us:
|
1 2 3 4 5 6 |
-- Again, UPDATE BEGIN TRAN UPDATE MyPartitionedTable SET c1 = c1 WHERE c1 < 10000 GO |
On another session window, let us try to query the table’s data:
|
1 2 3 4 5 6 7 8 |
-- Query partition 3 in a different window USE LocksDB; GO SELECT COUNT (*) FROM MyPartitionedTable WHERE c1 >= 21000; GO |
As you can see, the data is returned without any problems this time. This is exactly the behavior we want to see.
|
1 2 3 4 5 6 7 8 9 10 |
USE LocksDB; GO SELECT * FROM sys.partitions WHERE object_id = OBJECT_ID ('MyPartitionedTable'); GO SELECT * FROM sys.dm_tran_locks WHERE [resource_type] <> 'DATABASE'; GO |
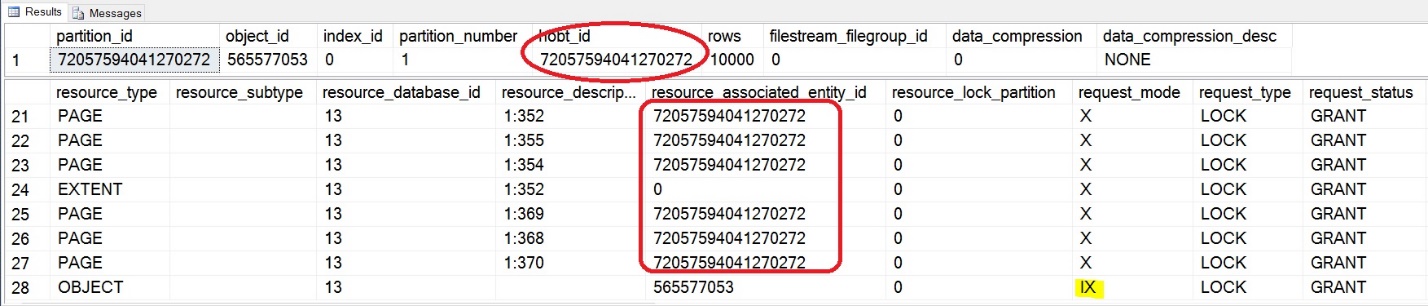
As you can see above, the hobt_id for the first partition has the Exclusive lock and the object has only the Intent locks. This is the very reason why we were able to query from other partition without any problems.
As you can see, we have used a number of combinations of DMV’s and database settings to identify potential problems that might occur in a database.
As an DBA, be aware of all the settings that get introduced in every release of SQL Server and try play around with them to understand their functioning. The more we question our understanding of how SQL Server works, we will be able to write code that will make things work. Understanding the root-cause for any problem will help us in eliminating the problem totally.
After this experiment, I wrote back to my DBA friend to let him know how some of the settings in SQL Server had helped me gain confidence in eliminating potential performance problems. I had also requested them to check the status on their SQL Server’s for this setting on every database. If there was deviation, told them to automate in changing the same.
As I wrap up, let us take a moment to clean up our experiment database that was just created. Cleanup script would be:
|
1 2 3 4 5 6 7 8 |
Rollback -- Cleanup USE master GO DROP DATABASE [LocksDB] GO |
In this blog post we have learned that how we can lock settings to use to enhance partitioning capability. Lots of people think partitioning is be a silver bullet to solve all of the problems but it is not true, there are some problems which require a bit more thinking like playing with lock settings.

He has successfully authored 11 SQL Server database books, 18 video courses and written over 3500 articles on database technology via his blog. Rounding out his professional career, Pinal has held key positions as Sr. Consultant for SolidQ and as a Technology Evangelist for Pluralist and Microsoft.
Pinal holds a Master of Science from the University of Southern California, and numerous professional certifications, including MCTS, MCDBA and MCAD (.NET).
View all posts by Pinal Dave
- SQL Server: Lock settings to use to enhance partitioning capability - December 30, 2015