
This is the 12th article in the series of SQL Server Always On Availability Groups.
Introduction
SQL Server 2016 provides a new feature Distributed Availability Group for disaster recovery purposes. It is a particular type of availability group that helps access the multiple failover clusters. In this article’s series, we configured a traditional Always On group. It has the following requirements.
- A failover cluster configuration
- Availability replicas should be part of the same failover configuration
- We should configure a SQL listener that always connects to the primary replica
This article explores the concept of the Distributed Availability Group and configures it for the demonstration purpose
SQL Server Distributed Availability Group
Suppose we have two independent failover clusters in your infrastructure. These clusters are configured with two separate SQL Server Always On availability groups. Suppose one of the clusters is in your primary site and the second cluster is in the disaster recovery site. SQL Server distributed availability group provides a solution to configure the availability groups between these clusters.
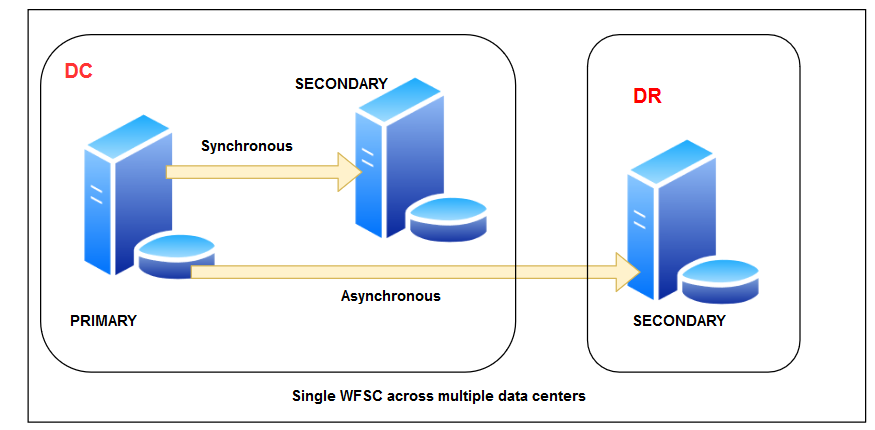
In a traditional SQL Server Always On Availability Groups, all replicas should be part of the failover cluster. We can implement a disaster recovery solution in a traditional AG, but you need to configure the DR server in the same failover cluster. You can configure an asynchronous data commit for the DR Availability group. It requires a geographically stretched failover cluster, as shown below. You need to do complex networking, firewall configurations. It also requires additional configurations such as CrossSubnetDelay, CrossSubnetThreshold using Windows PowerShell.
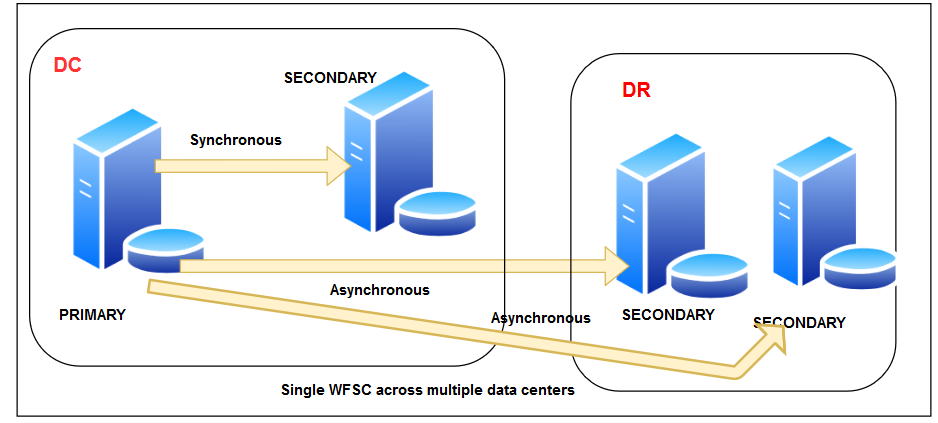
You can add multiple secondary replicas that receive the data from the primary SQL replica located in the leading site. In the below image, we see two DR nodes receiving asynchronous data from the primary replica. These four nodes are part of a single geographical cluster.
