
This article helps you learn the AWS Redshift cluster pricing model, as well as options to pause and resume cluster on-demand and on-schedule.
One of the motivations for migrating from on-premises to cloud-hosted models like Infrastructure as a Service, Platform as a Service or Software as a Service is cost savings due to reduced infrastructure management and related administrative tasks or resources required to keep the solution functional. One of the factors that enables saving costs on the cloud is the pricing model. Generally, for most of the cloud-based services, there is no upfront cost or long-term commitment and service is charged as per the use. Considering this in the database world, the charges vary on factors like instance-size, features enabled, multi availability zone deployment, storage volumes etc. One factor that is common across any database is the time or duration for which the database was used. Once the resources or instance is terminated and/or stopped, then the charges no longer apply. This pricing model makes it necessary to scale down, stop or terminate (whichever applicable) the resources and instances once they are not in use. This would require the ability to perform the action ad-hoc as well as in a scheduled manner.
AWS Redshift is one of the most popular and heavily used data services for petabyte-scale data warehousing. Considering the high volume of data it can accommodate, the number of nodes in a cluster tend to be high, which translates into higher costs as well, and requires cost-optimization. Typically, in an SDLC environment, there are different AWS Redshift clusters by environments like Dev, Stage, Test and Production, where each environment has at least one or more AWS Redshift clusters housing different volumes of data. Production grade clusters may be required to operate 24 x 7, but development and other lower environment do not require the cluster to operate full time. Ideally, if feasible, one should terminate the cluster and restore it from snapshots once the cluster is required. At times, terminating the cluster and restoring it frequently may be too much of a hassle and may not be worth the effort. In such cases, one may want to pause the cluster which will not eradicate the cost, but at least reduce the costs. In this article, we will learn different options to pause and resume the AWS Redshift cluster and discuss how it will translate into cost savings.
AWS Redshift Cost Structure
The pricing model of AWS Redshift is very straight-forward. Depending on the type of node instance used to build the cluster, on-demand nodes are priced per hour of usage with billing per-second. If the cluster is stopped the compute billing gets stopped and only the storage charge applies. More about the cost savings can be read from here.
Pause and Resume AWS Redshift Clusters
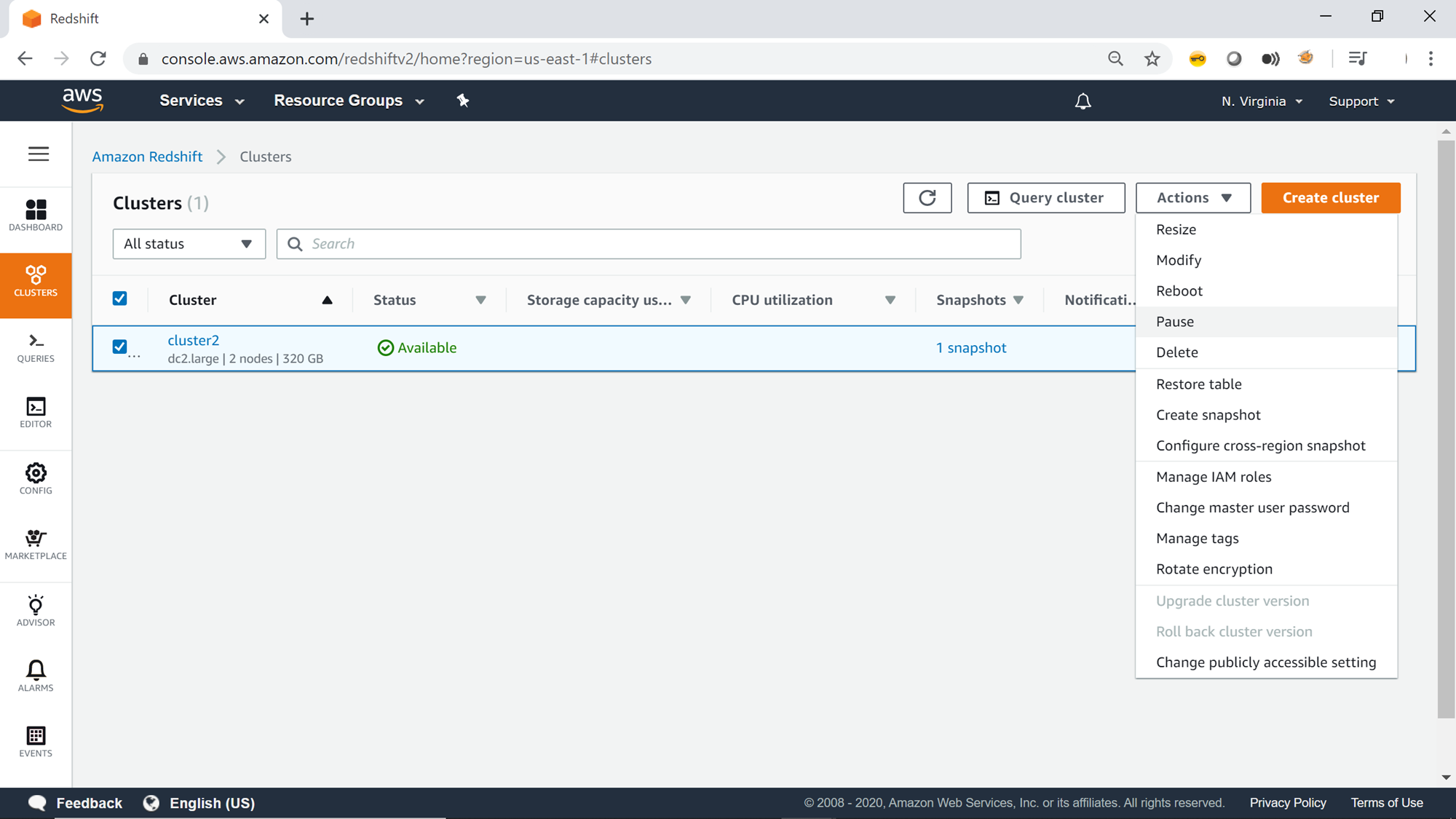
Let’s start the exercise in which we would look at different options to pause and resume clusters. It’s assumed that an AWS Redshift cluster is already in place. Beginners can refer to this article, Getting started with AWS Redshift, to learn how to create a new AWS Redshift cluster. Navigate to the clusters list by clicking on the Clusters menu item from the left pane. Select your cluster and click on the Actions menu, and you would find the Pause option as shown below. Click on the Pause button to see what options we get to pause the cluster.
