

As we’ve worked with Azure Cosmos DB, we’ve seen that we can store data within fields and the fields of each document don’t always have to match – though we still want some organization for querying. The fields and values storage becomes useful when working with object-oriented languages as these fields can be keys that we use with values that we extract as properties. For an example, the below PowerShell line creates a JSON document in an object and we can see that we can extract the values of these keys in the JSON object.
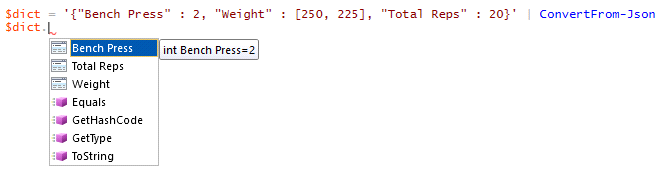
Our converted JSON object now has three properties.
Sometimes our data have hierarchies or related data to what we have stored and we must keep these data grouped in a manner that related to our existing data. We’ll look at how we can group related and hierarchy data together using arrays and subdocuments.
Creating Subdocuments and Arrays in Azure Cosmos DB
We’ve used documents in Azure Cosmos DB to store data values of fields directly in our documents. For an example, when we query our collection for Jump Rope/Pushup Circuit exercises, we see the fields of Jump Rope and Pushups. Using the same scenario of fitness, we may have multiple fields that relate to the same document that should be within a field, like a rotation of exercises that are part of a routine that are within the document. We can create a subdocument for this. A subdocument is a document within a document and this differs from the SQL relationship approach, as rather than create a situation with JOINs, we store the related data in this case in a subdocument within our document.
We can also store information within arrays in Azure Cosmos DB. Arrays group related information together identified by a field. From our PowerShell example, we that the field Weight stores data in a two-element array – 250 and 225. Let’s take this example from PowerShell and store it in its own object to see what we can do with arrays.
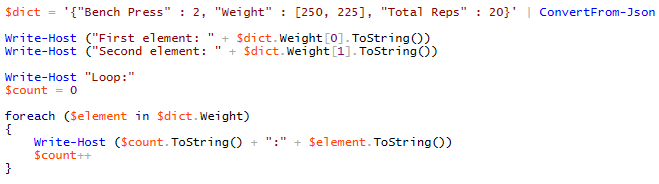
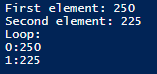
We can query the elements in the array separately or through a loop.
We see that we can get the values from an array by directly referring to them in their element position (always starts at 0). As we see in our example, our first element in our array is 250. We can also loop through each element of our array. Both of these items stored refer to Weight – 250 being the first element and 225 being the second element. Because this involves exercises in sets, we can deduce that the first exercise involved a weight of 250 and the second involved a weight of 225. Compare storing data this way to having another row of data or having a field which specifies set one and set two. Using an array here is more intuitive and as we see, easier to work with when using object-oriented languages.
The strength of NoSQL databases, like Azure Cosmos DB and MongoDB, are their ability to provide data easily to object-oriented languages on a document-level. We want to avoid querying across multiple objects to get data and instead query on the document level and get the data we need within it.
Using the example exercise routine of HST, we’ll create an array with subdocuments that list ten exercises that are a part of this routine that follow a format of the number of times the exercise was performed (sets), the weight of each set, and the total repetitions for our exercise. Notice the structure of our insert into our Azure Cosmos DB and how the subdocuments inside the array match the format of field and value. We’ll also see an array object for weights where there are two sets – for instance, we have two values for the weight for bench press of 250 and 225. Because all of these values are numbers, we avoid wrapping them in strings. Finally, after we add our result, we query the data (the first part of the query is shown).

We create a document with an array of ten subdocuments.

When we query for our added record, we see the document with the subdocuments.
Let’s look at our insert query again and think about why this organizes our data better than trying to add these all as fields. Because of this structure, we know the exercise, the sets performed, the weight of each set, and the total repetitions. We could structure our repetitions by the count of each (two-value array) or the total like we do in the document we added. Ultimately, these exercises relate to this day and this type of workout and we group them by subdocuments for organization in our Azure Cosmos DB. We could add them all as individual fields in the main document and avoid using the subdocument, but this would make the organization difficult and our queries difficult to understand, especially if we have repetitions that may differ on some days – such as a day where we do 30 repetitions for one exercise, but 20 for another exercise. When we group data in subdocuments, we want to think about how they data will be queried along with what other fields may be extracted as well. Our NoSQL database may not the final destination (or source) and when we extract these data for applications, reports, or even SQL Engines, we have to think about how we group our data for those platforms.
Before we query documents based on subdocuments, we’ll add two more documents following this format with subdocuments of exercises within our daily exercise.


Querying Subdocuments
Querying documents by using data within subdocuments in Azure Cosmos DB follows a similar pattern to querying data in documents. Like querying a field that exists in one document, but not another, our queries will return documents that have the subdocuments of the data we’re querying. One technique we can use for querying subdocuments is the dot notation since the subdocuments fields function as properties for the field object that holds the subdocument. If we look at our documents we created, we’ll see the exercise field and within that field, a list of subdocuments with fields. We can therefore use the dot notation of DocumentField.SubdocumentField and apply a filter. In our below example we apply this technique – our DocumentField is exercise and our SubdocumentField is Set. From there, we filter on “Pullups” and avoid returning all the fields except the date and time of the routine.

We return all documents in our Azure Cosmos DB with subdocuments that have “Pullups” in their set field.
We can also apply similar design logic to the output of our queries. Suppose that we want to only see the Sets and Weights and exclude everything else. We can use the dot notation on our output options to filter out the _id field (which recall returns by default unless excluded) and the Set and Weight. Since the repetitions for these three documents is the same, we’ll exclude them by not adding them to our output options.

We get back the Sets and Weights with no other parts of the document or subdocument returning.
Like we used operators with filtering for documents in Azure Cosmos DB, we can apply these operators in our subdocuments. In the below queries, we first look for documents where we used a weight greater than 400 for the type of HST (all should return). In the next query, we look for a document where used a weight less than 100 for the type of HST (none should return).

We can apply operators to subdocument field’s values.
Conclusion
As we’ve seen, we can store subdocuments in Azure Cosmos DB that are related to existing documents. In practice, one popular example is a person’s list of addresses as a subdocument within the document of the person document – this can be an entire list of addresses. In our example, we stored a type of exercise program as an array of subdocuments. While this can be useful to group related information, relative to how we plan to query our data, we’ll want to design our subdocument to align with these queries, like we want our document to as well. For instance, our example would work well if our queries will always pull the full lists of exercises when querying for HST exercise days. This highlights the most important point that we want to design our data model to fit around how our users will query the data in the least performance impacting manner as possible.
Table of contents
| Getting Started with Azure Cosmos DB |
| Updating and Querying Details in Azure Cosmos DB |
| Applying Field Operators and Objects in Azure Cosmos DB |
| Getting Started with Subdocuments in Azure Cosmos DB |

He has spent a decade working in FinTech, along with a few years in BioTech and Energy Tech.He hosts the West Texas SQL Server Users' Group, as well as teaches courses and writes articles on SQL Server, ETL, and PowerShell.
In his free time, he is a contributor to the decentralized financial industry.
View all posts by Timothy Smith
- Data Masking or Altering Behavioral Information - June 26, 2020
- Security Testing with extreme data volume ranges - June 19, 2020
- SQL Server performance tuning – RESOURCE_SEMAPHORE waits - June 16, 2020