
In this article, we will review how to configure the sync group to replicate data between Azure SQL databases using Azure SQL Data Sync.
Azure SQL Data Sync is a service that is used to replicate the tables in Azure SQL database to another Azure SQL database or on-premises databases. Data can be replicated one way or bidirectional.
We will be discussing the following topics in this article:
- Creating a sync group
- Adding the member databases
- Adding the tables to the sync group
- Replicating schema changes
- Limitations of Azure SQL Data Sync service
- Consideration while using triggers on both hub and member databases
Creating a sync group
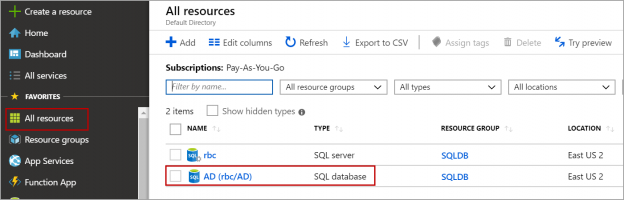
To create a sync group, Navigate to All resources page or SQL databases page and click on the database which will act as a hub database.
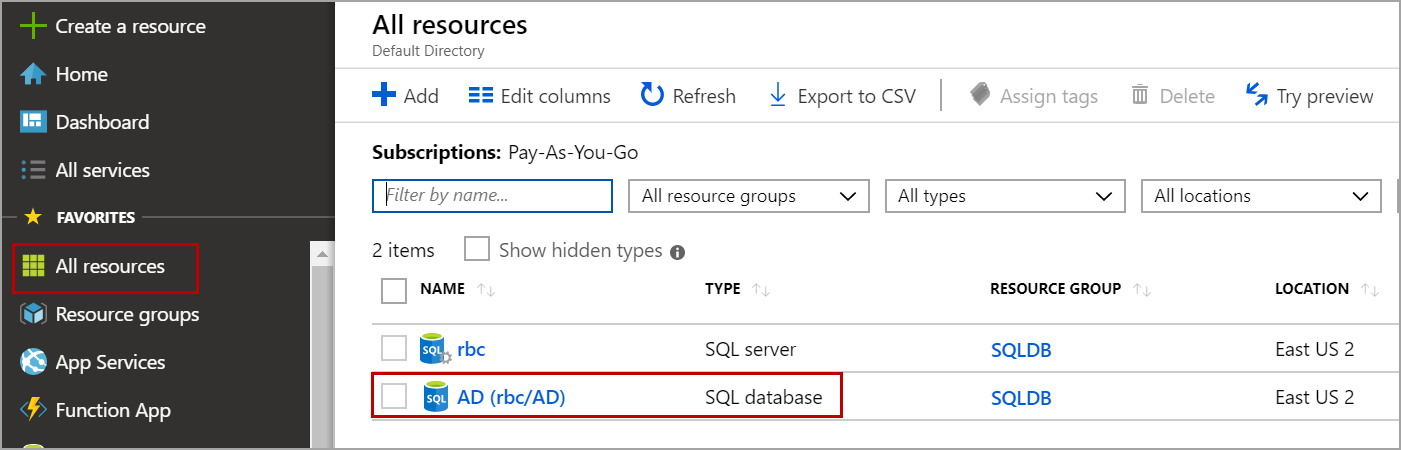
In the database details page, click on Sync to other databases and click on New Sync Group as shown in the below image.