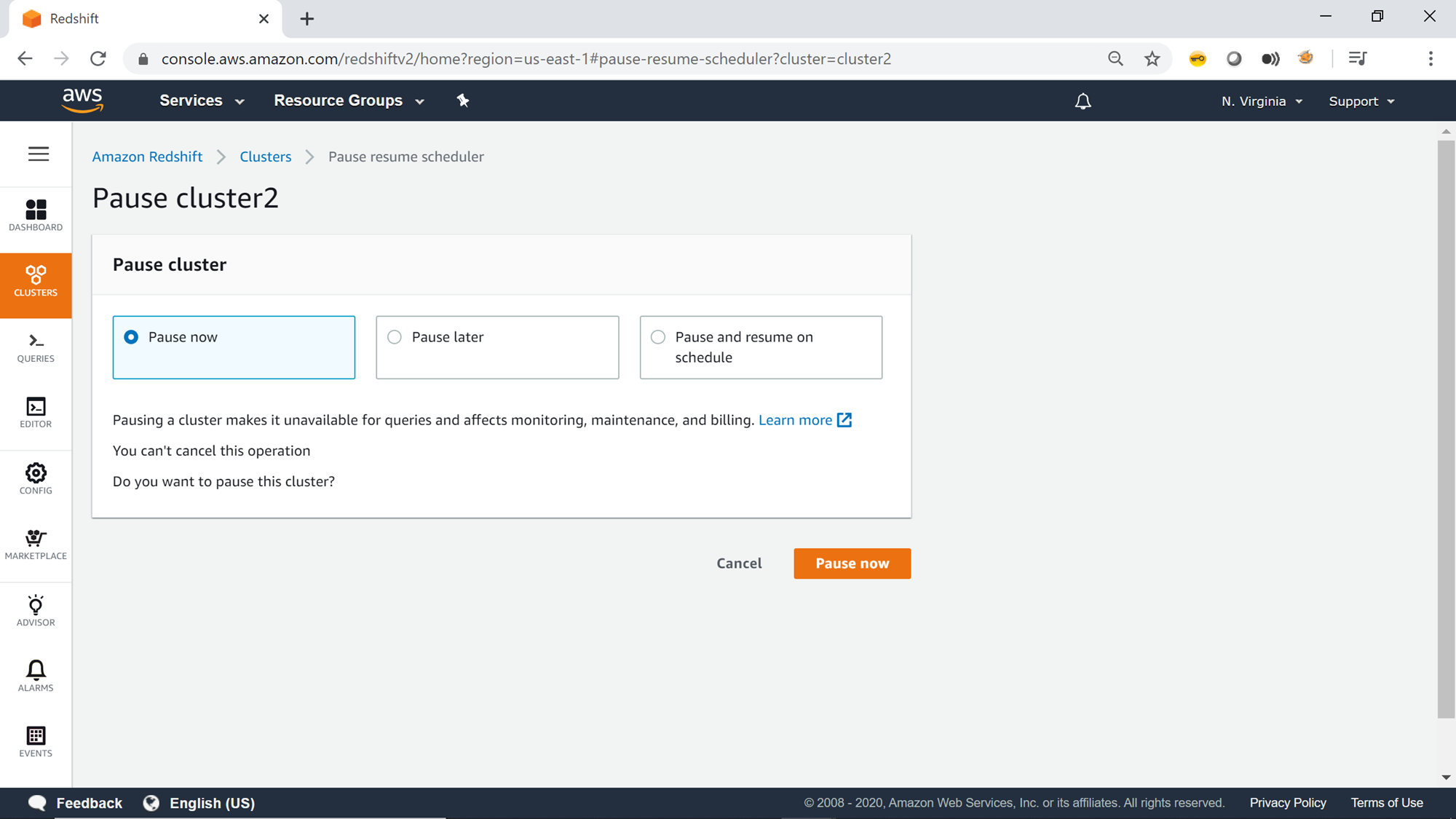
On clicking the Pause menu item, a new page will appear with different pause options as shown below. There are three options to pause the cluster – Pause Now, Pause Later and Pause and resume on schedule.
-
The Pause now option is useful when you want to pause the cluster ad-hoc for an unplanned pause of the cluster. Pausing of the cluster would make the cluster unavailable, the cluster cannot queries and certain parts of cluster monitoring will also pause.

-
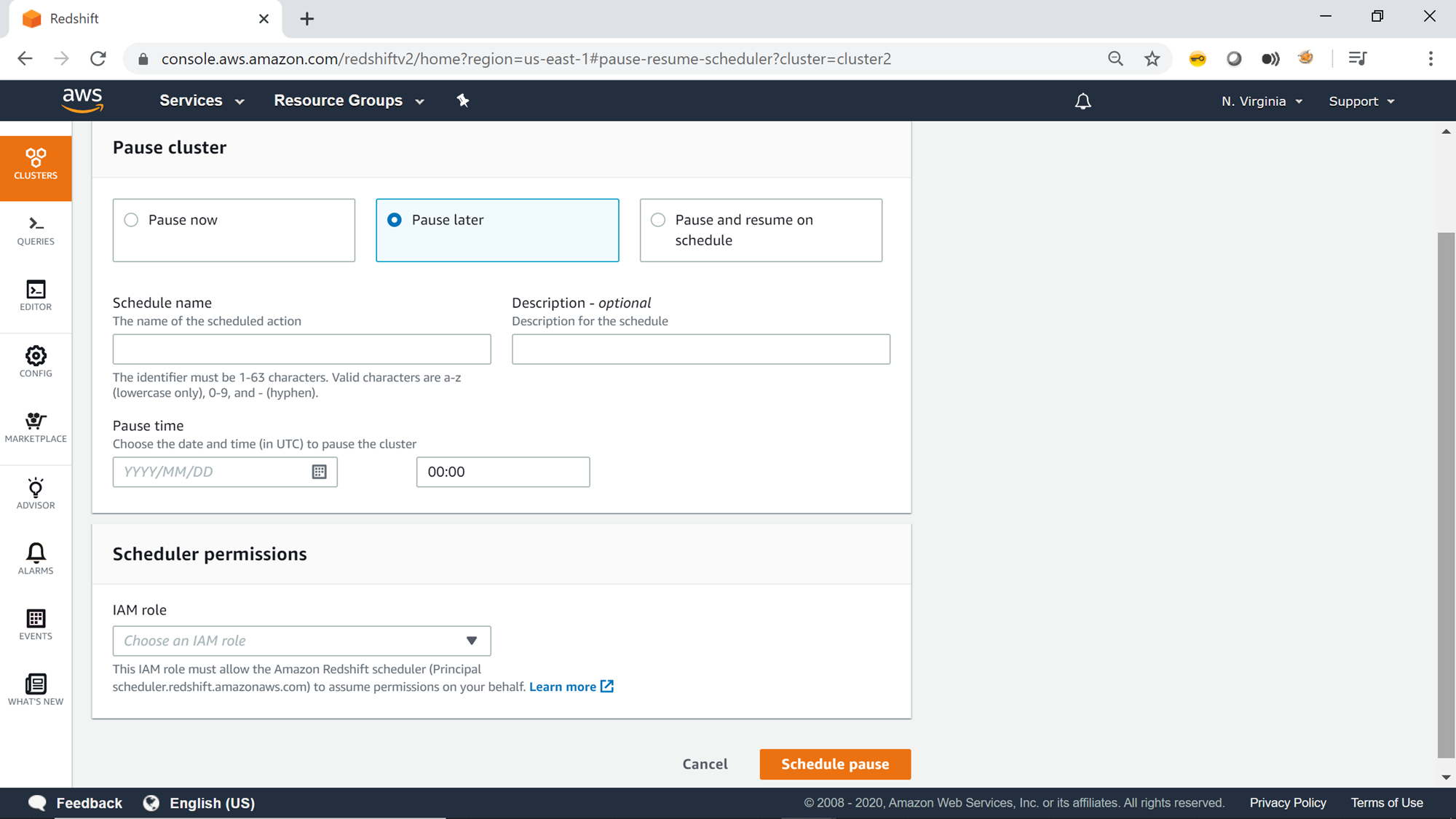
The next pause option is Pause later. This option provides the ability to pause the cluster on a schedule. To schedule, provide a schedule name, an optional description, a pause start-date and time. The key thing to note here is that there’s no end time, and it’s just related to pausing of the cluster on the schedule. You may have to resume to cluster manually or on a schedule separately.
