

In this 29th article of the SQL Server Always On Availability Groups series, we configure the AG between SQL Server Linux instances.
Introduction
SQL Server 2017 & 2019 works on the cross-platform operating system: Windows and Linux. You can use SQL Server on Red Hat Enterprise Linux (RHEL), SUSE Linux Enterprise Server, and Ubuntu. You can install it on-premise or cloud solutions such as Azure, AWS.

As we can use SQL on both platforms, it is essential to understand the high-availability and disaster recovery mechanism on the Linux SQL as well. In the previous articles (see ToC at the bottom), we explored various aspects of SQL Server Always On Availability Groups for Windows-based servers. In this article, we will configure the availability groups between two Linux VM’s.
Environment details
In this article, we create an availability group between two Linux instances. For this purpose, we require two virtual machines in the Oracle VM VirtualBox. You can follow my earlier article SQL Server 2019 on Linux with Ubuntu, and prepare the virtual machines with Ubuntu OS.
I use the following virtual machines in this article:
- linuxnode2: 10.0.2.51 – Initially, it acts as the primary replica
- linuxnode3: 10.0.2.50 – Initially, it acts as the Secondary replica
- Domain Controller and DNS: VDITest3 (10.0.2.15)
- SSMS client on Windows VM: SQLNode3 (10.0.2.44)
Configure the SQL Server Linux VM’s for static IPs
By default, once you create a virtual machine, it gets a dynamic IP address. The dynamic IP address might change when you reboot the OS. We need to assign the static IP address using the network configuration of Ubuntu.
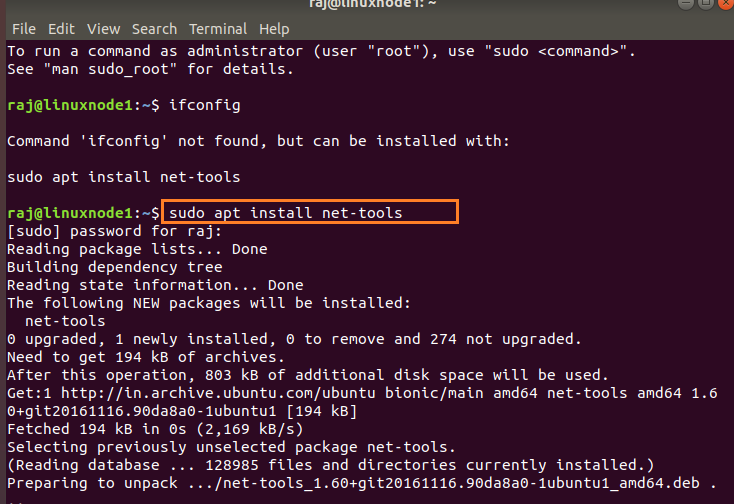
Connect to the virtual machine linuxnode3, launch terminal and install the ifconfig utility like below. We use the ifconfig command to check the network interfaces and associated IP addresses.
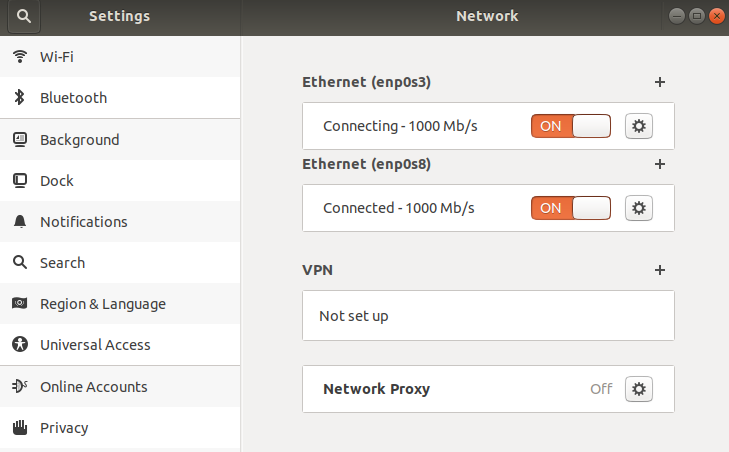
Now, open the network settings, and it shows you two network interfaces. I use one interface for internet connectivity and the other for the static IP configuration.
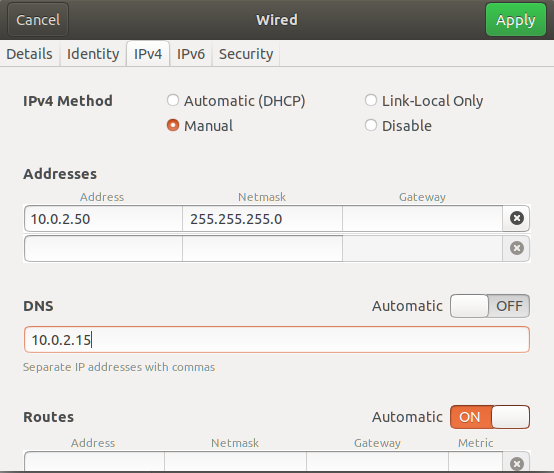
Open the enp0s3 interface and assign a static IP, subnet mask, and DNS, as shown below.