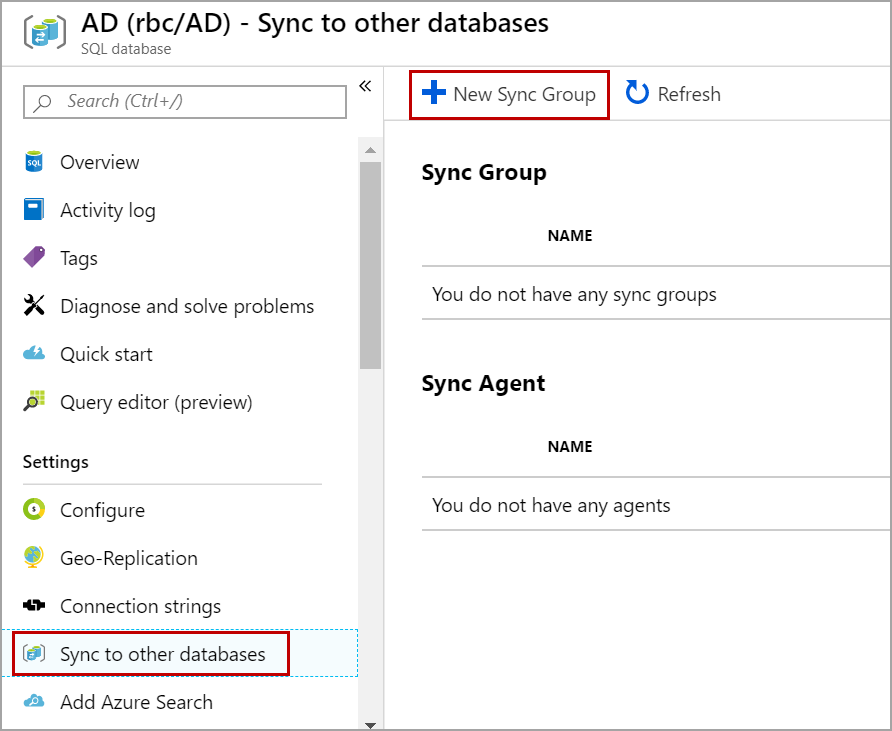
Enter the name of the sync group and choose the Sync Metadata Database. If you choose New database, then a new database is created on the server you choose with tables that store the sync information. If you choose to use an existing database, all the available databases on the server are shown in the drop-down and you must select one. The tables are created in the database you selected to store sync information. Set Automatic sync On and set the frequency to sync the data changes automatically at a specified interval.
Conflict resolution: Conflict occurs when the data is modified on the Azure SQL hub and member database within the same sync cycle. Conflict resolution helps which change needs to be persisted. We have only two options available as of now unlike in SQL Server replication. We cannot have a custom conflict resolver to resolve conflict when it occurs. If you choose Hub to win as Conflict resolution, then the change from Hub database is persisted. If you choose Member to win as conflict resolution, then the change from the member database is persisted when a conflict arises.
After selecting the conflict resolution Click Ok.
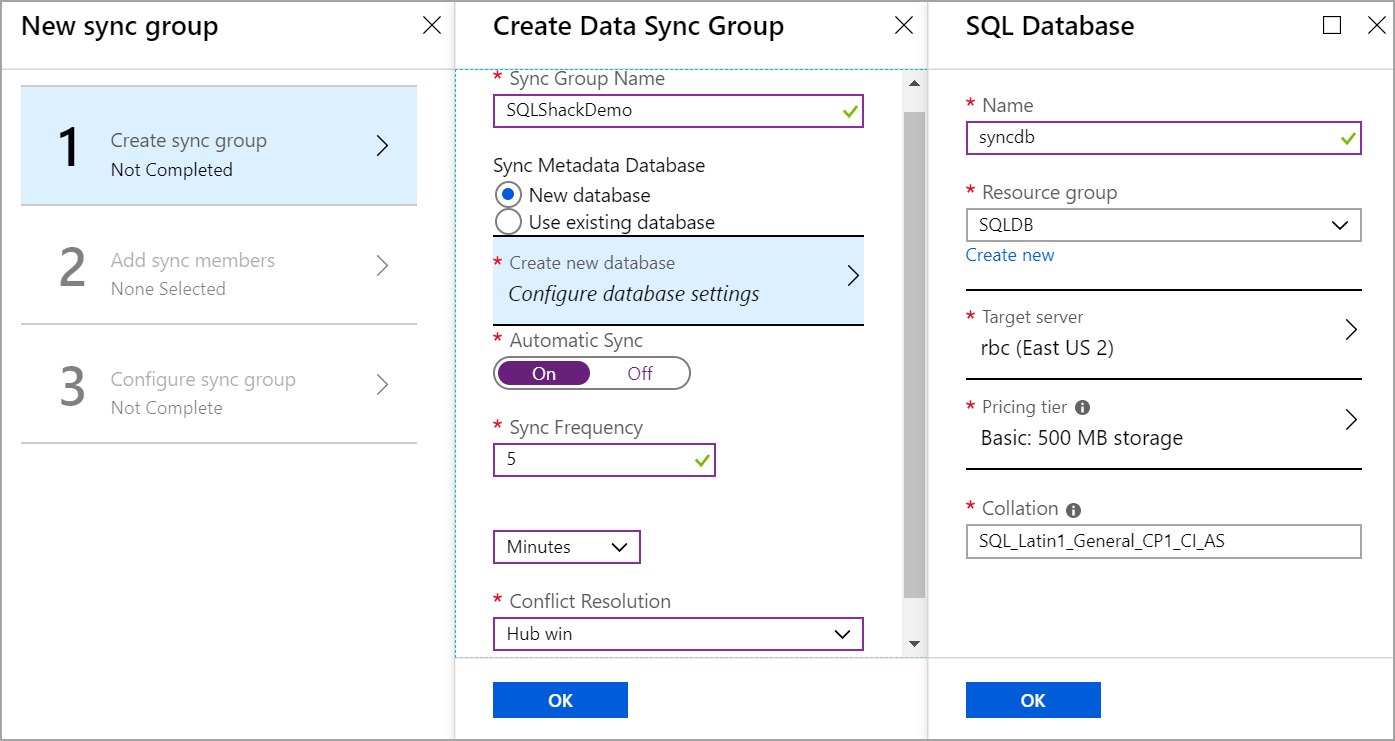
Once the sync group is created, we should add the Azure SQL database as a member of the sync group.
