
In this article, we will be discussing how to design a Recommender System in Azure Machine learning which is the next article in the Azure Machine Learning series. During this lengthy article series on Azure Machine Learning, we have discussed multiple machine learning techniques such as Regression analysis, Classification Analysis, Clustering and Anomaly detection of Time Series. Further, we have discussed the basic cleaning techniques, feature selection techniques and Principal component analysis, Comparing Models and Cross-Validation and Hyper Tune parameters in this article series to date.
What are Recommender Systems?
If you are buying some goods from Amazon.com, you would have noticed that there are recommendations for you to buy more related items. In most commercial websites, recommendations are provided in order to increase revenue as well as customer satisfaction.
There are two types of recommender systems that is Content-Based and Collaborative filtering. In the content-based approach, both user properties, and item properties will be considered for recommendations. In the collaborative filtering approach, transactions and user ratings are taking into account. In Azure Machine Learning, Matchbox recommender is introduced which has a combination of content-based and collaborative filtering recommenders. Therefore, Matchbox recommender can be considered as a Hybrid recommender system to design a recommender system in Azure Machine Learning.
Let us see how to use Matchbox recommender to develop recommender systems.
Matchbox Recommender in Recommender Systems in Azure Machine Learning
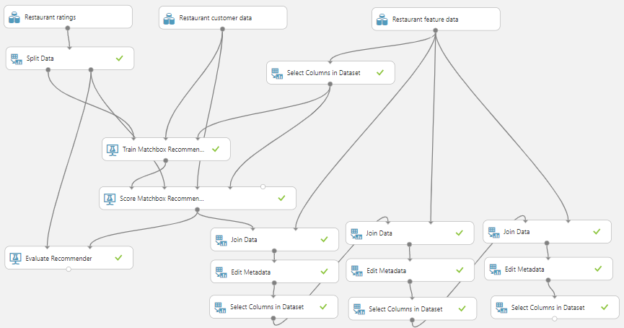
First of all, let us use the existing data set of Restaurant data set in Azure Machine Learning which is shown in the below image.
The restaurant ratings data set has ratings by users for the given restaurant while the restaurant feature data set has the features of data. Restaurant customer data set consists of user profile data.
Let us see the experiment first and then let us examine the configurations. This experiment is available at https://gallery.cortanaintelligence.com/Experiment/Recommender-Systems-Restaurant and the following is the screenshot of the entire experiment.
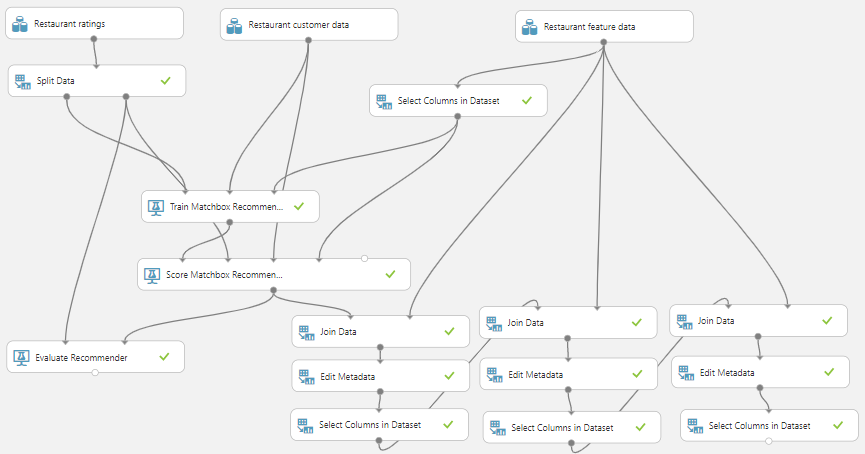
Though this is a much complex experiment than the previous examples, let us look at each control individually. Restaurant ratings data set contains userID, PlaceID, and ratings. Please note that the Match Box recommender needs columns in that the same order of user, place, or item and ratings. If you don’t have ratings, you need to derive ratings from existing attributes which we will look at in a different scenario. Like we did in Classification, we need to split data for training and evaluating which is done by the Split Data control with the Recommender Split as the splitting mode.