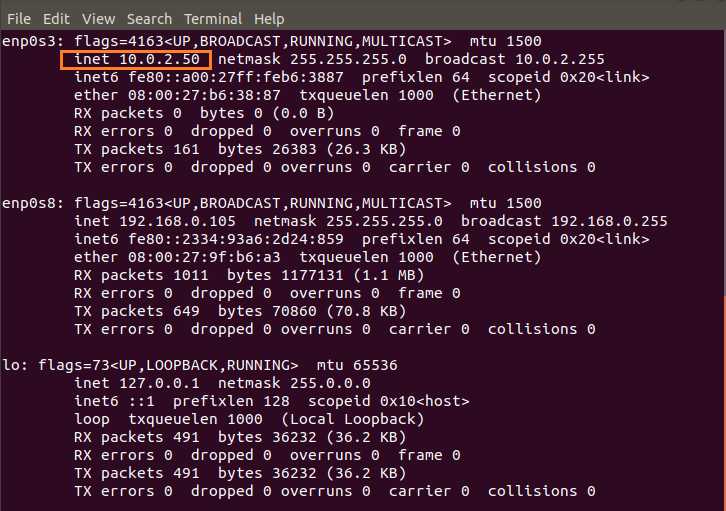
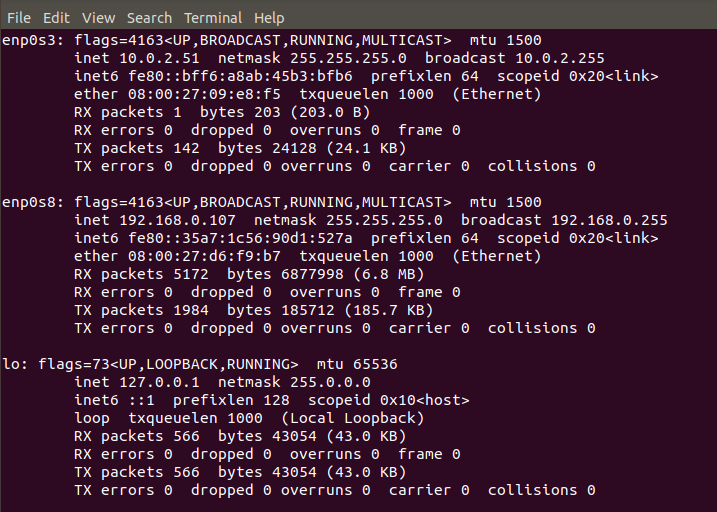
Apply the configuration and verify the IP address using the ifconfig command. It shows the IP address in the inet section.
Verify the hostname for your virtual machine using the sudo cat /etc/hostname command. If required, you can open a vi editor and modify the hostname as per your requirement.

Similarly, configure the linuxnode2 virtual machine for the static IP address and verify its hostname.

Host file entry in the virtual servers
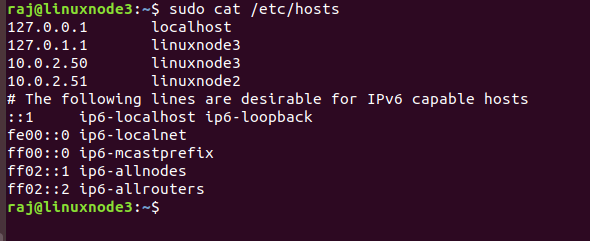
In this article, we do not have servers as a member of the domain. To resolve the IP address with the server name, we can either add an entry in the DNS or update the host file.
To update the host file, run the following command:
|
1 |
$ sudo nano /etc/hosts |
In this, add the IP address and hostname of both virtual machines, as shown below.
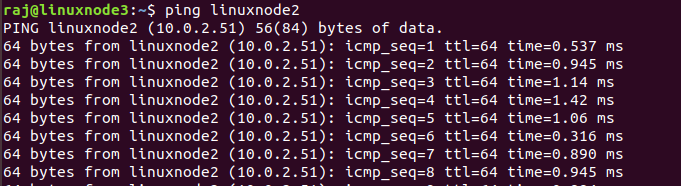
Now, you should test ping to another node with the hostname, and it returns the IP address.
Ping response from linuxnode3 to linuxnode2:
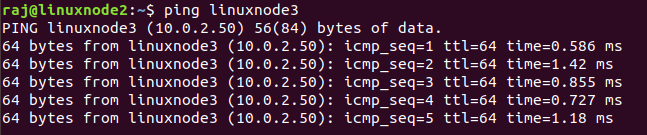
Ping response from linuxnode2 to linuxnode3:
Install SQL Server on SQL Server Linux server(linuxnode3)
We install the SQL Server 2019 on both the virtual machines. To install SQL Server 2019, launch the terminal and use the following steps.
Import the public repository GPG keys:
In this step, import the GPG public keys from the Microsoft URL. It should return status OK as a successful script execution.
|
1 |
$ wget -qO- https://packages.microsoft.com/keys/microsoft.asc | sudo apt-key add - |
Register the SQL Server 2019 Ubuntu repository
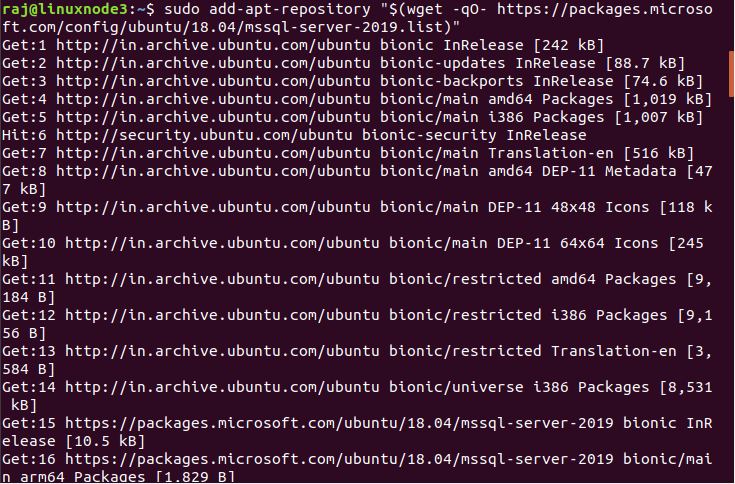
In this step, we use the add-apt-repository command to register the latest SQL Server 2019 Ubuntu repository available at the specified package URL.
|
1 |
$ sudo add-apt-repository "$(wget -qO- https://packages.microsoft.com/config/ubuntu/18.04/mssql-server-2019.list)" |
You can browse the URL and check the SQL Server repository.
