
This article discusses how to perform Text classification in Azure Machine using a popular word vector technique in Text Mining. This article is part of the Azure Machine learning series during which we have discussed many aspects such as data cleaning and feature selection techniques of Machine Learning. We further discussed how to perform classification in Azure Machine Learning and we will be utilizing some of those experiences here. Further, we have discussed several machine learning tasks in Azure Machine Learning such as Clustering, Regression, Recommender System and Time Series Anomaly Detection. With respect to text mining, we have discussed techniques such as Language Detection, Named Entity Recognition, LDA, Text Recommendations, etc.
In this article, we will be looking at how to utilize word vectors in order to perform Text Classification in Azure Machine and we will be utilizing the popular WEKA tool as well.
What is a Word Vector
As we know documents have words and sentences and modelling them to analytics is typically a complex task. Therefore, these documents need to be converted to word vectors so that they can be modeled.
Waikato Environment for Knowledge Analysis (WEKA) has rich capabilities to build a word vector for text data. This article will use the word vectors that were created from the WEKA and use them in Azure Machine Learning in order to build the classification models.
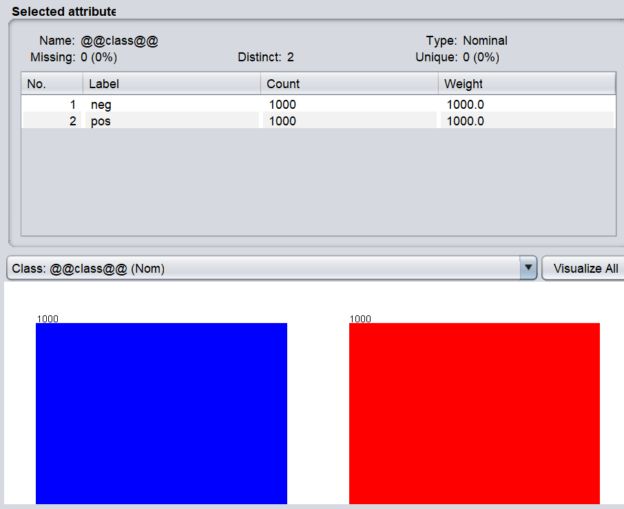
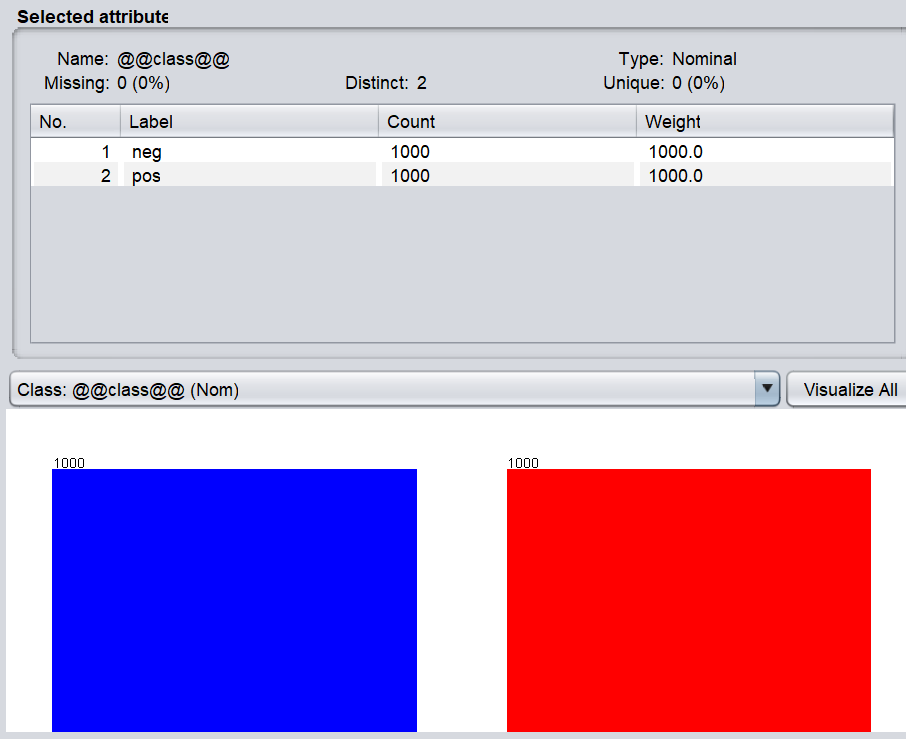
We have selected the popular IMDB 2,000 reviews dataset with its ratings as shown on the screen from WEKA.
