
Introduction
After discussing a few algorithms and techniques and comparison of models with Azure Machine Learning, let us discuss a validation technique, which is Cross-Validation in Azure Machine Learning in this article. During this series of articles, we have learned the basic cleaning techniques, feature selection techniques and Principal component analysis etc. After discussing Regression analysis, Classification analysis and comparing models, let us focus now on performing Cross-Validation in Azure Machine Learning in order to evaluate models.
What is Cross-Validation?
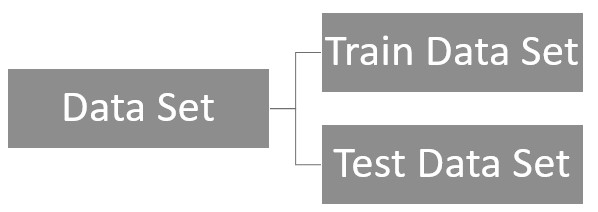
In Machine learning, we are building models using the existing data. In standard software development, you have input and output that can be verified much easily. However, in machine learning modeling, you have either prediction or prescription models. In the machine learning models, you have to evaluate with independent data set. If you are evaluating these built models with a bias data set, you will have a higher accuracy rate but will not be accurate when it comes to predictions. This is called overfitting in machine learning that has to be fixed. Until now, we split the data set into two streams, train and test by using Data Split and we used the train data set to build the model while the test data set was used to evaluate the built model. Typically, 70% will be allocated to train while the remaining 30% will be allocated to the test data set to evaluate the model as shown in the below figure:
However, in the above technique, there can be biases towards the train data set. As you know, in machine learning we have the issue of fewer data. With the above technique, we are reducing our data further. In Cross-validation in Azure Machne Learning, we will be using the entire data set for training and testing using the K-Folder technique in Cross-Validation. In the K-Fold cross-validation technique, the data is divided into k number of subsets. Then each subset from all datasets is treated as the validation set of the model for the model built for the rest of K-1 folds. This will be done for K iterations.
Let us look at the following example:
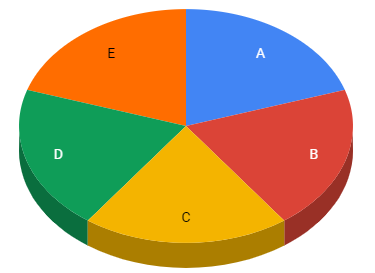
Let us say that the data set is folded to five folds and label them in A, B, C, D, and E as shown in the above figure. Then, the following are the iterations.
| Iteration | Train Set | Test Set |
| 1 | A-B-C-D | E |
| 2 | B-C-D-E | A |
| 3 | A-C-D-E | B |
| 4 | A-B-D-E | C |
| 5 | A-B-C-D | D |
Though Cross-Validation in Azure Machine Learning supports the K-Folder technique, a few other cross-validation techniques are used in the industry.
| Cross-Validation Technique | Description |
| Stratified K-fold | Similar to K-fold. It will distribute an approximately equal percentage of samples of each target class as the whole set. This can be achieved from the Cross-Validation in Azure Machine as discussed later in the article. |
| Holdout Method | Randomly assign data points to two folds and one is used for training and the other one is used for testing. Though this is a very simple technique, this will yield poor results. |
| Leave P Out | In this technique, p records will be used for testing and the rest will be used for training. This will be carried out for all the combinations. This is a very resource intensive process as there can be a large number of combinations. |
| Leave One Out | This is the same as the Leave P Out method but the P = 1 |
Azure Machine Learning supports the K-fold technique and Stratified K-fold and lets us see how we can implement them in Azure Machine Learning.
Cross-Validation in Azure Machine Learning
Let us look at implementing Cross-Validation in Azure Machine Learning. Let us use the sample Adventure Works database that we used for all the articles.
Then Cross Validate Model is dragged and dropped to the experiment. The Cross Validate model has two inputs and two outputs. Two inputs are data input and the relation to the Machine Learning technique. Let us use the Two-Class Decision Jungle as the Machine Learning Technique. Then the first output is connected to the Evaluate Model as shown in the following figure:
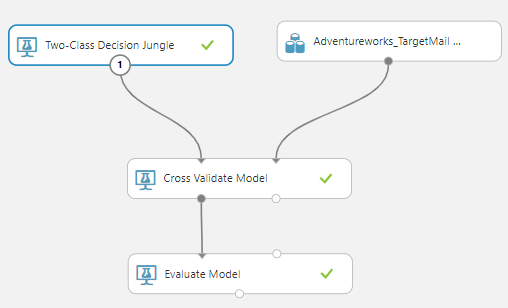
In the Cross validate model, we need to configure the label column which is the BikeBuyer. However, we do not have the configuration option to specify the number of folds. This can be done from a different configuration as discussed later in the article.