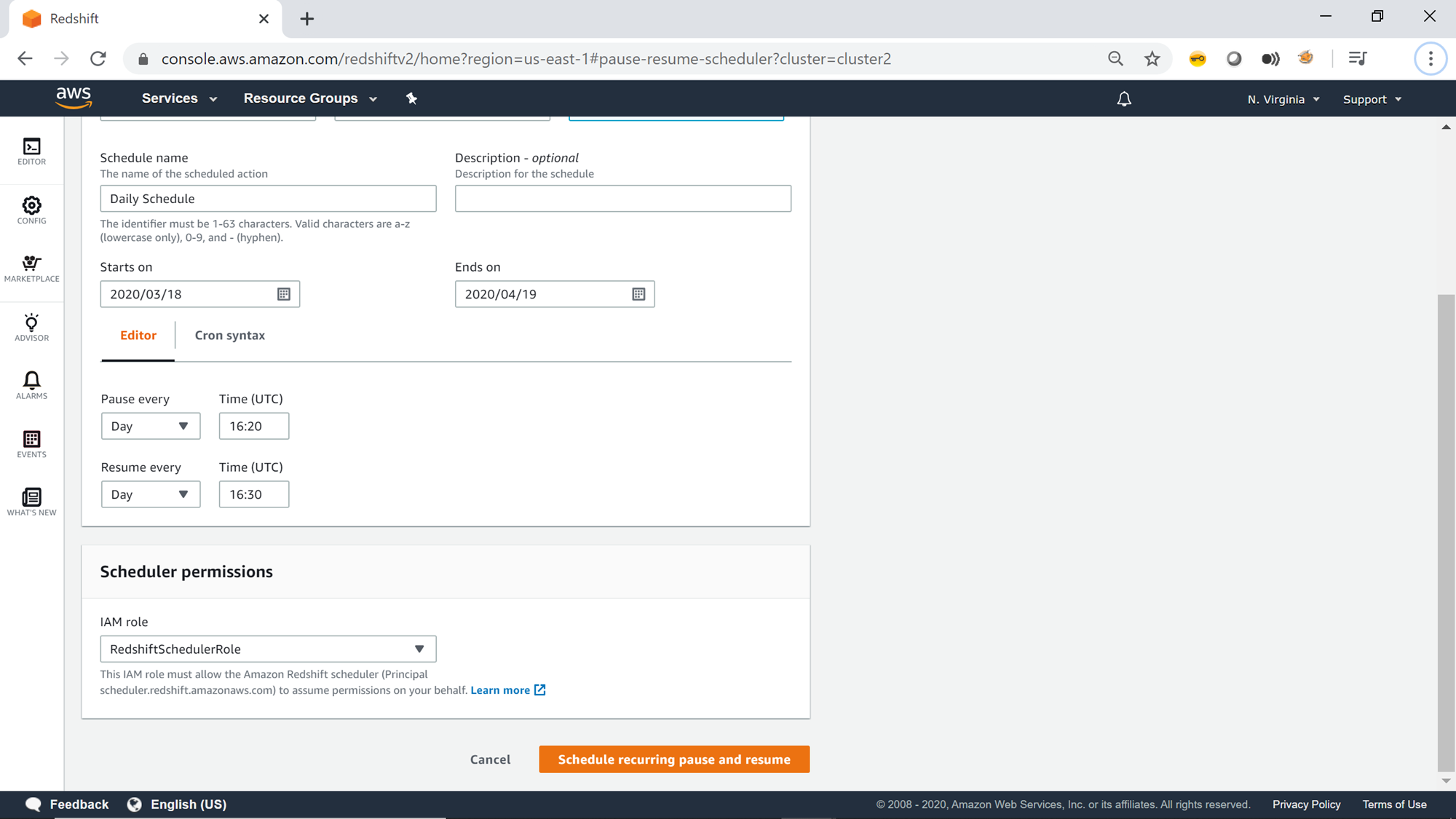
Next, the scheduler requires the IAM role which has the required permission to administer the redshift cluster to pause it. Once you have provided the IAM role, you can click on the Schedule pause button to pause the cluster.
-
The third option is to Pause and resume on schedule as shown below. This option like the previous option requires providing schedule related details. The difference in this option is that we need to provide an end-time as well. This end-time would signal the start of resuming the cluster. The editor interface provides options to configure the frequency of the schedule at the desired frequency – like on certain days, weekly, monthly etc. The time is in UTC format, so before specifying the time, consider converting it into UTC format.
