
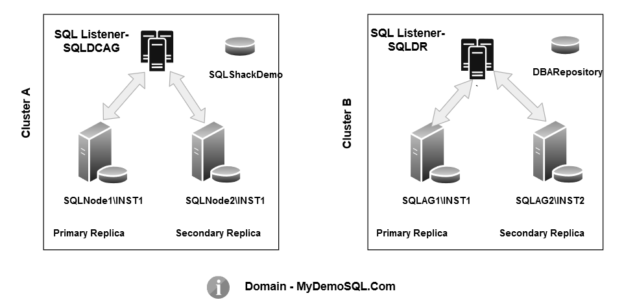
In the previous article, An overview of distributed SQL Server Always On Availability Groups, we explored the concept of the distributed availability groups in SQL Server Always On Availability Group. It is available from Windows Server 2016 and SQL Server 2017.
In this article, we will configure the distributed availability group for the environment specified in the previous article.
Prerequisites
You should go through previous articles in this SQL Server Always On series and prepare the environment before proceeding with this article.
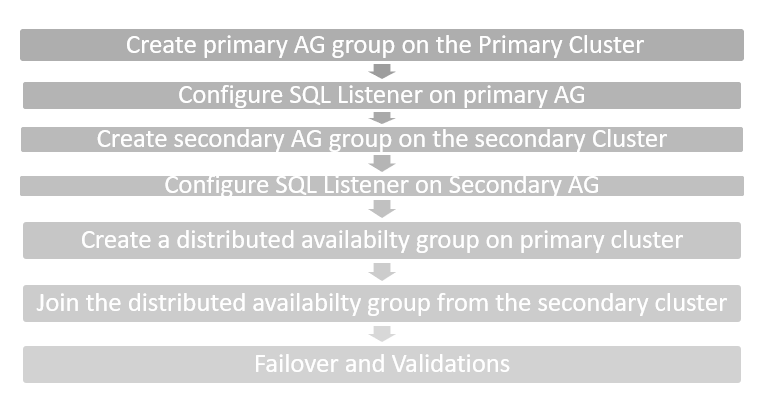
High-level steps for configuration of a distributed availability group
In the below flowchart, we can see the high-level steps of configuring the distributed availability group.
- We create a new SQL Server Always On Availability Group in the primary cluster and configure a listener to always point towards a primary replica
- We create another AG in the secondary cluster and configure a listener for this availability group
- We use automatic (direct) seeding to copy the data across replicas instead of taking database backup and restore it
- Create a distributed AG group in the primary cluster. This primary replica is also known as global primary in the distributed availability group
- Join the second cluster in the distributed availability group. The primary replica of the second cluster is also known as the forwarder
- Validate the configurations and ensure that availability groups are healthy
T-SQL scripts to configure a distributed availability group
We can configure the distributed availability group using t-SQL. SSMS does not have a GUI wizard for distributed AG configurations.
Let me summarize the useful terms in my environment that will be useful for you to understand the t-SQL.