Then, the first output of the data split is connected to the Train Matchbox Recommender control. In the Train Matchbox Recommender controller, the second port should have the user or customer data while the third or the last port should have data input from items. In this scenario, it is the restaurant data.
Let us see what the configurations for the Train Matchbox Recommender are as shown in the following figure.

The number of traits configuration decides how many attributes from the user and item data streams are considered for the recommender system in which the default is 10. In this configuration, the number of recommendation algorithms iteration is 5. Typically, if you have a higher value for this parameter, higher accuracy can be achieved but more resources are utilized.
The next important control is the Score Matchbox Recommender controller. This is the most important configuration in the Recommender system in Azure Machine Learning.

In the Recommender prediction kind option, there are four options such as Rating Prediction, Item Recommendation, Related Users and Related Items. In this scenario, we are looking at item recommendations so that the relevant option is selected. As you can see from the options, you have the options of selecting related users and related items as well as performing the rating predictions for the unrated data.
Similarly, item selections can be done for the rated items as well as for the unrated items. By configuring 3 for the Maximum number of items to recommend to a user option, we have limited the number of recommendations to 3.
In the Score Matchbox Recommender controller, there are five ports, and, in this example, we are using four ports. The first port is coming from the Score Matchbox Recommender controller while the second port is for the data coming from the second output of the Data split control. The next two ports are for customer and restaurant data respectively.
Now You are ready for the output which can be seen in the following figure.
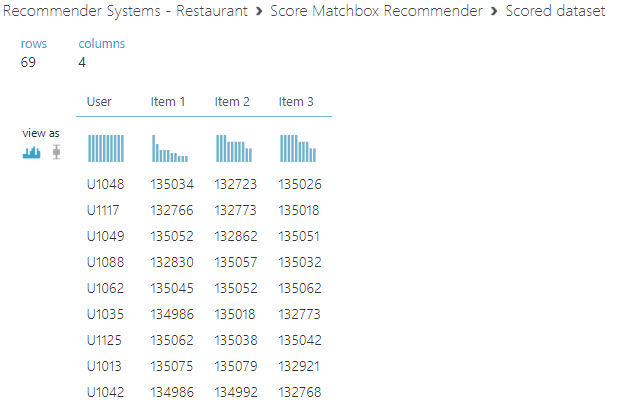
This means that the users are provided with recommendations with a maximum of three items. Since we are using PlaceID, the recommendation will be in the form of PlaceID. However, we can join the dataset to the Restaurant data set and by filtering unnecessary columns, you can view the Restaurant names instead of their ids.
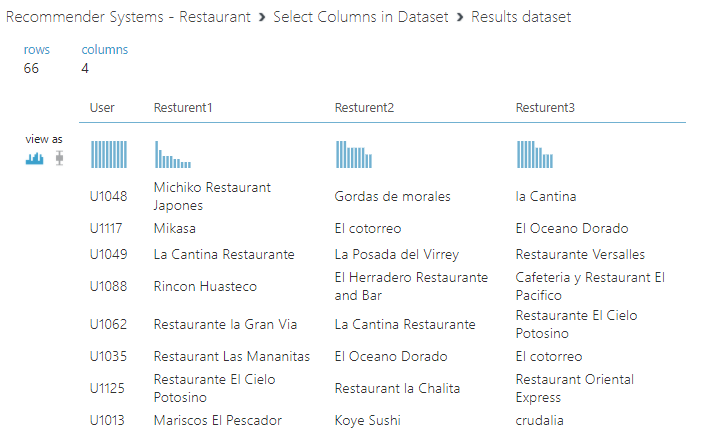
Next is the evaluation of the recommender system in Azure Machine learning for which Evaluate Recommender controller is used. For this control, the output of the split data set and Score Matchbox Recommender controller is used. Normalized Discounted Cumulative Gain (NDCG) is the parameter that is considered for the accuracy of the recommended model. When you have a higher value for the NDCG parameter, the recommender system is believed to be a higher accuracy model. In this scenario, NDCG has a value of 0.8873 or 88%.