There are 2,000 reviews of which 1,000 of them are labeled as positive while the rest of the 1,000 reviews are labeled as negative as shown in the below screenshot.
Our task is to find out what are the keywords that make positive or negative reviews. With this modeling, we will be able to classify unknown reviews into either Positive or negative classes.
After the file is loaded into the WEKA, you need to use a filter, Weka-> filters -> unsupervised -> attribute -> StringToWordVector as shown in the below image.
Once the required filter is selected, you need to configure the selected filter.

The following are the configurations for the selected StringToWordVector filter so that different types of word vectors can be derived.
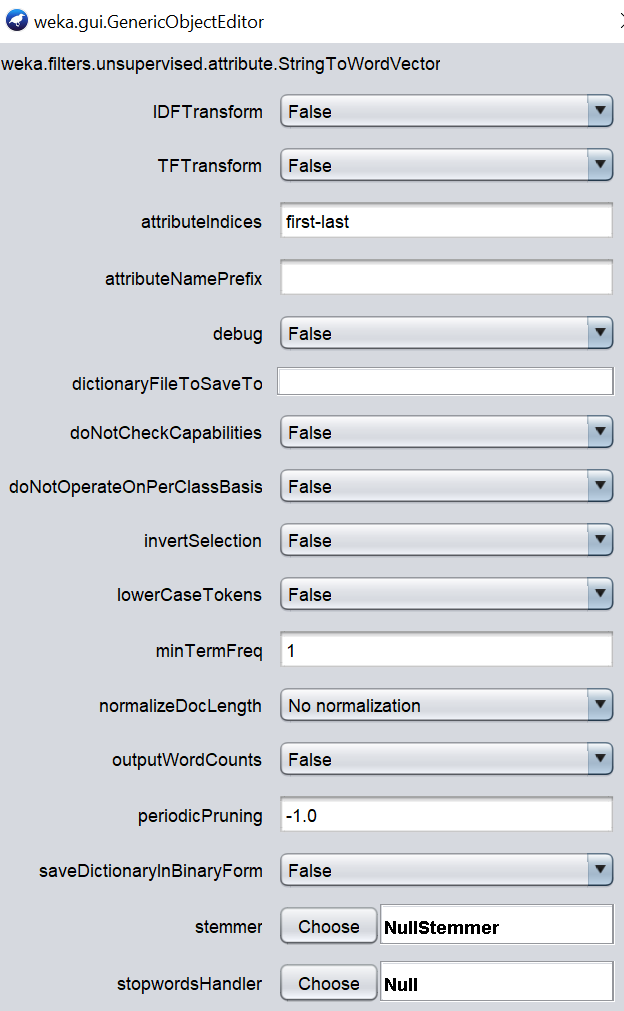
Though there are a lot of configurations for the WordVector filtering, we will be using only a few of these configurations. First, we will look at stemmer, stopwordhandler, tokenizer and no of words to keep as shown in the below figure.
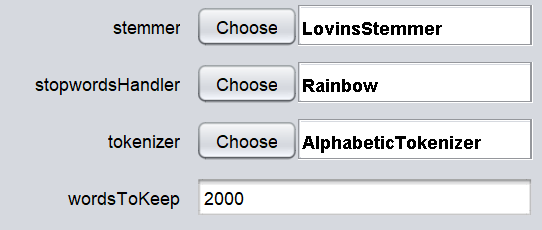
The tokenization technique will decide how the keywords are selected. Since the AlphabeticTokenizer is selected, all the numeric and special characters will be dropped. Stopword configuration will drop the word that does not have any semantic meaning such as I, we, you, a, an, the etc. With the usage of lovinsStemmer stemmer, words will be converted to the base form. Please note that these are classical techniques that are processed in text mining analytics. These are mandatory techniques that should be performed on text documents.