The second output of the Cross Validate Model will provide you with the standard classification evaluation parameters for each fold as shown below:
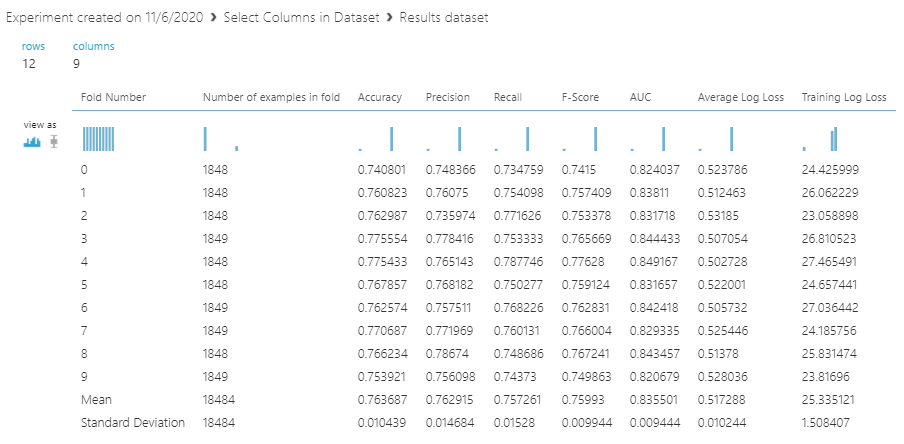
Important information in the above figure is the Standard Deviation. As you will see that the standard deviation is very small, the model is not much biased with the data.
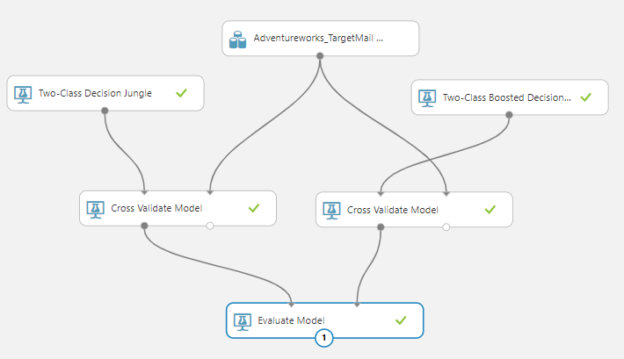
As we did in the last article, we can compare the evaluation with different techniques with cross-validation in Azure Machine Learning.
By looking at the following figure it can be observed that the Two-Class Boosted Decision tree technique is better than the Two-Class Decision Jungle.
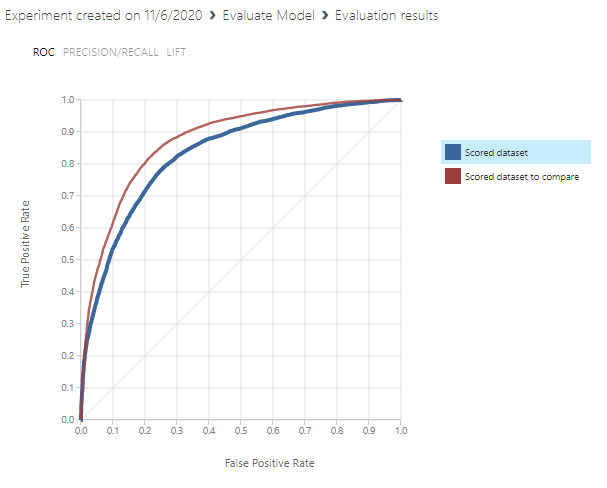
Similarly, you can check the other evaluation parameters such as Accuracy, Precision, Recall and F1 measure like we did in the previous article.
Modifying the Folds
If you have a large number of data set, having ten folds might take a long time to produce results. In that situation, you need to modify the number of folds using the Partition and Sample control.
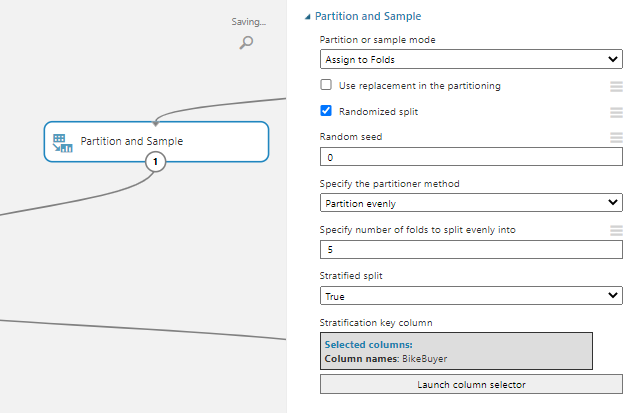
In the above configuration in the Partition and Sample control, we have chosen Assign to Folds as the Partition mode and we have set the number of folds to five or any other desired number. Further, we have the Stratification split to yes and the stratification key column as BikeBuyer so that we will see the same distribution in each fold. This means that we can achieve the Stratified K-fold cross-validation technique in Azure Machine Learning.