Adding the member database
To add a member database, Click on Add sync members. Enter the username and password of the hub database. Click on Add an Azure Database to add the Azure SQL database as a member database.
Enter the name of the sync member and select the database. there are three sync directions available.
- Bi-directional: the data changes are replicated from hub to member and member database to the hub database
- To Hub: the data changes are replicated from the member database to the Hub database which is one-way replication
- From Hub: The data changes are replicated from the Hub database to member database only which is one-way replication
Select the sync direction and enter the username, password of a member database as shown in the below image.
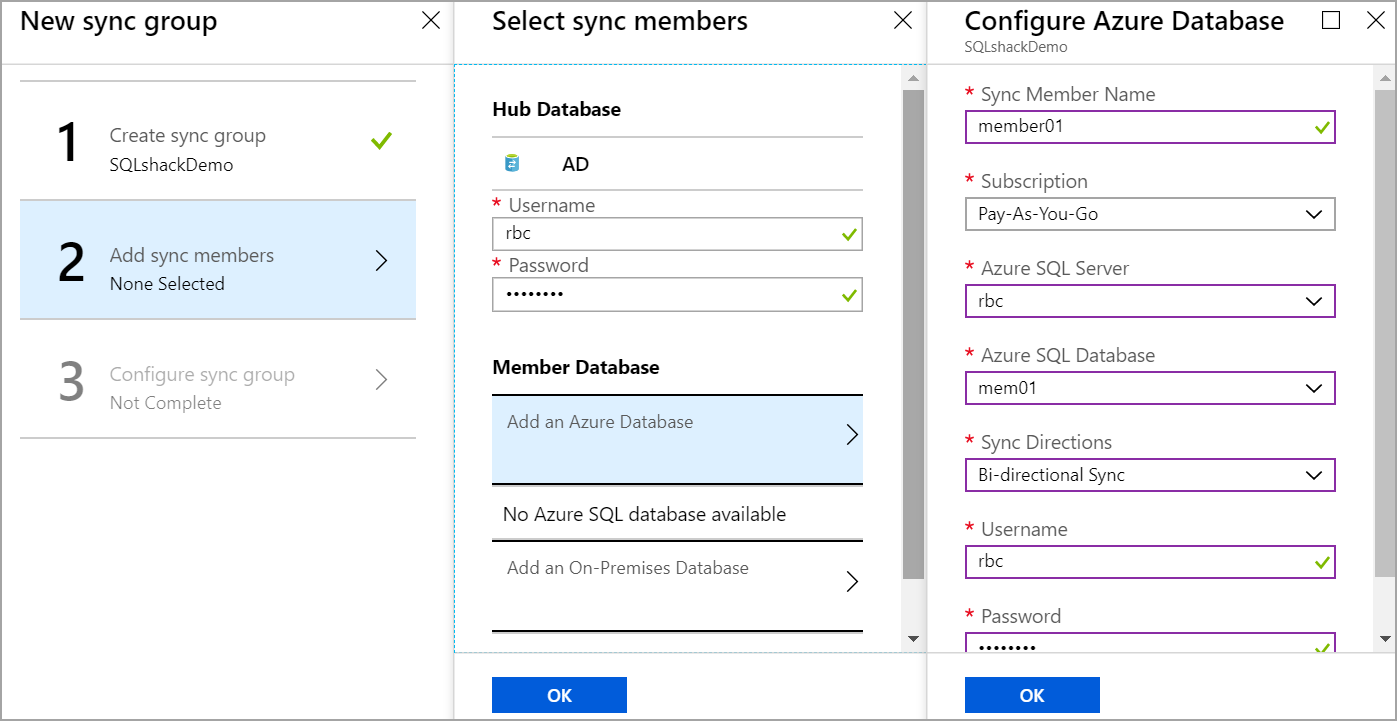
Here you can add multiple Azure SQL databases.
