In this article, we will explore various SQL Convert Date formats to use in writing SQL queries.
Read more »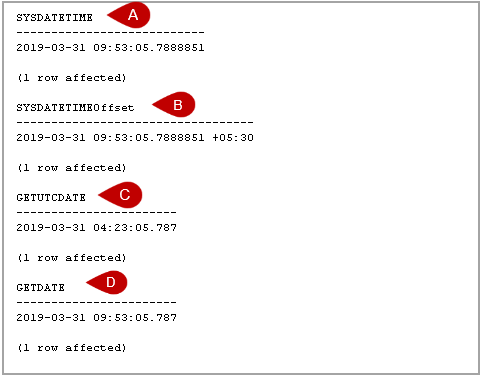

In this article, we will explore various SQL Convert Date formats to use in writing SQL queries.
Read more »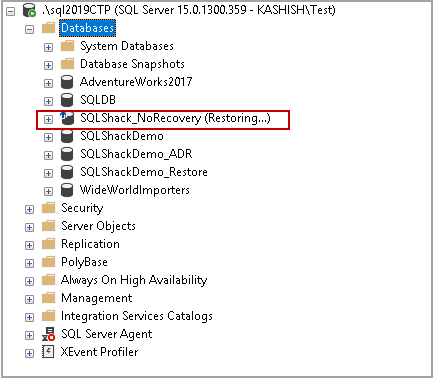
This article will cover SQL restore database operations using the open-source PowerShell module, DBAtools, and will cover commands for backup restoration using the command Restore-DBABackup with many various permutations like restoring from file, separate directory, renaming databases, norecovery options and more
Read more »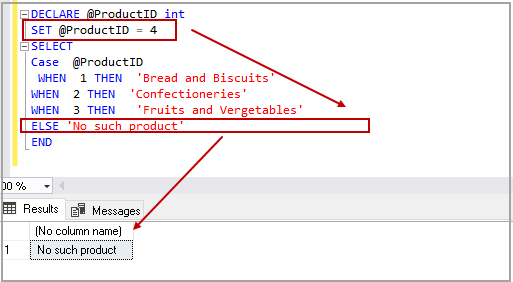
The case statement in SQL returns a value on a specified condition. We can use a Case statement in select queries along with Where, Order By, and Group By clause. It can be used in the Insert statement as well. In this article, we would explore the CASE statement and its various use cases.
Read more »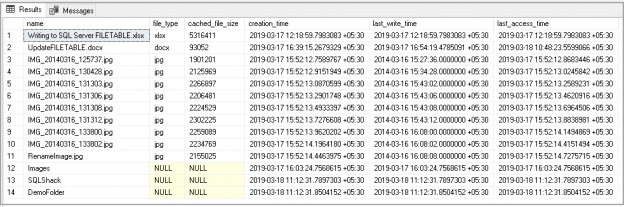
SQL Server FILETABLE provides benefits over SQL FILESTREAM available from SQL Server 2012. We can manage unstructured objects in the file system using SQL Server. It stores metadata in particular fixed schema tables and columns. It provides compatibility between an object in SQL Server table and Windows.
Read more »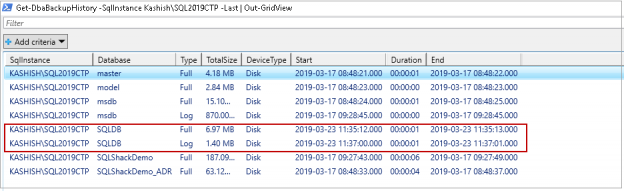
In my earlier PowerShell SQL Server article, SQL Database Backups using PowerShell Module – DBATools, we explored the importance of a disaster recovery solution for an organization. Microsoft offers various disaster recovery solutions in SQL Server.
Read more »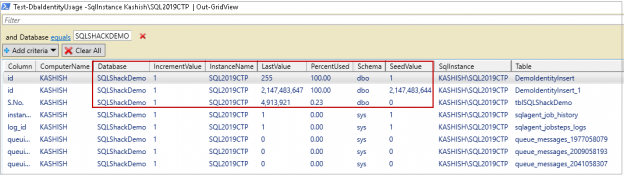
In this article, we will review PowerShell SQL Server module DBATools to identify IDENTITY columns about to reach the threshold.