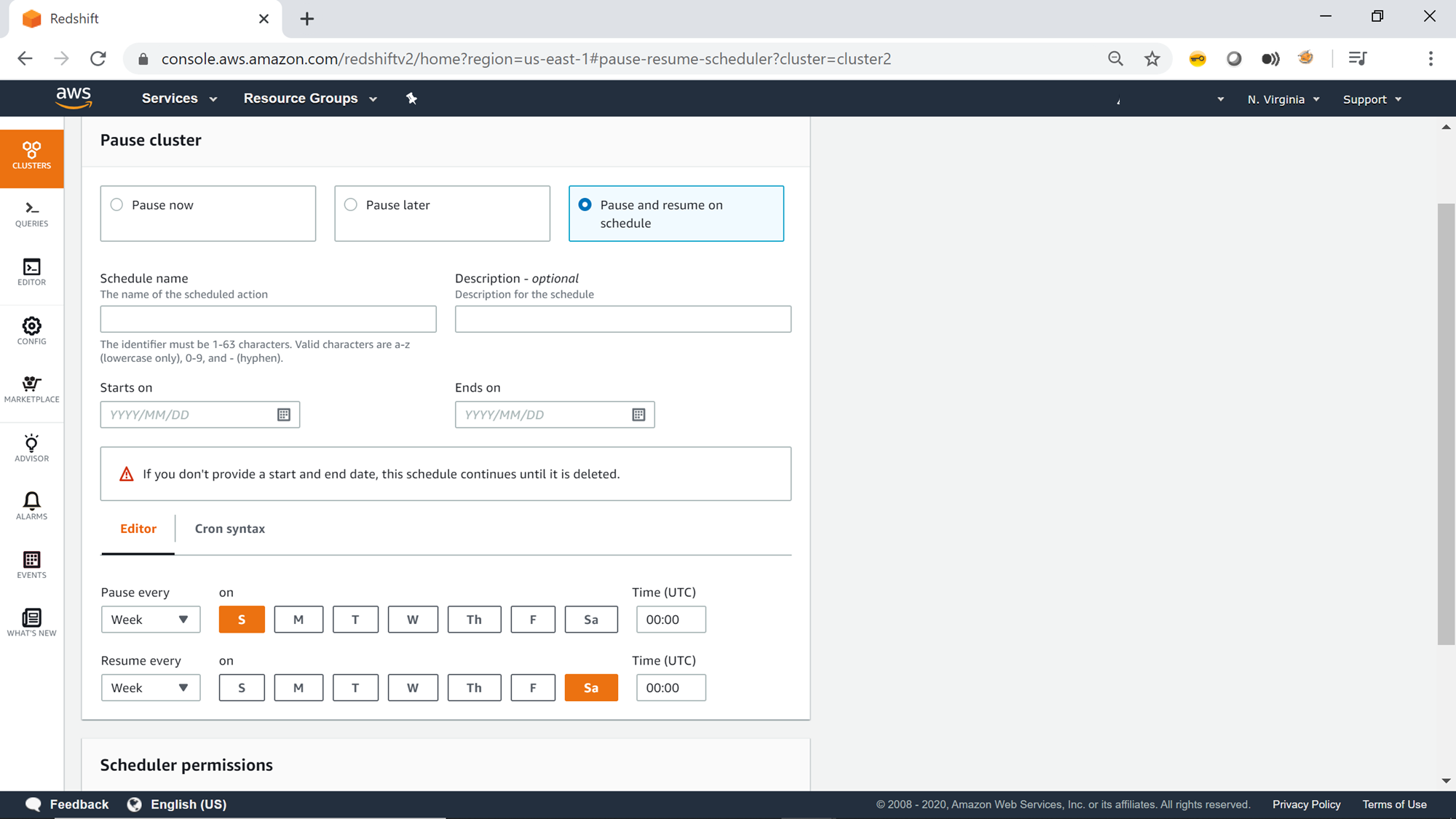
The next step is to schedule an IAM role that has the required permissions. Provide all the details and then move to the next step.
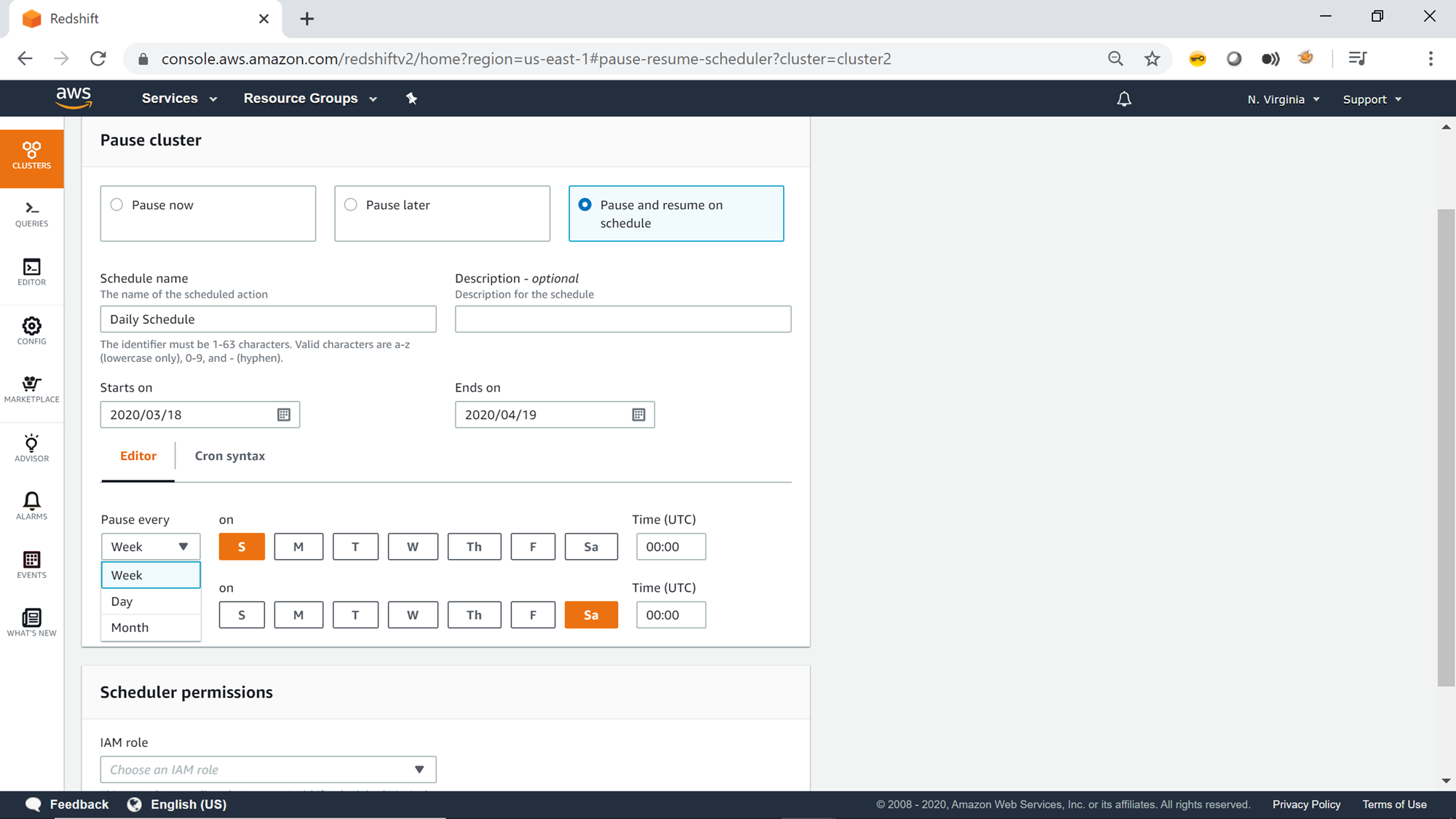
One can also specify criteria in the cron syntax to programmatically evaluate the time when the cluster should be paused and resumed. Let’s say we intend to start and stop the cluster daily at a scheduled time as shown below. This can be typically the case for development teams, when you need the cluster to be available during the working hours and paused during non-working hours. Once the schedule is configured click on the Schedule recurring pause and resume button.