|
Production – Cluster A |
DR – Cluster B |
|
|
Operating system |
Windows Server 2016 |
Windows Server 2016 |
|
SQL Server Version |
SQL Server 2019 |
SQL Server 2019 |
|
Nodes |
SQLNode1\INST1 and SQL Node2\INST1 |
SQLAG1/INST1 and SQLAG2/INST2 |
|
Primary replica of the primary cluster ( Global Primary) |
SQLNode1\INST1 |
NA |
|
Secondary replica of the primary cluster |
SQLNode2\INST2 |
NA |
|
Primary replica of the secondary cluster (Forwarder) |
NA |
SQLAG2\INST1 |
|
Secondary replica of the secondary cluster |
NA |
SQLAG2\INST2 |
|
A listener in the primary cluster |
SQLDCAG |
NA |
|
A listener in the secondary cluster |
NA |
SQLDR |
- Note: You can find all the scripts used in this article in a zip file attached to this article. For a better understanding, I have included the script screenshots instead of specifying the script
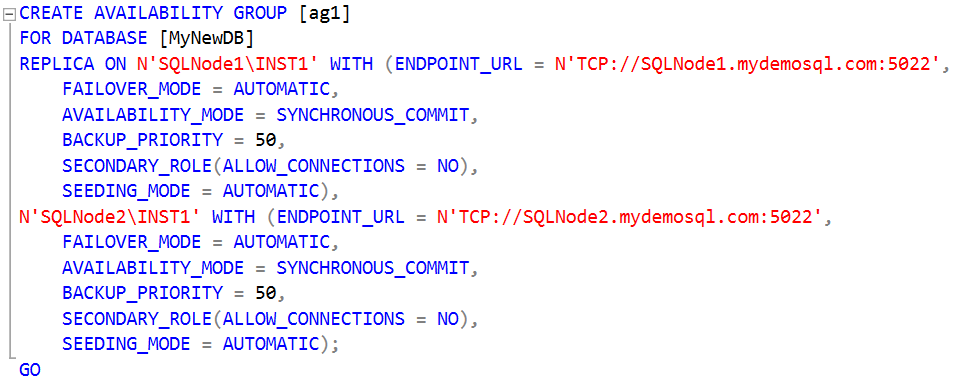
Step 1: Create a primary SQL Server Always On Availability Group on the primary cluster
In this step, we create a new availability group in the primary cluster. Execute this script on the primary replica of the primary cluster ( in my case SQLNode1\INST1)
- In this query, we create a new SQL Server Always On Availability Group AG1 for the database [MyNewDB]. This database should meet the prerequisites of an AG database
- In the replicas, specify both primary and secondary replica instances along with the endpoint URL
- The endpoint URL configured on the 5022 port
- We use automatic seeding for using the parameter ( SEEDING_MODE=AUTOMATIC). It does not require manual backup and restore of the AG databases
- We use SYNCHRONOUS data commit using the AVAILABILITY_MODE = SYNCHRONOUS_COMMIT argument
- It does not allow connections to the secondary database
Step 2: Join the secondary replicas to the primary availability group on the primary cluster
Connect to the secondary replica SQL instance of the primary cluster (in my case – SQLAG1\INST1) and join it in the availability group [AG1]. We also provide permissions to create a new database because, in the automatic seeding, SQL Server creates a new database in the secondary replica using direct seeding.

Launch the availability group dashboard from the primary replica, and you should see the new availability group [AG1], as shown below.
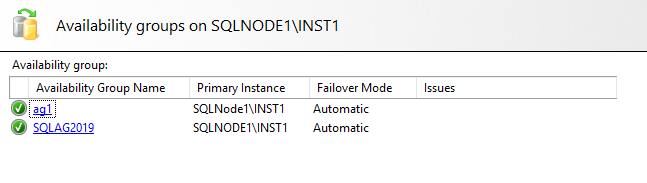
Here, we see two availability groups.
- SQLAG2019: This AG group is already present for my environment
- AG1: It is a newly created AG. We use this for the distributed availability group configuration
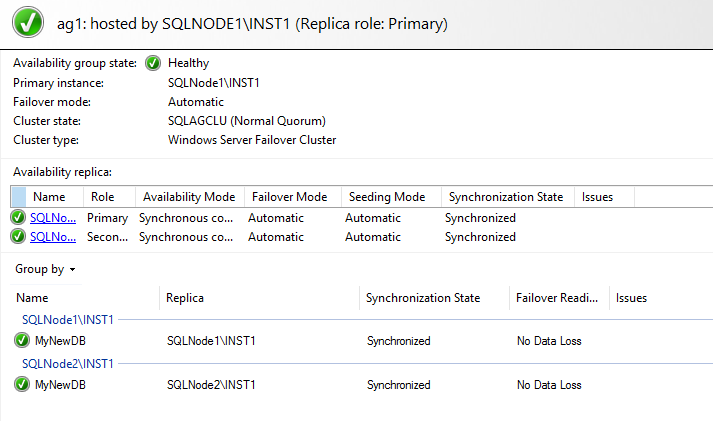
Click on the [AG1] availability group, and you get [MyNewDB] in the synchronized state. As you know, it uses direct seeding, and its synchronization depends upon the database size and network bandwidth. In my case, it is a small database, so it came into a synchronized state quickly.