Read more »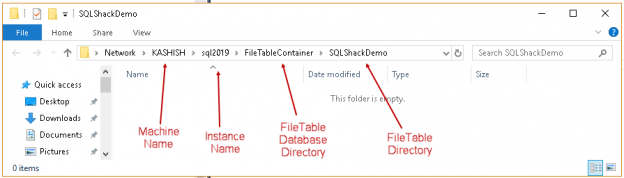
SQL Server FILETABLE is a next generation feature of SQL FILESTREAM. We can use it to store unstructured objects into a hierarchal directory structure. SQL Server manages SQL FILETABLE using computed columns and interacts with the OS using extended functions. We can manage SQL FILETABLEs similar to a relational table.
Read more »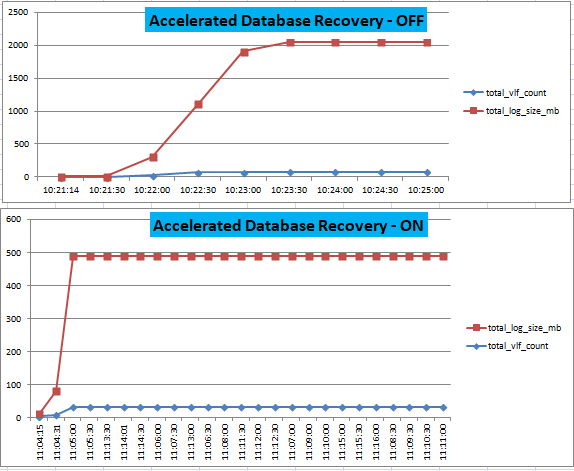
In my previous article in this series Accelerated Database Recovery; Instant Rollback and Database Recovery, we talked about a potential DBA painkiller to resolve long waiting times for database recovery and rollback scenarios using Accelerated Database Recovery. In this article, we will look at one more painful challenge for DBAs, Long Running Transaction with Transaction log growth.
Read more »
This article will be first article of series for SQL database backup and restoration using DBAtools, a powerful open source library of PowerShell automation scripts.
Read more »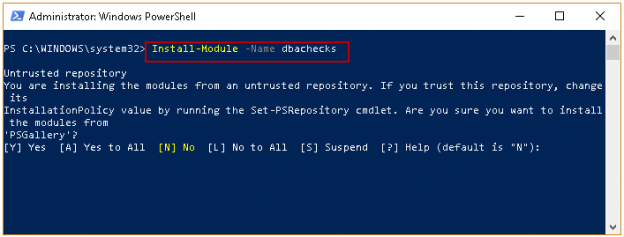
In this article, we will explore the DBAChecks PowerShell SQL Server Module. We can use the DBAChecks module to validate SQL Server instances using the various modules. We can also perform more than 100 configuration reviews using it.
Read more »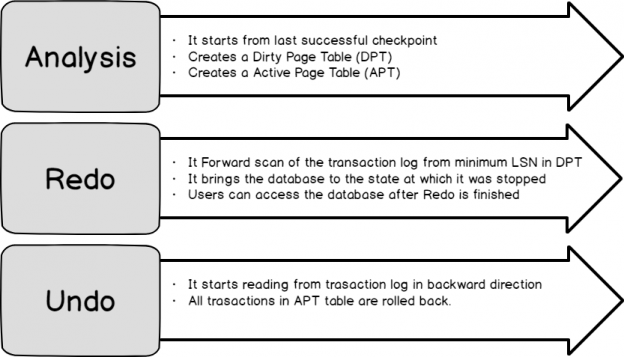
Accelerated database recovery will be the topic of this article, including killing an active query, abnormal shutdown and the accelerate recovery feature itself, in SQL 2019

This article will provide an overview and introduction to DBAtools, a powerful open source library of automation scripts.