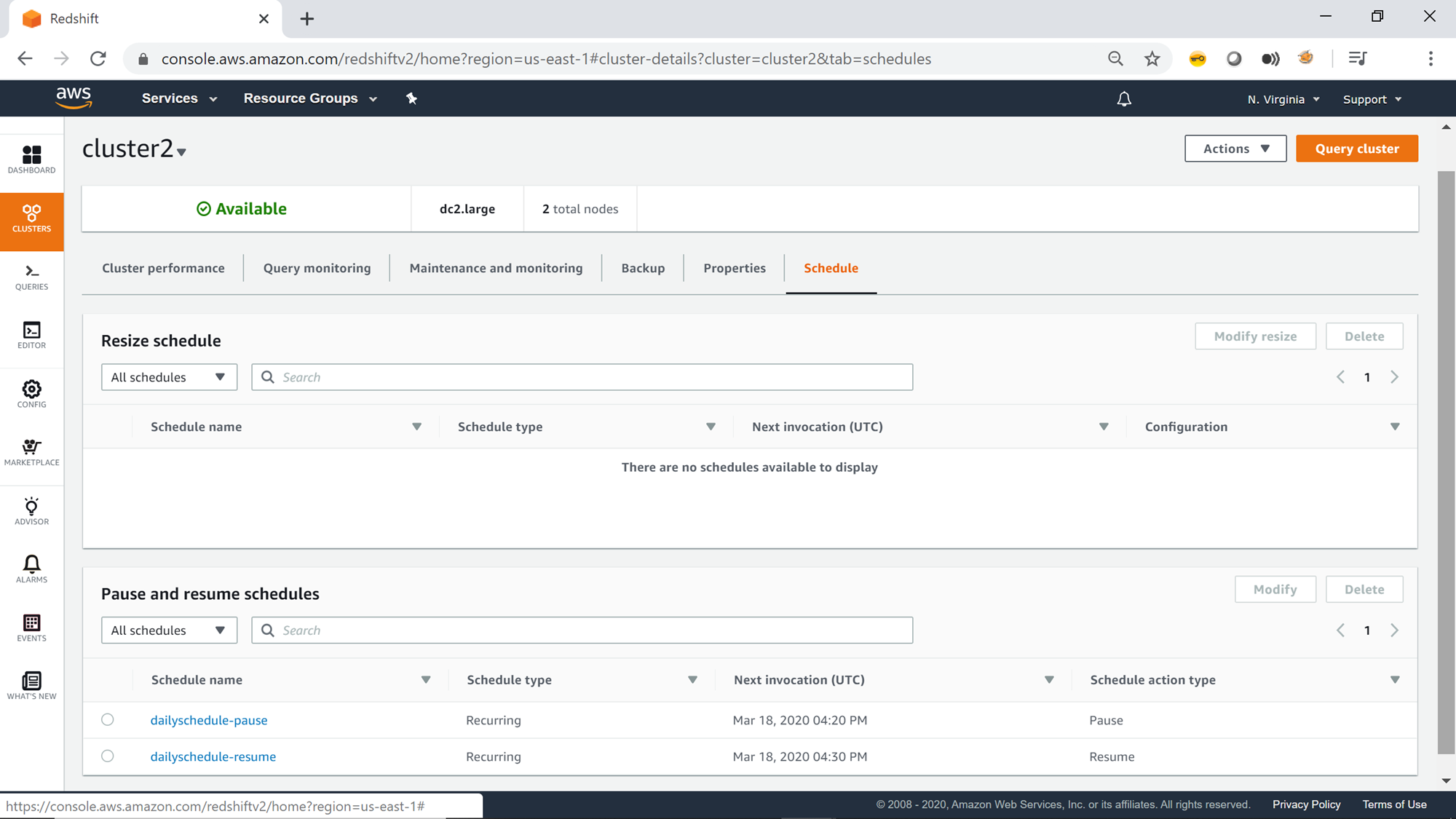
Once the schedule is created, you would be able to view the pause and resume schedule on the Schedule tab of the cluster properties page.
During the scheduled time, the cluster pause action would get triggered and you would find the status of the cluster changing to “Pausing” as shown below. The CPU Utilization and other compute metrics will start showing a downward graph as the cluster is going into Pause mode.
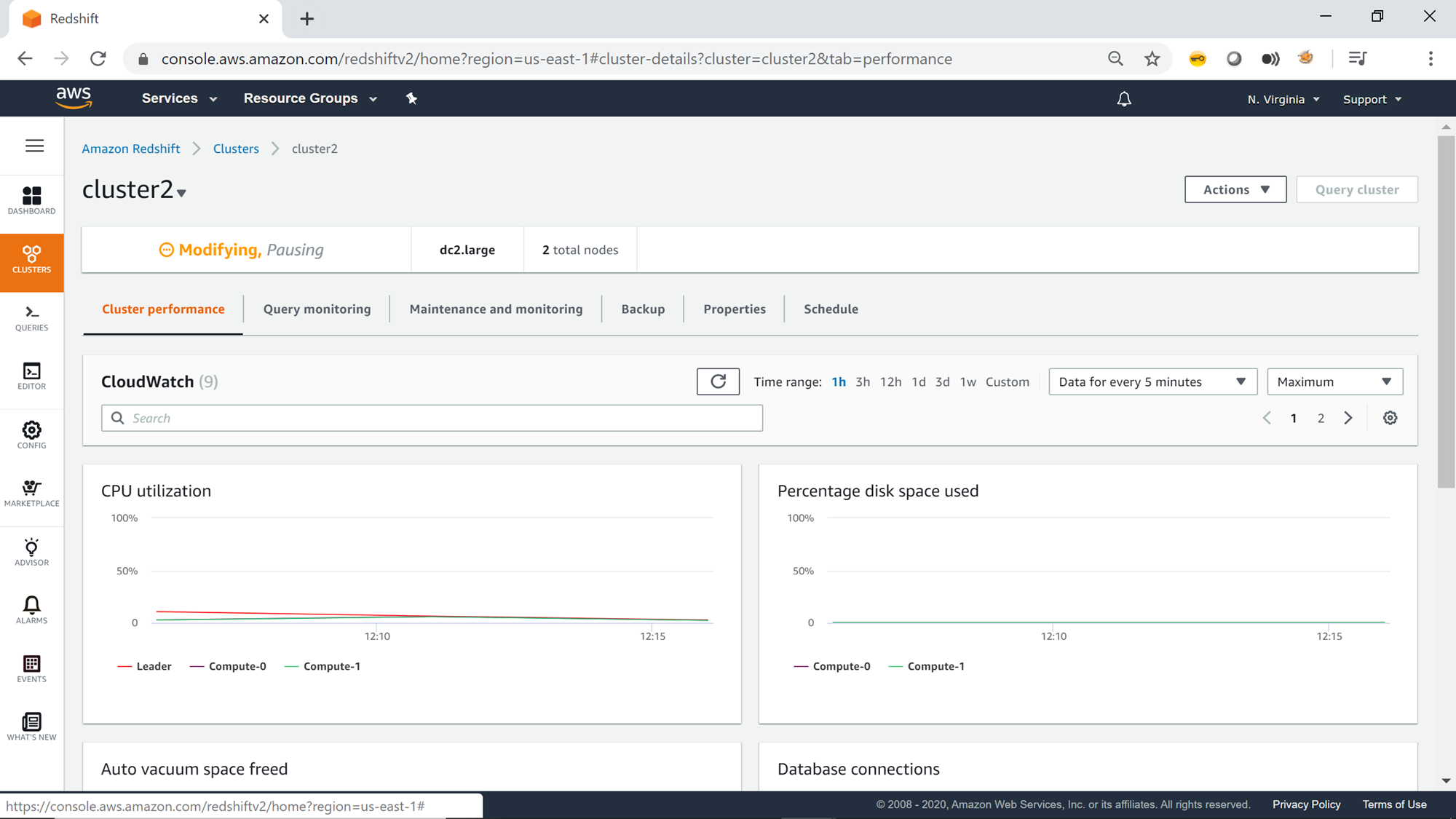
Once the cluster is in a Paused state, the cluster status would look as shown below. The cluster would also show a warning that it’s paused, and certain actions would not be available. Metrics like disk space used also won’t show details till the cluster is in Paused status.
