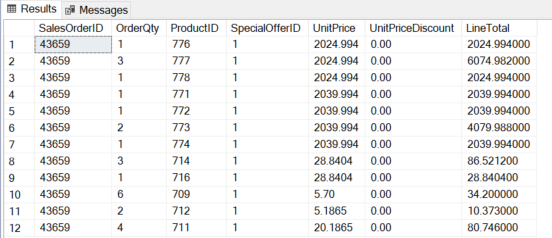
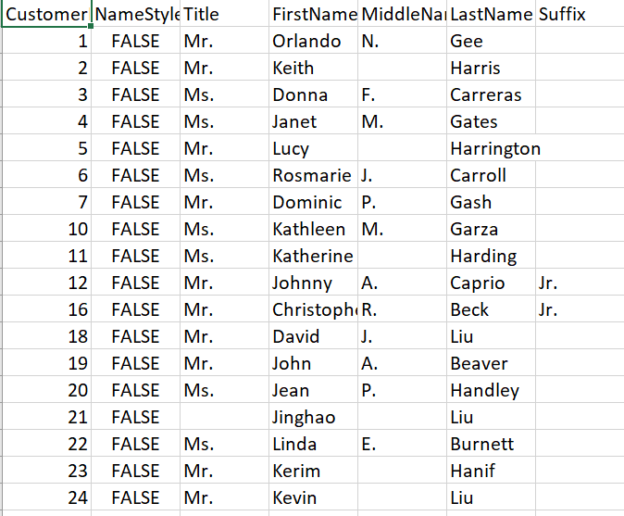
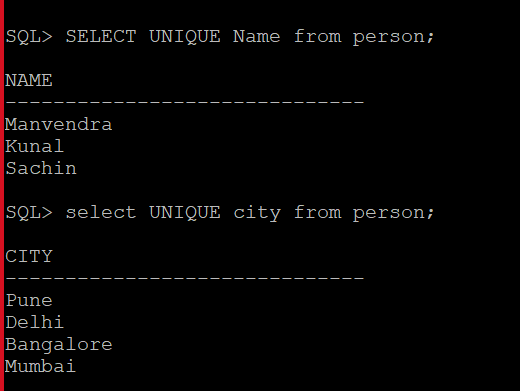
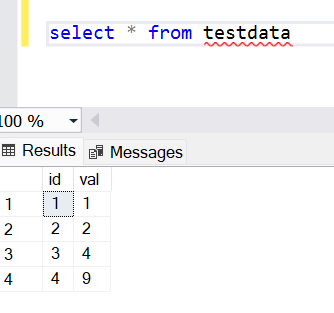
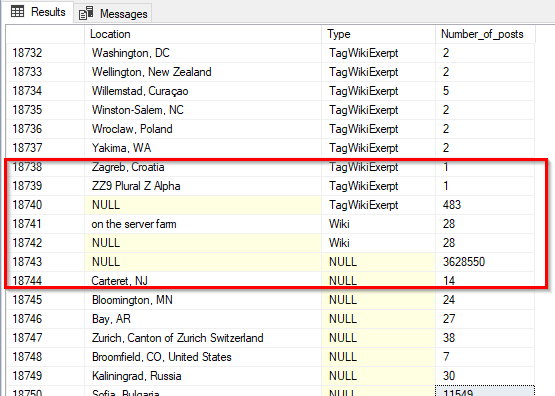
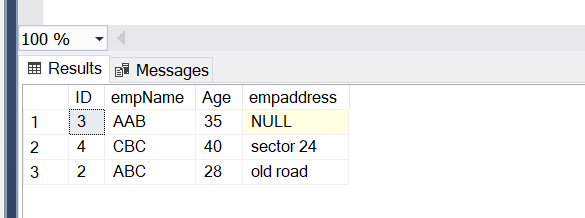
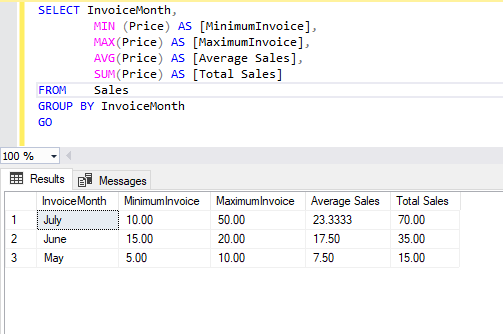
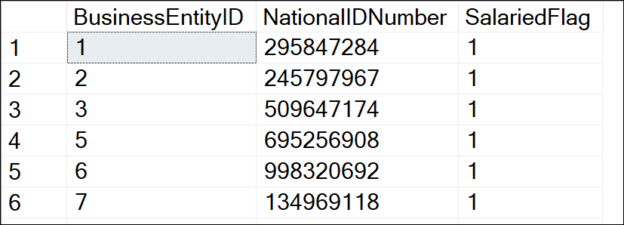
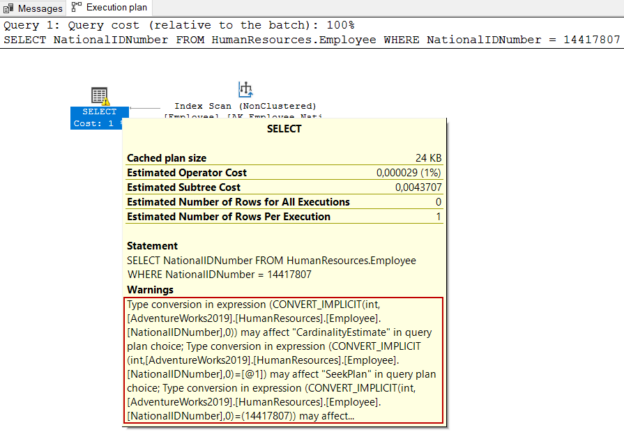
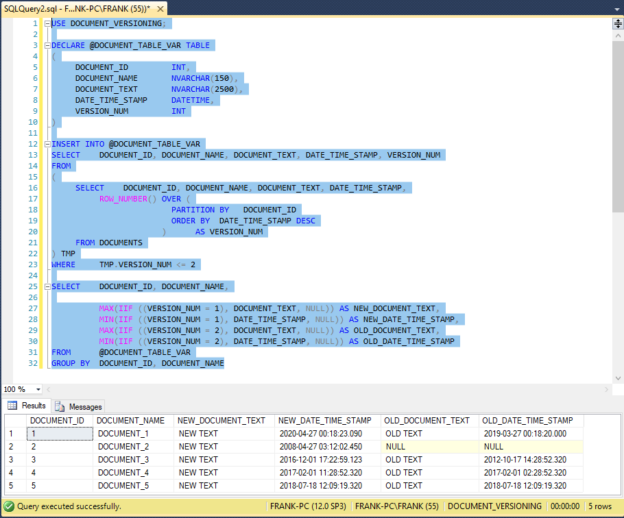
Today we will learn about the SQL IN operator. The RDBMS systems are very popular today in terms of data storage, data security, and data analysis. SQL stands for Structured Query Language which is used to create, update, or retrieve data in RDBMS or Relational Database Management Systems like SQL Server, Oracle, Microsoft Access, MySQL, and PostgreSQL.
Read more »