
Introduction
As we are well into the discussions of Text Analytics in Azure Machine Learning from the last couple of articles, we will be discussing the Filter based Feature Selection in Text Analytics and how we can build a prediction model from the Filter Based Feature Selection in order to perform text classification.
Before this article, we have discussed multiple machine learning techniques such as Regression analysis, Classification Analysis, Clustering, Recommender Systems and Anomaly detection of Time Series in Azure Machine Learning by using different datasets. Further, we have discussed the basic cleaning techniques, feature selection techniques and Principal component analysis, Comparing Models and Cross-Validation and Hyper Tune parameters in this article series as data engineering techniques to this date. In the first article on Text Analytics, we had a detailed discussion on Language detection and Preprocessing of text in order to organize textual data for better analytics. In the last article, we discussed how to recognize Named entities in Text Analytics.
We will be using previously discussed techniques to build the Azure Machine Learning Experiment with Filter Based Feature Selection in Text Analytics.
Sample Dataset
For this experiment, we will be using an existing dataset Wikipedia SP 500 Dataset. First, let us see the properties of this dataset.

There are three columns in the above dataset. What we are going to achieve in the Azure Machine Learning Experiment is, by examining the Text, to develop a model for Category classification. There are a few categories in the dataset which are Information Technology, Consumer Discretionary, Energy, Consumer Discretionary, Financials, Consumer Staples, Industrials, Health Care, Materials.
The target of this experiment is to build a machine learning model to identify any special relations between categories and text of the content. As you can imagine, this will not be an easy task as there can be differences in the content.
Let us start building the azure machine learning experiment and by using the basic features that we discussed in the previous articles.
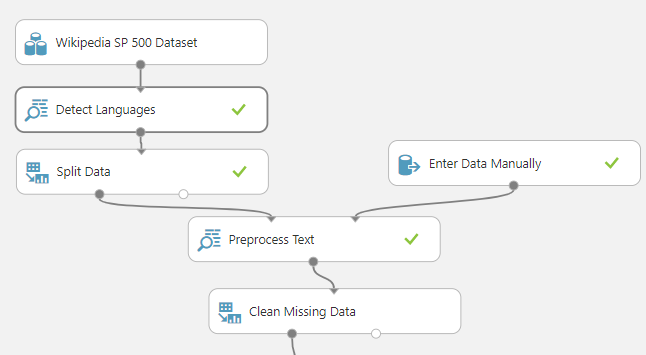
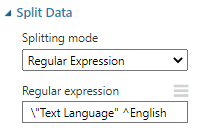
After the dataset is defined, as usual, we need to extract English content only as if not different techniques should be used for different languages. After the language detection is completed, Spilt Data control is used to choose only the English term by configuring the Split Data control like below.
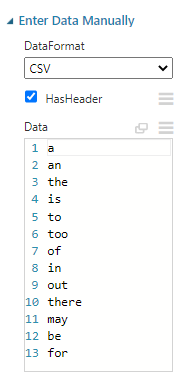
Then we used the Preprocess Text control so that URLs, emails are removed as they do not count for the semantic meaning of contents. Further by using the stop words at the Enter Data Manually control as configured below, we will eliminate non-contextual words.
After the preprocess text, there can be situations where the entire text will become empty. Those rows should be removed by using the Clean Missing Data as configured below.
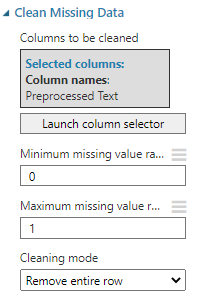
Since we have chosen Remove Entire row option, the entire row will be removed if the Preprocessed Text column is empty. Please note that, for this data set, the Clean missing data option is not required, but it is included in this example for completeness.
Filter Based Feature Selection
After preprocessing tasks are completed, next is to get into the business with Feature Hashing. The following are the next important controls that have been newly added to this experiment.
In the Feature Hashing control, we need to convert the text content into vectors.
