This article explores the Character Map Transformation in SSIS package with available configurations.
Read more »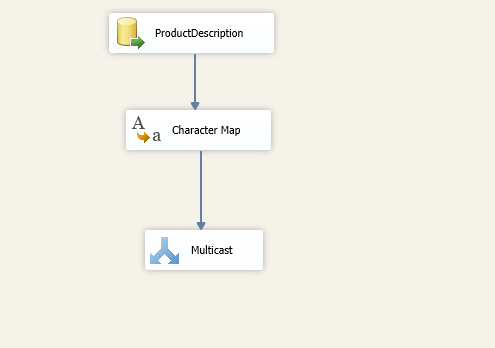

This article explores the Character Map Transformation in SSIS package with available configurations.
Read more »
This article gives an overview of SQL UPPER function and SQL LOWER function to convert the character case as uppercase and lowercase respectively.
Read more »
This article gives an overview of different editions in SQL Server and also explains the process to upgrade SQL Server editions.
Read more »
In this article, we will explore the process of SQL Delete column from an existing table. We will also understand the impact of removing a column with defined constraints and objects on it.
Read more »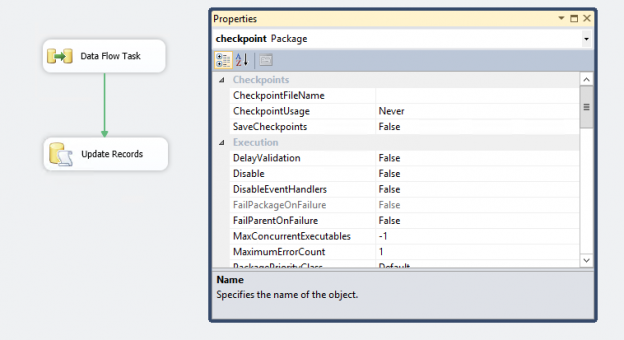
In the article, SQL Server CHECKPOINT, Lazy Writer, Eager Writer and Dirty Pages in SQL Server, we talked about the CHECKPOINT process for SQL Server databases. This article is about CHECKPOINT in SSIS package.
Read more »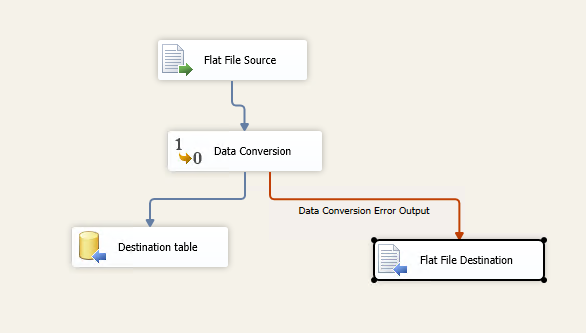
This article explains the process of configuring Error handling in SSIS package.
Read more »
This article explores the Term extraction transformation in SSIS and its usage scenario.
Read more »
This article explains the process of performing SQL delete activity for duplicate rows from a SQL table.
Read more »
We will explore Lookup Transformation in SSIS in this article for incremental data loading in SQL Server.
Read more »
Have you ever noticed SET NOCOUNT ON statement in T-SQL statements or stored procedures in SQL Server? I have seen developers not using this set statement due to not knowing it.
Read more »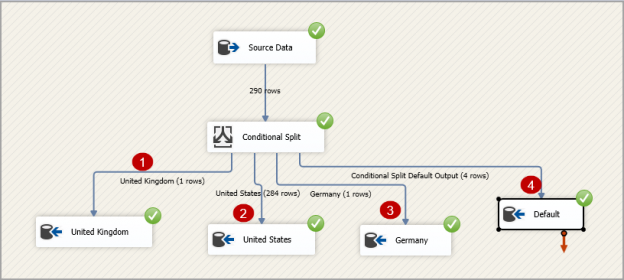
This article gives an overview of the different methods of SQL Server SSIS Package Logging.
Read more »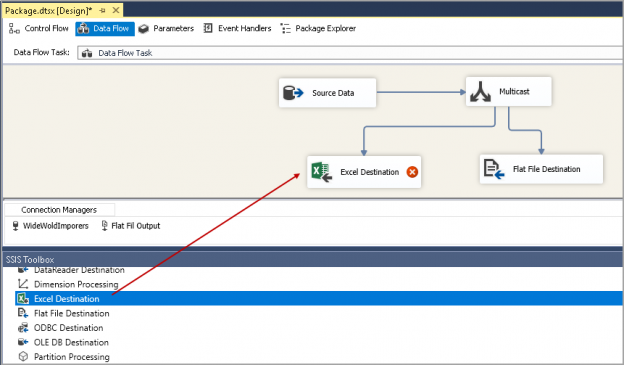
This article explores the SSIS Multicast Transformation for creating different logical copies of source data.
