
In this article, we will be discussing how Text Mining can be done in SQL Server. For text mining in SQL Server, we will be using Integration Services (SSIS) and SQL Server Analysis Services (SSAS). This is the last article of the Data Mining series during which we discussed Naïve Bayes, Decision Trees, Time Series, Association Rules, Clustering, Linear Regression, Neural Network, Sequence Clustering. Additionally, we discussed the way to measure the accuracy of the data mining models. In the last article, we discussed how models can be extracted from the Data query.
Why Text Mining is challenging
During the previous discussions, we mainly discussed data mining modeling in structured relation data. However, since there is no structure to text data, there are a lot of challenges when it comes to modeling the text data. Apart from text data is unstructured, text data will have a large volume of data. Due to the different styles of writing, it may be difficult to analyze data.
In this article, we are looking at how to overcome those challenges when performing Text Mining in SQL Server.
Data Set
Unlike the previous articles where we predominantly used AdventureworksDW as our sample database, in this article, we will be using more real-world scenarios. We will be using movie reviews data set at https://www.kaggle.com/nltkdata/movie-review. In this dataset, there are 1,000 each positively and negatively rated movies. Positively rated movies are in a folder named pos whereas negatively rated movies are in a folder called neg. Every review is in a text file as shown in the below screenshot.
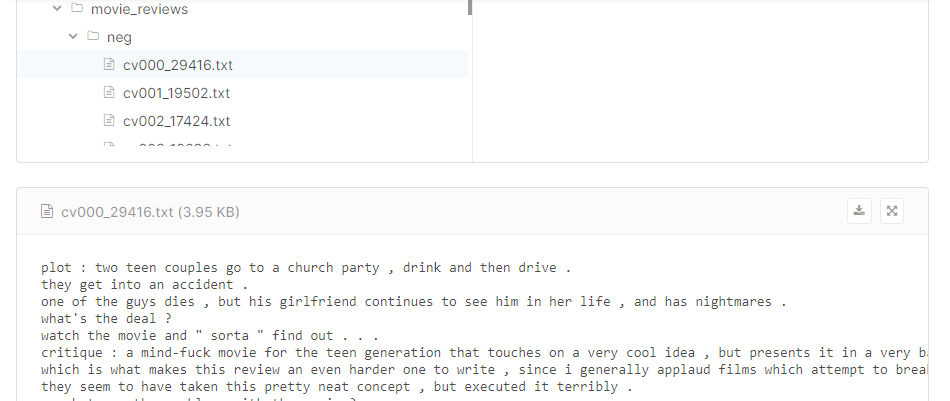
Every review is saved in a text file and that means that there is a total of 2,000 files, 1,000 for positive reviews and 1000 for negative reviews.
Our first task is to extract these film reviews from the following table named Cinema.
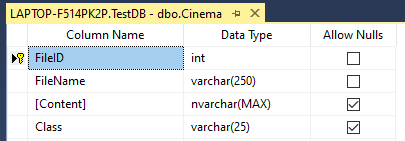
In the above table, FileID is configured for the auto-increment column and FileName is used to save the actual file name. The content column will be used to store the content of the review whereas the review category, negative or positive is stored in the Class column.
To extract all the 2,000 files to the Cinema table, the following SSIS is used.

Execute SQL Task is used to truncate the Cinema table to facilitate multiple executions. For each loop container is used to traverse through the folder and get the file name. Following is the data flow task to write one file content to the table.
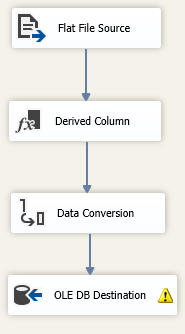
In this derived column is used to get the review class, positive or negative. Since files full path is D:\FilmReviews\review_polarity\txt_sentoken\neg\cv000_29416.txt in format, the last folder name is derived using following SSIS code to get the class.
REVERSE(SUBSTRING(REVERSE(@[User::FN]),FINDSTRING(REVERSE(@[User::FN]),”\\”,1) + 1,3))
@[User::FN] is the variable for the Filename.
The following screenshot shows the sample data set for the cinema table after data is extracted to it from the text files.