Update the package lists
Run the apt-get command to update the package list and repositories.
|
1 |
$ sudo apt-get update |
Install SQL Server on Ubuntu
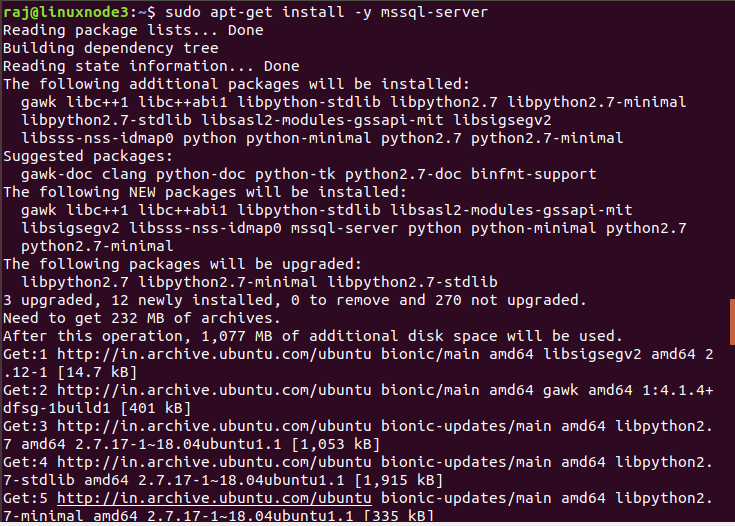
The below command downloads the SQL Server installations and installs the SQL Server without configuring it.
|
1 |
sudo apt-get install -y mssql-server |
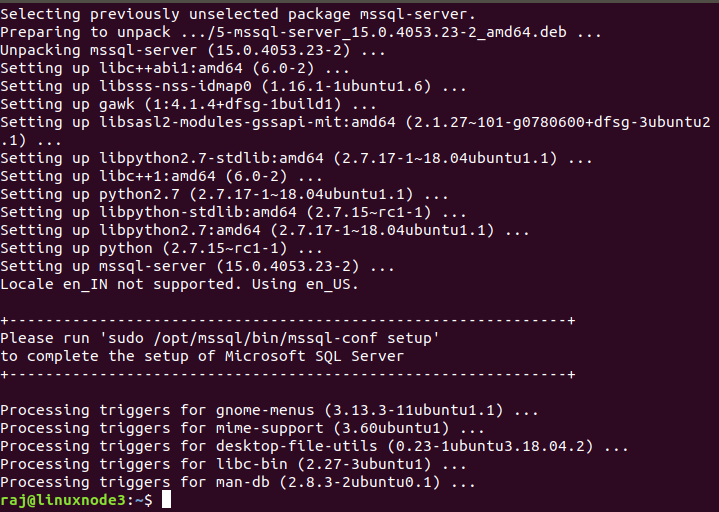
To configure the SQL Server, it shows the command in the output for configuring the edition, language, SA password.
Once you run the command, it asks for several inputs.
|
1 |
$ sudo /opt/mssql/bin/mssql-conf setup |
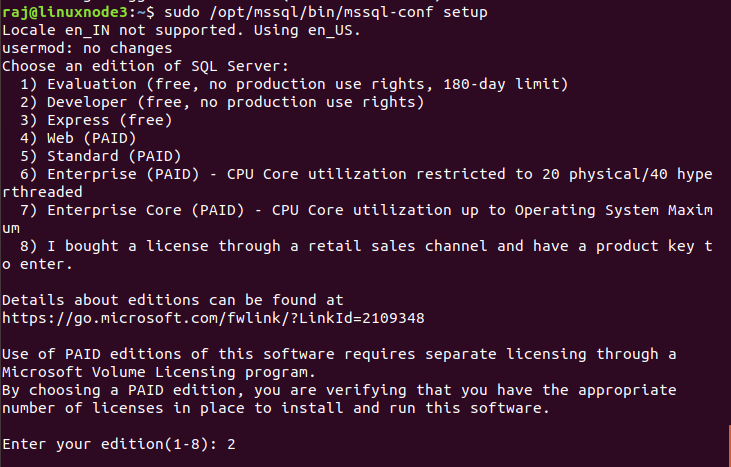
Edition of SQL Server: You need to enter the serial number for the SQL Server version. For the developer instance, specify the code 2

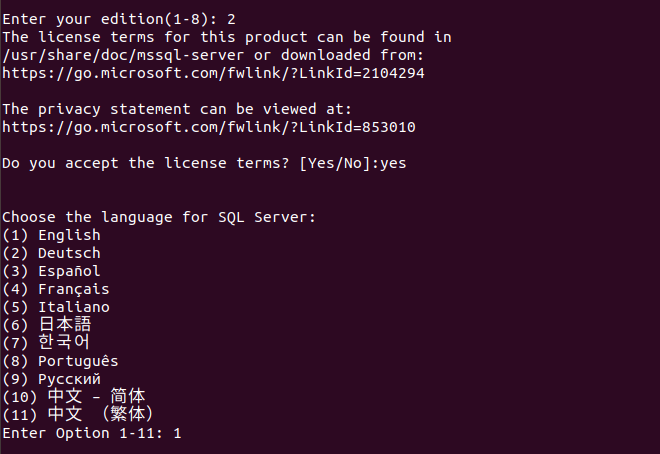
- Accept the license terms and conditions
-
Specify the language for your SQL Server installation
-
Enter the password for the SA login in SQL Server
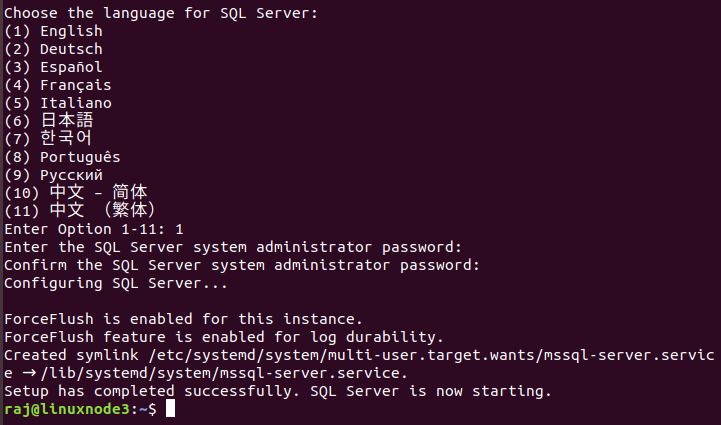
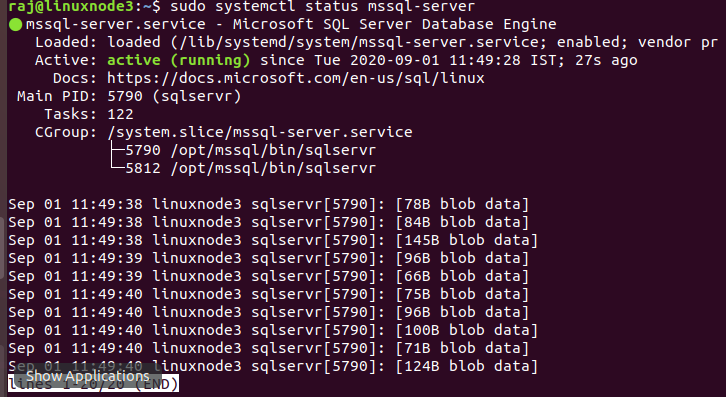
Once the SQL Server setup completes, verify the SQL service status. As shown below, it is in the active (running) status.