Read more »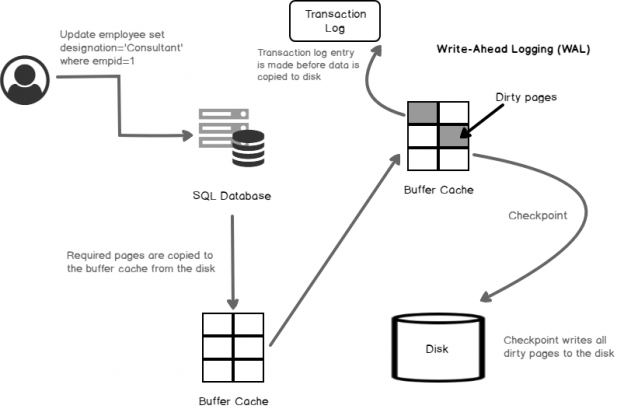
Database administrators should be aware of the internal SQL Server processes such as the dirty pages, SQL Server CHECKPOINT, Lazy writer process. This is a very common question that you might come across in SQL DBA technical interviews as well on all levels such as beginner, intermediate and expert level.
Read more »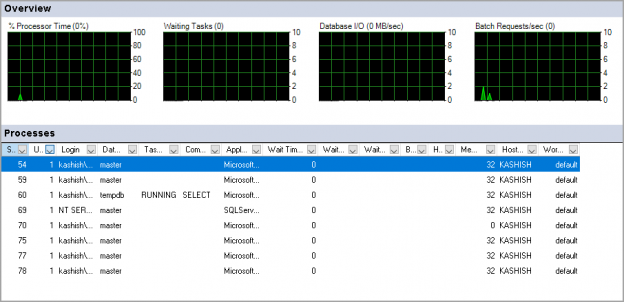
This article gives an overview of the KILL SPID command and how to monitor the rollback progress.
Read more »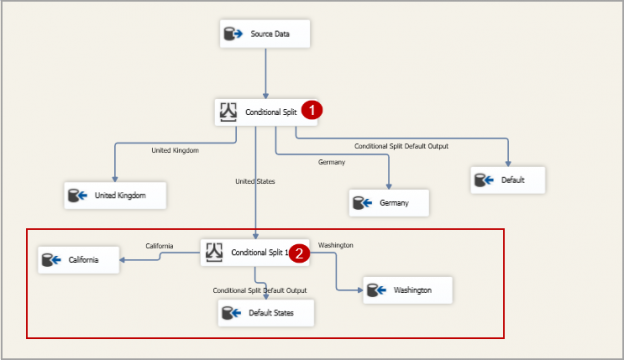
This article explores the SSIS Conditional Split Transform task to split data into multiple destinations based on the specified conditions.
Read more »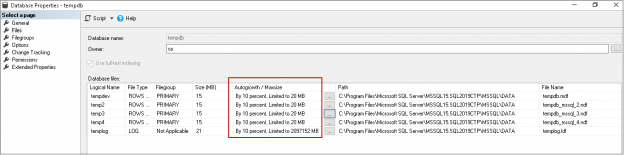
This article explores the usage of TempDB and different ways to shrink the TempDB database in SQL Server
Read more »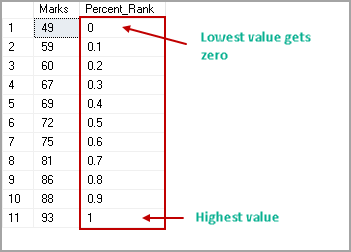
This article explores the SQL Server PERCENT_RANK analytical function to calculate SQL Percentile and its usage with various examples.
Read more »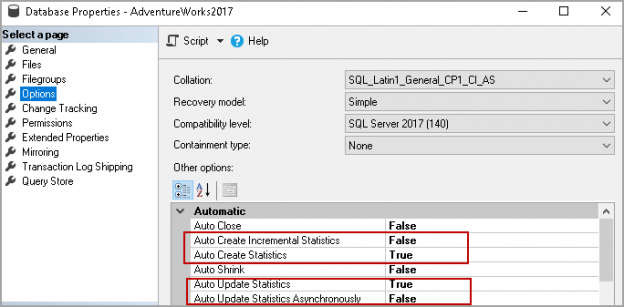
This article gives a walk-through of SQL Server Statistics and different methods to perform SQL Server Update Statistics.