Apart from the above techniques, there are few other techniques that would be dependent on the dataset. Those four configurations should be verified with different configurations using the WEKA.
Word Count: Output word counts rather than 0 or 1(indicating presence or absence of a word).
Term Frequency (TF): Term frequency is transformed to log (frequency +1 )
Inverse Document Frequency (IDF): If the same word is repeated in many documents, IDF will reduce the weightage of the frequency of the word counts.
Document Normalization: This parameter will consider the size of the document.
With four parameters, there are sixteen combinations as shown in the below table.
|
Combination |
IDF |
TF |
World Count |
Document Normalization |
|
1 |
False |
False |
False |
False |
|
2 |
False |
True |
False |
False |
|
3 |
False |
True |
True |
True |
|
4 |
False |
True |
True |
True |
|
5 |
False |
True |
False |
True |
|
6 |
False |
False |
False |
True |
|
7 |
False |
False |
True |
False |
|
8 |
False |
False |
True |
True |
|
9 |
True |
False |
False |
False |
|
10 |
True |
True |
False |
False |
|
11 |
True |
True |
True |
False |
|
12 |
True |
True |
True |
True |
|
13 |
True |
True |
False |
True |
|
14 |
True |
False |
False |
True |
|
15 |
True |
False |
True |
False |
|
16 |
True |
False |
True |
True |
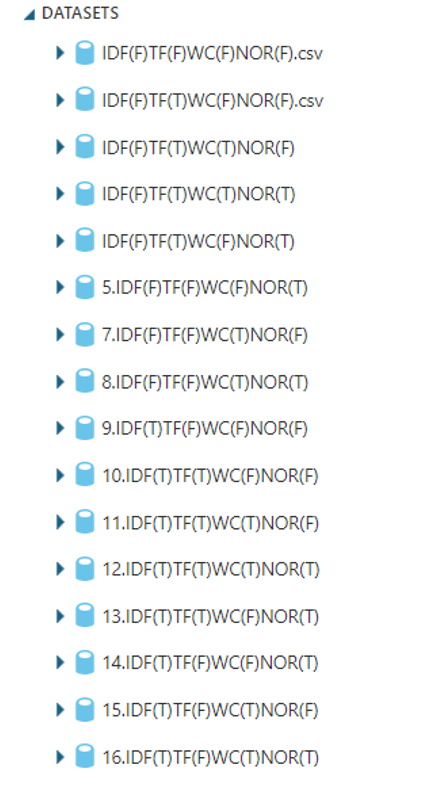
With the above combinations, sixteen files are created and these files are uploaded to the Word Vector for Different Configuration IMDB | Kaggle.
Now files are ready to use for Text Classification in Azure Machine Learning. All these sixteen files were uploaded to Azure Machine Learning for you to use.
After the sixteen datasets were uploaded, next is to perform Text Classification in Azure Machine Learning. It will be the same as the text classification that was covered before and shown in the below figure.