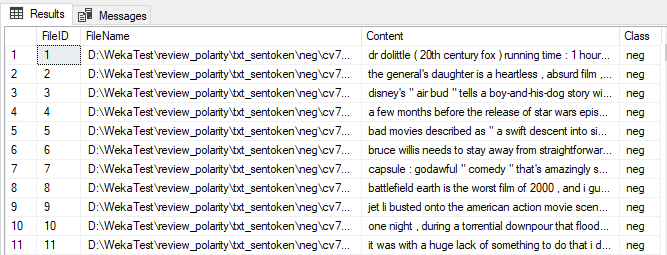
Term Extraction
The next operation is Term Extraction for which we will be using Term Extraction transformation control in SSIS. In this control, there are three important configurations, Term Extraction Exclusion and Advanced. Detailed discussion on this can be found at Term Extraction Transformation in SSIS article.
For the Term Extraction, we will be using the Cinema table as the source of data as presented in the below screenshot.
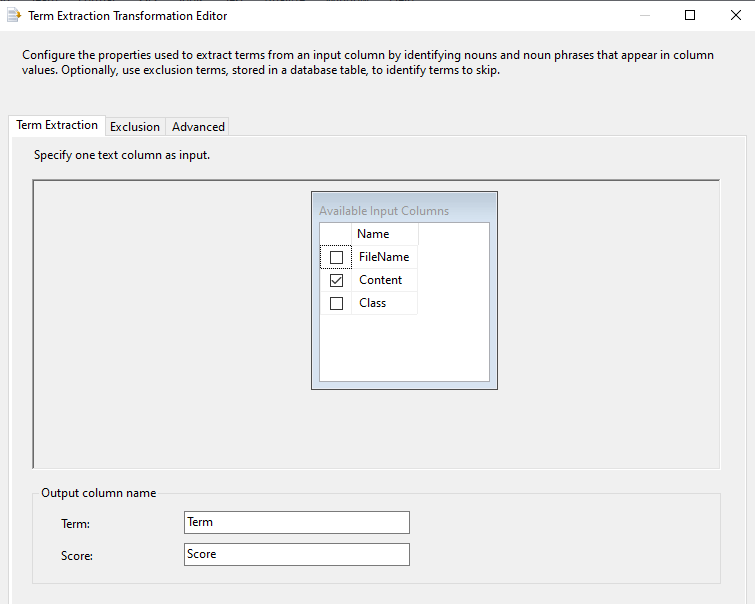
Next is configuring the exclusion list. Words like, the, a, and, will not make any value. Therefore, those words should be eliminated for better results and better performance.
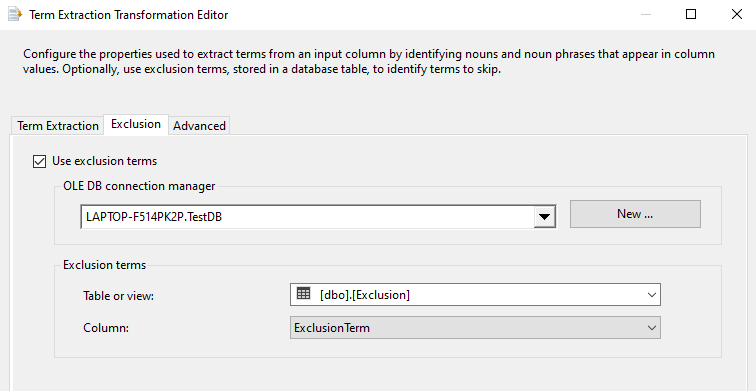
The exclusion table contains an only column that is ExclusionTerm. Next is to configure Advanced options as shown below.
