
In this 14th article of SQL Server Always On Availability Group series, we monitor and failover a distributed AG.
Introduction
We can implement a distributed availability group between multiple independent failover cluster nodes. In the previous articles, we understood the concept and also walked through T-SQL scripts to implement it. In this article, we will explore the T-SQL scripts to monitor the distributed availability group and failover process.
Prerequisites
You should follow previous articles, An Overview of distributed SQL Server Always On Availability Groups, and Deploy a distributed SQL Server Always On Availability Group in the series of SQL Server Always On Availability groups and configure a distributed availability group before you go further in this article.
Verification of the distributed SQL Server Always On Availability Group
View the distributed availability group in SSMS
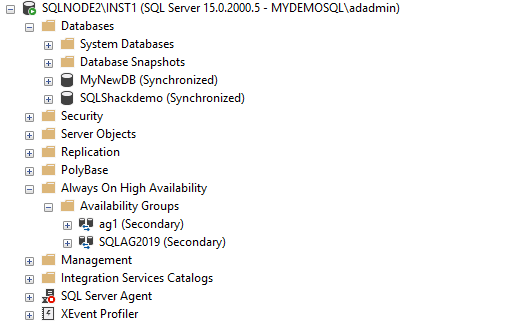
We have configured the distributed availability group between two different Windows failover clusters. Now, connect to the primary replica of the primary cluster and expand the availability group.
You can see a keyword Distributed for the distributed availability group.
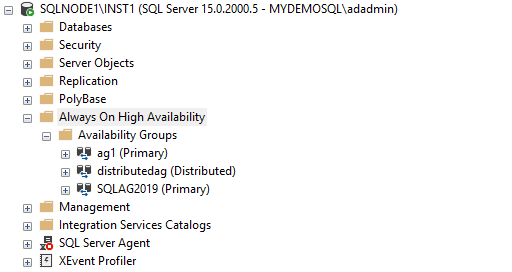
If you connect to the secondary replica of the primary cluster, it does not show the distributed availability group. You do not see it here because the distributed AG configured on the listener URL that always connects with the primary replica. Your database [MyNewDB] is in the synchronized state as well.
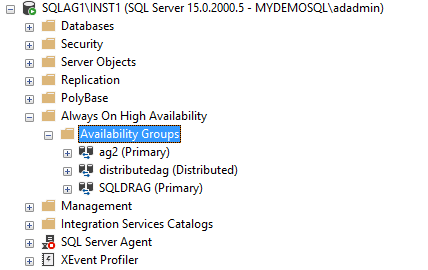
Similarly, you can connect to the forwarder replica and view the distributed availability group.
View the AG dashboard for the SQL Server Always On Availability Group
Right-click on the distributed availability group, and you see a few options such as Show Dashboard, Failover…, Delete… and Properties are greyed out. You cannot launch these options from the SSMS GUI wizard.
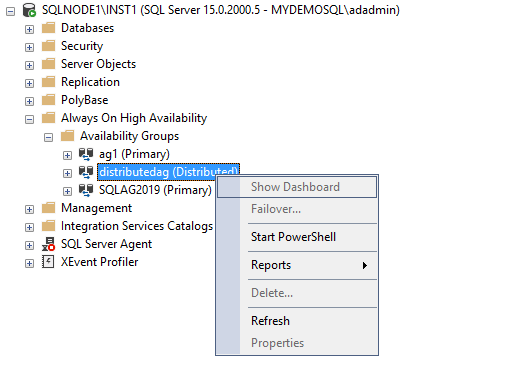
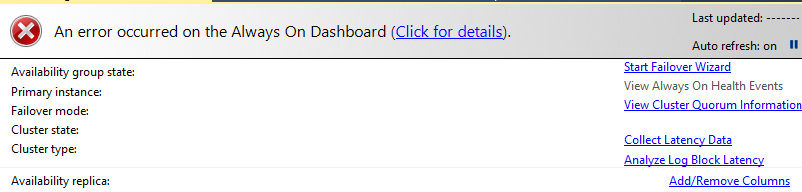
If you try to launch the dashboard from the parent folder Always On Availability group for distributed availability group, you get the below error.
