
This article will show Partitions in SQL Server and how they work.
Introduction
The databases keep growing, and then because of performance issues, they start dying. The users complain about performance and then some DBAs mention two main words to solve the performance problems: Partitions and indexes.
The indexes are out of the scope of this article, and our hero of the day will be the partition. What is a partition? In this article, we will talk about several places where partitions are used in SQL Server and will provide the definitions and concepts.
The partitions can be applied to Tables, views, indexes, and SSAS partitions for multidimensional databases. If you want to look at the indexes, we also have a pretty nice article for you:
What is a partition in SQL Server?
When we have a big table, sometimes it takes too much time to get the data in the queries. One of the keys to get the data faster in the query is to partition a table. Divide and rule or divide and conquer. This phrase attributed to Philip II of Macedon (the father of Alexander the Great) explains how the partition works. Imagine that you have an extremely long book, and it takes too much time to find a page. Even with indexes, the index has 100 pages. So, to solve the problem you divide the book into smaller books and then it is easier to find the information.
That is what we do in SQL Server (and other databases). We partition the table into smaller tables and that way it is easier to get the information.
What is a partition in tables?
Let’s start talking about partitioned tables, we have vertical and horizontal partitioning.
A vertical partition is commonly used when you have a BLOB column (Binary Large Object with images, audio, or other types of file). In this scenario, you want to have all the columns in one table and the BLOB column in another table. This is because the BLOB requires too many resources compared with varchars or numeric columns, so they need to be separated.
On the other hand, we have the horizontal partition which is more complex:
The horizontal partition divides the data into tables with the same column names and data types. A common scenario is a partition per month. Each table partition stored the data for a month of the year. To create a horizontal partition, you need to create data files for each partition, then add files to the database, create a function to map rows of a partitioned table into partitions that are based on values. We also need to create a partition scheme and map the partition.
If you want a detailed explanation about how to create a horizontal and a vertical table partition, we have the exact article that you need here:
If you want to go deeper on Table Partitioning, we have an article about how to automate Table Partitioning here:
What is a partition applied to SQL Server Views?
SQL Server also has the Partitioned View feature. You can create smaller tables and the view will contain a UNION ALL of every table, so the view will be like a big table compounded by multiple tables. The following code is a sample of what I mean:
|
1 2 3 4 5 6 7 8 9 10 |
CREATE VIEW DBO.LargePartitionedView WITH SCHEMABINDING AS SELECT id, name, email FROM DBO.table1 UNION ALL SELECT id, name, email FROM DBO.table2 UNION ALL SELECT [id, name, email FROM DBO.table3 |
For a more step by step explanation about partitioned views, we have a special article that can help you with that:
What is a partition applied in a T-SQL query?
There is a SQL partition by clause in SQL Server that is not related to table partitioned nor partitioned views. This clause is used for aggregations and it is an improved version of the group by clause.
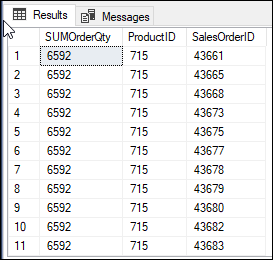
For example, if I want to see the SUM of the and we want to see the SUM of the OrderQty per ProductID and also, I want to see the SalesOrderID like this, we will have an error:
|
1 2 3 4 5 |
SELECT SUM(OrderQty),ProductID,SalesOrderID FROM Sales.SalesOrderDetai GROUP BY ProductID |
The error message is something like this:
Msg 8120, Level 16, State 1, Line 1 Column ‘Sales.SalesOrderDetail.SalesOrderID’ is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause.
When we use the GROUP BY, we need to include all the non aggregated columns into the select. On the other hand, the OVER (PARTITION BY) clause is more flexible, and you can include other columns without the need to group by.
|
1 2 3 4 5 6 |
SELECT SUM(OrderQty) OVER(PARTITION BY ProductID) AS SUMOrderQty, ProductID,SalesOrderID FROM Sales.SalesOrderDetail; |
As you can see, the OVER PARTITION BY is very powerful and allows the creation of flexible aggregation queries and solves several problems of the GROUP BY clause.
For a more detailed article about this SQL statement, we have a very interesting article here:
What is a partition in SSAS Multidimensional models?
Another type of partition in SQL Server is the partition created in SQL Server Analysis Services models. SQL Server offers a multidimensional model for business intelligence. A simplified definition of the SSAS Multidimensional model is a special and fast database for reports. The OLTP databases are not so efficient for reports and then, the multidimensional model is a different concept of database designed for Reports.