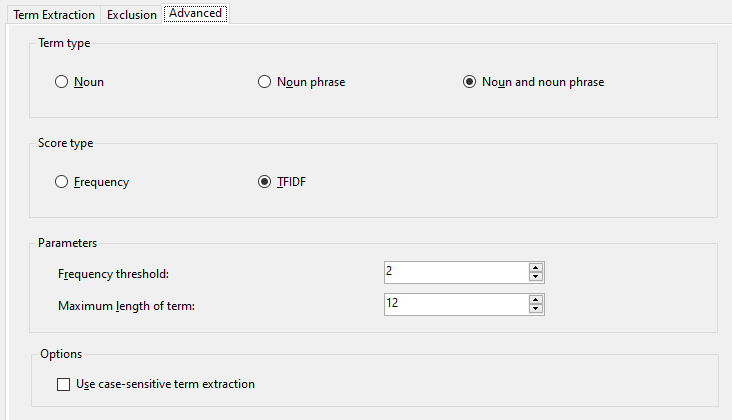
We have used TFIDF, Term Frequency Inverse Document Frequency for the score type. TFIDF of a selected term t = (frequency of t) * log ( (number of rows in Input) / (number of rows having t) ) .
Following is the output of the above transformation stored in a table named, TermScore.

From the above data set, we can identify what are the most important terms as the high value of a score means it has higher importance.
Term Lookup
After finding the terms of the entire data set, next is to find out how each document has each term. For that, we will be utilizing the Term Lookup transformation in SSIS.
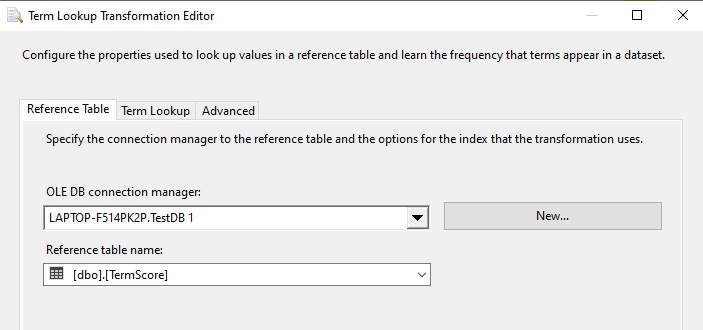
TermScore is used as a reference table as presented in the above screenshot.
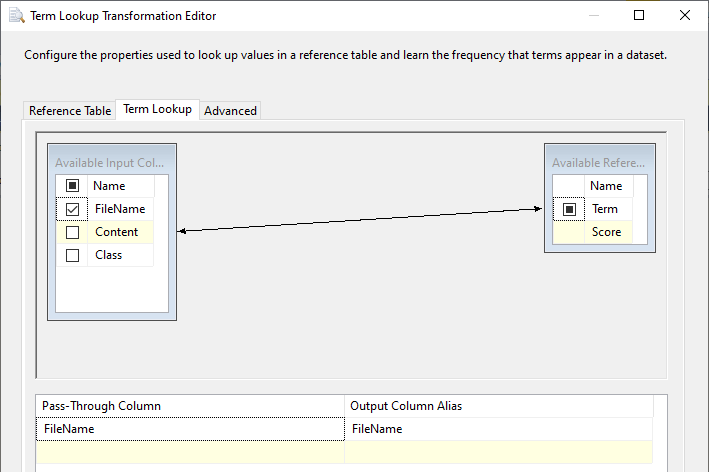
Then we will be doing a term lookup against the initial cinema dataset. This will give you the number of occurrences for terms against each document that will be saved in the DocumentTerms tables as shown in the below screenshot.
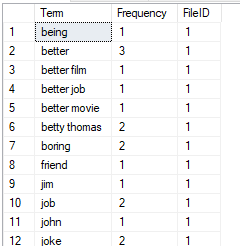
Term Document Incident Matrix
Term Document Incident Matrix is a basic matrix that is used for modeling in Text Mining. Text Mining in SQL Server does not provide off the shelf option to create a term document incident matrix.
The following screenshot shows the Term Document Incident Matrix for each file.
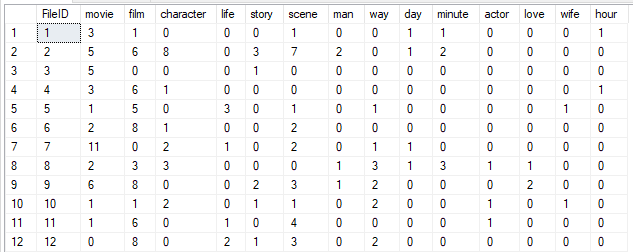
For example, FileID 1 has 3 terms of movie and 1 term for film and the FileID 2 has 5 terms of movie and 8 terms of character.