|
1 |
$ sudo systemctl status mssql-server |
Similarly, install SQL Server 2019 on the linuxnode2 as well.
Install Azure Data Studio on SQL Server Linux virtual machines
Azure Data Studio works on the Linux operating system as well. You can install the Azure Data Studio and launch it to create the connections to SQL Server Linux.
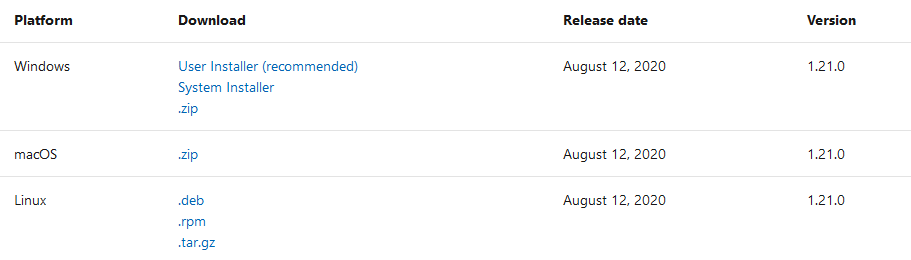
In the new connection window, specify the server name and SQL Server authentication details.
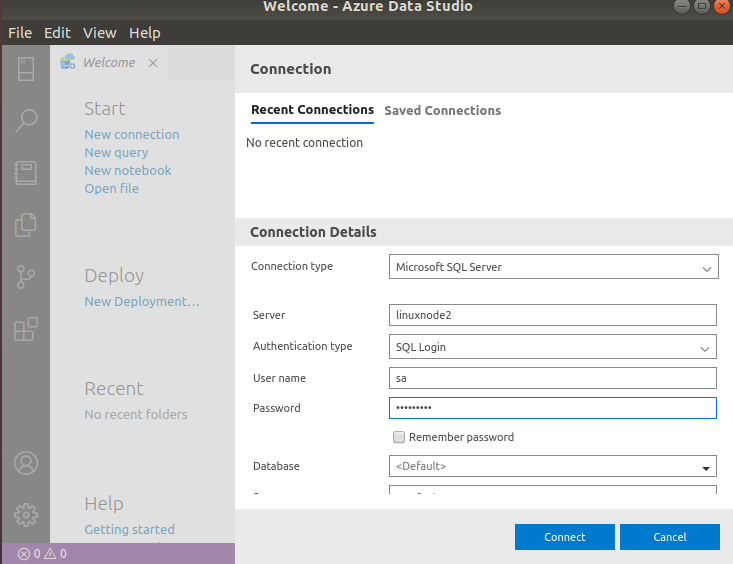
Here, we can see connections to both SQL instances are successful in Azure Data Studio.
Configure the SQL instance for high availability
In the Windows SQL Server, we enable the SQL Server Always On using the SQL Server Configuration Manager. SQL Server Linux does not have a GUI configuration manager. We use mssql-conf utility for enabling the HADR.
|
1 |
$ sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1 |
You need to restart SQL services using the following command:
|
1 |
sudo systemctl restart mssql-server |

You need to configure the high availability on both SQL nodes linuxnode2 and linuxnode3.
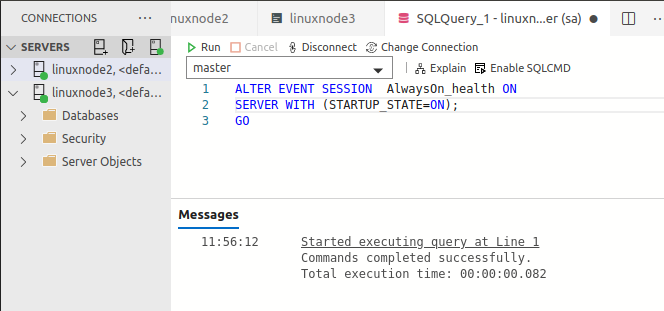
Enable the AlwaysOn_health extended event session
Connect to both SQL instances (linuxnode2 & linuxnode3) and execute the below query to enable and start the extended event session for the SQL Server Always On Availability Groups.
