
This SQL Server FILETABLE article is the continuation of the SQL Server FILESTREAM series. The SQL Server FILESTREAM feature is available from SQL Server 2008 on. We can store unstructured objects into FILESTREAM container using this feature. SQL Server 2012 introduced a new feature, SQL Server FILETABLE, built on top of the SQL FILESTREAM feature. In this article, we will explore the SQL FILETABLE feature overview and its comparison with SQL FILESTREAM.
Once we connect to SQL Server and expand any database in SSMS, we get the following tables options.
- System Tables: SQL Server manages these internal SQL Server tables
- FileTables: We will talk about these tables in this article
- External Tables: External tables are new features in SQL Server 2017 onwards
- Graph Tables: Graph tables are also a new feature in SQL Server 2017 onwards
SQL Server only stores metadata in FILESTREAM tables. It provides performance benefits by taking advantage of NTFS API streaming of the Windows file system. We do not control over the objects in FILESTREAM container using the SQL Server although it provides the transaction consistency.
SQL Server 2012 introduced the SQL Server FILETABLE feature that is built on SQL FILESTREAM. We can store directory hierarchies in a database. It provides compatibility with Windows applications to the file data stored in SQL Server. SQL FILETABLE stores the file and directory attributes along with the FILESTREAM data into FILETABLE. The user can access the objects from the container similar to a file share. We do not have to make changes in the applications to access these data. You can also paste the files in the container (host directory), and SQL Server automatically inserts metadata into FILETABLE.
We need to perform the following steps to create SQL Server FILETABLE on SQL Server 2012 and above versions.
-
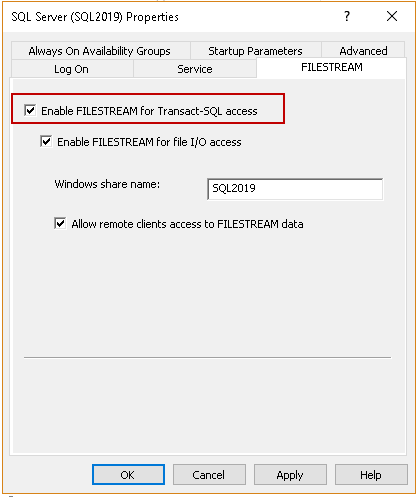
SQL Server instance with enabled FILESTREAM feature: Open SQL Server Configuration Manager and check on Enable FILESTREAM for Transact SQL access.

-
Configure filestream_access_level using sp_configure.
Value
Description
0
Disabled
1
Enabled for T-SQL access
2
Enabled for T-SQL and Windows streaming
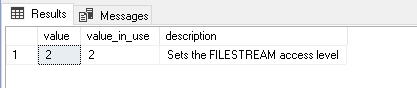
We have already configured filestream_access_level during SQL FILESTREAM series. You can verify the configuration using the following query.
123USE masterGOSELECT [value],[value_in_use],description FROM [sys].[configurations] WHERE name= 'filestream access level'In the below screenshot, we can verify that we have enabled FILESTREAM access for both Windows streaming and T-SQL.
-
Create a SQL FILETABLE database with the following script.
12345678910111213141516171819202122CREATE DATABASE SQLFileTableON PRIMARY(NAME = SQLFileTable_data,FILENAME = 'C:\sqlshack\FileTable\SQLFileTable.mdf'),FILEGROUP FileStreamFG CONTAINS FILESTREAM(NAME = SQLFileTable,FILENAME = 'C:\sqlshack\FileTable\FileTable_Container')LOG ON(NAME = SQLFileTable_Log,FILENAME = 'C:\sqlshack\FileTable\SQLFileTable_Log.ldf')WITH FILESTREAM(NON_TRANSACTED_ACCESS = FULL,DIRECTORY_NAME = N'FileTableContainer');GOIn this database, we have specified following parameters.
- FILESTREAM filegroup along with the FILESTREAM container path. It should be a valid directory name.
- Windows applications can use a file handle to access FILESTREAM data without any SQL transaction. Enable non-transactional access to files at the database level. If we have any existing database, we can validate it using the following query
-
1234SELECT DB_NAME(database_id) as DatabaseName, non_transacted_access, non_transacted_access_descFROM sys.database_filestream_optionswhere DB_NAME(database_id)='SQLFileTable';GO
We can have the following options for non-transacted access.
- OFF: Non-transactional access to FileTables is not allowed
- Read Only– Non-transactional access to FileTables is allowed for the read-only purpose
- Full– Non-transactional access to FileTables is allowed for both reading and writing
- Specify a directory for the SQL Server FILETABLE. We need to specify directory without directory path. This directory acts as a root path in FILETABLE hierarchy. We will explore more in a further section of this article
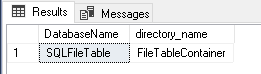
If you have a SQL FILETABLE, you can use the following query to check the directory name for FILETABLE.
123Select DB_NAME ( database_id) as DatabaseName, directory_nameFROM sys.database_filestream_optionswhere DB_NAME(database_id)='SQLFileTable';