Read more »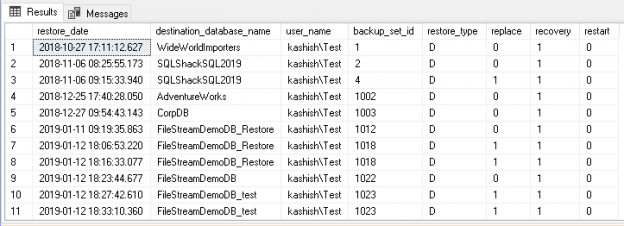
This article will review how to get information on your SQL database restore history, including the metadata in MSDB that can be queried, as well as value added tools and features to the group, sort, report and export this critical information.
Read more »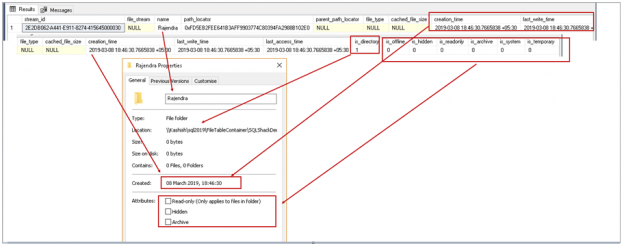
This SQL Server FILETABLE article is the continuation of the SQL Server FILESTREAM series. The SQL Server FILESTREAM feature is available from SQL Server 2008 on. We can store unstructured objects into FILESTREAM container using this feature. SQL Server 2012 introduced a new feature, SQL Server FILETABLE, built on top of the SQL FILESTREAM feature. In this article, we will explore the SQL FILETABLE feature overview and its comparison with SQL FILESTREAM.
Read more »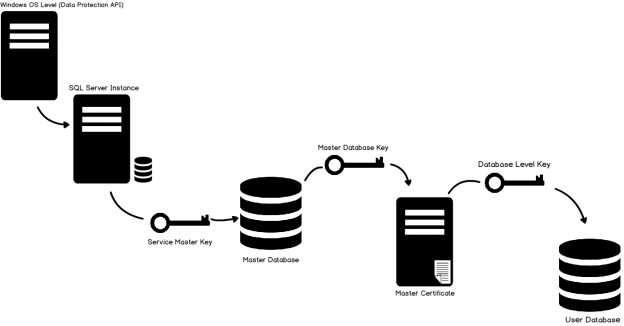
This article is the continuation of the SQL FILESTREAM series.
Read more »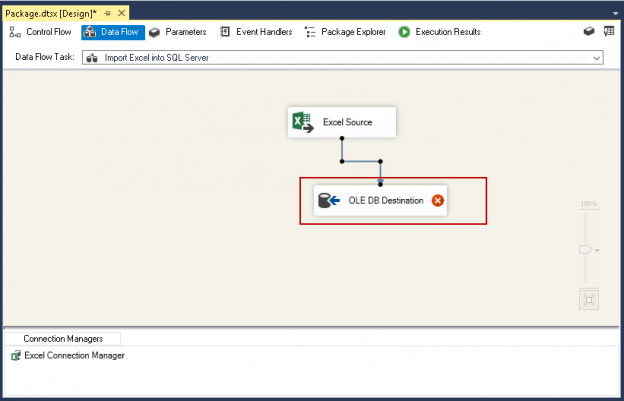
I have seen many organizations receive data from various sources and import into SQL Server. You might receive data in various formats and want to import into SQL Server. We can prepare a ETL (Extract-Transform-Load) process to import data into the SQL Server. In doing so, might receive data in a compressed file, which helps to send data over the network using a ZIP file format because it reduces the file size significantly. If we are receiving a ZIP file to import into SQL Server, we need to unzip it and then only we can import data. We might need to create a ZIP file as well from the existing files.