|
1 2 |
ALTER EVENT SESSION AlwaysOn_health ON SERVER WITH (STARTUP_STATE=ON); GO |
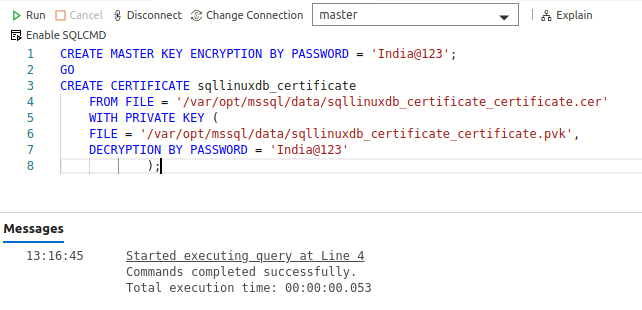
Create the Master key, Certificate and backup the Certificate on the primary replica
Connect to the SQL instance that you want to configure as a primary replica and execute the following queries:
-
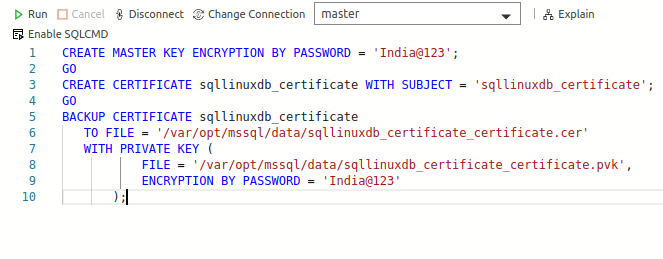
Create a database master key and encrypt with a password
1CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'India@123'; -
Create a certificate with the CREATE CERTIFICATE statement
12CREATE CERTIFICATE sqllinuxdb_certificateWITH SUBJECT = 'sqllinuxdb_certificate'; -
Backup the certificate and the private key
It creates a certificate backup along with the private key file at the SQL Server Linux default data folder /var/opt/mssql/data/
123456BACKUP CERTIFICATE sqllinuxdb_certificateTO FILE = '/var/opt/mssql/data/sqllinuxdb_certificate_certificate.cer'WITH PRIVATE KEY (FILE = '/var/opt/mssql/data/sqllinuxdb_certificate_certificate.pvk',ENCRYPTION BY PASSWORD = 'India@123');
Copy the backup and private key file on another SQL node
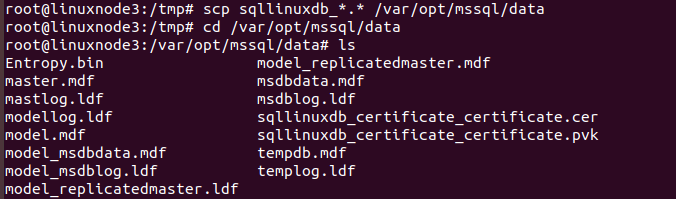
In this step, we need to copy the files from the primary replica to the secondary replica.
This command copies both files from the source SQL server (linuxnode2) to the destination server (linuxnode3) in the /tmp directory.
|
1 2 |
$ cd /var/opt/mssql/data # sudo scp sqllinuxdb_certificate_*.* raj@linuxnode3:/tmp |
In the output, you can verify it coped both *.cer and *.pvk file in the secondary replica.

Now, connect to the linuxnode3 using terminal and copy these Certificate, private key file into the /var/opt/mssql/data.
|
1 2 |
$ cd /tmp # scp sqllinuxdb_*.* /var/op/mssql/data |
You could copy the files directly to the data directory in the secondary replica if your account has permission to write in the SQL data folder.
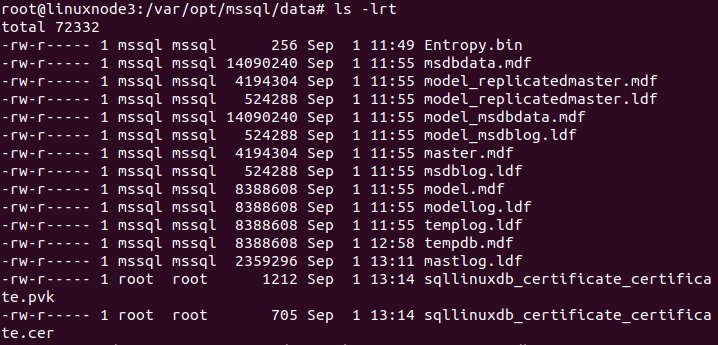
Run the ls command to view the file in the /var/opt/mssql/data directory.
We need to verify the permissions for the Certificate and private key. SQL account (mssql) should be able to access these files.
Using the ls-lrt command, I show the owner of these files are the root user
To change the ownership, run the chown command, as shown below.
|
1 |
# chown mssql sqllinuxdb_*.* |
Rerun the ls-lrt command and verify that ownership is now with the mssql account.
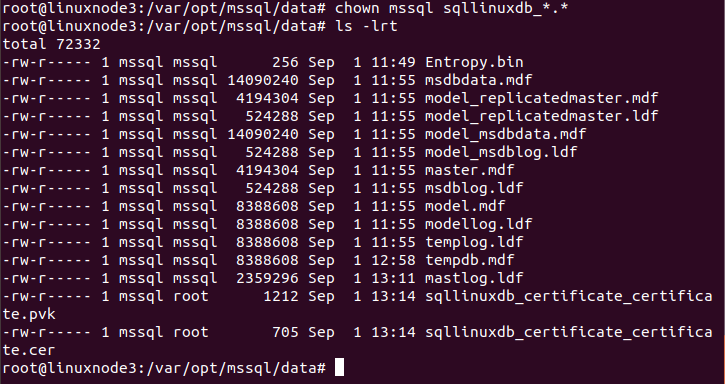
Now, connect to the secondary replica instance and create the Certificate using the files present in the /var/opt/mssql/data directory. In case you use a different directory, your SQL account should have permissions to access the files.