The above matrix is created from the following stored procedure.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
CREATE PROCEDURE [dbo].[usp_TermDocumentIncidenceMatrix] AS BEGIN SET NOCOUNT ON IF EXISTS ( SELECT 1 FROM sys.tables WHERE NAME = 'TermDocumentIncidenceMatrix' ) DROP TABLE TermDocumentIncidenceMatrix DECLARE @Statment AS VARCHAR(8000) SET @Statment = ' ' SELECT TOP 250 @Statment = @Statment + ' [' + [Term] + '] float,' FROM [TestDB].[dbo].[TermScore] ORDER BY score DESC SET @Statment = 'CREATE TABLE TermDocumentIncidenceMatrix (FileID INT PRIMARY KEY,' + @Statment SET @Statment = SUBSTRING(@Statment, 1, LEn(@Statment) - 1) + ')' EXECUTE (@Statment) SET @Statment = 'INSERT INTO dbo.TermDocumentIncidenceMatrix SELECT [FileID]' + REPLICATE(',0', 250) + ' FROM [dbo].[Cinema]' EXECUTE (@Statment) DECLARE @Term VARCHAR(4000) DECLARE @stat VARCHAR(4000) SELECT TOP 250 [Term] ,0 STATUS INTO #Terms FROM [TestDB].[dbo].[TermScore] ORDER BY score DESC WHILE ( SELECT COUNT(1) FROM #Terms WHERE STATUS = 0 ) > 0 BEGIN SELECT TOP 1 @Term = [Term] FROM #Terms WHERE STATUS = 0 SELECT @stat = 'UPDATE TDIM SET [' + @Term + ']= Dt.Frequency FROM TermDocumentIncidenceMatrix TDIM INNER JOIN [dbo].[DocumentTerms] DT ON TDIM.FileID = DT.FileID WHERE Dt.[Term] = ''' + @Term + '''' EXECUTE (@stat) UPDATE #Terms SET STATUS = 1 WHERE [Term] = @Term END END GO |
For the above procedure, 250 terms of highest scores are used for the Term Document Incident Matrix. Now we have prepared the relevant data set and ready to create the data models for Text Mining in SQL Server.
Association Mining Model
Let us look at what are the common terms that are used. For this, we will be using the Association Mining rule. The following Data source view is used for the association rule mining.
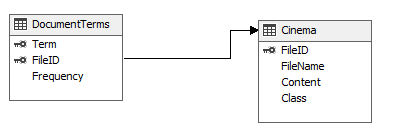
Since there is an already foreign key defined between Cinema and DocumentTerms table, there is no need to define the relationship in SSAS modeling.
In this data set, Cinema is selected as the case table whereas the documentterms table is selected as the nested table.
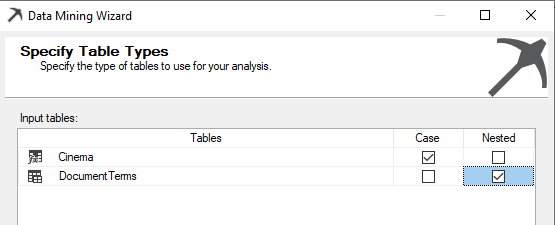
The following are the configuration of Key, Input and Prediction columns.
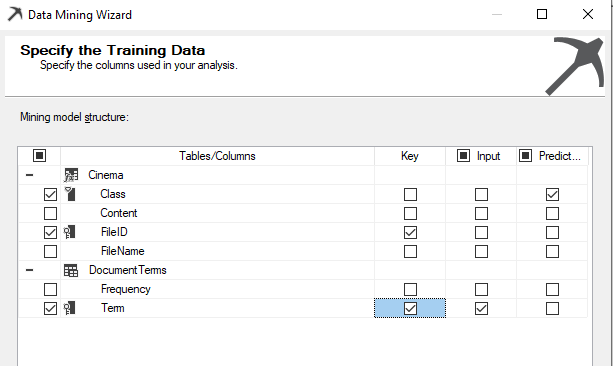
Let us look at the associate rule outcomes after processing the data mining model.