Read more »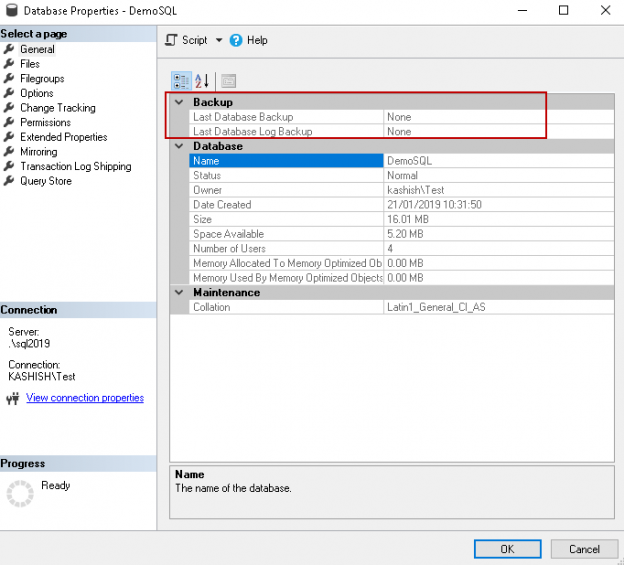
In the continuation of our SQL FILESTREAM article series, we’ll be covering transaction log backups
In SQL Server, we take transaction log backups regularly to have a point-in-time recovery of a database. It is essential to define the backup policy with the combination of full, differential and transaction log backups. A standard configuration of backups for large databases in the production database environment is as follows.
Read more »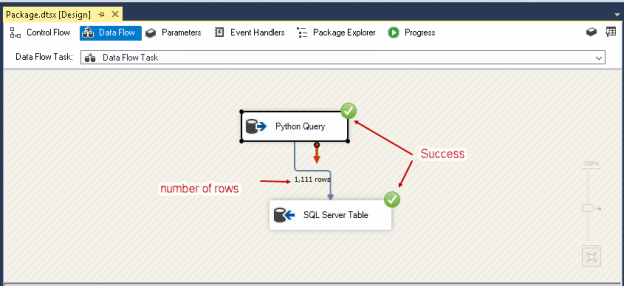
Using Python SQL scripts is a powerful technical combination to help developers and database administrators to do data analytics activities. Python provides many useful modules to perform data computation and processing of data efficiently. We can run Python scripts starting from SQL Server 2017. We can create the ETL solutions to extract data from various sources and insert into SQL Server.
Read more »
Power BI Desktop is a useful reporting and analytical tool to represent data in various formats. These presentations help us to quickly understand information and circulate it to stakeholders in a visual fashion.
Power BI Desktop amplifies the value of data. We can connect to multiple data sources and visualize the data interactively. One of the best parts of Power BI Desktop is the custom visual feature. It allows developers to create custom visuals and users can then download these visuals from the marketplace and use it as per the data set requirements. We can prepare reports using Power BI Desktop and share the reports using the Power BI service.
Read more »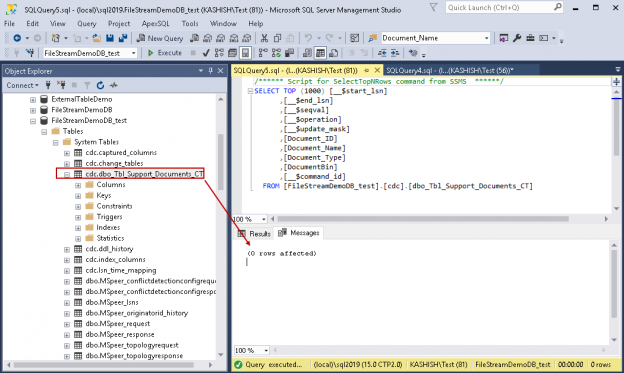
Sometimes we require tracking data change activity (Insert, update and deletes) in SQL Server tables. SQL Server 2008 introduced Change Data Capture (CDC) to track these changes in the user-defined tables. SQL Server tracks the defined table with a mirrored table with same column structure; however; it adds additional metadata fields to track these changes. We can use table-valued function to access this changed data.
