
Introduction
In this article, we will be discussing Clustering in Azure Machine Learning which is another machine learning technique such as Regression analysis, Classification analysis. During this article series, we have discussed the basic cleaning techniques, feature selection techniques and Principal component analysis, Comparing Models and Cross-Validation until today. We will introduce further few techniques that were not discussed before in this article as well. Previously, we have discussed how to perform clustering in SQL Server during the SQL Server Data Mining series.
What is Clustering?
Clustering is an unsupervised technique that is used to perform natural grouping on your data set. For example, if you are the head of customer relations, you would prefer to group your customers depending on the number of officers you have so that you can allocate separate officers to each given cluster. What are attributes that can be used to group your customers as there are many attributes such as age, salary, designation, education qualification, etc.? Since there are a lot of attributes, you need machine learning techniques to group them. Clustering in Azure machine learning provides you with techniques to cluster your data set.
There are different cluster techniques as shown in the below figure.
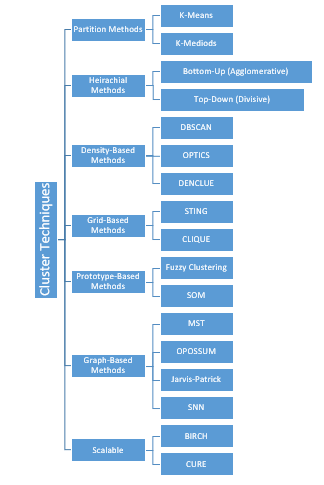
Though you will see a large number of clustering techniques, K-Means is the only technique that is supported in Clustering in Azure Machine learning.
Simple Clustering
Let us look at how to create simple Clustering in Azure Machine Learning. This time we will not be using the same controls that were used for Classification and Regression in the previous articles.
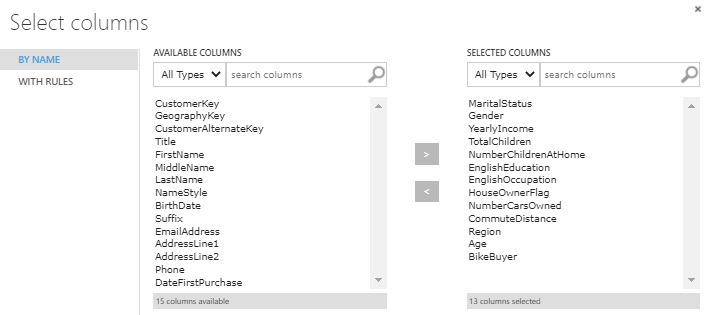
Let us start with creating an empty experiment after login into azure machine studio. Then drag and drop the adventure dataset which we have been using in the previous articles. Since we do not need all the columns, let us select MaritalStatus, Gender, YearlyIncome, TotalChildren, NumberChildrenAtHome, EnglishEducation, EnglishOccupation, HouseOwnerFlag, NumberCarsOwned, CommuteDistance, Region, Age and BikeBuyer attributes by using Select Columns in Dataset as shown in the below screen.
Though we can use the clustering straightway, you will see that your clusters will not be in good shape as YearlyIncome is not normalized. To accomplish the uniformity, we can use Normalized Data control as Zscore as the transformation function. With that, you are ready to perform clustering techniques.
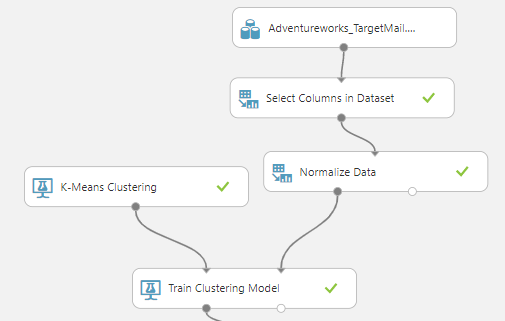
In Clustering in Azure Machine Learning, we are introducing two new components that were not introduced before. Those two controls are K-Means Clustering and Train Clustering Model. There are connected to the Normalized Data control set as shown in the above figure.