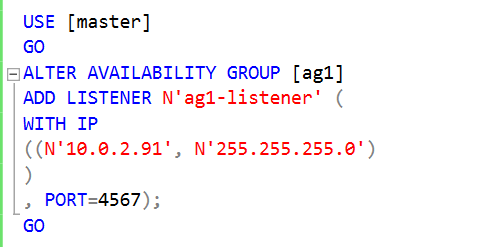
Step 3: Create a SQL Listener for the [AG1] SQL Server Always On Availability Group
As highlighted earlier, we require a listener for the availability group configuration of the distributed AG. Previously, we have a listener for the [SQL2019AG] availability group. Let’s create another listener using the below script.
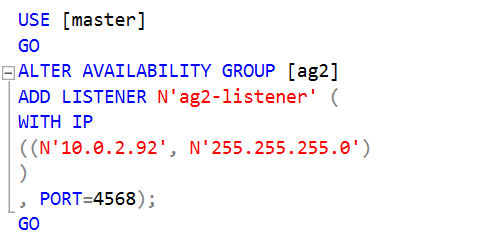
Here, specify a listener name, IP address and the port number. Make sure the firewall allows the traffic for this port.
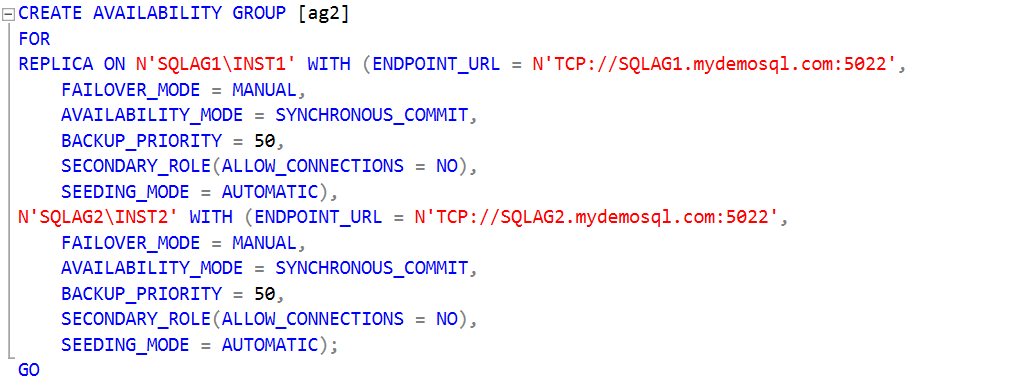
Step 4: Create a secondary availability group on the second cluster
In this step, connect to the primary replica (forwarder) of the second cluster and create an availability group similar to step 1.
- Specify the primary replica instance name and its endpoint. The endpoint format is N’TCP://[hostname].domain:[PortNo]’
- Specify the secondary replica instance name and its endpoint
- We do not use any database name in this CREATE AVAILABILITY GROUP command because it automatically seeds data from the primary replica
Step 5: Join the secondary replica to the secondary SQL Server Always On Availability group on the secondary cluster
This step is similar to step 2 except that the script executes on the secondary replica of the secondary availability group. It also gets permission to create a new database using automatic seeding.

Step 6: Create a listener for the secondary availability group
In this step, configure a new SQL listener for the secondary availability group [AG2]. You should allow the listener port in your Windows firewall configurations so that users can connect to it.
