
With Microsoft SQL Server, like all Microsoft products, you will enjoy experiencing new features and enhancements to the existing ones, when a new SQL Server version is launched. These SQL Server enhancements concentrate heavily in simplifying and speeding up the data retrieval without consuming excessive resources.
SQL Server 2016 comes with a fantastic combination between two existing features, which we used to take benefits from in the previous SQL Server versions, which will lead to a big performance enhancement that we will see practically within this article. These two features are the SQL Server Clustered Columnstore index and the In-Memory OLTP. Before showing the combination performance gain, we will briefly describe each one separately.
The SQL Server Coumnstore Index
Columnstore index is a technology for storing, managing and retrieving large data using a columnar data format. Using the Columnstore technology, the data will be logically organized as tables with rows and columns, and physically in columnar data format, unlike the traditional row-store technology, in which the data will be physically stored in row-wise format.
The Columnstore technology, allows you to gain 10x query performance enhancement over the traditional row-wise technology. It also provides you with high level of data compression, with 10x data compression over the uncompressed data, reducing the storage required in your data warehouse. The Colmnstore index performance gain comes from the fact that we usually select a few columns from our table, and the columns often contain similar data, which results in high compression rate, enabling large amounts of data to be compressed in-memory. With this high compression rate, the I/O bottleneck will be minimized too. In addition to that, it helps reducing the memory footprint, allowing the SQL Server to perform more queries in memory. The new Batch-Mode query execution mechanism for the Columnstore storage format, in which SQL Server processes multiple rows at the same time in one CPU instruction, will reduce the CPU consumption too.
A Columnstore index works well for data warehousing workloads, in which full table scans and large data sets analysis is performed, by reducing the amount and size of data that will be accessed to execute the query. For example, you can take benefits from the Clustered Columnstore indexes in your data warehouse for the fact tables and large dimension tables. Non-Clustered Columnstore indexes are used mainly to perform real-time analysis on the OLTP workload type. Starting from SQL Server 2016, the Columnstore index can be used for real-time analytics on the operational workload type.
Columnstore indexes, included in the first incarnation in SQL Server 2012 Enterprise Edition, were read-only indexes, which requires dropping the index each time we need to load the data. In SQL Server 2014, Columnstore indexes are enhanced to be fully readable and writable indexes. They incude the ability to create a Clustered Columnstore index starting from that SQL Server version, enabling the index to store all the data on it, instead of being dependent on a row-wise data.
Starting with SQL Server 2016, Batch mode processing for queries is enabled, even for queries that run under a single thread. B-Tree non-Clustered indexes on a Clustered Columnstore index are supported also starting from that version. Other enhancements on the Columnstore indexes were introduced in this version such as creating a filtered non-clustered Columnstore index, with the ability to perform compression delays when the rows are moved to the Columnstore index. Real-time analytics, in which the non-clustered Columstore index is created on the top of row-based index, heap table or In_Memory optimized table, was introduced also in SQL Server 2016.
SQL Server In_Memory OLTP
The SQL Server In-Memory OLTP engine, introduced the first time in SQL Server 2014 version, enables you to move a selected tables and stored procedures into memory and query these objects with the highest performance, lowest data access latency and the new optimistic concurrency control concept. Optimistic concurrency means that, the In-Memory OLTP query processing engine will not use locking and latching concepts. Instead, it uses a high performance row versioning mechanism to control the transaction operations, with 5x to 20x faster processing, than the disk-based alternatives, as promised by Microsoft. This is because the data is read from and written directly to the memory.
Memory-Optimized tables are fully durable by default, which means that the committed transactions data will be preserved in the case of the server crashes. A second copy of the table is maintained on disk storage, for durability purposes only, such as recovering the data after restarting the server. Another durability option supported in SQL server is the Non-Durability Memory-Optimized tables, in which the data is not persisted on the disk, with no data recovery in the case of server crash or failover.
Natively Compiled stored procedures are preassembled T-SQL code that is compiled from interpreted code into native x64 code when it is created. In this way, it reduces the number of instructions that will be executed by the CPU to process this stored procedure, speeding up the query execution. A Natively Compiled stored procedure can only interact with the Memory Optimized tables. You can simply access the Memory-Optimized tables using the T-SQL commands, just like the normal disk-based tables.