View the failover cluster resources for the distributed SQL Server Always On Availability Group
In a traditional availability group, you see the resources such as listeners in the failover cluster manager.
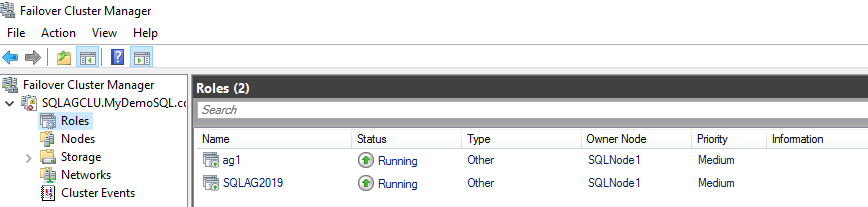
For a distributed SQL Server Always On Availability Group, you do not see any resources in this failover cluster manager. A distributed AG stores all metadata inside SQL Server. You cannot manage any distributed AG resources from the cluster manager.
Monitor distributed availability groups using dynamic management views
We can use dynamic management views(DMV’s) to monitor a distributed availability group, its performance, issues. We can use the following dynamic management views ( DMV) for AG monitoring.
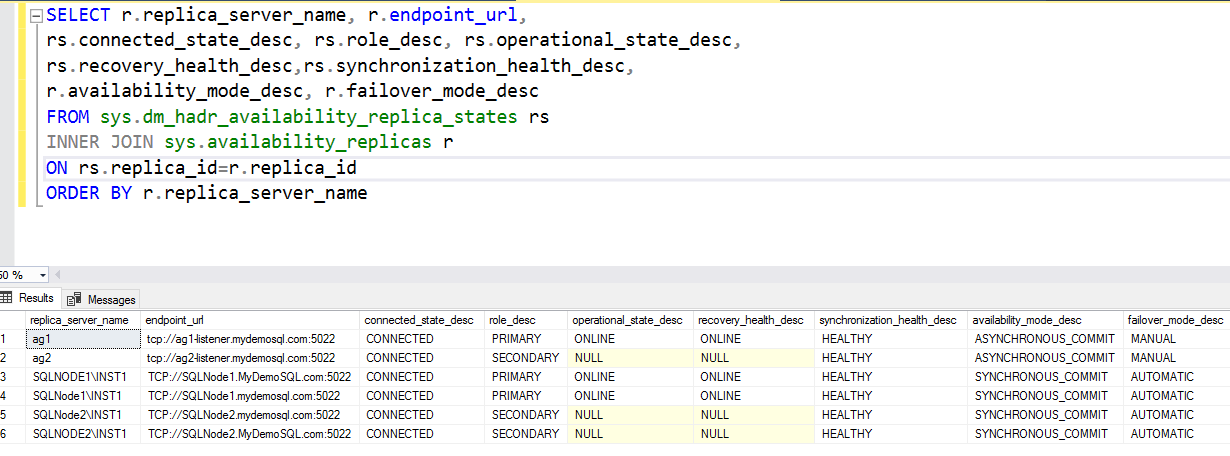
The DMV to check replica status, role and failover mode
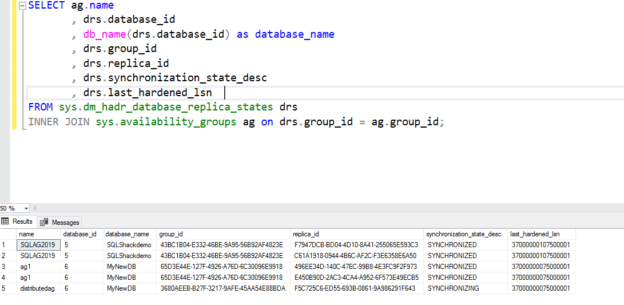
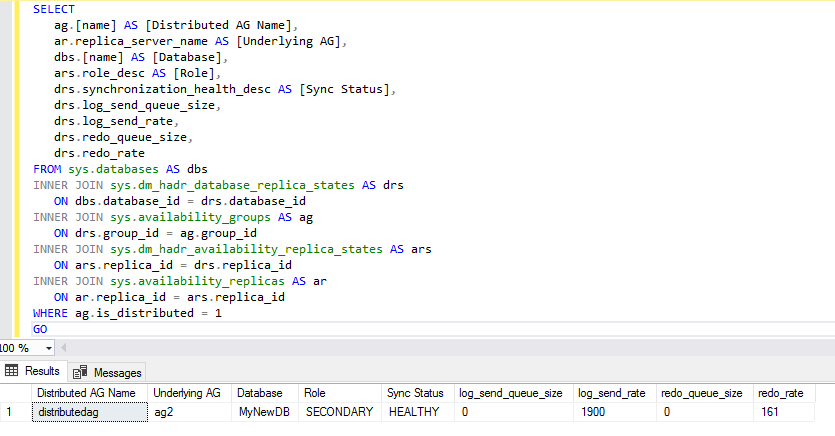
The below query returns the availability of replicas and their state information. It filters the records for a distributed availability group using the is_distributed column of the sys.availabilty_groups DMV.
