
In this article, we will be discussing how SQL Server Integration Services (SSIS) can be used to predict data mining models built from SSAS. In this article, we will be looking at the Data Mining Query in SSIS. During the data mining article series, we have discussed all the Data mining techniques that are available in SQL Server. The discussed techniques were Naïve Bayes, Decision Trees, Time Series, Association Rules, Clustering, Linear Regression, Neural Network, Sequence Clustering. Further, we discussed how the accuracy of the data mining models can be verified.
When Data Mining models are built and deployed to SQL Server Analysis Services (SSAS), a few maintenance and usage tasks can be used from SSIS. Since SSIS is a tool that can be used to integrate data from heterogeneous sources, SSIS can be used to execute some tasks in Data Mining.
Data Mining Query
Though we create data mining models from SSAS, modelled data can be used for different activities. One of the obvious tasks with data mining modeling is prediction. There is a Data flow task in SSIS that can be used to query the data mining models.
Let us look at a scenario to use the Data Mining Query. Let us see how we can predict who the possible bike buyers are using a built model.
For the last article, we developed a mining structure that has four data mining models, Decision Trees, Logistic Regression, Naïve Bayes, and Neural Network. We will be using that data mining model. Let us assume that we have a dataset, that can be used to predict whether the bike buyer or not.
In the AdventureWorksDW database, there is a table named [ProspectiveBuyer] that contains prospect buyers. Now our task is to predict the possible bike buyers using any data mining models.
SSIS Project Creation
First, let us create an SSIS project using SQL Server Data Tools. Then for the default package let us drag and drop a Data Flow Task. Your SSIS package should look like the following screenshot.
Now, let us create the data flow task by double-clicking the Data Flow Task in the SSIS package.
First, you need to include the data source which is the ProspectBuyer table. The following query can be used.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
SELECT CONCAT ( [Salutation],' ',[FirstName],' ',[MiddleName] ,' ',[LastName] ) FullName ,CONCAT ([AddressLine1],' ‘,[AddressLine2],' ',[City] ,' ' ,[StateProvinceCode],' ',[PostalCode] ) Address ,[Phone] ,[EmailAddress] ,[MaritalStatus] ,[Gender] ,[YearlyIncome] ,[TotalChildren] ,[NumberChildrenAtHome] ,[Education] ,[Occupation] ,[HouseOwnerFlag] ,[NumberCarsOwned] FROM [AdventureWorksDW2017].[dbo].[ProspectiveBuyer] |
We used CONCAT command for columns Full Name and Address as they are divided into multiple attributes. The following is the sample dataset for the above query.
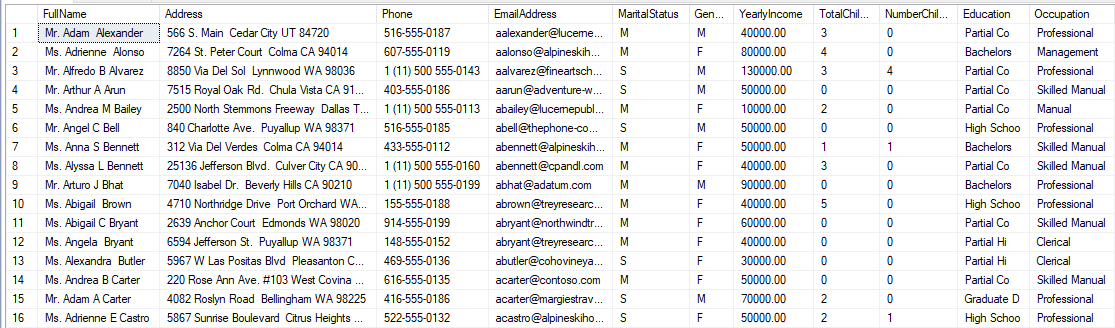
In the above data set, Full Name, Address, Phone and Email Address will be used as contact attributes so that the marketing team can contact them once they identify someone as a possible bike buyer. Rest of the attributes, [MaritalStatus], [Gender], [YearlyIncome], [TotalChildren], [NumberChildrenAtHome], [Education], [Occupation], [HouseOwnerFlag], [NumberCarsOwned] are used to determine whether the prospect customer is a bike buyer or not.