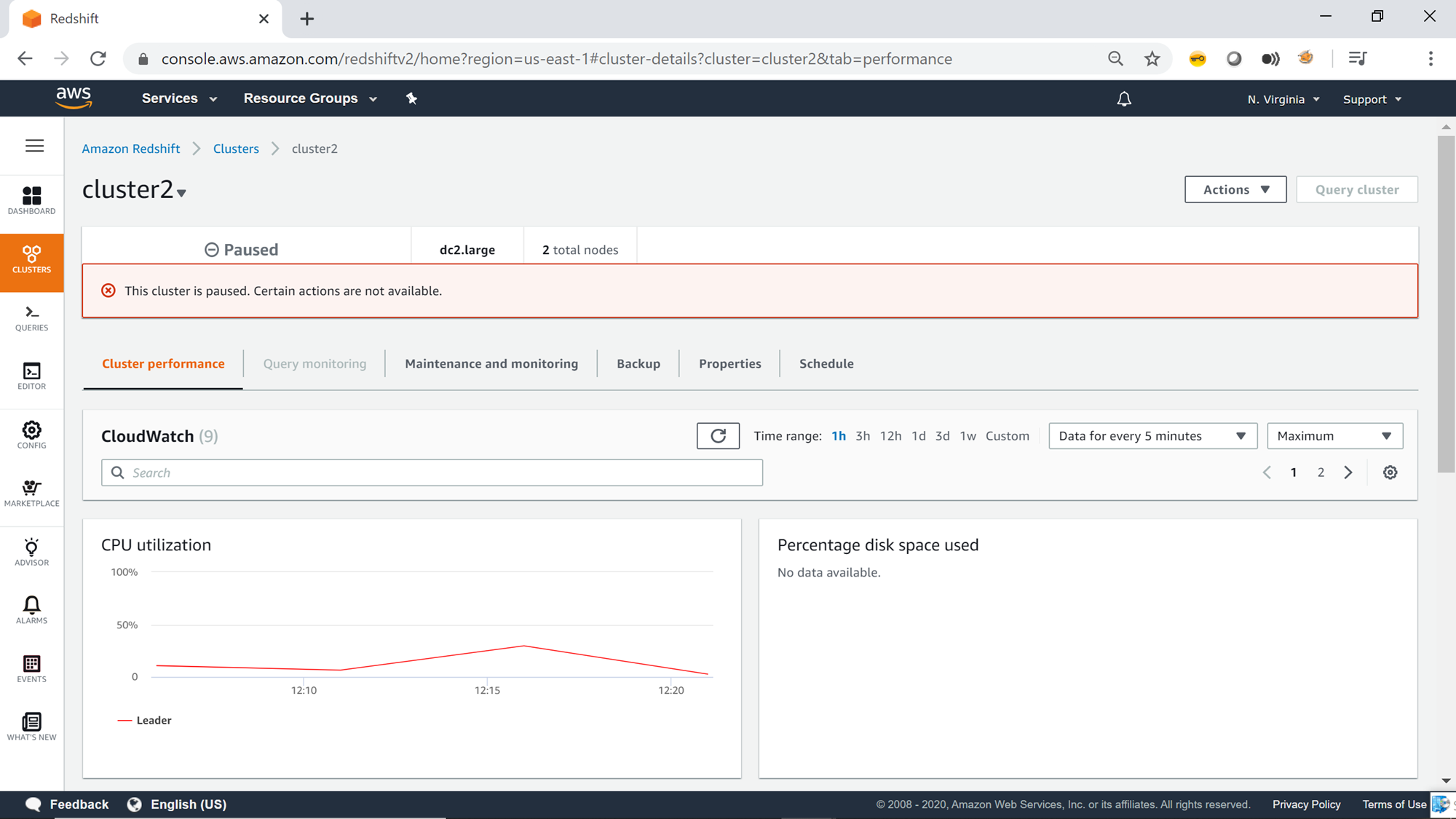
Once the Resume schedule triggers, you would again find the cluster status changing to “Resuming” as shown below. You would start getting the metrics back on the graphs and may find the compute metrics going high as the cluster is getting operational again.
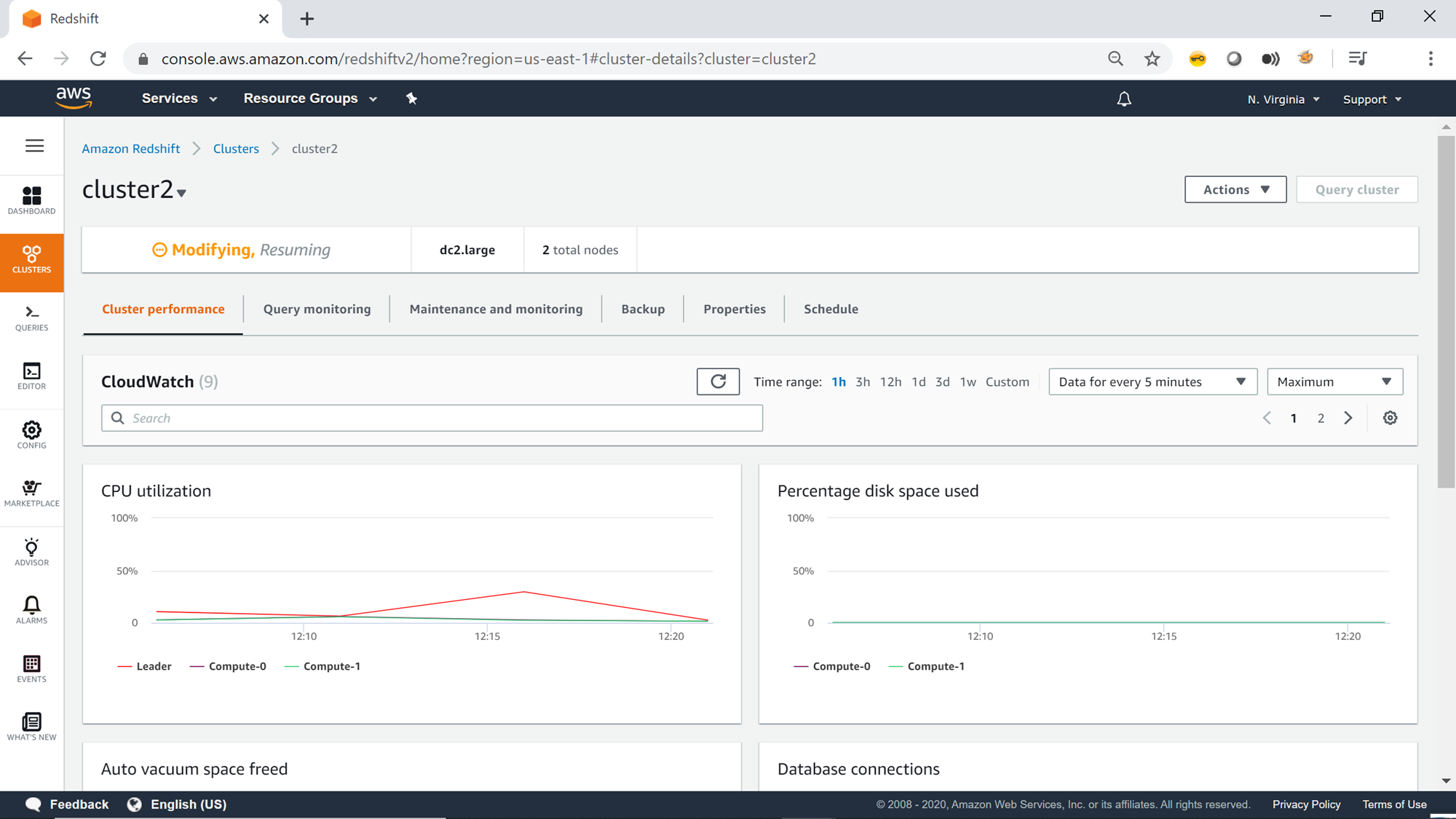
Once the cluster is becoming Available, you would find it in “Restoring” status before becoming available as shown below.