In the output, we can see underlying AG as well that we used to set up a distributed availability group. The current sync status is healthy.

The query to check the underlying SQL Server Always On Availability Groupmetadata
In the below output, we can see underlying availability group configurations details such as endpoint_url, connected state, synchronization health, failover mode.
The query to check distributed availability group performance
In a traditional always on, we can use the SSMS dashboard or DMV to check AG performance. In the distributed availability group, we can check current sync status, log rate, redo queue size, redo rate from the DMV sys.dm_hadr_database_replicas_states.
The query to filter the OS performance counters value for a distributed availability group
In SQL Server, we use DMV sys.dm_os_performance_counters to retrieve OS performance counter and their values directly from the SQL Server. You can use a similar DMV to monitor the health of a distributed availability group as well.
In this query, specify the distributed AG name, and you get the performance counters’ values.
|
1 |
SELECT * FROM sys.dm_os_performance_counters WHERE instance_name LIKE '%distributed AG name%' |
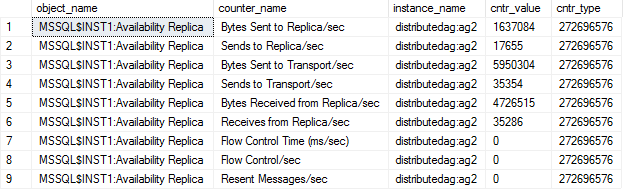
You can create a SQL job to capture these values frequently and monitor AG health conditions.
The query to monitor the automatic seeding in a distributed availability group
In a distributed availability group, it uses automatic seeding for the following:
- It uses direct seeding for database synchronization from the primary replica (primary cluster – Global primary) to the secondary replica (primary cluster). In our case, it uses automatic seeding from [SQLNode1\INST1] to [SQLNode2\INST2] for [AG1] availability group
- It uses another direct seeding from the global primary (primary cluster) to the forwarder( primary replica of the secondary cluster). In our case, it uses automatic seeding from the [AG1] to [AG2] availability group from the [MyNewDB] database
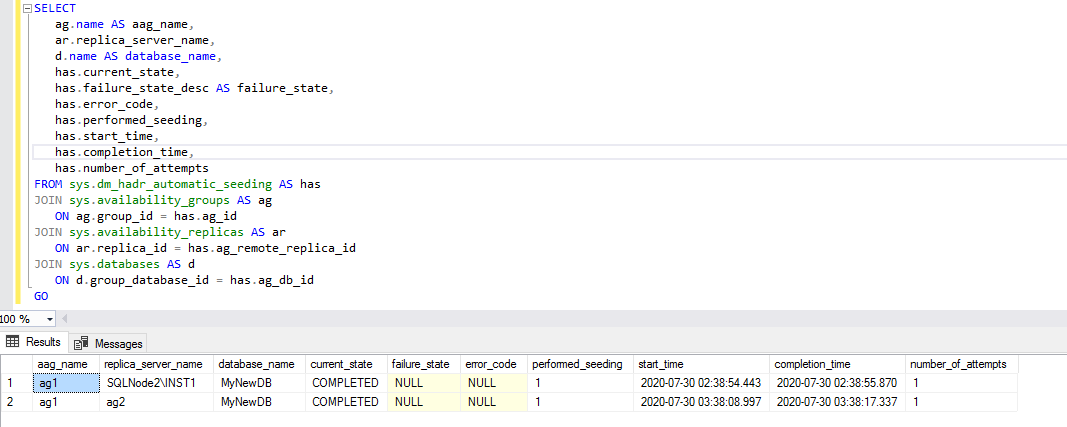
We can see the automatic seeding status, its start and end time, source to destination replica in the below image. It uses an additional DMV sys.dm_hadr_automatic_seeding to monitor sync status. It shows NULL for the failure_state and error_code because our automatic seeding is successful.