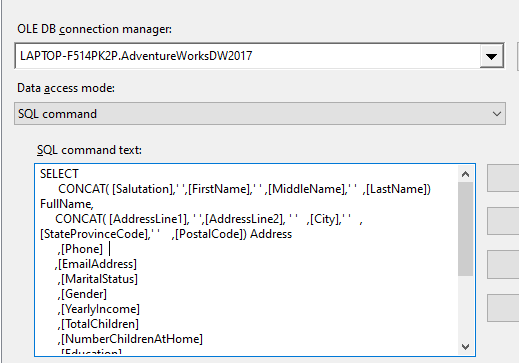
Let us Drag and Drop an OLEDB Source from the Data Flow list to the data flow task, configure the source with the above query. The OLEDB Source configuration will look like the following screenshot.
After data source, the next is to configure the Data Mining Query. Let us drag and drop the Data Mining Query data flow task from the SSIS toolbox and the package will be shown as the below screenshot.
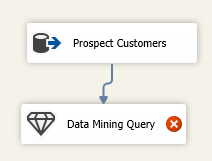
Configure the Data Mining Query in SSIS
In this, we need to configure the connection to the SSAS server in which the Data Mining Model is deployed.
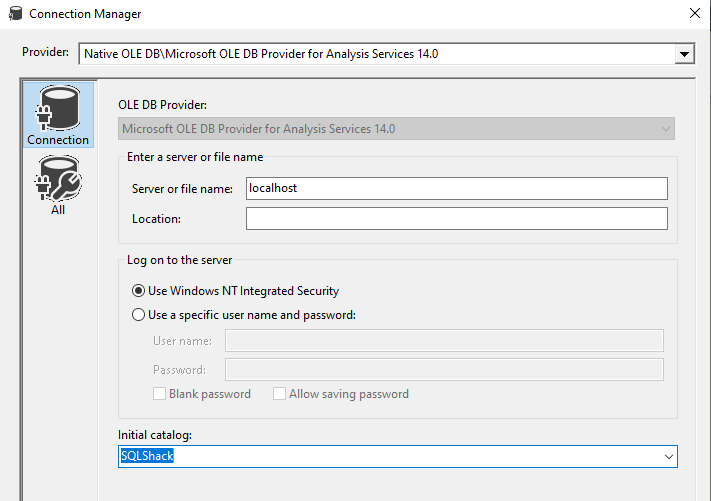
In the above configuration, the SSAS server and the catalog is configured. SQLShack is the SSAS catalog that was used to deploy the Data Mining structures.
After the SSAS connection is completed, next is to select the relevant Data Mining Structure and data mining model as shown in the following screenshot.
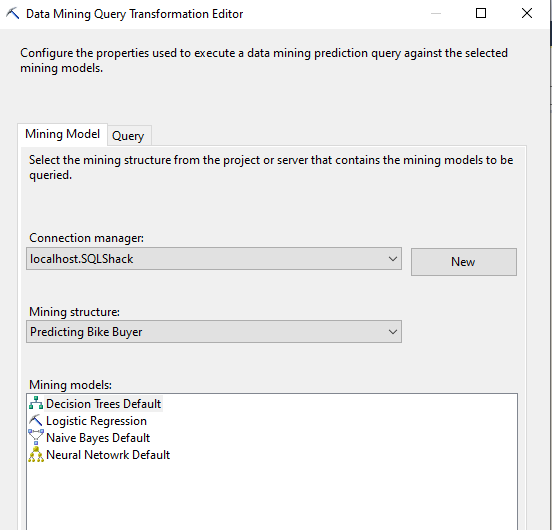
In the last article, we understood that the Decision Trees data mining algorithm has the highest accuracy for the bike buyer date set. Let us select the Decision Trees from the Mining Models. However, you have the option of using any data mining model.
After the data mining model is selected, the next is to write the prediction query for Data Mining Query in SSIS. By clicking the Build New Query will take you to the Data Mining Query design screen as shown in the following screenshot.