Adding tables to the sync group
To add the tables to a sync group, click on the configure sync group as shown in the below image and select the Hub database. Click on Refresh Schema to list the tables in the hub database. select the table you want to replicate and click on Save.
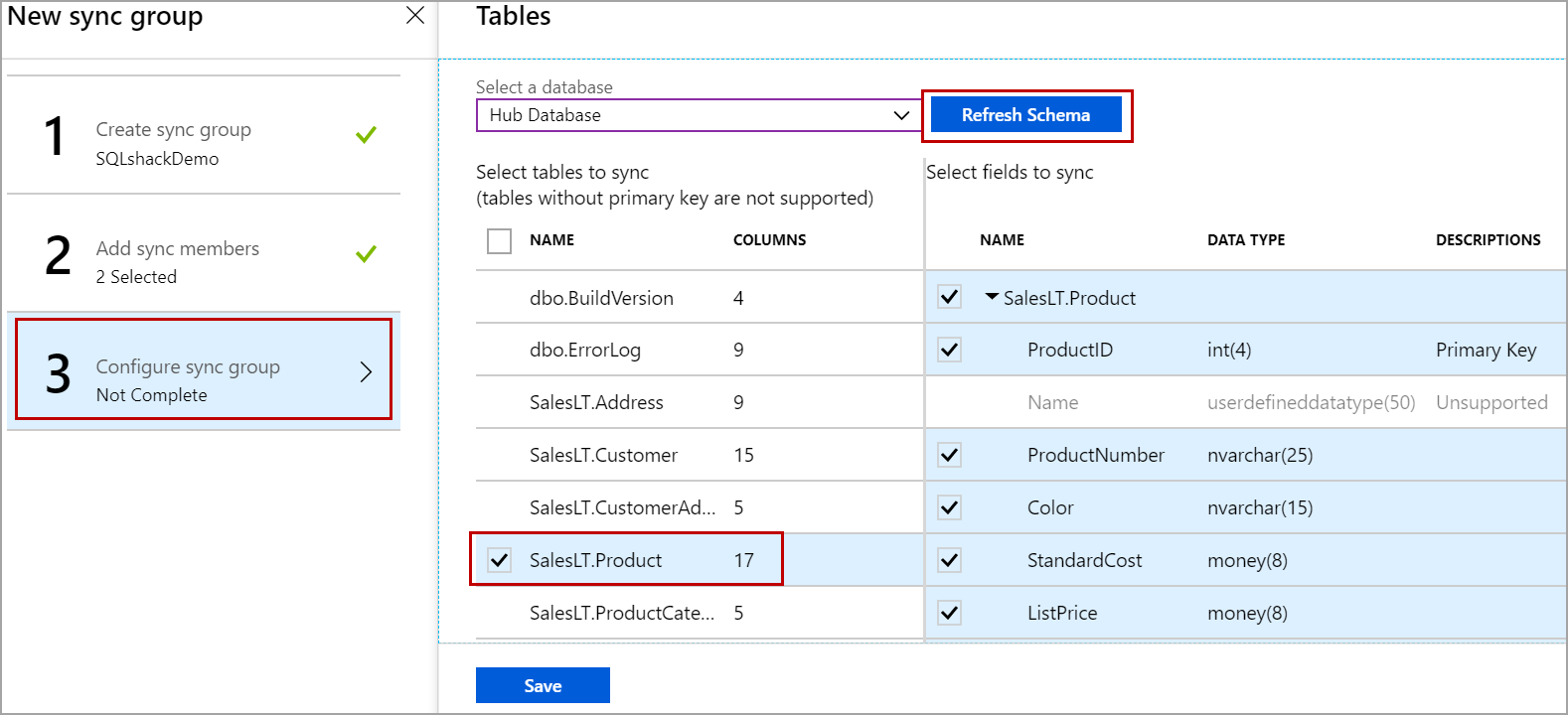
Once you click on Save, the selected tables are added to the sync group and three triggers one for insert, one for delete and one for the update are created on each table to track the data changes and insert information related to the data changes in the tracking tables. The naming convention of these tracking tables is as below.