Failover from the primary to secondary cluster AG in a distributed SQL Server Always On Availability Group
In a distributed availability group, we can do a manual failover. It does not support automatic failovers because the replicas are in different clusters. Let’s perform a manual failover for distributed AG.
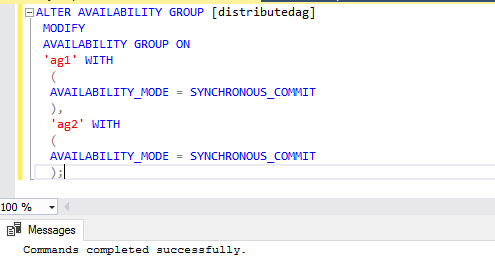
- We have a distributed availability group in asynchronous data commit configuration. In this configuration, we can have data loss if we perform an AG failover. We can set the distributed availability group in the synchronized mode. You need to run the query in both primary replicas of separate clusters
-
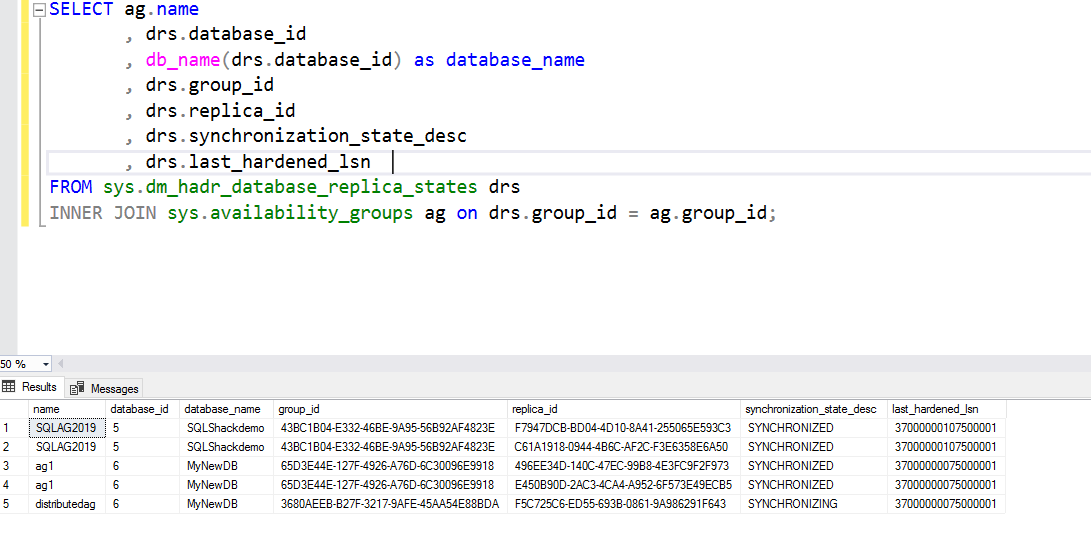
Monitor the distributed availability group. It should be in SYNCHRONIZED mode, and last_hardened_lsn should be the same for the primary replica and forwarder. It might take some time for AG to be in the synchronized state depending upon the active transactions. You should not proceed until AG’s are fully synchronized

-
Run the below query to change the role of a primary replica of the primary Availability Group to secondary in a distributed availability group. You must run this command on the primary replica of the primary cluster( global primary)
1ALTER AVAILABILITY GROUP distributedag SET (ROLE = SECONDARY);It modifies the distributed availability group in an offline state. It terminates all connections for the AG in the global replica.