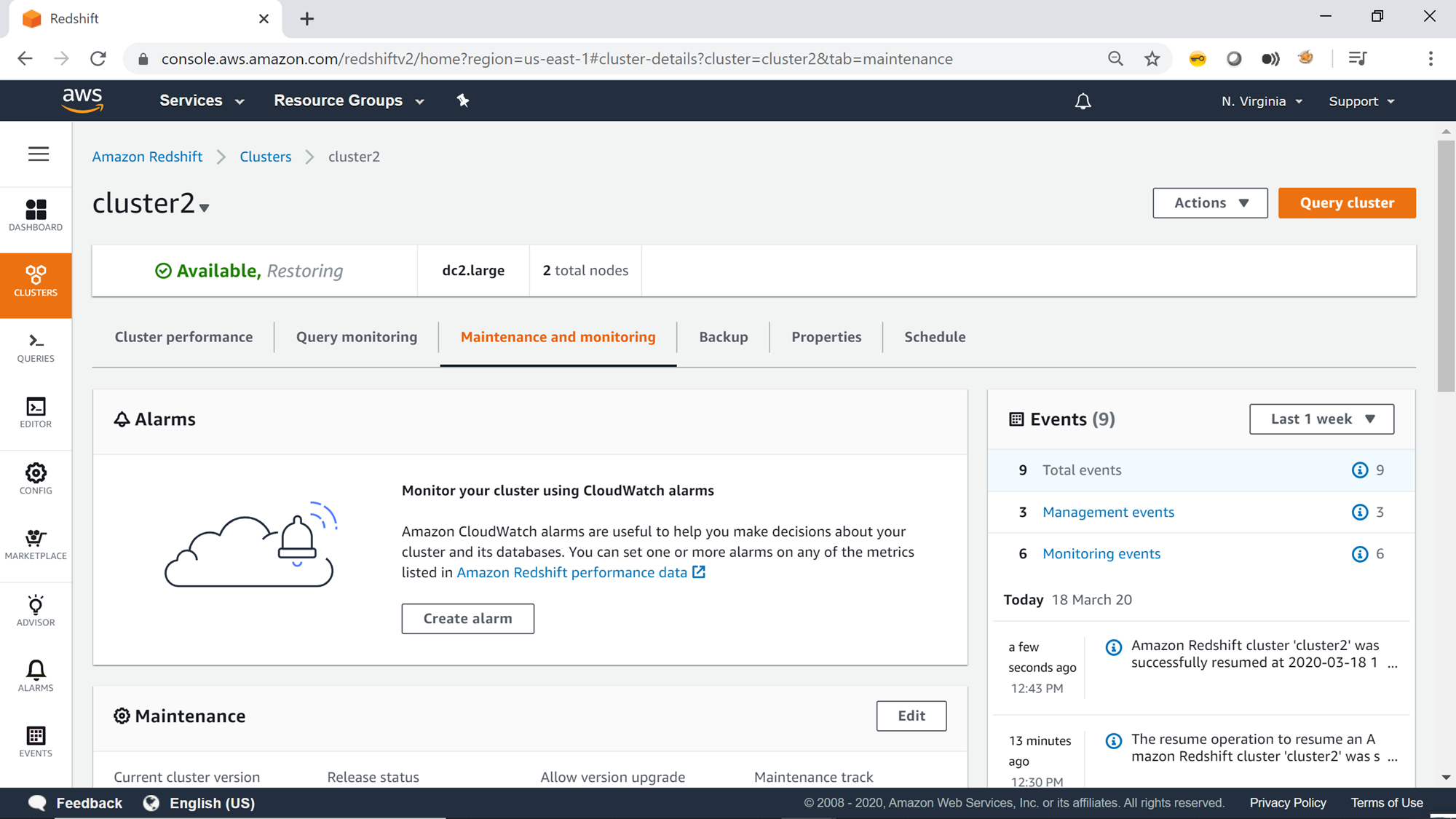
Once the cluster is in Available status, it would look as shown below. Now, it’s safe to start accessing the cluster and resume normal operations. You can configure CloudWatch alarms on the cluster from the Alarms section shown below, to receive notifications when the cluster gets paused and resumed.