Step 7: Create a distributed SQL Server Always On Availability Group on the global primary replica
We can create a distributed availability group once the primary and secondary availability groups are available. We run this query on the primary replica of the primary availability group(global primary). In my case, it is SQLNode1\AG1.
In the below query, note down the following points.
- We are using an option WITH(DISTRIBUTED) to tell SQL Server that this availability group is distributed
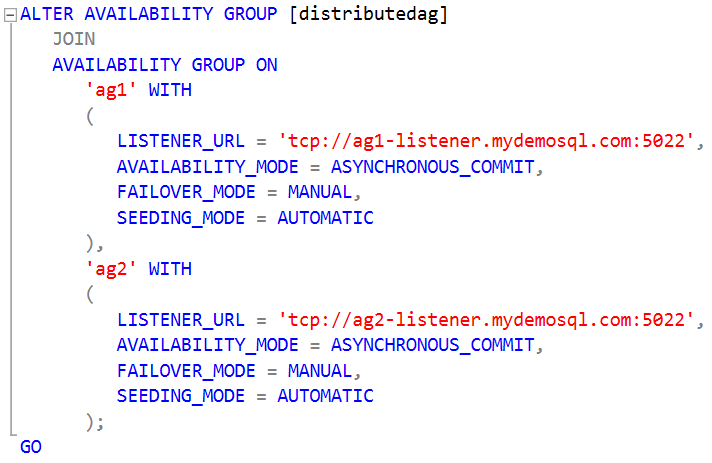
- We have specified the primary availability group and use its listener in the LISTENER_URL
- We used port 4567 for the listener configuration in step 3, but the below query uses the port 5022
- We used Asynchronous data commit in the distributed availability group. I would recommend using the asynchronous mode to avoid any impact on the primary replica. You should have a good network bandwidth because the primary replica sends the transaction logs to all secondary replica and forwarders in a distributed availability group
-
A distributed availability group supports manual failover irrespective of the synchronous or asynchronous commit

Note: The endpoint specified in the LISTENER_URL section is then the listener port we configured in steps 3 and 6. You should be careful in specifying the port number else it does not allow AG connections
- Similarly, specify the secondary availability group and its listener address. It also uses port 5022 similar to the primary listener configurations

Step 8: Join the distributed availability group on the primary replica of the secondary cluster
We have created a distributed availability group on the primary replica of the primary cluster in step 7. Now, we require the secondary cluster to join this AG and start direct seeding automatically.
Connect to the forwarder and run the below command. In this t-SQL, we use the JOIN keyword to join an existing availability group.
- Note: SQL Server service account should have connected permissions to the endpoint in an availability group configuration. In this article, we use the following service accounts
- SQLNode1 and SQLNode2 use managed service account MYDEMOSQL\gMSAsqlservice$
- SQLAG1 and SQLAG2 uses service account mydemosql\svc-node1
You should add the service accounts in primary and secondary replicas of both clusters if these accounts do not have the permissions. You get the error such as below if the service account lacks permission issues.
Database Mirroring login attempt by user ‘MYDEMOSQL\gMSAsqlservice$.’ failed with error: ‘Connection handshake failed. The login ‘MYDEMOSQL\gMSAsqlservice$’ does not have CONNECT permission on the endpoint. State 84.’. [SERVER: 10.0.2.91]
|
1 2 3 4 5 6 7 |
USE master GO CREATE LOGIN [MYDEMOSQL\gMSAsqlservice$] FROM WINDOWS; GO GRANT CONNECT ON ENDPOINT::Hadr_endpoint TO [MYDEMOSQL\gMSAsqlservice$]; GO |
Conclusion
In this article, we configured a distributed SQL Server Always On Availability Group between two independent failover clusters. In the next article, we will do the validation and monitoring of the distributed AG. We will also cover the AG failover from the primary cluster to the secondary cluster.
Table of contents

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023