-
Perform a manual failover with FORCE_FAILOVER_ALLOW_DATA_LOSS parameter. Run this command on both the current primary replica of the secondary availability group
1ALTER AVAILABILITY GROUP distributedag FORCE_FAILOVER_ALLOW_DATA_LOSS; - You can run the monitoring query and see that the availability group [ag2] is now having the primary role

-
You can also monitor the forwarder SQL Server error logs. It gives details information about transitioning the role from the forwarder to the global primary
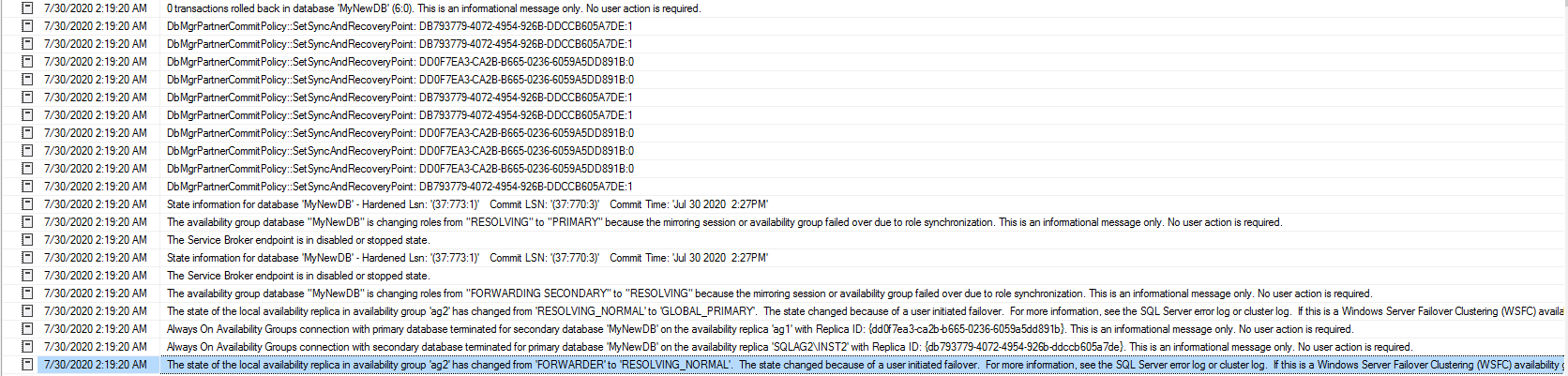
It might take a few minutes for databases to be in synchronized state again. You can monitor the health of the distributed availability group using the above-specified examples.
You can follow the same steps and perform a failback as well.
Impact of the distributed availability group by the failover within a cluster
In the previous section, we performed a distributed availability group failover from the global primary replica to forwarder replica. As you know, that the distributed AG works on the SQL Listener, and a SQL listener always points to the primary replica.
Suppose you are applying Windows patches to the AG replicas in the primary site. For this requirement, you follow below high-level steps.
- Apply Windows patch on the secondary replica
- Perform a failover from the Current primary replica to secondary replica
- Apply Windows patch on the current secondary replica
- Failback
In my demo, the current primary replica is on SQLNode1 for the primary cluster.
Let’s perform a failover from the SQLNode1 to SQLNode2. You can note here that both the nodes part of a Windows failover cluster. It affects the [MyNewDB] database that is part of the distributed availability group.