Read more »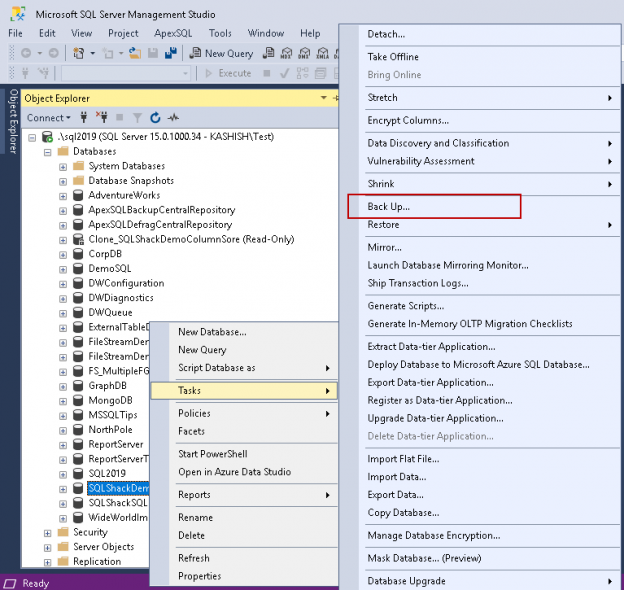
A Database administrator’s key task is to keep the database healthy and available for the users. We are used to taking regular SQL backups depending upon the database criticality and the recovery model. We define the Recovery Point Objective (RPO) Recovery Time Objective (RTO) or the database system, and we should be able to recover the database in any scenario to meet the requirement.
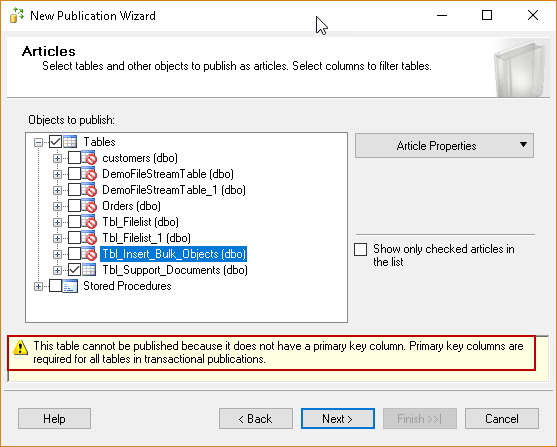
In the previous articles in this series (see TOC at bottom), we wrote about the various feature of the SQL Server FILESTREAM. In SQL Server, we use replication to replicate the articles to the destination server. Consider a scenario in which we have the FILESTREAM database in our environment. We would also have the requirement to configure this database for SQL Server replication.
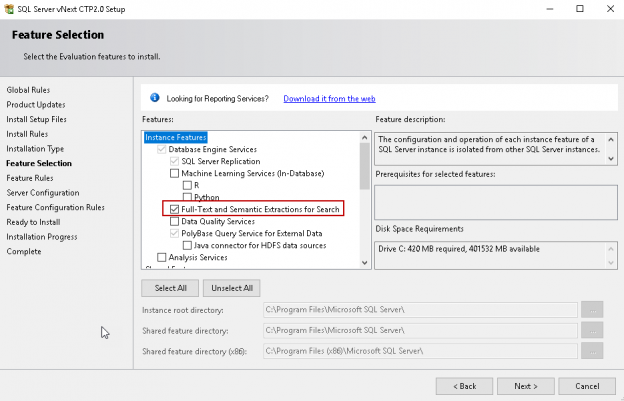
In this article, the latest in our series on the SQL FILESTREAM feature, we are going to look at the synergy and interoperability with SQL Server Full Text search, another powerful SQL Server feature
Read more »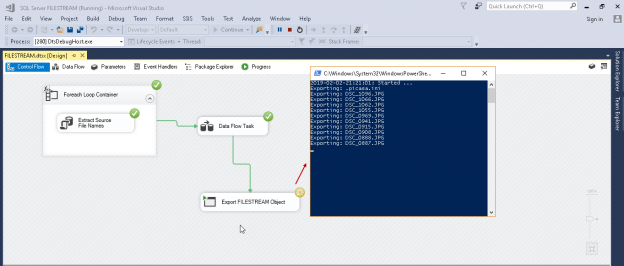
In this series of articles on SQL Server FILESTREAM (see TOC at bottom), we explored various ways to store unstructured data in the file system with the metadata in SQL Server tables. If we have a large number of objects in the file system, it is advisable to use the fast disk for storage purpose. It is faster and provides better IO in comparison with the traditional file system.
© Quest Software Inc. ALL RIGHTS RESERVED. | GDPR | Terms of Use | Privacy