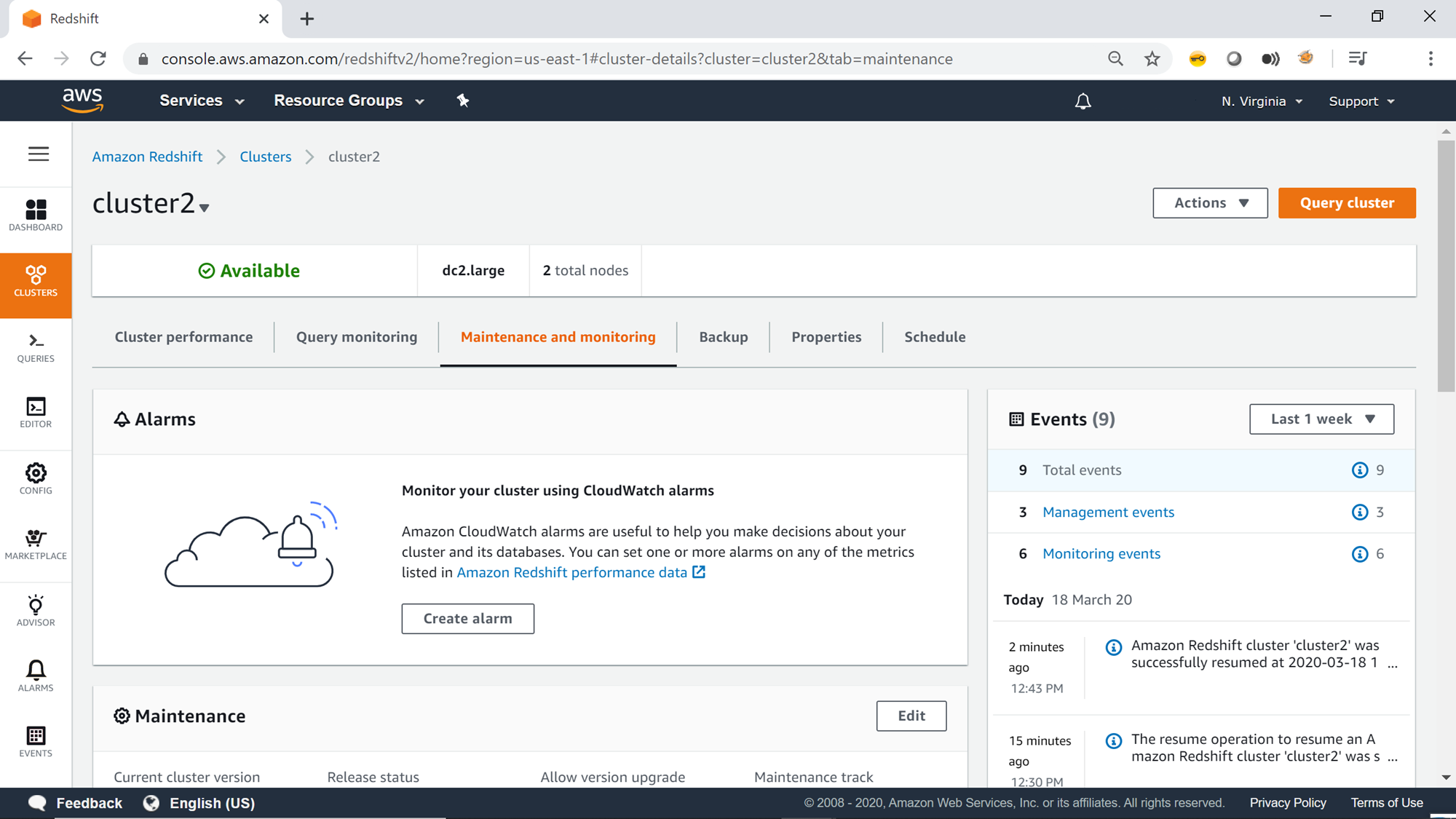
On the right-side you would find all the events that got generated, including when the cluster was getting paused and resumed. So, in case if you were not monitoring when the cluster got paused and resumed, you can always refer to the events to get this detail.
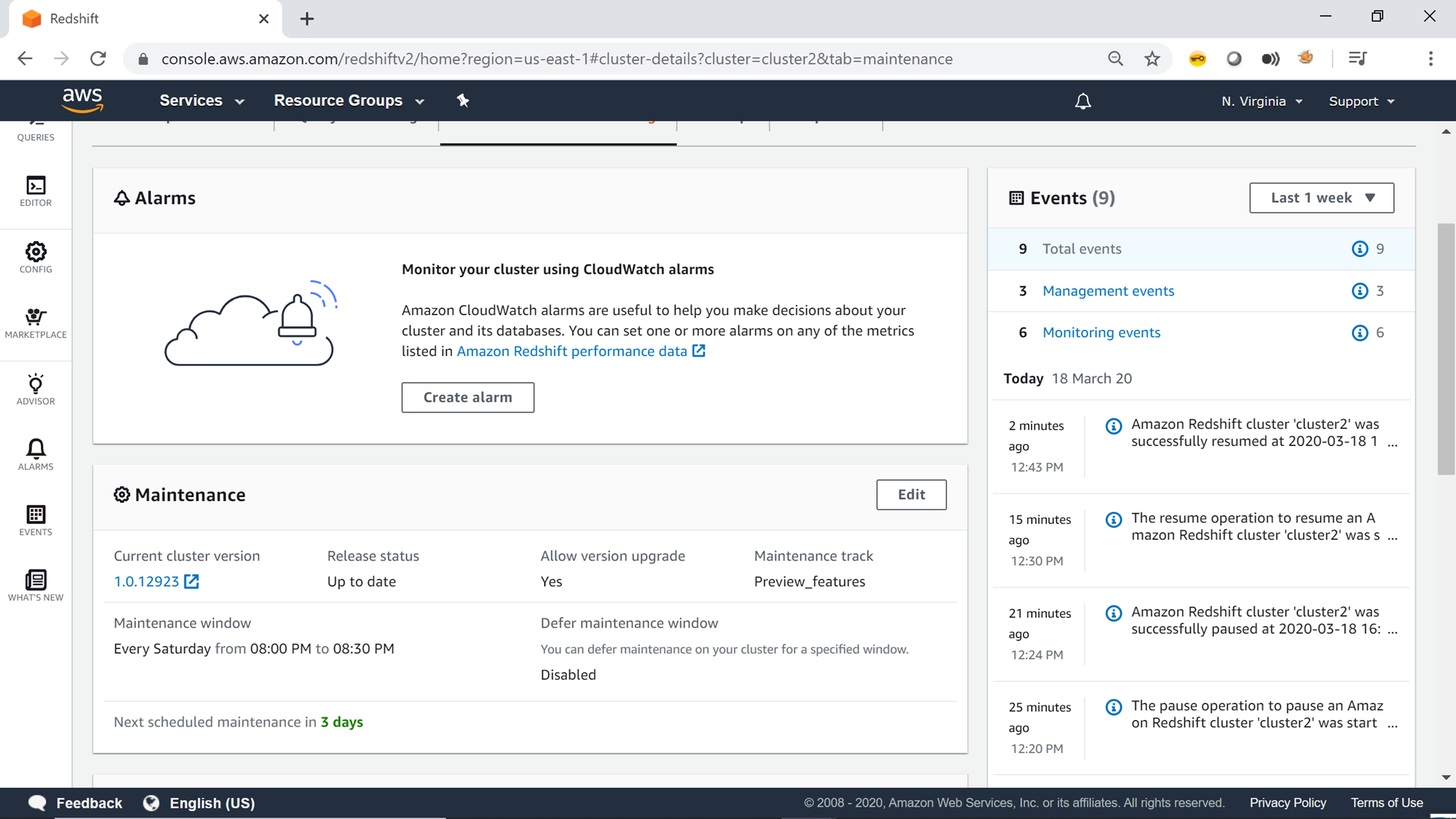
In this way, one can schedule pausing and resuming of the AWS Redshift cluster to save cluster usage costs.
Conclusion
In this article, we learned about the AWS Redshift cluster pricing model, as well as options to pause and resume cluster on-demand and on-schedule. We also understood what to expect when the cluster gets paused and while it gets resumed, and different options to monitor the cluster during these events.
Table of contents

He has worked internationally with Fortune 500 clients in various sectors and is a passionate author.
View all posts by Rahul Mehta
- Finding Duplicates in SQL - February 7, 2024
- MySQL substring uses with examples - October 14, 2023
- MySQL group_concat() function overview - March 28, 2023