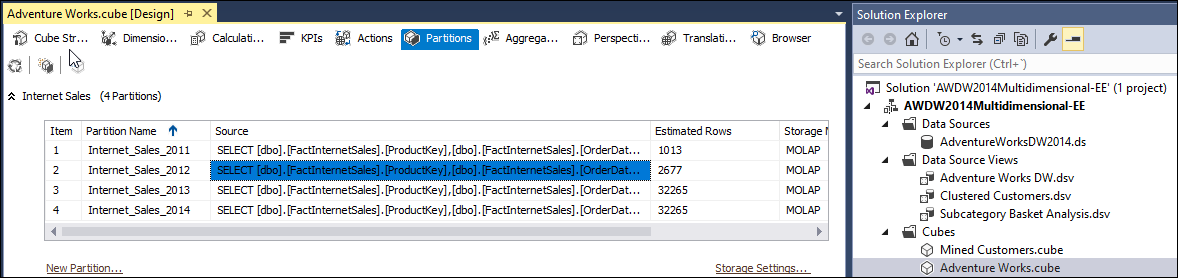
In SSAS, we have the measures that are the values that we want to measure. For example, we have a sales SSAS multidimensional database, and we want to measure the total sales and total revenue. They are the measures in SSAS. If we have too much data, we will divide the total sales into partitions per month, per week, or other criteria to divide the data into partitions.
The partitions are created in the cube in an SSAS Analysis Services project. You need to go to the Partition option.
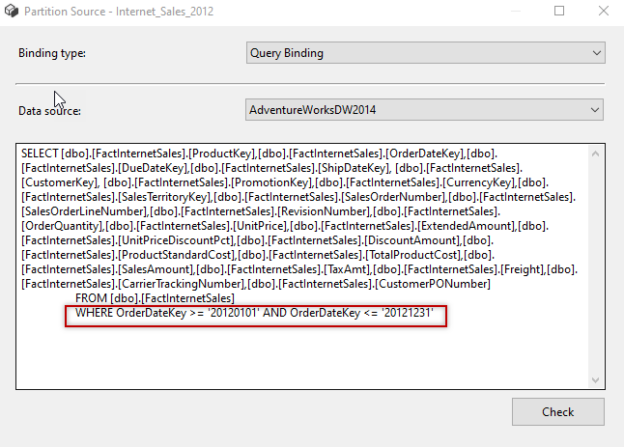
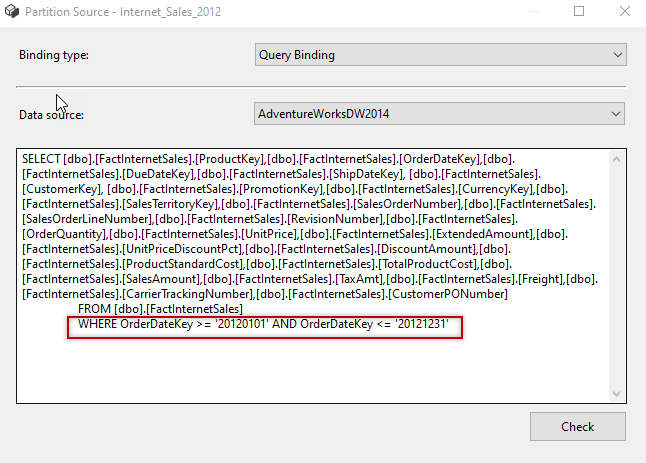
In the query, in the where clause, we usually define the date range of the partition. Usually, the partitions are separated by the date:
For a step-by-step tutorial, we created this awesome article for you:
Conclusion
In this article, we showed different questions related to the partitions in SQL Server. There are table partitions in the database engine, partitioned views, the over partition T-SQL clause and we also talked about the SSAS partitions. If none of these explanations answered your question, feel free to write your questions related to Partitions in the comments.

He has worked for the government, oil companies, web sites, magazines and universities around the world. Daniel also regularly speaks at SQL Servers conferences and blogs. He writes SQL Server training materials for certification exams.
He also helps with translating SQLShack articles to Spanish
View all posts by Daniel Calbimonte
- PostgreSQL tutorial to create a user - November 12, 2023
- PostgreSQL Tutorial for beginners - April 6, 2023
- PSQL stored procedures overview and examples - February 14, 2023