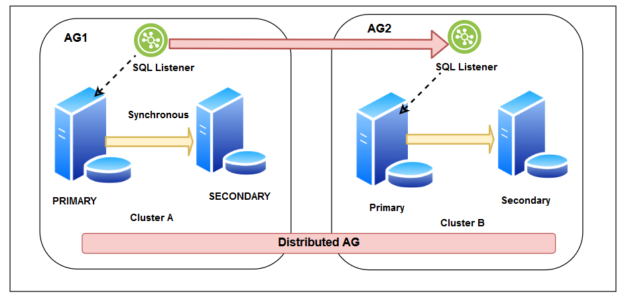
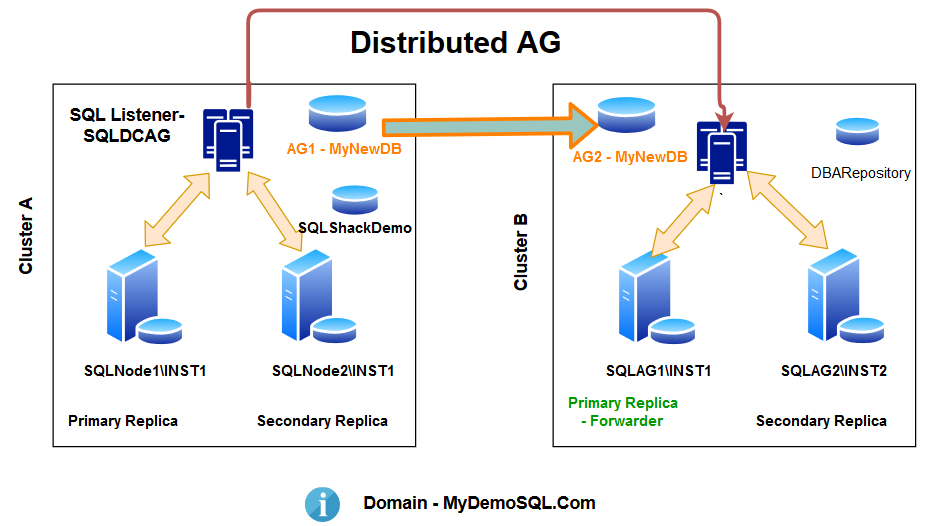
Now, suppose you have two separate sites, and you do not want to create a stretched cluster. Both clusters are independent of each other. You can configure the distributed availability group where the primary cluster is in the DC and secondary cluster in the DR.
As shown below, we create a distributed SQL Server Availability group with below configurations:
- You have a failover cluster in your primary site, and it has a synchronous replica between the two nodes. You configured a SQL listener to point applications to the primary replica
- You have another failover cluster in the DR site, and it also has synchronous data commit replica in its two nodes. You also configured another SQL listener in the DR cluster
- We created a distributed AG that connects the listener of both failover clusters hosted in the DC and DR site
- You can configure both synchronous or asynchronous data commit for a distributed availability group. In the synchronous data commit, primary replica waits for an acknowledgement from the secondary replica to commit the transaction. In case you prefer to configure the synchronous replica, you should consider the network bandwidth and transaction workload to avoid any impact on the application connecting to the primary replica in the DC site
Benefits of distributed SQL Server Always On Availability Groups
- Disaster-recovery and Multi-site scenarios: We can create availability groups span across multiple data centers. You do not require geographical stretched failover clusters
- Datacenter migrations: Suppose you need to migrate the servers from a data center to another. Your applications cannot afford much downtime. You need a high resilience infrastructure to move your resources. Usually, we use the backup-restore method, log shipping methods to send data across another data center
Suppose we are running SQL Server in Windows Server 2012 and we require to migrate to Windows Server 2016 without changing anything in the SQL Server. You can leverage the distributed availability group for these hardware or software movements as well.