-
Create FILETABLE with FILETABLE_DIRECTORY and FileTable_Collate_Filename. Execute the following query in FILETABLE database
123456789use SQLFileTableGoCREATE TABLE SQLShackDemoDocumentsAS FILETABLEWITH(FileTable_Directory = 'SQLShackDemo',FileTable_Collate_Filename = database_default);
FILETABLE_DIRECTORY: It is the root directory for all objects in the SWQLFILETABLE. It should be unique in all FILETABLE directory names in particular database.
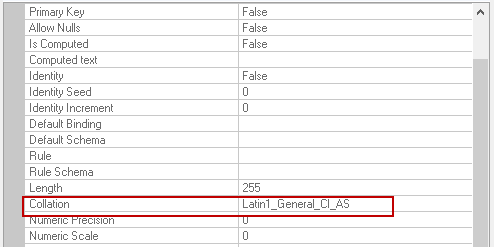
FILETABLE_COLLATE_FILENAME: it is the collation for the Name column in the FILETABLE. If we specify database_default in this, it applies the source database collation. We can also specify the collation in this parameter. We can use the following query to specify the collation in FILETABLE.
12345678CREATE TABLE [dbo].[SQLShackDemoDocuments]AS FILETABLEWITH(FILETABLE_DIRECTORY = N'SQLShackDemo',FILETABLE_COLLATE_FILENAME = Latin1_General_CI_AS)GO
We cannot create a SQL Server FILETABLE using the GUI in SSMS. To demonstrate this limitation, connect to FILETABLE database in SSMS and right click on FileTables and then File Table
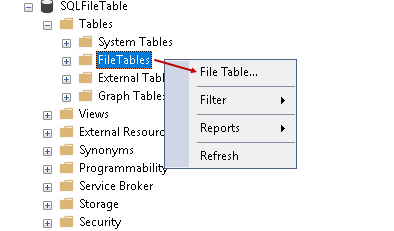
It gives the FileTable template as per the following screenshot. It does not launch the table designer window similar to a relational table.
Once we have created the SQL Server FILETABLE, expand the table to view the columns in this table.
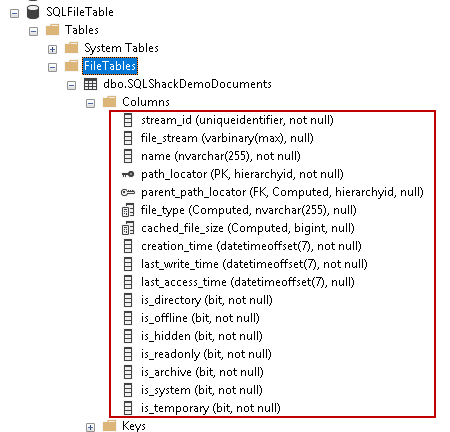
If you look at creating FILETABLE script, we did not specify any column in the table. SQL Server uses predefined and fixed schema for the FILETABLE. It holds metadata of each file along with its characteristics. Let us look at each column description.
FILETABLE Column | Description |
Stream_id | It is a unique identifier rowguidcol column for each FILESTREAM table |
File_stream | It is the FILESTREAM column holding actual file content. |
Name | It is the name of the file or folder.
|
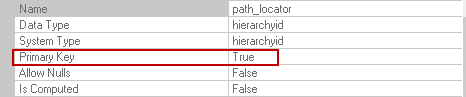
Path_locator | This column represents the file or folder hierarchy. It is also the primary key on SQL Server FILETABLE.
|
Parent_file_locator | Parent_file_locator column is a persisted computed column. It contains the path_locator of the parent folder. In the following screenshot, you can see that it uses GetAncestor() function on the path_locator field.
|
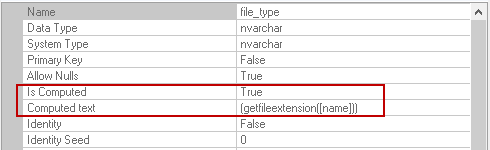
file_type | The file_type column shows the file type as per their extension. It is also a computed column. It uses function GETFILEEXTENSION() to get file extension
|
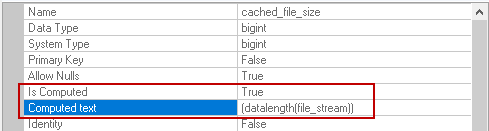
cached_file_size | It gives the file size in bytes. It is also a computed column and uses a datalength function on the file_stream column to calculate file size.
|
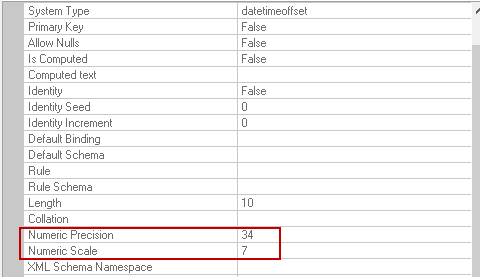
creation_time | It captures the date and time the file was created. It uses numeric precision 34 and numeric scale 7.
We can check the date format using the following query in SSMS. SELECT CAST(‘2019-03-08 12:35:29.1234567 +12:15’ AS datetimeoffset(7)) AS ‘datetimeoffset’ It gives output in the following format.
|
last_write_ time | It shows the date and time when the file or folder contents were last updated. It gives output in time in the same format as of creation_time. |
last_access_time | It gives the last file accessed date and time in the same format as of creation_time. |
is_directory | We can check if the particular row refers to a file or folder. Value 0 – File Value 1 – Folder |
is_offline | If the file is offline, it updates the attribute is_offline. |
is_hidden | It refers to the hidden attribute of the file. |
is_readonly | It refers to the read-only attribute of the file. |
is_archive | It gives information about the archive attribute. |
is_system | It gives information about the system file attribute. |
is_temporary | If the file is temporary, this flag is updated. |