|
1 2 3 4 5 6 7 8 9 |
CREATE CERTIFICATE sqllinuxdb_certificate WITH SUBJECT = 'sqllinuxdb_certificate'; GO CREATE CERTIFICATE sqllinuxdb_certificate FROM FILE = '/var/opt/mssql/data/sqllinuxdb_certificate_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/sqllinuxdb_certificate_certificate.pvk', ENCRYPTION BY PASSWORD = 'India@123' ); |
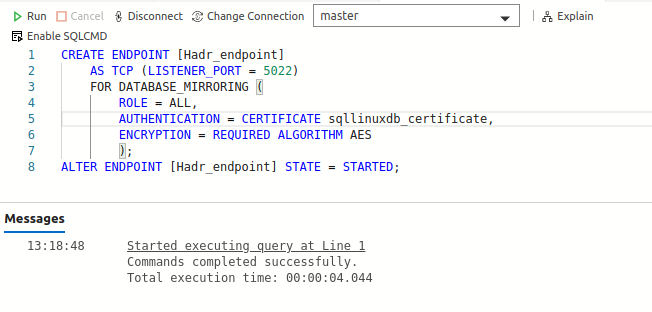
Create HADR endpoints on both primary and secondary replica
In this step, create the HADR endpoints on both the primary and secondary replica. This endpoint is for communication between the primary and secondary replica instances. By default, it uses the 5022 port. You need to specify the certificate name in the AUTHENTICATE section.
|
1 2 3 4 5 6 7 8 |
CREATE ENDPOINT [Hadr_endpoint] AS TCP (LISTENER_PORT = 5022) FOR DATABASE_MIRRORING ( ROLE = ALL, AUTHENTICATION = CERTIFICATE sqllinuxdb_certificate, ENCRYPTION = REQUIRED ALGORITHM AES ); ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED; |
Note: You should allow port 5022 in the firewall so that primary and secondary replica can communicate on it.
To open the firewall port in Ubuntu, run the following command.
|
1 2 |
sudo apt install ufw sudo ufw allow 5022 |
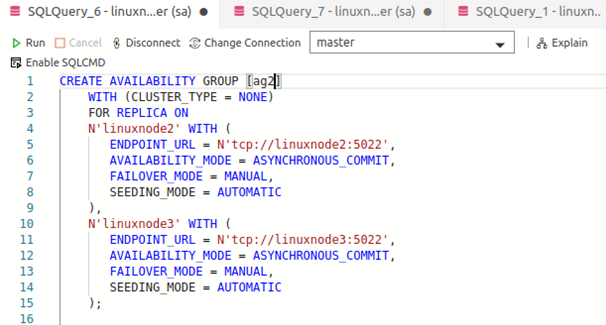
Create the SQL Server Always On Availability Group
We use the following CREATE AVAILABILITY GROUP statement to create the Availability group. Let me explain the query and its argument values here.
- Define a name for the availability group in the CREATE AVAILABILITY GROUP statement. (CREATE AVAILABILITY GROUP [ag2])
- CLUSTER_TYPE: We do not have configured a Linux cluster between the linuxnode2 and linuxnode3 servers. Therefore, use the value NONE in the CLUSTER_TYPE
- ENDPOINT_URL: Specify the endpoint URL for the respective SQL instance. It is in the format of TCP://[server]:[port]
- AVAILABILITY_MODE: We can use asynchronous commit for the cluster less Linux SQL AG
- FAILOVER_MODE: In an asynchronous commit, we only have manual failover
- SEEDING_MODE: We use automatic seeding to create the secondary database and synchronize it with the primary replica
- Grant permissions to create the database on the secondary replica
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
CREATE AVAILABILITY GROUP [ag2] WITH (CLUSTER_TYPE = NONE) FOR REPLICA ON N'linuxnode2' WITH ( ENDPOINT_URL = N'tcp://linuxnode2:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC ), N'linuxnode3' WITH ( ENDPOINT_URL = N'tcp://linuxnode3:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC ); ALTER AVAILABILITY GROUP [ag2] GRANT CREATE ANY DATABASE; |
Join secondary replicas to the SQL Server Always On Availability Group
Execute this query on the secondary replica to join the availability group. We need to specify the cluster type as NONE.
|
1 2 3 |
ALTER AVAILABILITY GROUP [ag2] JOIN WITH (CLUSTER_TYPE = NONE); ALTER AVAILABILITY GROUP [ag2] GRANT CREATE ANY DATABASE; |
Create a sample database on the primary replica and take a full backup
In the previous step, we configured an availability group. Now, to add a database, create a new database on the primary replica instance and take a full backup so that database meets the AG prerequisite.
|
1 2 3 |
Create Database LinuxAGSQL Go backup database LinuxAGSQL to disk='LinuxAGSQL.bak' |
Add a database to the SQL Server Always On Availability Group
Execute the query to add the database [LinuxAGSQL] into the availability group.
|
1 |
ALTER AVAILABILITY GROUP [AG2] ADD Database [LinuxAGSQL] |
It adds the database into the availability group and uses the automatic seeding for secondary data initialization.
Verify the secondary database and its synchronization
We can verify that the secondary database is created successfully and is in synchronizing state for the asynchronous commit.
|
1 2 3 |
SELECT * FROM sys.databases WHERE name = 'LinuxAGSQL'; GO SELECT DB_NAME(database_id) AS 'LinuxAGSQL', synchronization_state_desc FROM sys.dm_hadr_database_replica_states; |
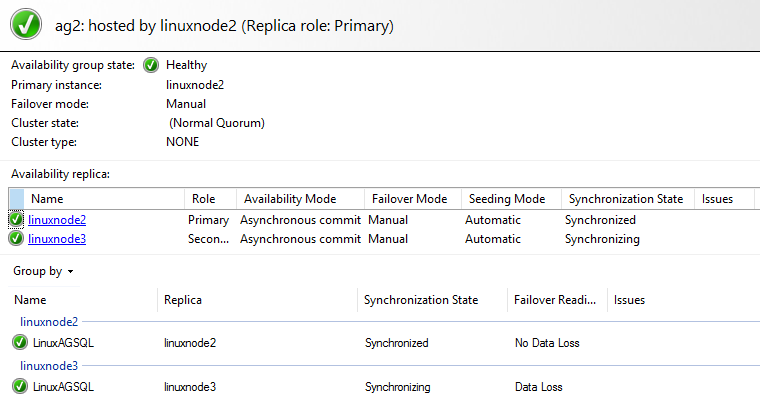
Launch the AG dashboard and verify AG health
You can install the SQL Server Management Studio on a Windows server that has firewall connections open to the Linux server. Open the SSMS, Connect to the primary replica and launch the AG dashboard.