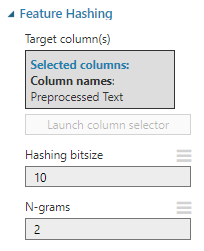
There are two parameters to be defined in the Feature Hashing control. Hashing bitsize will define the maximum number of vectors. 10 hashing bitsize means 1,024 vectors (2^10). 1,024 vectors are more than enough even for the large volume text files. Next, we need to choose N-grams which is 2 as 2 is the optimal number for N-grams for most situations. A detailed description of N-Grams is given in the link given in the reference section.
After the vectors are generated, we do not need other text columns. Apart from the vectors, we need only the dependent attribute or the category column in this example. Therefore, we can remove the unnecessary attributes by Select Columns in dataset control. However, this control will show 1,024 vectors even though it is not available in the previous step, Feature Hashing. Therefore, you need to choose only the available attributes in the Feature Hashing control at the Select Columns in dataset control. In the above example, only 93 vectors were generated.

The drawback of the Feature Hashing control is that it does not provide the Hashing feature. If the feature hashing feature is provided, the user will have the option of understating this control more. Apart from this drawback, the other drawback is that the inability to calculate TF-IDF options. In Azure Machine Learning, there is no control to reduce the weights when the same term exists in many documents which are called Inverse Document Frequency (IDF).
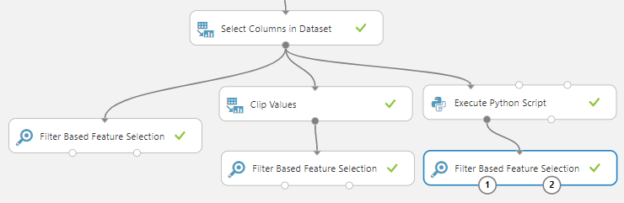
In the case of the weka tool, there are many options such as binary, exponential methods to calculate term frequency. Though there is no direct method to find those numbers in azure machine learning, we can use Clip Values and Execute Python Script to achieve those options.
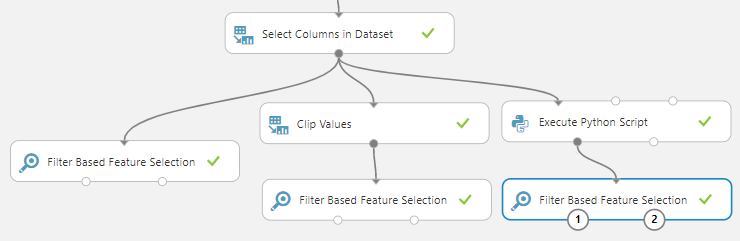
Clip Values control will replace all the values which are greater than 1 to 1 by using the following configurations.
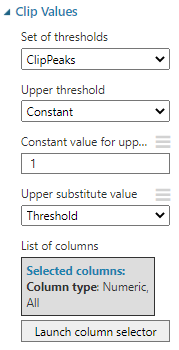
Then the output will be as follows.

The next method is using the log term frequency by using a Python script and the script is as follows.
|
1 2 3 4 5 6 7 |
import pandas as pd import numpy def azureml_main(dataframe1 = None, dataframe2 = None): for i in range(1,len(dataframe1.columns)): dataframe1.iloc[:,i] =numpy.log ( 1 + dataframe1.iloc[:,i] ) return dataframe1, |
The above script will change the existing values of all columns to the log values. The above script will provide the following output.
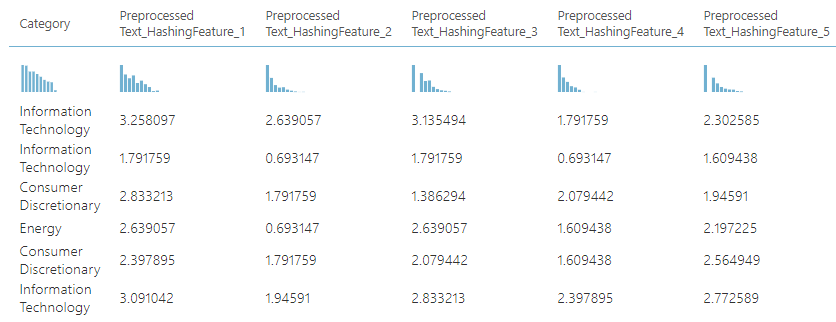
However, document normalization should be implemented via python or R scripting in Azure Machine Learning. After the vectors are derived now it is time to build the model. You can use the existing 93 vectors but using 93 vectors will not be practical. Therefore, we can use Filter Based Feature Selection control can be used to choose the most important vectors.