In-Memory OLTP is recommended for specific transactional workloads, such as the systems that have high rate of concurrent data insertion, transactions with low-latency, intensive business logic processing, temporary tables processing and the ETL data integration jobs. In SQL Server 2016, the In-Memory OLTP engine is enhanced by removing the previous limitations such as the amount of data that can be handled, the supported T-SQL commands in addition to the collations limitation that is no longer available.
In-Memory OLTP supports three types of indexes; Hash indexes, Non-Clustered and Clustered indexes. These indexes exist in the memory storage, with no data contained in the indexes, where it only contain memory pointers to the real data rows. The indexes will be rebuilt when the database starts up again.
Also starting with SQL Server 2016, we are able to create a Clustered Columnstore index on the top of a Memory-Optimized tables, allowing us to take benefits from these two features together.
a Clustered Columnstore index on the Memory Optimized table.“
Practical example
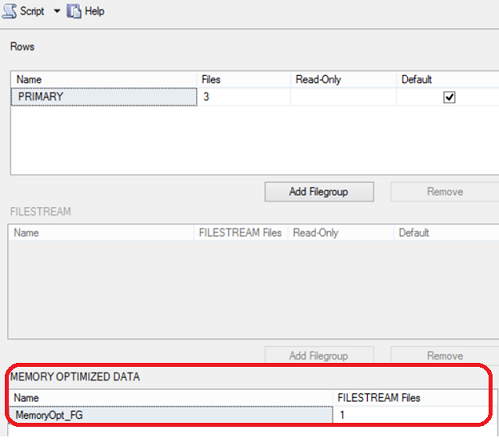
Let us start preparing for our demo to see that performance gain practically. We will start by preparing our test database, SQLShackDemo database, to host the Memory Optimized table. We will create a new filegroup that contains MEMORY_OPTIMIZED_DATA, create a database data file in that filegroup and enable the In_Memory OLTP feature on the SQLShackDemo database as follows:
|
1 2 3 4 5 6 7 8 |
USE master GO ALTER DATABASE SQLShackDemo ADD FILEGROUP MemoryOpt_FG CONTAINS MEMORY_OPTIMIZED_DATA ALTER DATABASE SQLShackDemo ADD FILE (name='MemoryOptDataDF', filename='D:\Data\MemoryOptDataDFShack') TO FILEGROUP MemoryOpt_FG ALTER DATABASE SQLShackDemo SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT=ON GO |
The created filegroup that will host the Memory Optimized Data can be found in the FileGroups tab of the database properties window, under Memory Optimized Data section as below:
Now the database is ready to host the Memory Optimized table. In this demo, we will compare the performance of three tables: disk-based table with clustered index, disk-based table with Clustered Columnstore index and finally Memory-Optimized table with Clustered Columnstore index. The below T-SQL script will create the mentioned three tables under the SQLShackDemo database:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
USE [SQLShackDemo] GO CREATE TABLE [dbo].[EmployeesWithClusteredIndex]( [EmpID] [int] NOT NULL, [EmpName] [varchar](50) NOT NULL, [EmpAddress] [varchar](50) NOT NULL, [EmpDEPID] [int] NOT NULL, [EmpBirthDay] [datetime] NULL, PRIMARY KEY CLUSTERED ( [EmpID] ASC ))ON [PRIMARY] GO CREATE TABLE [dbo].[EmployeesWithClusteredColumnstoreIndex]( [EmpID] [int] NOT NULL, [EmpName] [varchar](50) NOT NULL, [EmpAddress] [varchar](50) NOT NULL, [EmpDEPID] [int] NOT NULL, [EmpBirthDay] [datetime] NULL, INDEX Employees_CCI CLUSTERED COLUMNSTORE)ON [PRIMARY] GO CREATE TABLE [dbo].[EmployeesWithInMemoryClusteredColumnstoreIndex]( [EmpID] [int] NOT NULL CONSTRAINT PK_Employees_EmpID PRIMARY KEY NONCLUSTERED HASH (EmpID) WITH (BUCKET_COUNT = 100000), [EmpName] [varchar](50) NOT NULL, [EmpAddress] [varchar](50) NOT NULL, [EmpDEPID] [int] NOT NULL, [EmpBirthDay] [datetime] NULL, INDEX Employees_IMCCI CLUSTERED COLUMNSTORE ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA) GO |
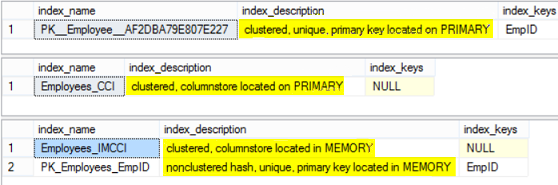
The three tables are created successfully. We will use the sp_helpindex to check the indexes created under these three tables and the description for these indexes:
|
1 2 3 4 5 6 7 8 |
EXEC SP_helpIndex '[EmployeesWithClusteredIndex]' GO EXEC SP_helpIndex '[EmployeesWithClusteredColumnstoreIndex]' GO EXEC SP_helpIndex '[EmployeesWithInMemoryClusteredColumnstoreIndex]' GO |
The result for the previous script will show us, the Clustered index created on the disk-based table, the Clustered Columnstore index created on the disk-based table and finally the Clustered Columnstore index and non-clustered hash index created on the Memory-Optimized table:
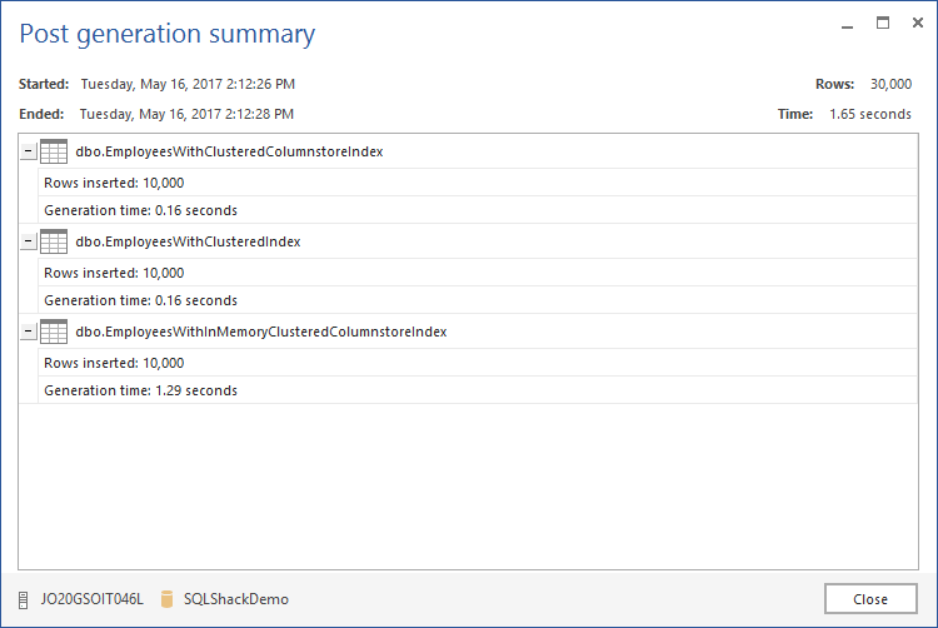
To perform a fair and meaningful test, we will fill the three tables with random 10,000 records of data using ApexSQL Generate, a SQL Server test data generation tool. The 30,000 records are inserted quickly in 1.65 seconds as follow:
We are ready now to start the test. We will enable the Time and IO statistics, enable the Actual Execution Plan and run the below SELECT query on the three tables with the same conditions:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
SET STATISTICS TIME ON SET STATISTICS IO ON SELECT [EmpName], [EmpAddress],[EmpBirthDay] FROM [EmployeesWithClusteredIndex] WHERE [EmpID]> 174 AND [EmpName] LIKE '%Sany%' GO SELECT [EmpName], [EmpAddress],[EmpBirthDay] FROM [EmployeesWithClusteredColumnstoreIndex] WHERE [EmpID]> 174 AND [EmpName] LIKE '%Sany%' GO SELECT [EmpName], [EmpAddress],[EmpBirthDay] FROM [EmployeesWithInMemoryClusteredColumnstoreIndex] WHERE [EmpID]> 174 AND [EmpName] LIKE '%Sany%' GO SET STATISTICS TIME OFF SET STATISTICS IO OFF |
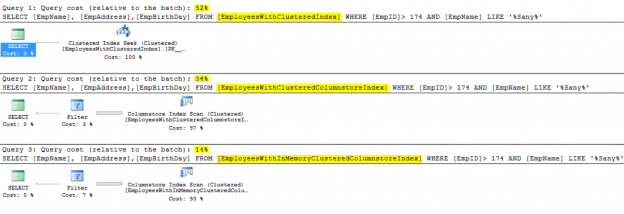
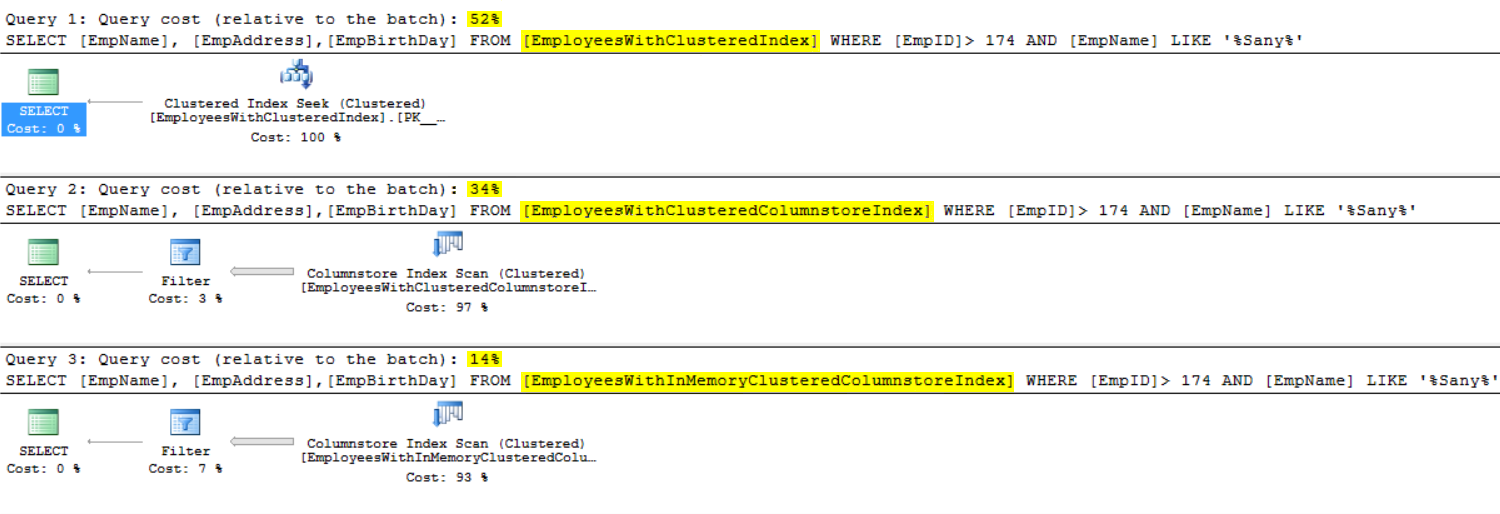
It is clear from the below execution plan, that the disk-based table with Clustered index has the heaviest weight comparing to the other tables. And that the Memory-Optimized table with Clustered Columnstore index is 2.5 times better than disk-based table with the Clustered Columnstore index. The credit of the Clustered Columnstore index over the normal Clustered index in the disk-based table is about 1.5x gain:
Also the I/O statistics show us that there is no logical I/O performed on the table when querying the Memory-Optimized table with Clustered Columnstore, as the table is in the memory. Again, the performance gain of the Clustered Columnstore index over the normal Clustered index in the disk-based table from the IO aspect is about 1.4x:

The last aspect for our performance comparison is the query execution time. From the result below, the time required to retrieve the data from the Memory-Optimized table with Clustered Columnstore is negligible, comparing to the time required to retrieve the data from the other two tables. The credit of the Clustered Columnstore index over the normal Clustered index in the disk-based table is clear from the CPU time side, with is about 2x gain:

You can imagine from the previous results, the performance enhancement that you will gain from adding the Clustered Columnstore index to the Memory-Optimized table from all aspects.