- Failover mechanism in the DR site: We configure a distributed availability group in the DR site having nodes in a failover cluster group and AG configuration with the listener. It provides a safeguard mechanism to your DR infrastructure as well and safeguards you in case of any server issues. You can also apply patches to DR replica nodes with minimum downtime
- Scale-out readable replicas with distributed availability groups: In a traditional SQL Server Always On Availability Groups configuration, SQL Server 2019 allows 1 primary and up to 8 secondary replicas. In a distributed configuration, we have two availability groups, so it supports up to 16 secondary replicas
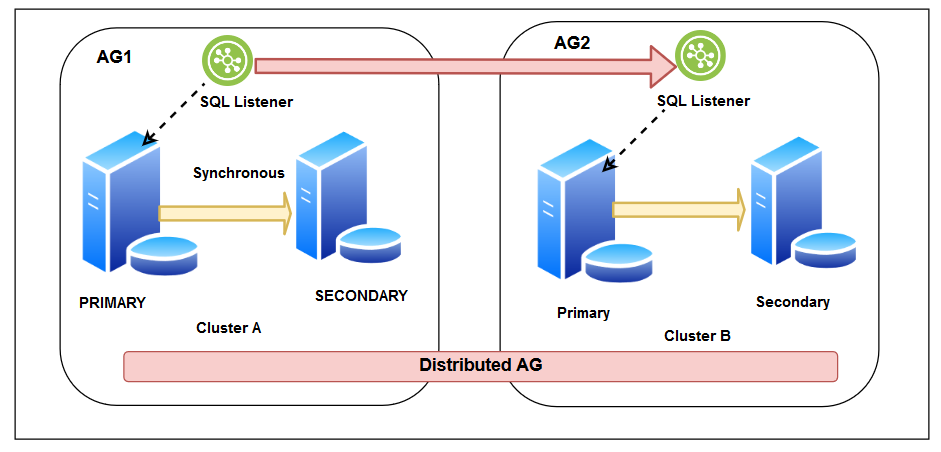
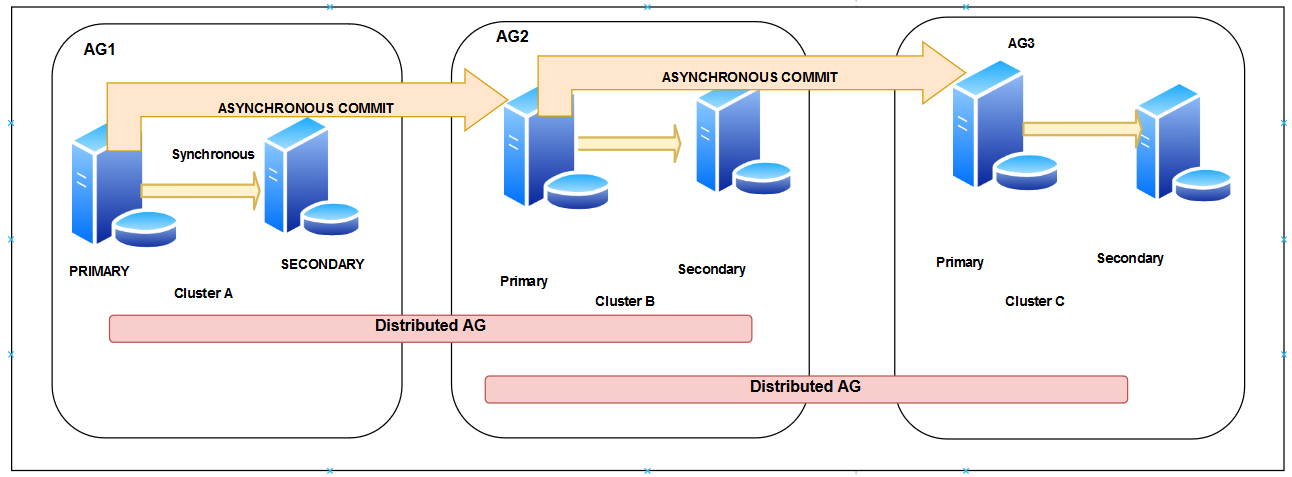
- In the below image, we see multiple distributed groups to provide scalable read-only secondary replicas
- We configured a distributed replica between Cluster A and Cluster B
- Another distributed replica between Cluster B and Cluster C
Environment setup details
You should explore previous articles in the SQL Server Always On Series and prepare the environment as below.