Let us see how we can configure, these controls. First, we will start with K-Means Clustering.
K-Means Clustering
As indicated before, Azure Machine learning supports only K-Means clustering and there are a few configurations to be done as shown below.
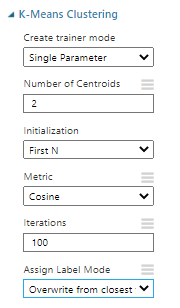
In the K-Means clustering, there are two types of trainer mode, Single Parameter and Range Parameter. The Single parameter is used if you know your parameters. The range Parameter option is used along with the Sweep Clustering control that will be discussed later. The number of centroids is an important parameter in clustering that will define how many clusters you will get. This value is by default is set to two and if you set this to a large value, it does not guarantee that you will get the clusters. Two types of distance measures are Euclidean and Cosine.
Train Clustering Model
In the train clustering model, you can choose the columns that are required for the cluster. This means that you do not have to use Select Columns in Dataset control though we have used it as a practice. Following is the cluster graph that shows these there is less discrimination between these clusters.
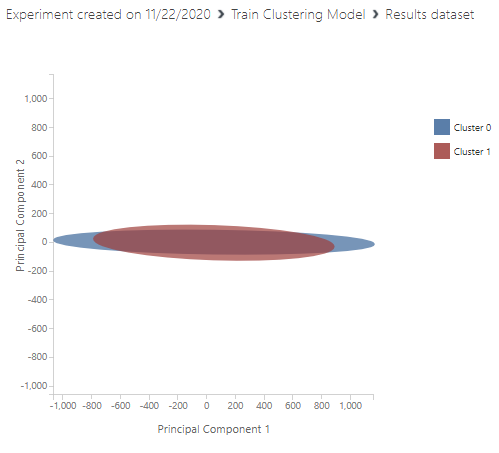
With these two configurations, you are done with the modeling of K-Means Clustering in Azure Machine Learning. Since this an unsupervised training, evaluation of the clustering is not possible as classification or regression. The next task is to allocate different data points to the derived clusters.
Assign Data to Clusters
In this exercise, we need a data source. It can be the same data source that we used before or a different data source. To simulate the real-world scenario, let us use a different dataset.
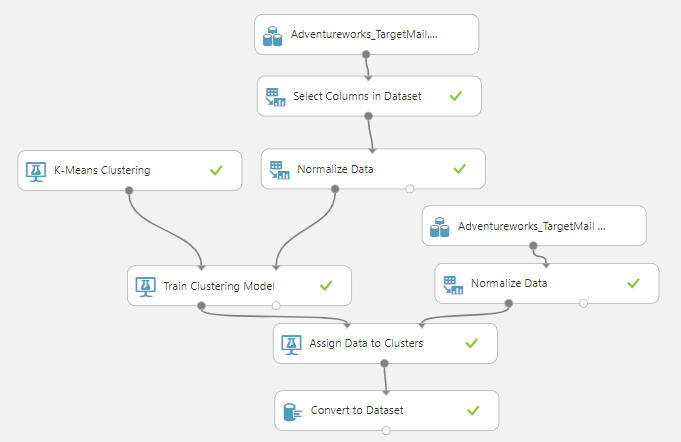
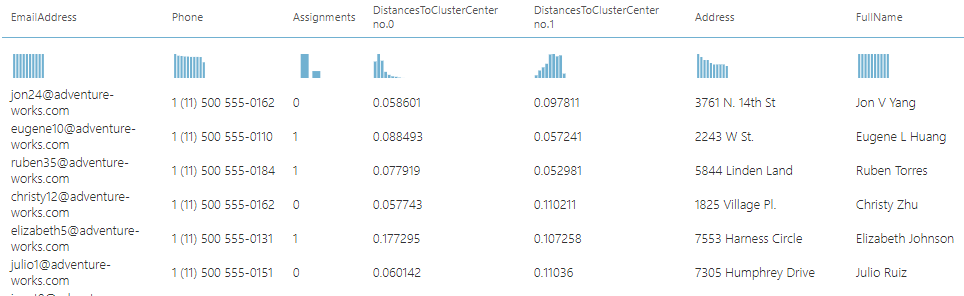
Assign Data to Clusters control does not have any configurations. This control simply joins the data set with the trained model. To visualize the cluster data, you need to use the Convert to Dataset control. From the Covert to DataSet control, you can view the Cluster assignments and distance to each cluster as shown in the below figure.