Read more »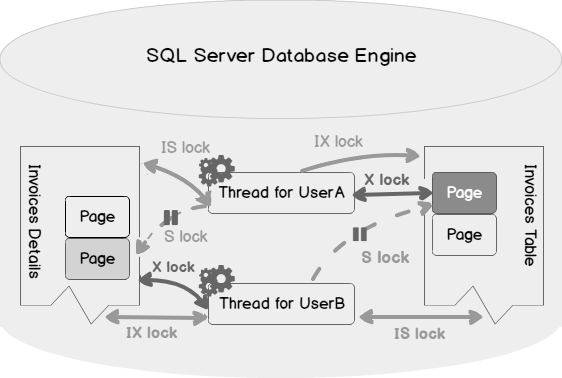
Performance monitoring is a must to do the task for a DBA. You should ensure that the database performance is optimal all the time without any impact on the databases. Performance issues act like an open stage, and you need to look at every aspect such as CPU, RAM, server performance, database performance, indexes, blocking, waits, and SQL Server deadlocks. You might face frequent deadlocks issues, and they have a direct impact on the application performance.
Read more »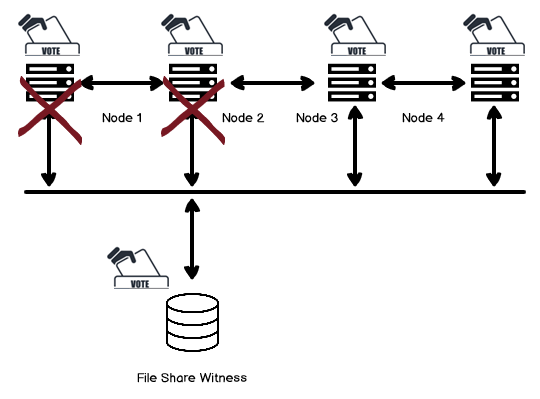
This article gives an overview of Windows Failover Cluster Quorum modes that is necessary for SQL Server Always on Availability Groups.
Read more »
This article gives an overview of the SQL STUFF function with various examples.
Read more »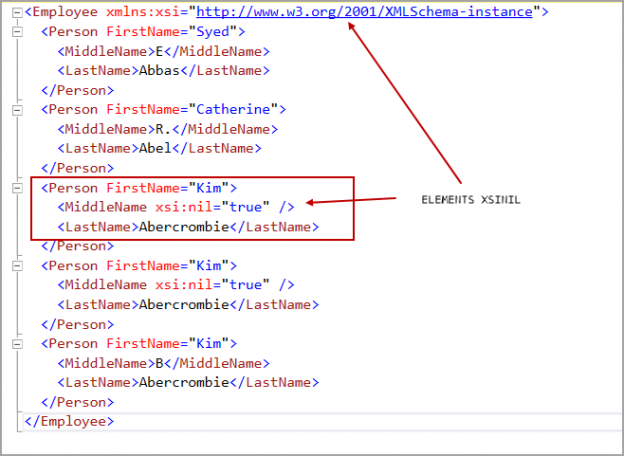
As SQL professionals, we often have to deal with XML data in our databases. This article will help you walk through several examples of using ‘FOR XML PATH’ clause in SQL Server.
Read more »
This article gives an overview of the Max Worker Threads for the SQL Server Always On Availability Group databases.
Read more »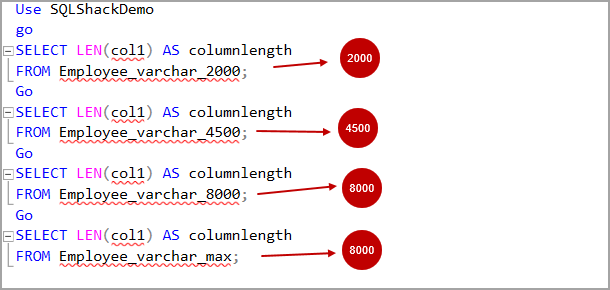
I have seen that SQL developers use varchar(max) data while designing the tables or temporary tables. We might not be sure about the data length, or we want to eliminate the string or binary truncation error.
Read more »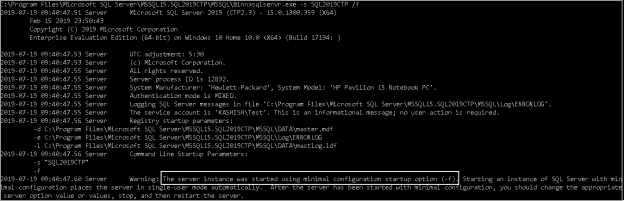
In the SQL world, it is an important activity to perform SQL Server installation for a database administrator. Have you ever noticed ‘SQL Server Startup Parameters’ for the SQL Service? You might not have noticed them, but these parameters are beneficial for DBAs.
Read more »© Quest Software Inc. ALL RIGHTS RESERVED. | GDPR | Terms of Use | Privacy