-
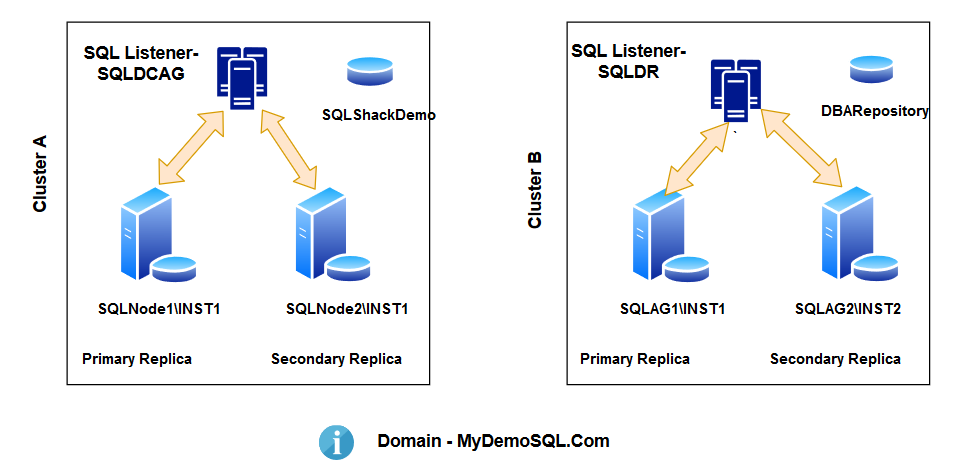
You should configure two failover clusters as below:
- First Windows Failover Cluster:
- In the first cluster, you have two instances [SQLNode1\INST1] and [SQLNode2\INST1]
- You use synchronous data synchronization between primary and secondary SQL Server Always On Availability Group for the [SQLSHACKDEMO] database.
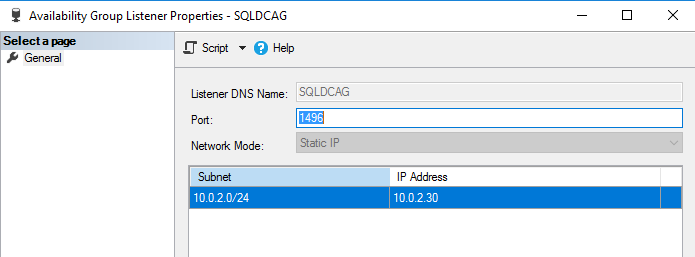
- You configure a SQL Listener [SQLDCAG] to connect with the primary replica

- Second Windows Failover Cluster
- In this second cluster, you have two instances [SQLAG1\INST1] and [SQLAG2\INST2]
- You use synchronous data synchronization between primary and secondary replica for the [DBARepository] database
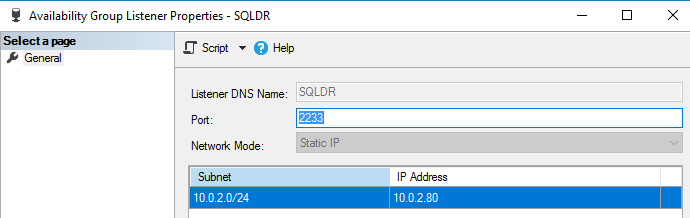
- You configure a SQL Listener [SQLDR] to connect with the primary replica
- First Windows Failover Cluster:
- Both Windows Failover Clusters are part of the [MyDemoSQL.COM] domain
- You should allow firewall in both clusters to allow connections to another cluster replica
-
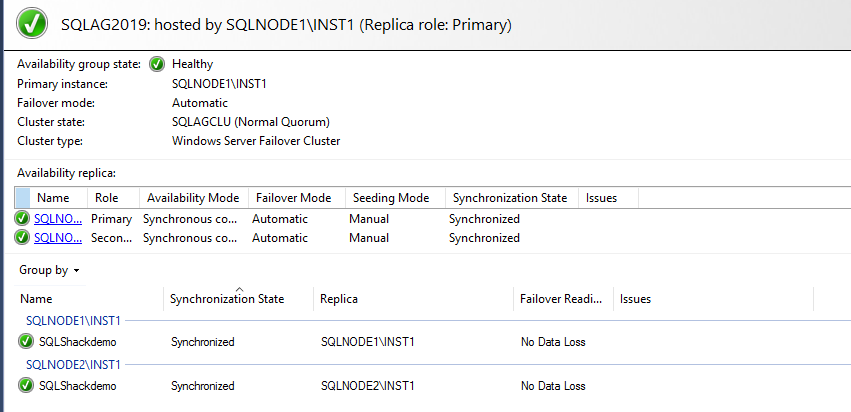
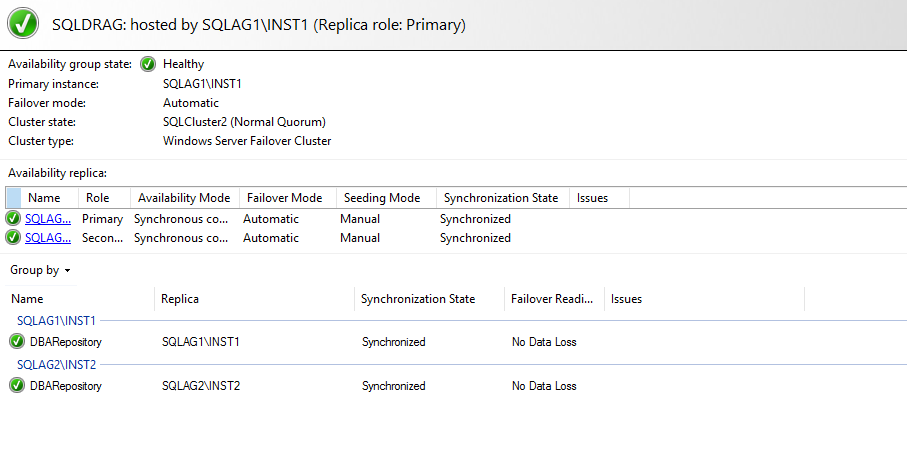
Your AG dashboard is healthy in both SQL Server Always On Availability Groups
-
SQLAG2019 Availability Group
SQLDRAG Availability Group
-
Details to configure a Distributed Availability Group
For the distributed AG configuration, note the following useful points.
- It connects using the SQL Listener of both availability groups in separate clusters. In a traditional AG, listener configuration is optional. If you do not use listeners, you need to create them first before planning for the distributed AG
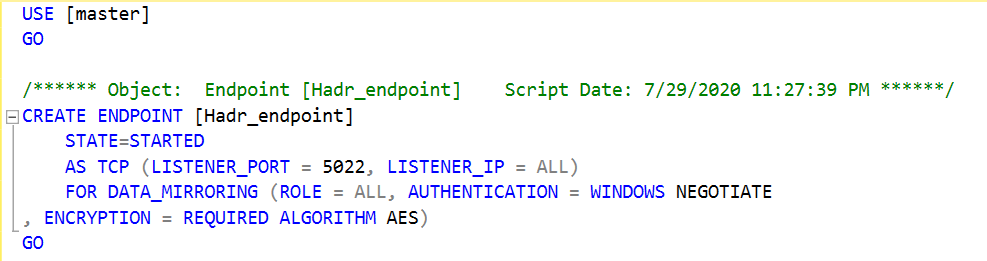
You should configure the HADR endpoint to listen to all IP addresses. You can script out the existing. Connect to the primary replica in SSMS for both clusters and navigate to Server Objects -> Endpoints -> Database Mirroring -> Hadr_endpoint. Right-click on the Hadr_endpoint and generate a create endpoint t-SQL. It should use the parameter LISTENER_IP=ALL as shown below:
- You cannot configure a listener for the distributed availability group. In this case, your application cannot redirect connections to another cluster (primary) automatically. It requires an explicit configuration in the application connection string
- We can configure the distributed availability group for both synchronous and asynchronous mode
- Data movement in a distributed availability group is different than to a traditional availability group
- Let’s assume that Cluster A is the primary replica in a distributed availability group. SQLNode1 is the primary availability group of the primary replica
- Similarly, Cluster B is the secondary replica of the distributed availability group. SQLAG1 is the primary availability group of the secondary replica
- The Primary replica of the secondary distributed availability group receives the transactions and forwards it to the secondary replica. This primary replica is known as the forwarder. In our current scenario, SQLAG1 is the forwarder
- It does not have a mechanism to support the automatic failover between multiple clusters. A distributed availability group supports only manual failover using the FORCE_FAILOVER_ALLOW_DATA_LOSS parameter
- We can configure a distributed availability group in below failover cluster scenarios:
- Your both failover clusters are part of the same domain. This article explores this scenario practically
- Your both clusters are a member of the different domains. You should have domain trust relationships to allow the database connections
- Your one failover cluster is part of a domain while another cluster is not part of the domain. You need to use certificates to allow the DB connections
- Both clusters are not part of the domain
Conclusion
In this article, we learned the concept of distributed SQL Server Always On Availability Groups, its features and its requirements. In the next article, we cover the practical implementation of it.
Table of contents

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023