
This article gives an overview of configuring AWS Redshift snapshots for scheduled data backup, data archival, as well as disaster recovery.
Introduction
AWS Redshift is one of the data repositories offered by AWS. It’s a columnar data warehouse service that is generally used for massive data aggregation and parallel processing of large datasets on the AWS cloud. As a part of data administration, backing up data for various purposes is one of the standard and mainstream activities in a data administration role. Like every data repository, Amazon Redshift too supports various features for database snapshots. In this article, we will learn different backup related features supported by Amazon Redshift.
AWS Redshift Setup
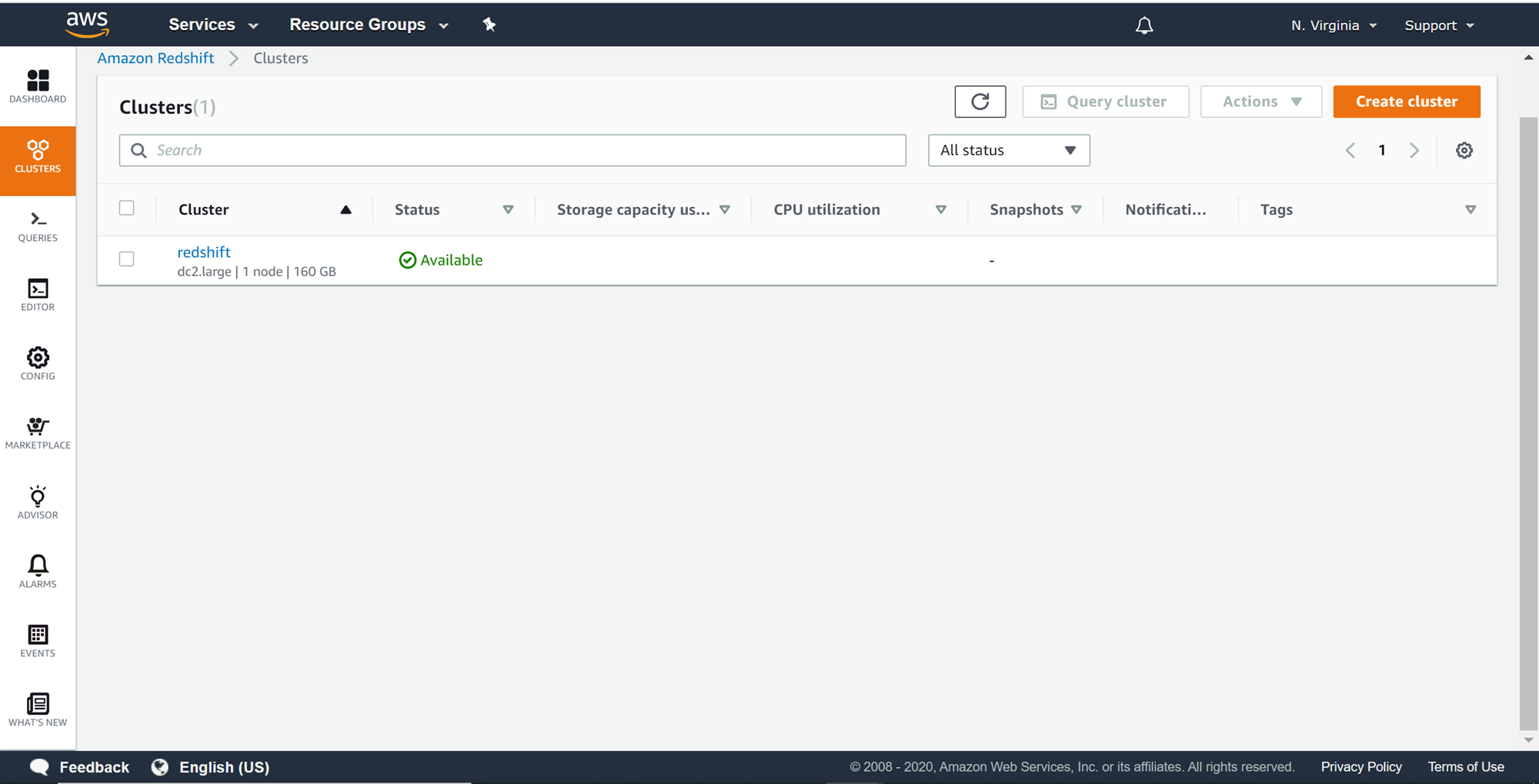
Firstly, we need a working Redshift cluster. Beginners can refer to this article, Getting started with AWS Redshift, to learn to create a new Redshift cluster. Once the cluster is in place, it would look as shown below on the Redshift Clusters page.