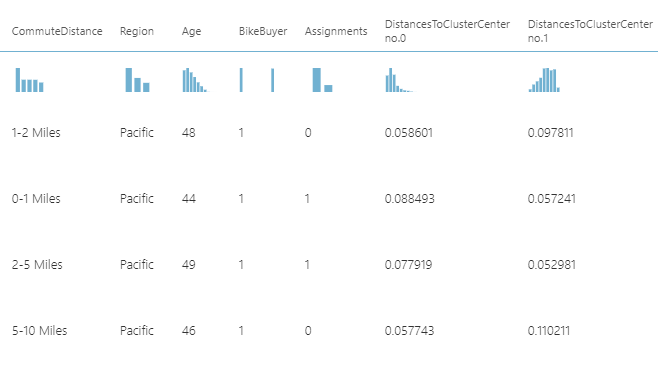
If you further analyze the above data output, you will see that the relevant customer or the record is assigned to the closest cluster.
In a practical situation, we would like to see the output as the contact details of customers rather than the model parameters such as name, address, email address and phone number. It is much prettier if you can concatenate names and addresses into a single column rather than displaying them in separate columns. Since there is no inbuilt technique to concatenate in Azure Machine learning, you can write a python script. Please note that third-party controls are available and you find them with a simple google search.
Following is the python code that can be used in the Execute Python Script Control.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import pandas as pd def azureml_main(dataframe1 = None, dataframe2 = None): dataframe1["Address"] = dataframe1["AddressLine1"] dataframe1.loc [dataframe1['AddressLine2'] == 'NULL','Address'] = dataframe1["AddressLine1"] dataframe1.loc [dataframe1['AddressLine2'] != 'NULL','Address'] = dataframe1["AddressLine1"] + ' ' + dataframe1["AddressLine2"] dataframe1["FullName"] = dataframe1["FirstName"] dataframe1.loc [dataframe1['Title'] != 'NULL','FullName'] = dataframe1["Title"] + ' ' + dataframe1["FullName"] dataframe1.loc [dataframe1['MiddleName'] != 'NULL','FullName'] = dataframe1["FullName"] + ' ' + dataframe1["MiddleName"] dataframe1.loc [dataframe1['LastName'] != 'NULL','FullName'] = dataframe1["FullName"] + ' ' + dataframe1["LastName"] return dataframe1 |
Then after performing a simple Column Selection, now clustered data is available in Clustering in Azure Machine Learning as shown in the below figure.
Now, you can deploy this model as a web service and use it for prediction as we did in a previous article.
If you want to distribute this data to different data streams you can do this by using a Split Data control. In this Split Data configuration, it is configured as below.
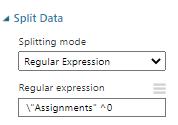
If you have more than two clusters and you need to separate them into different data streams, you need to use multiple Split Data as Split Data supports only two divisions.