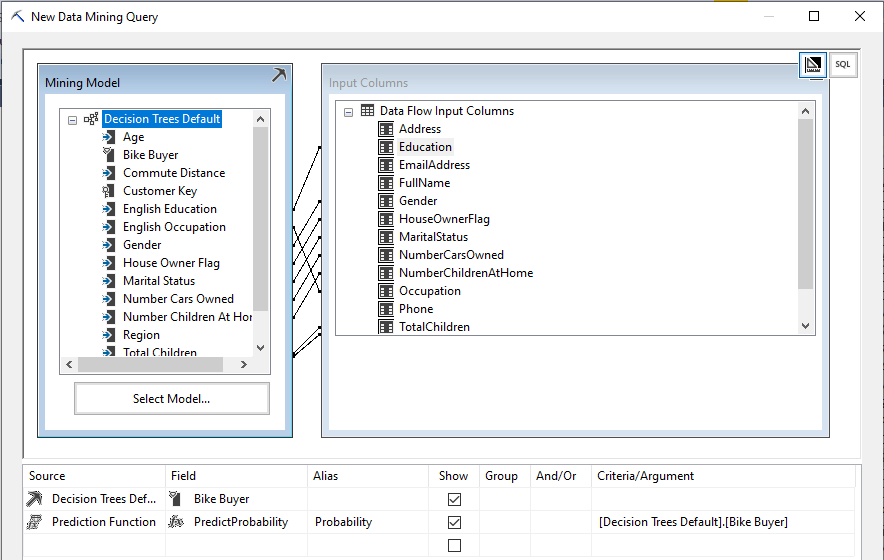
In the above screen, Input attributes are mapped to the model parameters. By default, the same name attributes will be matched automatically. From this model, we are expecting two things. Those two are whether the prospective customer is a bike buyer and what the probability of him buying a bike is. Those two parameters are defined at the bottom of the screenshot.
When the above query is defined, the DMX query will be updated in the following screen as shown below.
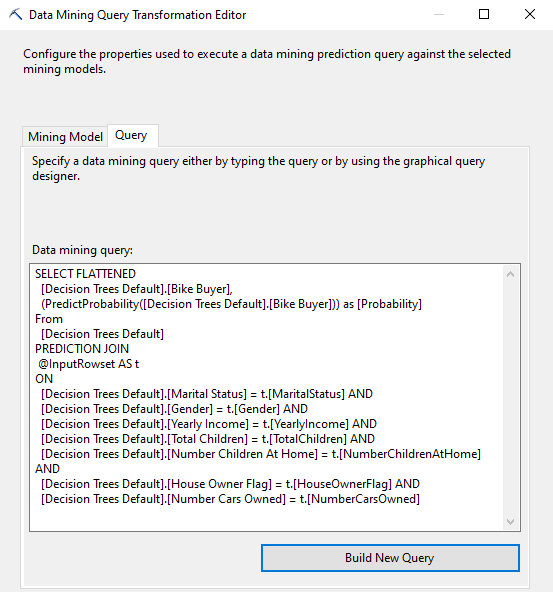
Following is the DMX query for the prediction of the above data mining model that will be used in Data Mining Query in SSIS.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
SELECT FLATTENED [Decision Trees Default].[Bike Buyer], (PredictProbability([Decision Trees Default].[Bike Buyer])) as [Probability] From [Decision Trees Default] PREDICTION JOIN @InputRowset AS t ON [Decision Trees Default].[Marital Status] = t.[MaritalStatus] AND [Decision Trees Default].[Gender] = t.[Gender] AND [Decision Trees Default].[Yearly Income] = t.[YearlyIncome] AND [Decision Trees Default].[Total Children] = t.[TotalChildren] AND [Decision Trees Default].[Number Children At Home] = t.[NumberChildrenAtHome] AND [Decision Trees Default].[House Owner Flag] = t.[HouseOwnerFlag] AND [Decision Trees Default].[Number Cars Owned] = t.[NumberCarsOwned] AND [Decision Trees Default].[English Occupation] = t.[Occupation] AND [Decision Trees Default].[English Education] = t.[Education] |
After the Data Mining Query is configured, the following data flow task can be seen. In the below data flow task, Row Count is configured to view the results.