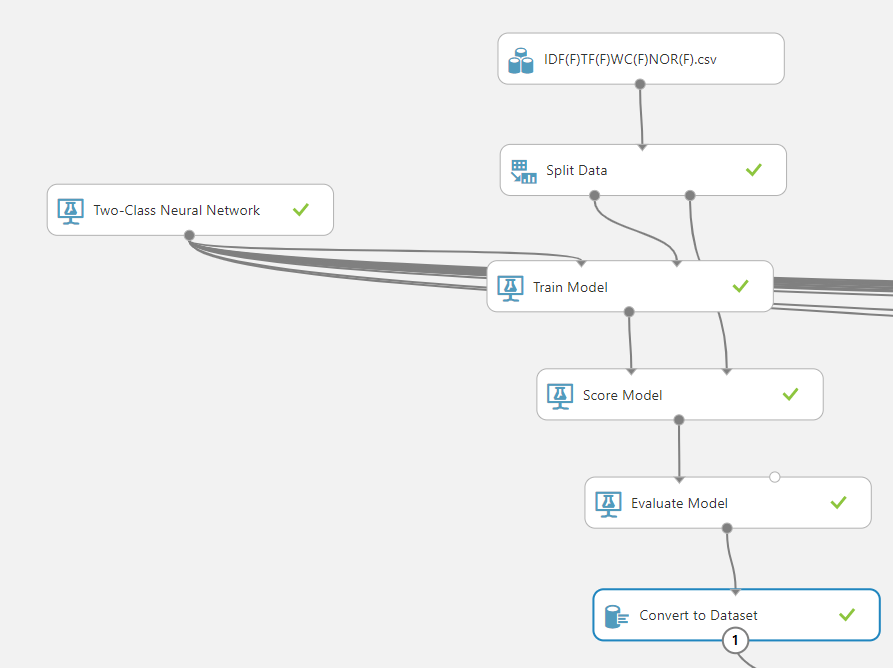
As shown in the above figure, a Two-class neural network is used for text classification in Azure Machine Learning. The Split data control is used to split data between 70/30 for training and testing where the Train Model and Score Model were used. After the Evaluate model control. Then it is connected to a Convert to Dataset control. Similar 16 units are built for each dataset and connecting the same two-class neural network algorithm.
Multiple Apply SQL Transformation controls were used to combine datasets with the following scripts:
SELECT ‘IDF(F)TF(F)WC(F)NOR(F)’ AS Type,* from t1
UNION ALL
SELECT ‘IDF(F)TF(T)WC(F)NOR(F)’ AS Type,* from t2
UNION ALL
SELECT ‘IDF(F)TF(T)WC(T)NOR(F)’ AS Type,* from t3
Though we can use Add Rows control, we have used Apply SQL Transformation controls to reduce the number of controls as there is a limit of 100 controls. Add Rows control has only two inputs while Apply SQL Transformation has three inputs. By means of UNION, it was possible to reduce the number of controls.
Finally, this is the output for all datasets and their evaluation parameters for the Text Classification in Azure Machine Learning.

From these combinations, you can choose the better combinations with the highest accuracy or precision or recall or F1-Score. As you can see IDF – True, TF – True, Word Count – False and Document Normalization – False is the better combination as it has the highest accuracy as well as the highest precision.
You can refer to the shared experiment as listed in the Reference section. Since this is a bulky experiment there are few things to point out. Since this is the free version of Azure Machine learning, not more than 100 controls cannot be used. Further, an experiment cannot contain more than 100 MB of data. Since we have 16 datasets, the size is more than 100 MB and removed some datasets from the experiment and you may add them back again from the shared dataset. Further, SQL Transformation will not work for columns more than 1024 which is another blocking concern for Text Classification in Azure Machine Learning.
As discussed in the last article, we could use Ensemble Classification for multiple configurations. Since accuracies are almost similar there is no need to perform ensemble classification.
In case we need to label unlabeled document, first, we need to transform with necessary parameters in WEKA and then input those values to the Azure Machine Learning in order to find the
Conclusion
This article discusses how to utilize Word Vector in WEKA with different text analytics parameters such as Term Frequency, Inverse Document Frequency, Document Normalization and Word count. We have used word vectors that were created from WEKA and loaded them into Azure Machine Learning. Using standard controls, it was possible to perform Text Classification in Azure Machine Learning. There are a few limitations with respect to free azure machine account such as the maximum number of controls etc.
References
- Word Vector for Different Configuration IMDB | Kaggle
- Text Classification Using WEKA Word Vector2 | Azure AI Gallery
Table of contents

View all posts by Dinesh Asanka
- Testing Type 2 Slowly Changing Dimensions in a Data Warehouse - May 30, 2022
- Incremental Data Extraction for ETL using Database Snapshots - January 10, 2022
- Use Replication to improve the ETL process in SQL Server - November 4, 2021