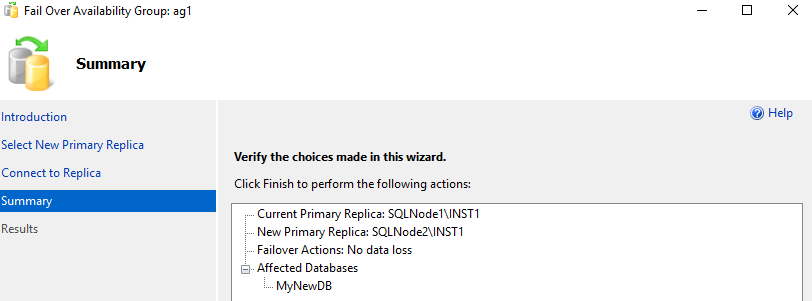
It performs a failover for the [AG] availability group.
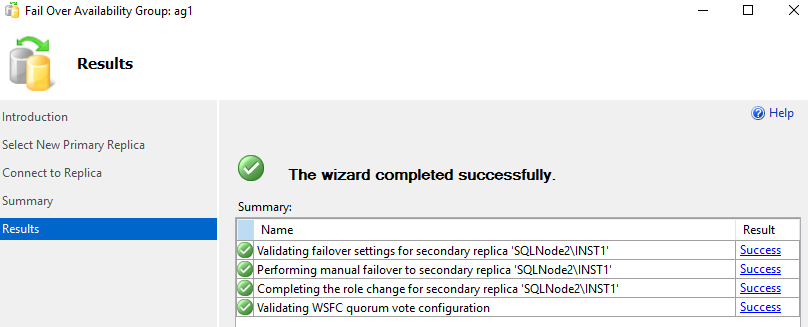
Rerun the query to check the current replica owner. Oh! Where are my distributed availability group?

Wait! Don’t worry. We have switched the distributed availability group, so the new primary replica is the SQLNode2.
Refresh the availability group in the SQLNode2, and you see the [AG1] availability group is primary on it.
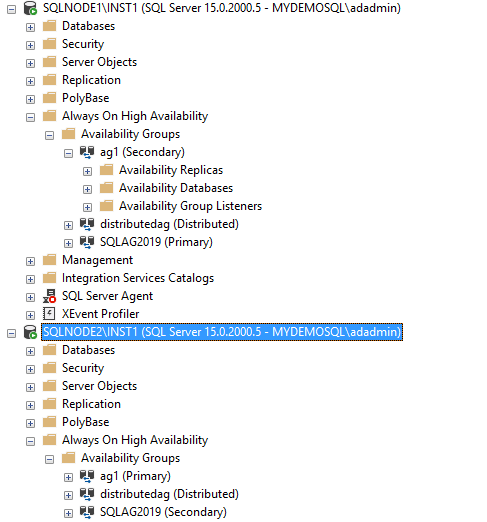
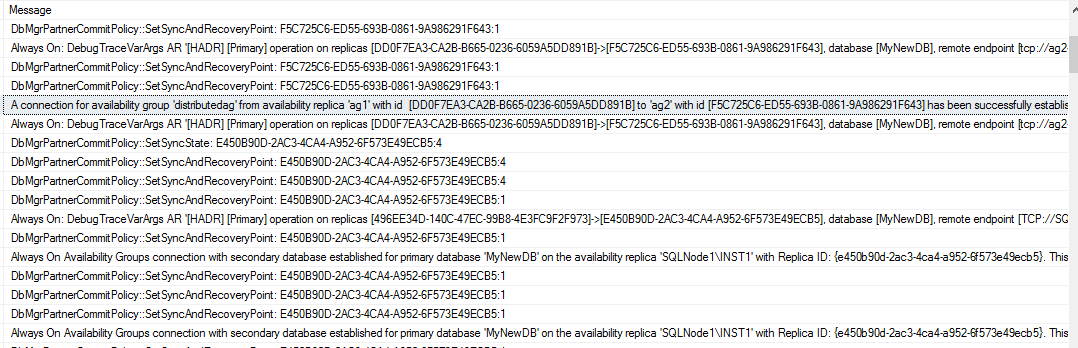
It also causes a distributed availability group to reestablish the connections from the global primary. During the failover, the transactions could not move from the global primary to the forwarder. You can see similar events in the SQL Server logs.
Conclusion
In this article, we performed failover in a distributed SQL Server Always On Availability Group and monitored its performance using dynamic management views.
Table of contents

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023