Scenario 2
After designing a recommender system in Azure machine learning for a restaurant, let us use the typical Adventureworks database for a different recommender system.
First, we need to find the queries for transactions, users, and items.
The following is the T-SQL script for the user transactions. We need CustomerID and ProductID as well as the ratings. In this example, we have used transaction count as the ratings. If the count is more than 5, it will be replaced with 5 later in the experiment by using the Clip Values control.
|
1 2 3 4 5 6 7 |
SELECT CustomerID ,ProductID ,COUNT(1) AS Count FROM [Sales].[SalesOrderHeader] SOH INNER JOIN [Sales].[SalesOrderDetail] SOD ON SOH.SalesOrderID = SOD.SalesOrderID GROUP BY CustomerID ,ProductID |
The next script is to extract customer details. We have used the CONCAT function to combine the customer name columns and bucketized the Sales amount as shown in the below script.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
SELECT Cus.CustomerID ,CONCAT ( Per.[Title] ,' ' ,Per.[FirstName] ,' ' ,Per.[MiddleName] ,' ' ,Per.[LastName] ) CustomerName ,Ter.NAME AS TerritoryName ,Ter.CountryRegionCode ,Ter.[Group] ,CASE WHEN Ter.SalesYTD < 3000000 THEN 'Low' WHEN Ter.SalesYTD < 6000000 THEN 'Medium' ELSE 'High' END AS SalesCategory ,ISNULL(S.NAME, 'No Store') AS StoreName ,Per.PersonType FROM Sales.Customer AS Cus INNER JOIN Person.Person AS Per ON Cus.PersonID = Per.BusinessEntityID LEFT JOIN Sales.Store AS S ON Cus.StoreID = S.BusinessEntityID INNER JOIN Sales.SalesTerritory AS Ter ON Cus.TerritoryID = Ter.TerritoryID |
The final query is to extract Product details as shown below.
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT ProductID ,ProductNumber ,P.NAME ProductName ,MakeFlag ,FinishedGoodsflag ,ISNULL(Color, 'NA') Color ,ISNULL(SC.NAME, 'NA') ProductSubcategory ,ISNULL(C.NAME, 'NA') ProductCategoryName FROM Production.Product P LEFT JOIN Production.ProductSubcategory SC ON P.ProductSubcategoryID = SC.ProductSubcategoryID LEFT JOIN Production.ProductCategory C ON SC.ProductCategoryID = C.ProductCategoryID |
Now let us build the Recommender System in Azure Machine Learning with the above data. Like we did before, the following is the experiment that is published in the azure machine learning gallery.
https://gallery.cortanaintelligence.com/Experiment/Matchbox-Recommender-Adventureworks
The following figure shows the entire experiment in Azure Machine Learning:
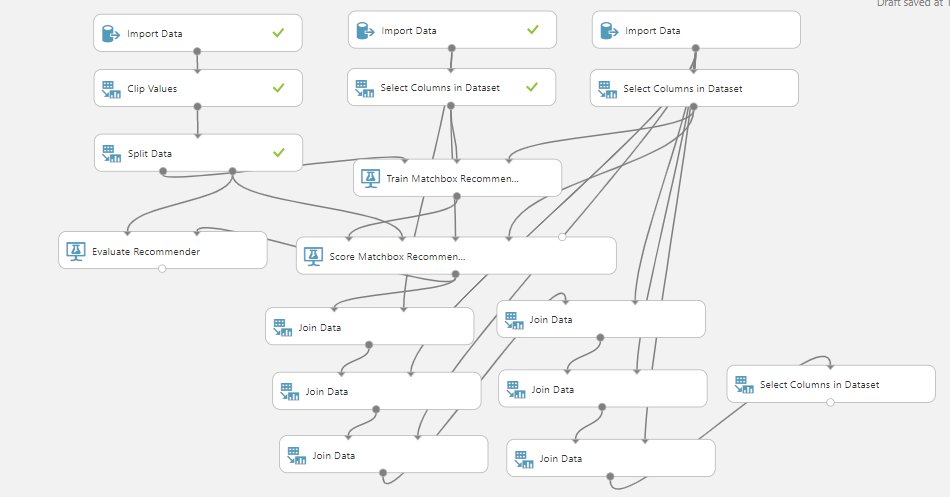
In this experiment, we are extracting data from Azure SQL Database. Import Data control is used for that purpose and with the following configuration.