We will be using the same configuration of Filter Based Feature Selection for all three methods.
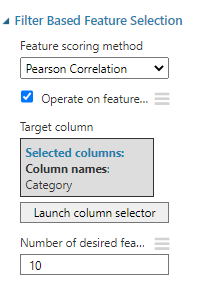
There are multiple scoring methods and we have used Pearson Correlation and you can find the features for the other scoring methods in the given reference.
We will choose the most important 10 features and let us compare the different important features that were resulted from Filter Based Feature Selection control for different techniques.
|
Normal Frequencies |
Binary (Clip Values) |
Log based (Python) |
|
HashingFeature_77 |
HashingFeature_77 |
HashingFeature_77 |
|
HashingFeature_39 |
HashingFeature_68 |
HashingFeature_46 |
|
HashingFeature_85 |
HashingFeature_46 |
HashingFeature_85 |
|
HashingFeature_46 |
HashingFeature_37 |
HashingFeature_39 |
|
HashingFeature_91 |
HashingFeature_71 |
HashingFeature_68 |
|
HashingFeature_35 |
HashingFeature_31 |
HashingFeature_38 |
|
HashingFeature_79 |
HashingFeature_85 |
HashingFeature_35 |
|
HashingFeature_38 |
HashingFeature_64 |
HashingFeature_20 |
|
HashingFeature_3 |
HashingFeature_14 |
HashingFeature_11 |
|
HashingFeature_44 |
HashingFeature_36 |
HashingFeature_91 |
From the above table, depending on the technique the parameters are different. After the Filter Based Feature selection, next is to build the multi-class classification model which we have done. Since we have done this modelling multiple times in many previous articles, it will not be discussed in detail.
We have used the multiclass Decision Forest and similarly, we can use many other multiclass classification techniques. The following table shows the average accuracy for each method.
|
Normal Frequencies |
83.86 % |
|
Binary (Clip Values) |
82.43 % |
|
Log-based (Python) |
85.00 % |
Since the Log-based method has a little higher accuracy than others, we can choose the Log-based technique. Following is the confusion matrix for the log-based technique.
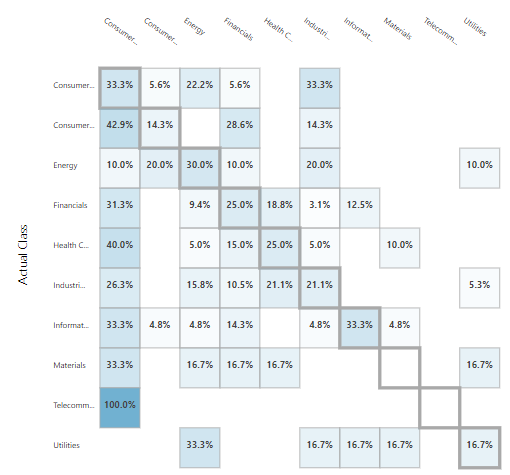
We can create the web service with input and output predict as the prediction for the unknown texts. The fully completed Azure Machine Learning experiment with Filter Based Feature Selection in Text Analytics can be found at https://gallery.cortanaintelligence.com/Experiment/Filter-Based-Feature-Selection-in-Text-Mining.
Conclusion
In this article, we discussed how to model text content and perform predictions. We used basic preprocessing techniques and Feature Hashing was done in order to find the relevant features. Then by using the Filter Based Feature Selection control the important features were selected. Then the classification is applied using the multi-class classification technique.
Before the Filter Based Feature Selection, we have used three different techniques in order to extract the term frequencies and the models were built for all those techniques. Finally, the evaluation is carried out for all the models to identify the better technique.
References
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/feature-hashing
https://gallery.cortanaintelligence.com/Experiment/Filter-Based-Feature-Selection-in-Text-Mining
Table of contents

View all posts by Dinesh Asanka
- Testing Type 2 Slowly Changing Dimensions in a Data Warehouse - May 30, 2022
- Incremental Data Extraction for ETL using Database Snapshots - January 10, 2022
- Use Replication to improve the ETL process in SQL Server - November 4, 2021