AG dashboard looks adequate for the primary and secondary Linux instances.
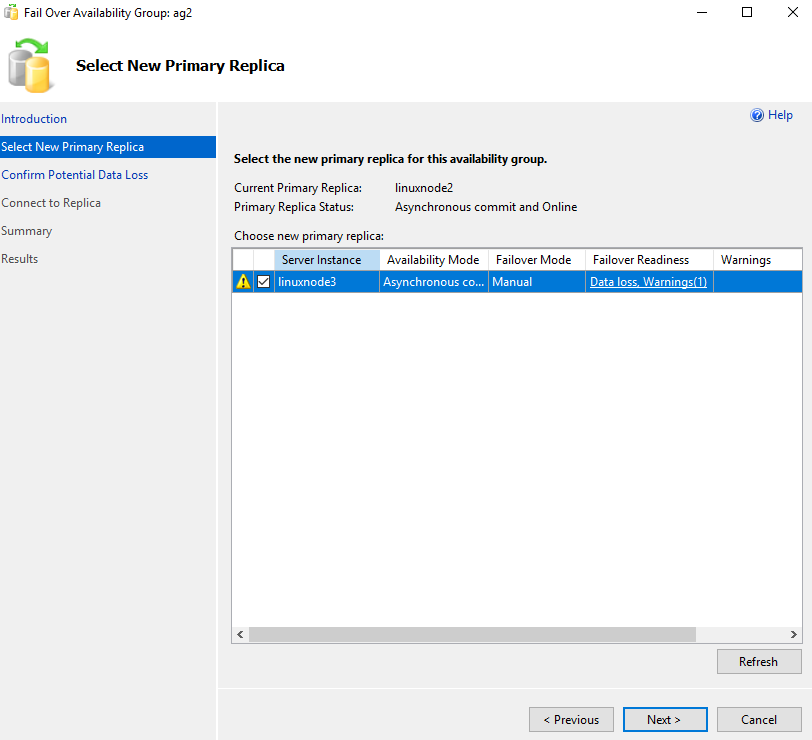
Perform a failover for Linux SQL Server Always On Availability Group
As you know, we can use a force failover for the asynchronous commit SQL Server Always On Availability Group.
Launch the failover availability group wizard, and it shows a warning for possible data loss. It is acceptable for our lab environment.
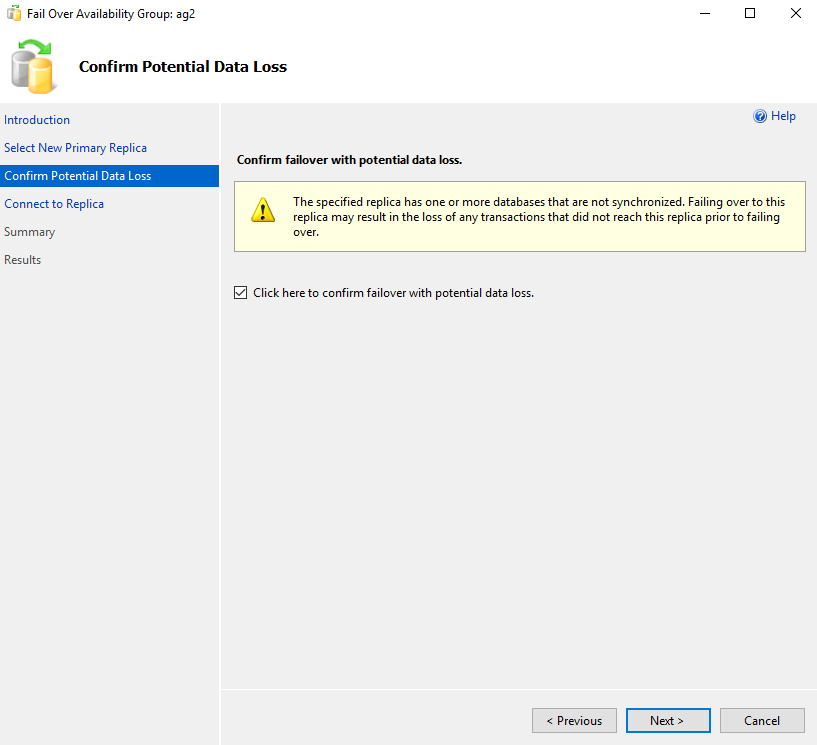
Accept the failover with the potential data loss.
Connect to the secondary replica using the SA authentication.
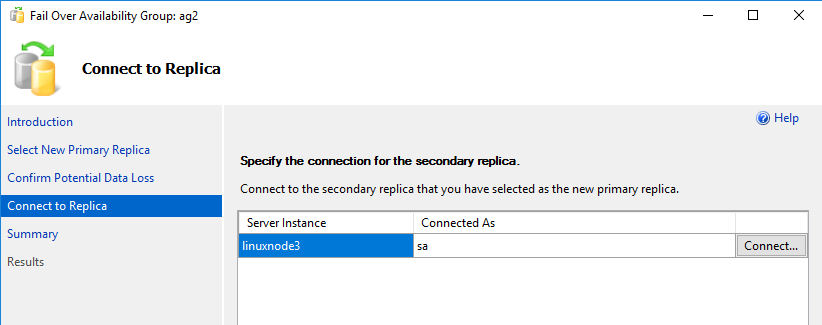
Validate the things and perform failover for the [LinuxAGSQL] database.