Limitations
Like any other new feature, creating Clustered Columnstore indexes over the Memory-Optimized tables has limitations and restrictions. When creating a Clustered Columnstore index on a Memory-Optimized table, the durability of that table should be SCHEMA-AND-DATA. If you try to create the below Clustered Columnstore index on a Memory-Optimized table with SHEMA_ONLY durability:
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE TABLE [dbo].[MemoryOptimizedWithColumnStore]( [EmpID] [int] NOT NULL CONSTRAINT PK_Employs_EmpID PRIMARY KEY NONCLUSTERED HASH (EmpID) WITH (BUCKET_COUNT = 100000), [EmpName] [varchar](50) NOT NULL, [EmpAddress] [varchar](50) NOT NULL, [EmpDEPID] [int] NOT NULL, [EmpBirthDay] [datetime] NULL, INDEX Employs_IMCCI CLUSTERED COLUMNSTORE ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY) GO |
The Creation statement will fail, showing that this durability is not allowed for the Columnstore index as follows:

Unlike disk-based tables, adding a Clustered Columnstore index to a Memory-Optimized table will not allow you to use ALTER TABLE statement to change the table schema.
Assume we create the below Memory-Optimized table:
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE TABLE [dbo].[MemoryOptimizedWithColumnStore]( [EmpID] [int] NOT NULL CONSTRAINT PK_Employs_EmpID PRIMARY KEY NONCLUSTERED HASH (EmpID) WITH (BUCKET_COUNT = 100000), [EmpName] [varchar](50) NOT NULL, [EmpAddress] [varchar](50) NOT NULL, [EmpDEPID] [int] NOT NULL, [EmpBirthDay] [datetime] NULL, INDEX Employs_IMCCI CLUSTERED COLUMNSTORE ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA) GO |
Then try to add a new column to that Memory-Optimized table:
|
1 2 3 |
ALTER TABLE [MemoryOptimizedWithColumnStore] ADD EmpEmail [varchar](50) NULL; |
The ALTER statement will fail, showing that it is not supported for the Clustered Columnstore index over a Memory-Optimized table as follows:

Another limitation is that a Clustered Columnstore index can’t be created on a Memory-Optimized table that has off-row columns. Columns that do not fit in the 8060 byte row size limit are called off-row. If you try to create the below Memory-Optimized table with Clustered Columnstore index, but with VARCHAR(8000) columns:
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE TABLE [dbo].[EmployeesWithInMemoryClusteredColumnstoreIndex_OffRow]( [EmpID] [int] NOT NULL CONSTRAINT PK_Employees_EmpIDRF PRIMARY KEY NONCLUSTERED HASH (EmpID) WITH (BUCKET_COUNT = 100000), [EmpName] [varchar](8000) NOT NULL, [EmpAddress] [varchar](8000) NOT NULL, [EmpDEPID] [int] NOT NULL, [EmpBirthDay] [datetime] NULL, INDEX Employees_IMCCIRF CLUSTERED COLUMNSTORE ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA) GO |
The CREATE statement will fail, showing that the field size exceeds the 8060 limit. Therefore, you need to reduce the filed size to fit that limit:

Conclusion
SQL Server consistently surprises us with new features and enhancements to the already existing ones. And with SQL Server 2016, we have a very useful enhancement resulting from combining two great features in the previous SQL Server versions; Clustered Columnstore Indexes and Memory-optimized tables. You can imagine the combination performance gain and how we will benefit from leveraging these capabilities. In this article, we described briefly these two features separately and how can we combine them together practically. In addition, we listed the limitations for this combination in practical terms. Now all that is left is to start using it!

He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers - February 11, 2021
- How to monitor Azure Data Factory - January 15, 2021
- Using Source Control in Azure Data Factory - January 12, 2021