Let us view the results by enabling the Data Viewer as shown in the above screenshot. The following screenshot shows the data viewer results as shown in the below screenshot.
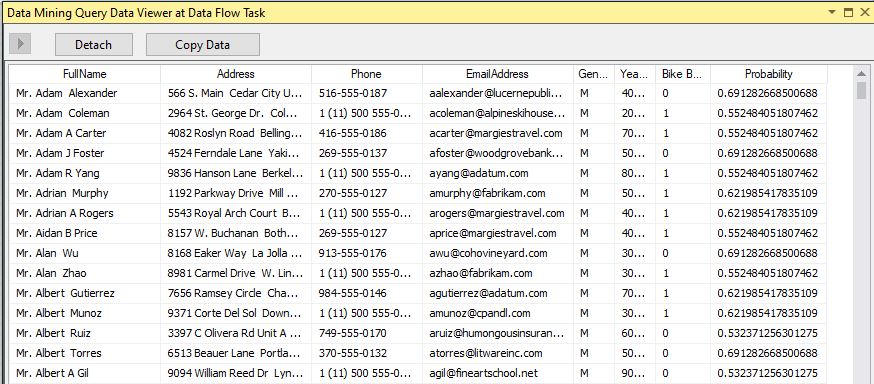
The Bike Buyer column indicates whether the relevant customer is a bike buyer or not with the relevant Probability.
Though this is the basic configuration of Data Mining Query in SSIS, there are a few features of SSIS that can be used to get the best out from the data mining models.
Extended SSIS features for Data Mining
Data Mining Query in SSIS can be extended to different features of SSIS. If you are a marketing person at the above organization, you would prefer to get a list of Bike buyers who have the highest probability of buying bikes and less probability of buying a bike so that you can target these to customer segments separately. Further, you would prefer to have the prospects in the order of highest probability.
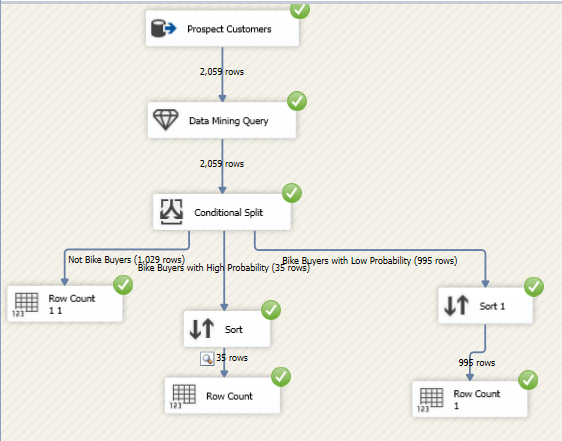
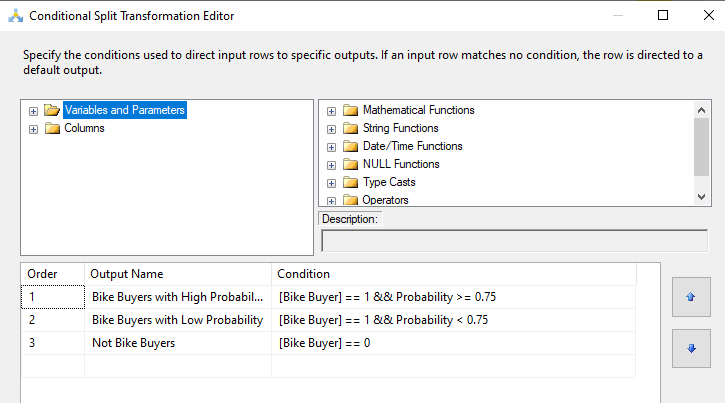
Conditional Split in SSIS is used to split the data flow into multiple depending on the conditions. Let us split the entire data set, Bike buyers with more than 75% probability and Bike Buyers with less probability and not bike buyers. This can be configured by Conditional split control in SSIS as shown in the following screen.
Next, we will sort the data stream with the highest probability using the Sort transformation.