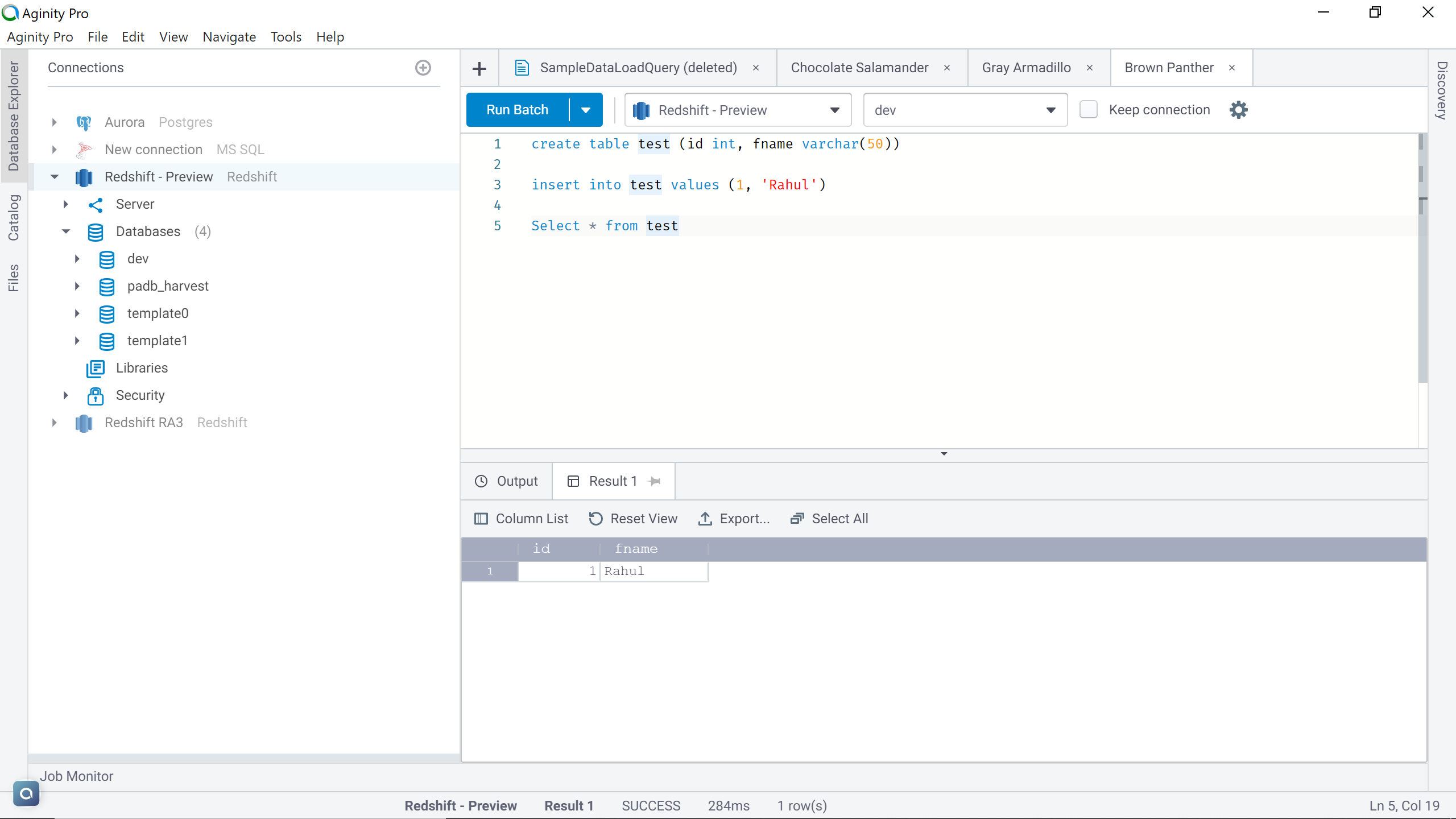
Though technically it’s possible to back up a totally blank cluster as well, but it’s recommended to create at least one database object and some data in it. Shown below are some sample queries that can create a basic table, insert a record and query the same. You can create a CSV file with some sample data using tools like Microsoft Excel, upload it in AWS S3 and load the data into a redshift table to create some sample data. You can refer to my last article, Load data into AWS Redshift from AWS S3, that explains how to accomplish it.