Partition and Sample control are added between the dataset and the Cross Validate Model as shown in the following figure:
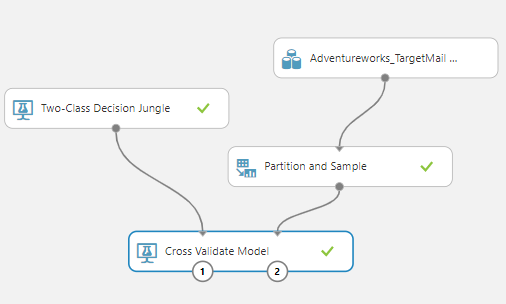
Like we did before, let us look at the fold wise evaluation parameters.
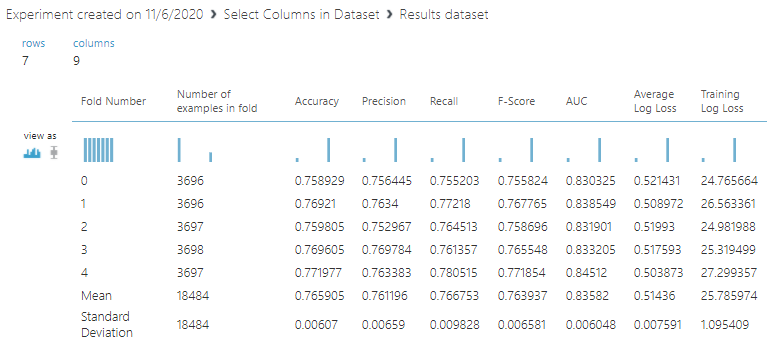
Now you can see that number of folds is reduced to five. Like before, the standard deviation is very small which means this model is verified with a unbias dataset.
Similar to comparing models, we can perform the comparison of models with Partition and Sample control. We can extend the partition and Sample for multiple cross validate model controls as shown in the below figure:
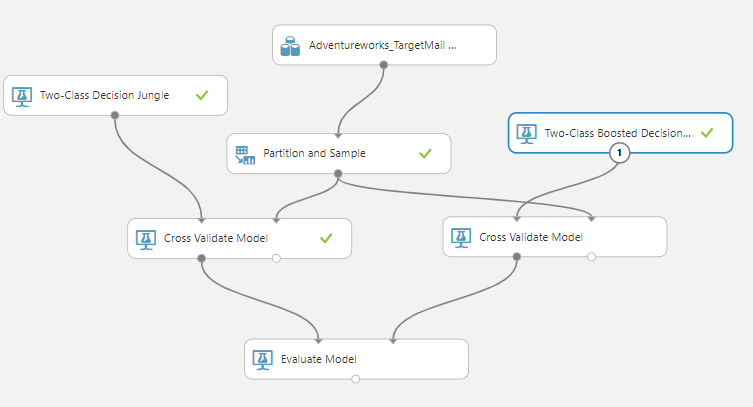
Similar to the previous comparison, we can do the same comparison with the inclusion of Partition and Sample.
Though we have discussed Classification techniques in this article, you can use Cross-Validation in Azure Machine Learning to evaluate other techniques such as Regression, Clustering etc.
Conclusion
Cross-Validation in Azure Machine Learning is an important evaluation technique to avoid overfitting of machine learning techniques. In the Azure Machine Learning Cross-validation model, there will be ten folds as default. Further, you can decide a different number of folds with Partition and Sample controls if the performance of the ten folds is unsatisfactory to your dataset. Using this technique, not only you can define the number of folds but also you have the ability to distribute the data as well. In the Cross Validate Model control, you can find the mean and the standard deviation for all the folds. By looking at the standard deviation, you can decide whether the model is built on an unbias dataset.
Further References
- https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/cross-validate-model
Table of contents

View all posts by Dinesh Asanka
- Testing Type 2 Slowly Changing Dimensions in a Data Warehouse - May 30, 2022
- Incremental Data Extraction for ETL using Database Snapshots - January 10, 2022
- Use Replication to improve the ETL process in SQL Server - November 4, 2021