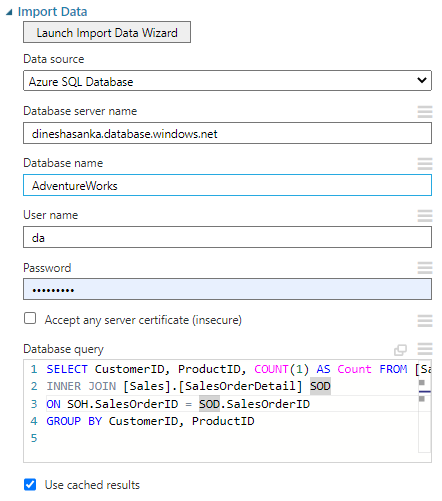
You need to provide the standard connection details of Azure SQL Database with the relevant query and Use cached results option is selected in order to improve the performance. Similarly, customer and product details are extracted using the same configurations.
Select Columns in Dataset is used to choose only the data that is relevant to the recommender system in Azure Machine Learning. However, attributes such as Customer Names and Product Names will be used later to display them in the final output.
The next controls and their configurations are the same controls that we used in the previous experiment, so no additional explanations are necessary. However, in this experiment, we have configured five product recommendations for each customer.
After the recommendations are completed, one join is performed to get the customer details and five more joins are done to receive recommended Products details. The following is the final output of the Recommender System in Azure Machine Learning for each customer and the Product Names.
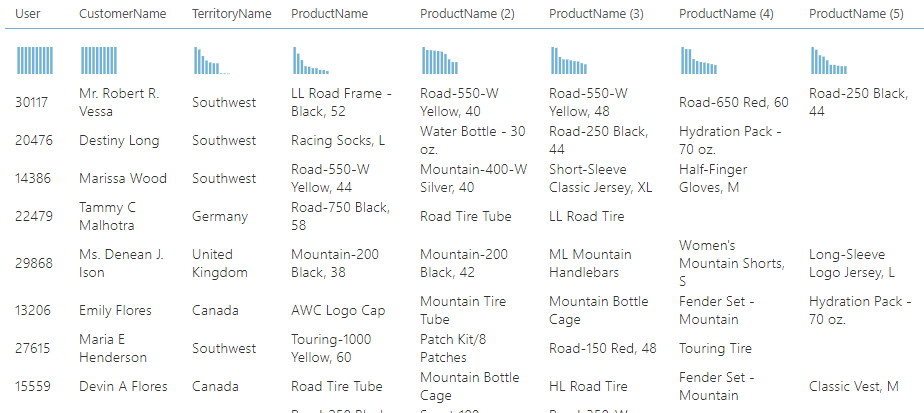
Conclusion
Recommender Systems in Azure Machine Learning is one of the most useful Machine Learning techniques. In Azure Machine Learning, the Matchbox recommender is used to recommend products for customers depending on the customer and product properties. Though this is the most common use case in recommendation systems, there are other features such as finding similar customers and products in the Matchbox recommender.
References
- https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/train-matchbox-recommender
- https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/score-matchbox-recommender
- https://gallery.cortanaintelligence.com/Experiment/Recommender-Systems-Restaurant
- https://gallery.cortanaintelligence.com/Experiment/Matchbox-Recommender-Adventureworks
Table of contents

View all posts by Dinesh Asanka
- Testing Type 2 Slowly Changing Dimensions in a Data Warehouse - May 30, 2022
- Incremental Data Extraction for ETL using Database Snapshots - January 10, 2022
- Use Replication to improve the ETL process in SQL Server - November 4, 2021