In my earlier articles on SQL FILESTREAM, we needed to define the FILESTREAM table, and it does not capture any predefined schemas or table columns. The SQL Server FILETABLE gives the advantage of capturing all metadata in the FILETABLE. We do not need to specify any metadata column while creating FILETABLE.
SQL FILESTREAM does not have control over the files in the container. SQL Server uses this metadata as per the file property. For example, if is_readonly attribute for a particular file is set to one, SQL Server does not allow making any changes in that particular file. We do not this control in the SQL FILESTREAM table.
Keys and Constraints in SQL Serve FILETABLE
In the following screenshot, you can see the Keys and Constraint in the SQL Server FILETABLE. These are automatically created by SQL Server. We do not need to create these Keys and Constraint explicitly.
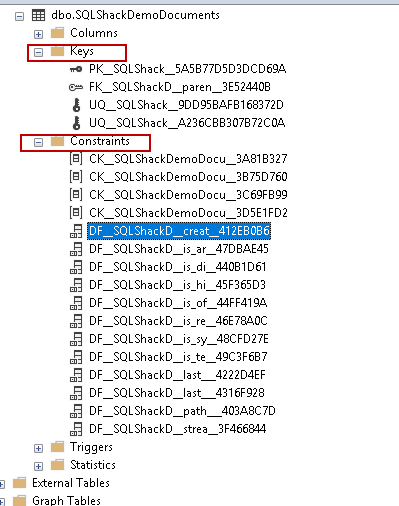
SQL Server creates the following key on FILETABLE.
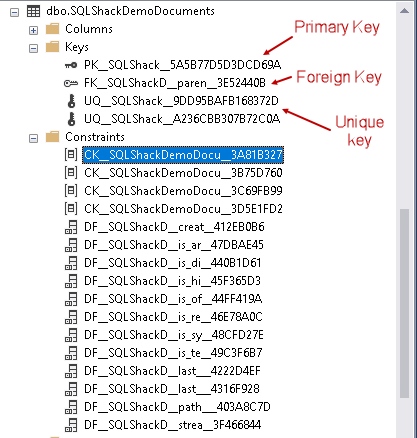
- Primary key on [path_locator]
- Foreign key on [parent_path_locator]
- Unique key on [stream_id]
- Unique key on combination of [parent_path_locator] and [name]
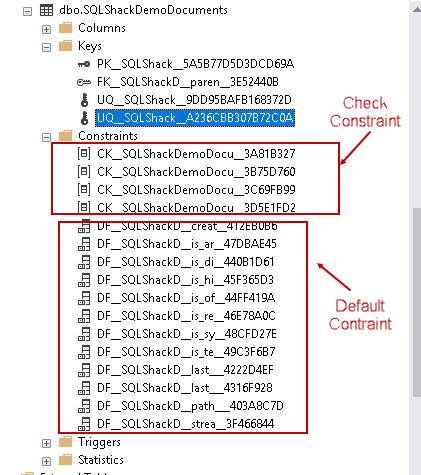
Constraints:
SQL Server FILETABLE contains the following constraints
- Check constraints: These constraints ensure the columns having valid values. For example, it checks for the valid filename using it
- Default constraints: these constraints set a default value for a file. For example by default [is_offline] column contains value 0
In SQL Server FILESTREAM, we cannot access the FILESTREAM container from SQL Server. We need to go to FILESTREAM container and access the files. SQL Server FILETABLE allows control over the directories and files. We can right click on a FILETABLE and click on Explore FileTable Directory.
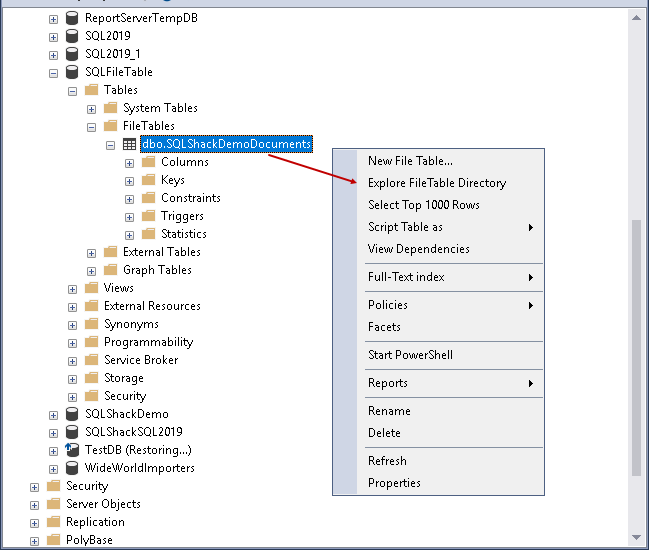
It opens the root path of the FILETABLE in the following format. In this format, it uses the machine name, the instance-level, FILESTREAM share name, database-level folder name and FileTable-level folder.
\\servername\instance-share\database-directory\FileTable-directory
In the following screenshot, you can see the FILETABLE root folder structure as per specified format.