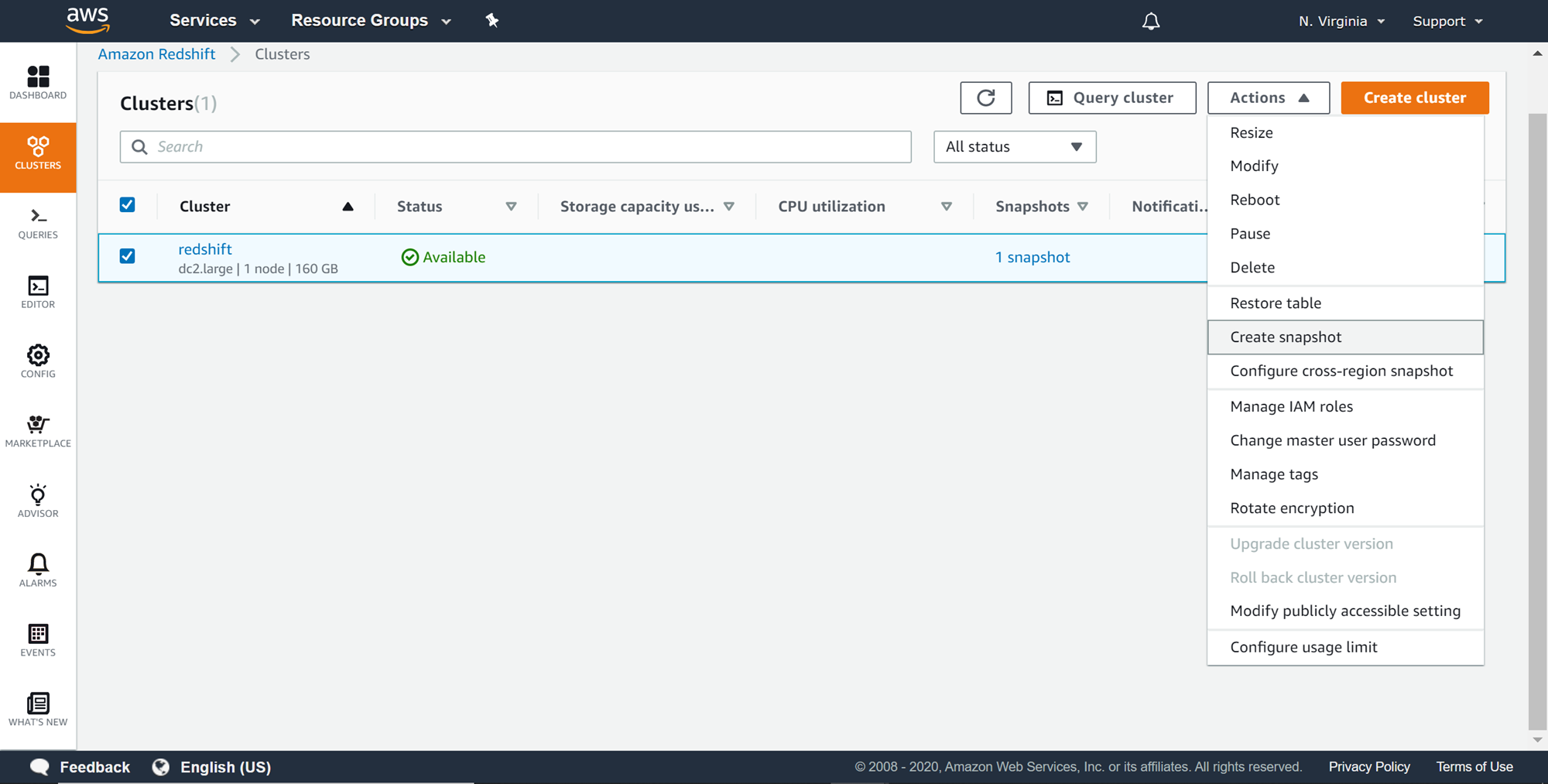
When an Amazon Redshift cluster is created, Automatic snapshots are enabled by default. Redshift periodically takes an automated incremental snapshot of the cluster every eight hours or 5 GB per node of changes. Amazon Redshift deletes automated snapshots every day (which is the default retention period for automated snapshots). It provides the ability to configure all the settings related to automated snapshots. This makes automated Snapshots the default choice for administrators to take ongoing incremental snapshots at the scheduled frequency. At times, there is a need to take a snapshot just before some important action, in which case, one has the option to take a manual snapshot. Once the required data for the purpose of this exercise in place, we can now navigate to the Actions menu where you would find the option to create snapshot as shown below.
Creating AWS Redshift snapshots
Once you click on Create snapshot option, a pop-up would appear as shown below. Provide a snapshot name and retention period. The default retention period is Indefinitely, meaning that once the manual snapshot it created, it will never expire till the snapshot owner decides to delete it manually.