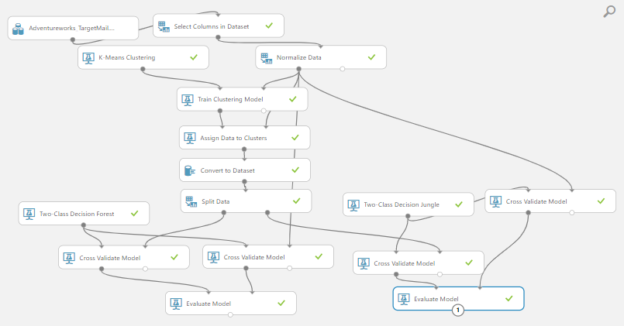
This is the final model for Clustering in Azure Machine Learning.
Choosing the Optimum Number of Clusters
As we discussed briefly, rather than we define the number of clusters, we can use Sweep Clustering control to define the optimum number of clusters as shown below.
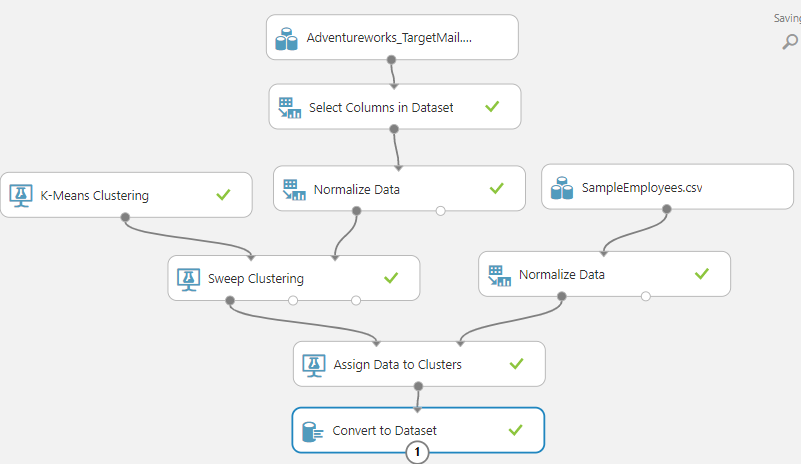
Let us see how to configure Sweep Clustering. To retrieve the optimum clusters, we need to modify the K-Mean clustering as follows.
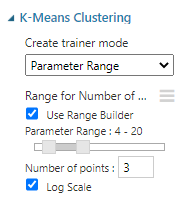
In the above configuration, we are specifying the number of clusters in a range. Following are the outputs of Sweep Configurations. In the sweep clustering control, the first output is the best model while the last output is the execution of multiple clusters. The second output provides the data with cluster assignments.
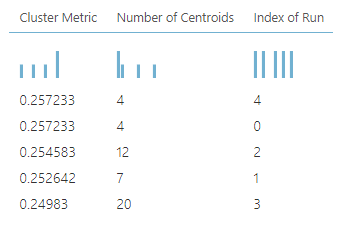
As you can see, the optimum number of clusters is four as it has the highest cluster metric.
Clustering and Classification
As we have discussed the classification before, now we can integrate Clustering and Classification together. Rather than applying classification for the entire data, we can configure classification for separate clusters so that we can choose optimum classification techniques. You can have different classification techniques for different clusters.
However, it is important to make sure that you will have an adequate number of data for each classification as you perform classification for divided clusters, it will reduce the number of records.
Conclusion
This article discussed one of the main unsupervised techniques, Clustering in Azure Machine Learning. Though there are a lot of clustering techniques, K-Means is the only technique that is supported in Azure Machine Learning. By using clustering, we can assign the data set to the defined clusters. Similarly, we can use Sweep Clustering to find the optimum clusters. Further, we looked at the option of combining Clusters and Classification in order to achieve better results.
Further References
- https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/k-means-clustering
- https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/train-clustering-model
- https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/assign-data-to-clusters
- https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/sweep-clustering
Table of contents

View all posts by Dinesh Asanka
- Testing Type 2 Slowly Changing Dimensions in a Data Warehouse - May 30, 2022
- Incremental Data Extraction for ETL using Database Snapshots - January 10, 2022
- Use Replication to improve the ETL process in SQL Server - November 4, 2021