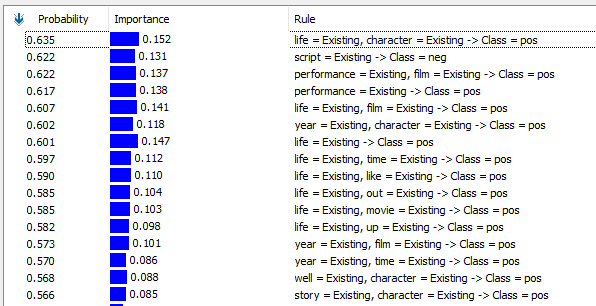
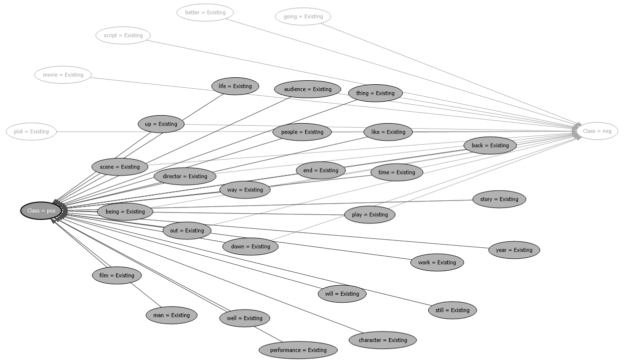
The above screenshot shows that when the text life and character exist the class is positive with a probability of 63.5%.
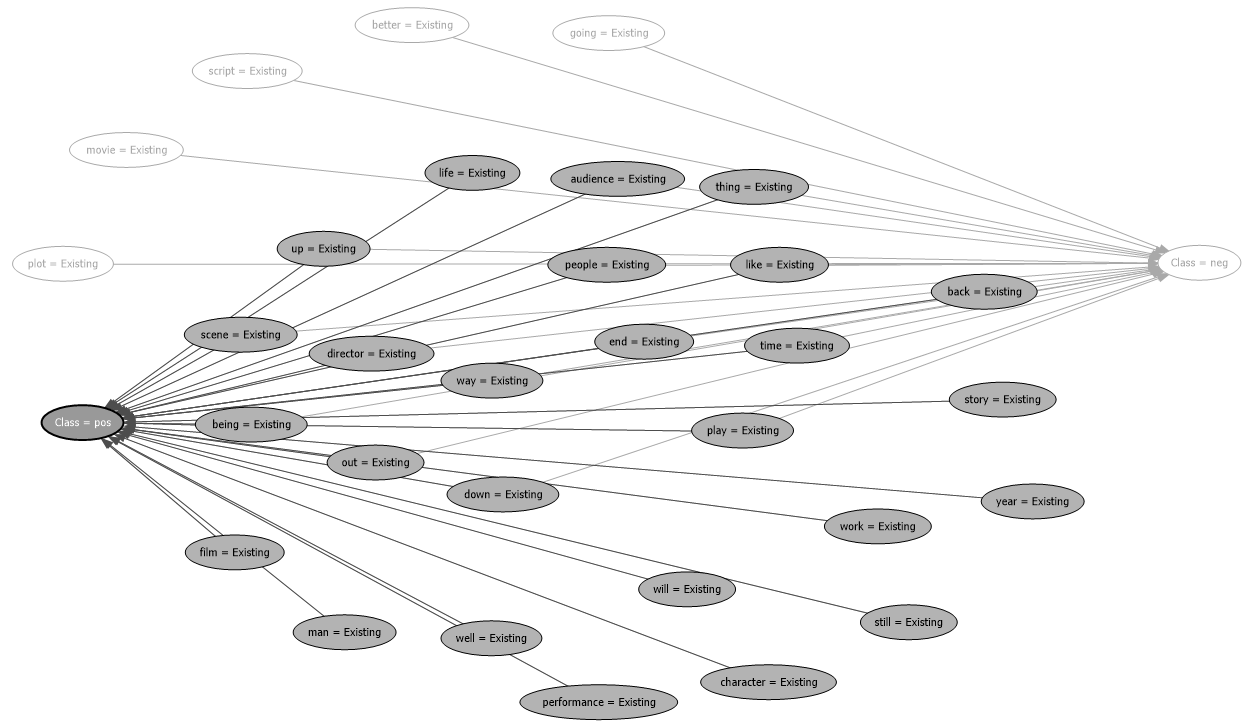
The above diagram shows the relationship diagram for the positive class.