DataSync.tablename_dss_tracking
![]()
Replicating schema changes
Currently, the Azure SQL Data Sync service supports only data sync and schema changes are not replicated to member databases. To replicate schema changes to member databases, we need to do a workaround by following the below steps.
- Create a DDL trigger to capture schema changes (DDL command) and insert into a tracking table
- Add the tracking table to sync group which replicated to all the members in the sync group
- On the member database, create a DML trigger on the tracking table and execute the DDL command
Please refer to the sample table and trigger which should be created on the Azure SQL hub database. I have added only two events for demo purposes.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
CREATE TABLE SCHEMACHANGES (ID INT identity(1,1) primary key,EVT_DATA XML,MODIFIED_BY varchar(50)) GO CREATE TRIGGER TRACK_SCHEMACHANGES ON DATABASE FOR ALTER_TABLE, CREATE_TRIGGER AS BEGIN SET NOCOUNT ON; INSERT INTO SCHEMACHANGES VALUES ( EVENTDATA(), USER ); END; GO |
Add the table to the data sync group which will replicate the data changes in the SCHEMACHANGES table to the member database.
On the member database, create a DML trigger which will get the command text from EVENTDATA and execute it on the member database. Please refer to the below sample script. You can add more error handling conditions to the trigger.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
CREATE TRIGGER [dbo].[APPLY_SCHEMACHANGES] ON [dbo].[SCHEMACHANGES] FOR INSERT AS BEGIN declare @cmd nvarchar(max), @id int DECLARE schemachanges CURSOR FOR select ID, m.c.value('.', 'nvarchar(max)') as CommandText from inserted OUTER APPLY inserted.EVT_DATA.nodes('EVENT_INSTANCE/TSQLCommand/CommandText') as m(c) OPEN schemachanges FETCH NEXT FROM schemachanges INTO @id, @cmd WHILE @@FETCH_STATUS = 0 BEGIN EXEC (@cmd) FETCH NEXT FROM schemachanges INTO @id, @cmd END CLOSE schemachanges DEALLOCATE schemachanges END GO ALTER TABLE [dbo].[SCHEMACHANGES] ENABLE TRIGGER [APPLY_SCHEMACHANGES] GO |
Limitations
- Tables with a primary key can only be replicated
- User-defined data types are not supported
- Computed columns are not supported
- Tables with identity column which is non-primary key are not supported in Azure SQL data sync
- Tables with the same name but different schema are not supported
- You must manage identity columns manually. No auto identity management like in SQL Server replication. In case if you insert a row with the same identity value on hub and master, the insert will be lost based on your conflict resolution
- Supports only data sync not the schema changes. For example, if you insert a row in member database with identity value 1 and there is an insert with same identity value on hub database, if the conflict resolution is set to member win then the row inserted at the Azure SQL hub database is deleted and row inserted at member will be persisted in both member and hub databases
- The initial sync will only create a table on the member database, not the other objects created on top of the table like triggers, foreign keys, etc.
- Continuous synchronization is not supported. The minimum sync frequency interval is 5 minutes
Considerations while using triggers on both sides
There is no keyword to identify the changes done by Azure SQL Data Sync like “NOT FOR REPLICATION” in SQL Server Replication. For example, if you have a trigger for insert on the Locations table which inserts data into Locations_History table. You added both the tables to Azure SQL data sync group and created the same trigger on Locations at member database as well to track changes done by the user and insert into Locations_History table. Please refer to the below sequence of actions.
- The user inserted a row in the Locations table which will insert a row in Locations_History table as well
- The insert in Locations and Locations_History will be replicated to the member database
- The trigger will fire again when data is synced and inserts a row in Locations_History
In this case, you may have two records in Locations_History table even though there is only one insert on Locations table in Azure SQL hub database. In such cases use a specific user for data synchronization and add a piece of code in your trigger to return without executing if the data is modified by user or you can also add a piece of code to capture the application name and return without executing the trigger if the data is modified by Azure SQL Data Sync service.
Conclusion
In this article, we explored Azure SQL Data Sync service and how to sync schema changes using Azure data sync. In case you have any questions, please feel free to ask in the comment section below.
Please refer to the SQL Azure category to learn more about Azure SQL.

- Geo Replication on Transparent Data Encryption (TDE) enabled Azure SQL databases - October 24, 2019
- Overview of the Collate SQL command - October 22, 2019
- Recover a lost SA password - September 20, 2019