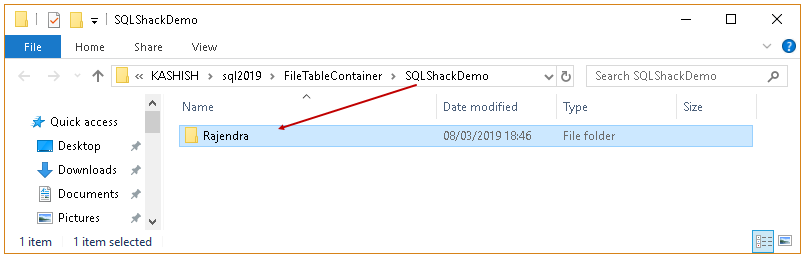
Create a new folder under the SQL Server FILETABLE directory. Right click and go to new and Folder. Provide a suitable name for the folder.
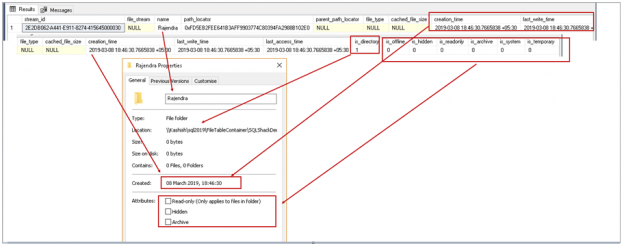
In the following screenshot, we created Rajendra folder under SQLShackDemo.
Now, go to SSMS and select the records from FILETABLE.
|
1 |
select * from [dbo].[SQLShackDemoDocuments] |
It automatically inserts the record in the FILETABLE. SQL Server uses the constraints and function to read the FILETABLE directory and access the record into FILETABLE. Remember, SQL Server FILESTREAM does not provide this functionality.

Now open the folder properties in Windows and compare with the inserted record in FILETABLE. In the following screenshot, you can see the corresponding values in SQL Server FILETABLE.

Let us create another folder inside the parent folder Rajendra. I renamed this folder Raj.

Reaccess the SQL Server FILETABLE, and we can see the parent-child relationship in FILETABLE as well. In the following screenshot, you can notice that path_locator and parent_path_locator columns are lined together. It is due to the primary and foreign key relationship.

Conclusion
In this article, we explored the overview of SQL Server FILETABLE and its comparison with SQL Server FILESTREAM. In further articles, we will explore FILETABLE feature in more detail.
Table of contents

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023