
We all love Availability Groups! Since its introduction in the SQL Server 2012, some things changed. In the beginning it was seen as “just a replacement for the database mirroring”, but when we discovered that this would support readable secondary’s, the possibility of having a listener and get rid of the shared storage – even being based on a Failover Cluster – we saw that Availability Groups is a special feature.
After the release of SQL Server 2014 we had more improvements: the number of replicas increased from 4 to 8, the availability of the secondary replica was improved, the same with the diagnostics. One more big improvement was the possibility of having the Azure replica, but we still have something that is being a blocker to migrate from database mirroring to availability groups…The SQL Server Enterprise edition is required!
Earlier this year, Microsoft announced the next version of SQL Server, the SQL Server 2016, which brought some exciting news… Including the support for SQL Server Standard Edition. By the way, I will write an article about this soon…
Having the Availability Groups feature being a mature solution, being adopted more and more we were able to acquire experience on some points that I will explain in this article. This knowledge is very useful to help us to answer customer’s questions and to plan a specific deployment. So let’s check some facts about Availability Groups!
#1: What happens when I add a readable secondary?
As we know, we have two kinds of replicas, in the Availability Groups: Primary and Secondary.
When a specific replica is acting as secondary, we can define if this replica is readable or not. A readable replica is very useful to offload the primary replica, so actions like backups or reports could be done in the secondary, alleviating the primary.
But the advice here is: Do not set your secondary as readable if you don’t really need! You could be compromising your performance for no reason.
There’s a process called “REDO Thread” running on the secondary replica, that is responsible for applying the changes made in the primary, and this thread cannot be blocked. So an exclusive lock on the rows is needed in order to apply the changes, which is a challenge if you have processes in the secondary, trying to read those same rows.
In fact, this works in some way… I can run a select in a table and simultaneously run a massive update in the primary over the same table. How does this work?
Simple! All transactions in secondary are mapped to Snapshot Isolation.
Ok, but where is the performance problem here?
Row version will be created and the TempDB will be used to store this. But not only this… In order to “manage” this version, a 14-byte pointer is needed to link the chain of versions. So, as the primary and secondary replicas must be identical, this extra 14 bytes will be also created in the primary!
Summarizing…
Effects in the Secondary replica:
- Attention to tempdb size.
- Navigate through row version chain results in logical and ‘random’ physical I/O.
Effects in the Primary:
- Table size increases around 5%.
- That extra 14 byte can lead to Page splits (fragmentation).
#2: Why do I have different options to control connections to the AG?
Probably you already noticed that we have two options to set a readable replica:
- Yes.
- Read-Intent Only.
But what is the purpose of this?
Let’s say that we set the readable secondary using the option “Yes”. If we try to connect that readable secondary and execute an insert, we will have a failure message.

However, we were able to connect! If your application is not treating the error messages properly, probably you would take a long time to understand that the problem is not the database or your code, is just the connection string that is not targeting the correct replica.
But what if we change the option to “Read-Intent Only” and try the same? The message will be different:

In this case, you won’t be even capable of connecting to the database/instance/AG because you need to explicitly specify in the connection string that your intention is read-only.
Summarizing this: the difference of having a readable secondary or a read-intent only secondary is just a kind of protection, to avoid mistakes. If you have your application with a connection string following the best practices for Availability Groups you will never connect to the wrong replica. But this is not all! The primary replica has also something similar:
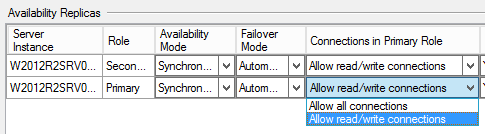
As you can see in the image, you can define the role of a replica when it is the primary. By default the primary replica accepts all the connections, but you can define it to allow read\write connections and this means that a connection wth the parameter pointing to “read-intent only” won’t be able to connect to the primary replica. What’s the objective of this? Simple! If you have your AG well-configured, and you application with the connection strings well-tuned, you will never run a huge report in the primary replica, which would affect the application performance. In other words, the primary replica would work for regular OLTP work, and the secondary to run reports (and maybe other tasks).
To conclude, there are three basic best practices:
- Configure the replicas accordingly.
- Define the read-only route (this is very important when you have more than one secondary replica).
- Configure the application’s connection string in order to take advantage of what you have, and take 100% of your environment.
- Use the parameter “ApplicationIntent=ReadOnly | ReadWrite”
In this article, we’ve discussed two common doubts/questions when talking about Availability Groups. There are more facts to come!! So stay tuned to SQL Shack for more 😉

With experience working in Portugal, Holland, Germany and United Kingdom, he's always available to learn and share his knowledge, in order to contribute to SQL Server community,
View all posts by Murilo Miranda
- Understanding backups on AlwaysOn Availability Groups – Part 2 - December 3, 2015
- Understanding backups on AlwaysOn Availability Groups – Part 1 - November 30, 2015
- AlwaysOn Availability Groups – Curiosities to make your job easier – Part 4 - October 13, 2015