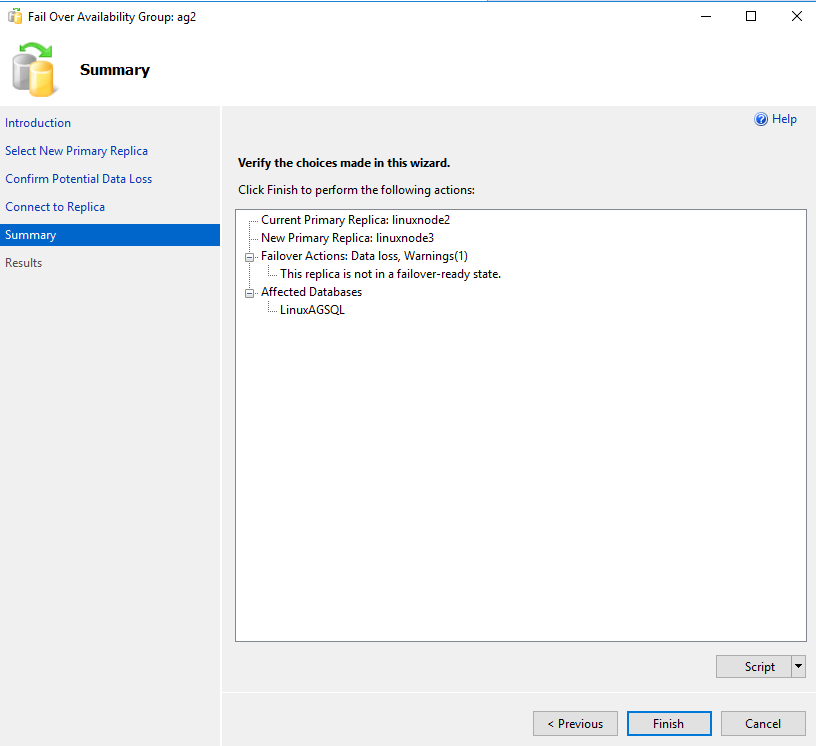
You can execute the following script to perform an AG failover in an asynchronous mode as well.
|
1 2 3 4 |
ALTER AVAILABILITY GROUP [AG2] SET (ROLE=SECONDARY); GO ALTER AVAILABILITY GROUP [AG2] FORCE_FAILOVER_ALLOW_DATA_LOSS; Go |
Launch the AG dashboard from the new primary, and it shows a warning for the secondary replica.
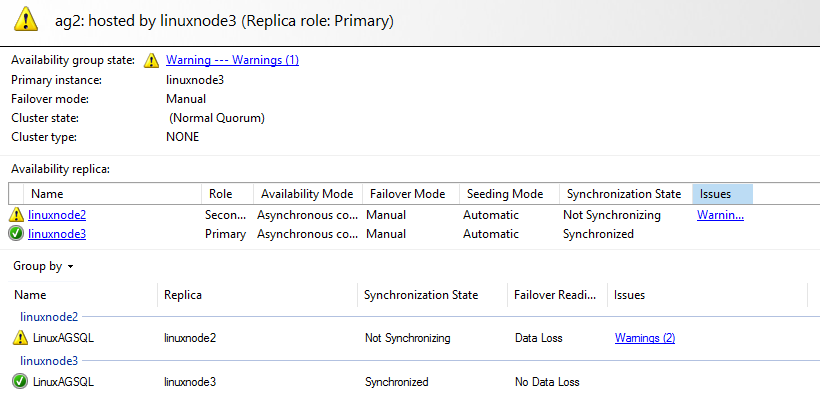
In the case of force failover, SQL Server suspends data movement, therefore, expand the availability group database in secondary replica and resume data movement.
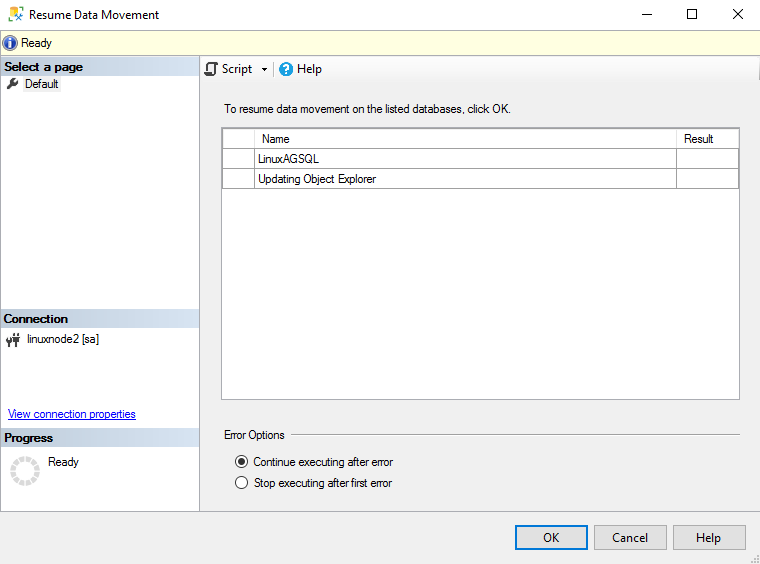
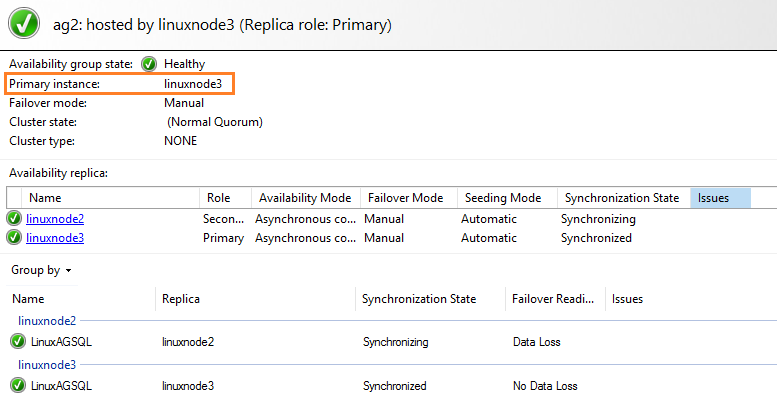
It resumes data movement for SQL Server Always On Availability Group, and Its dashboard becomes healthy, as shown below.
Conclusion
In this article, we configured the SQL Server Always On Availability Group between SQL Server Linux instances on SQL Server 2019. Theses instances do not have domain membership. As SQL Server works on both Windows and Linux, you should be familiar with high availability configurations on both platforms.
Table of contents

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023