Classification Mining Model
For the Classification model, we will look at the TermDocumentIncidenceMatrix table. In this modeling, classification variable is class, pos or neg. Since it is in the Cinema table we need to create a view. For this classification model, we will be using a view that is combined with two tables TermDocumentIncidenceMatrix and Cinema as shown in the below script.
|
1 2 3 4 5 6 7 |
CREATE VIEW [dbo].[vw_Cinema] AS SELECT dbo.TermDocumentIncidenceMatrix.*, dbo.Cinema.Class FROM dbo.Cinema INNER JOIN dbo.TermDocumentIncidenceMatrix ON dbo.Cinema.FileID = dbo.TermDocumentIncidenceMatrix.FileID GO |
This view is added to data source view.

Like we did in the accuracy measurement, we will create four models for classification, Decision Trees, Naive Bayes, Neural Network and Logistics Regression as shown below. In all these models, the classification or prediction column is the class.
Please note that all the terms will have continuous data type and better if we can convert them to a discrete data type.
Let us look at few classification models and the following is the model for decision trees.
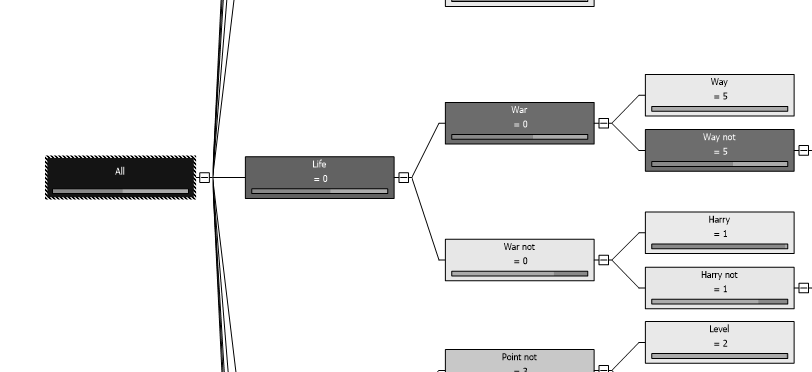
Let us look at the accuracies of these models from the confusion matrix as presented below.
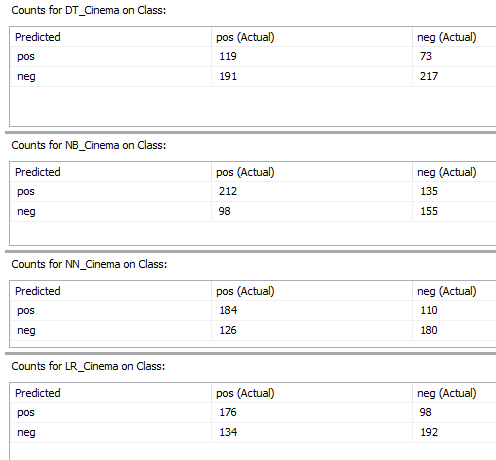
Let us calculate the accuracy of each model.
|
Algorithm |
Accuracy |
|
Decision Trees |
56.00 % |
|
Naïve Base |
57.83 % |
|
Neural Network |
60.67 % |
|
Logistic Regression |
61.33 % |
For this data set, Logistic Regression is a better algorithm.
Conclusion
In this last article of the series, we discussed Text Mining in SQL Server. We have used SSIS and SSAS tools in the Microsoft BI family. SSIS is used to Extract terms and perform term lookups. From SSAS, we have used Association and classification techniques to perform text mining.
Table of contents

View all posts by Dinesh Asanka
- Testing Type 2 Slowly Changing Dimensions in a Data Warehouse - May 30, 2022
- Incremental Data Extraction for ETL using Database Snapshots - January 10, 2022
- Use Replication to improve the ETL process in SQL Server - November 4, 2021