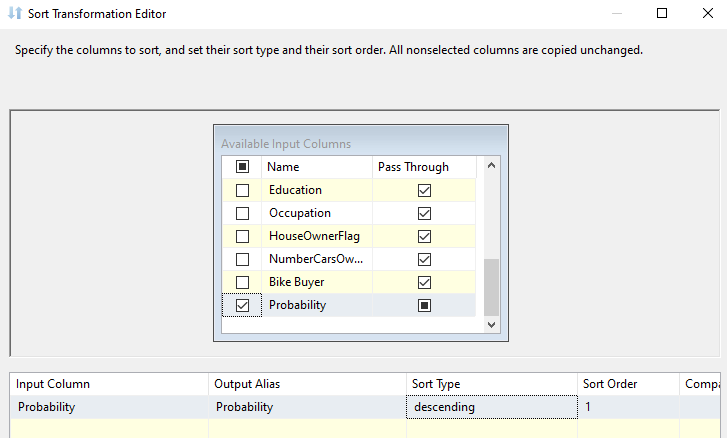
The following screenshot shows the final SSIS package for Data Mining Query.
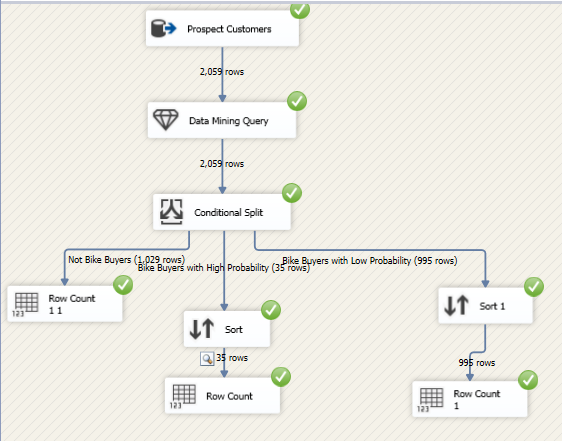
You will see that there are 35 records of customers who are more likely to buy a bike with the probability of 75% and there 995 possible bike buyers with less probability. 1028 customers are unlikely to buy bikes from this organization.
Following is the list of customers who are more likely to buy bikes.
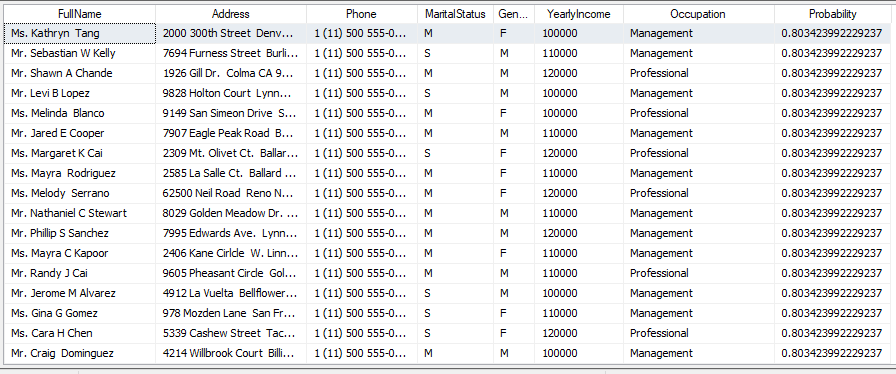
The above list provides the contact details of the prospect customers.
Since Data Mining Query in SSIS can be used to query the data mining models, it can incorporate other options like storing data into a database table, saving to a text file, sending emails and so on.
Conclusion
In this article, we looked at the Data Mining Query in SSIS to perform predictions with data mining models in SQL Server. Since SSIS has rich transformation controls, data splitting, data filtering, sorting can be performed. Apart from those operations, writing to the database, sending emails too can be done via SSIS.
Table of contents

View all posts by Dinesh Asanka
- Testing Type 2 Slowly Changing Dimensions in a Data Warehouse - May 30, 2022
- Incremental Data Extraction for ETL using Database Snapshots - January 10, 2022
- Use Replication to improve the ETL process in SQL Server - November 4, 2021