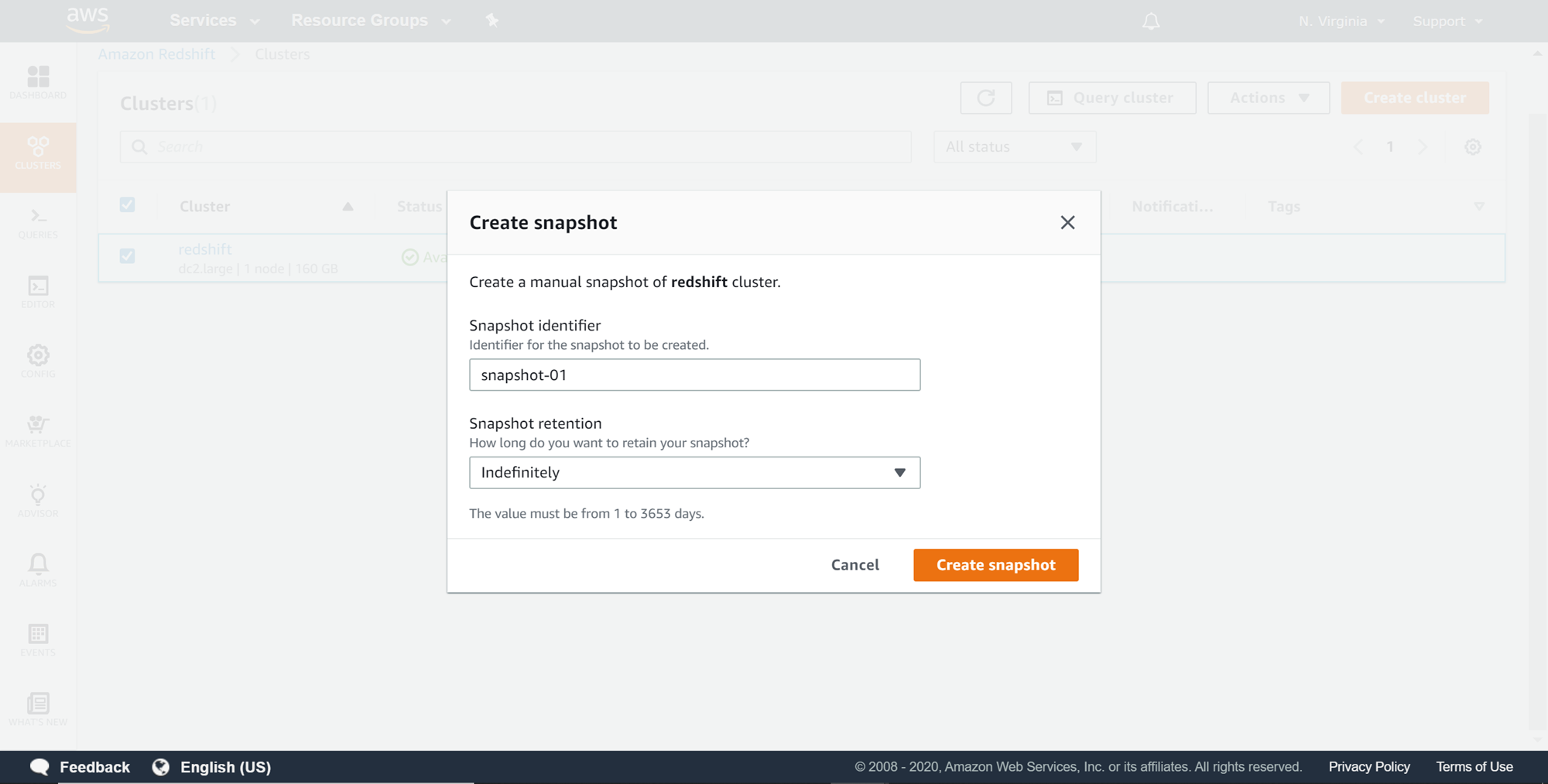
You can select the Custom value option to provide a custom duration for the snapshot retention period. Once the desired value is selected, click on Create snapshot button to start creating the snapshot.
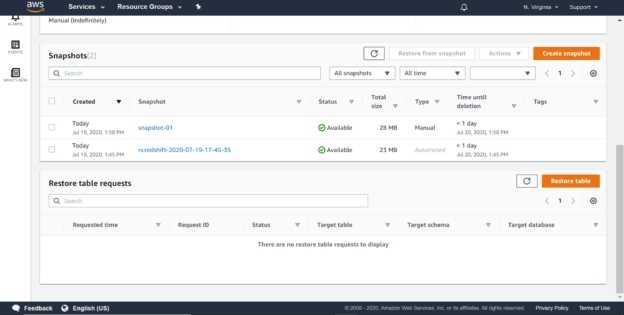
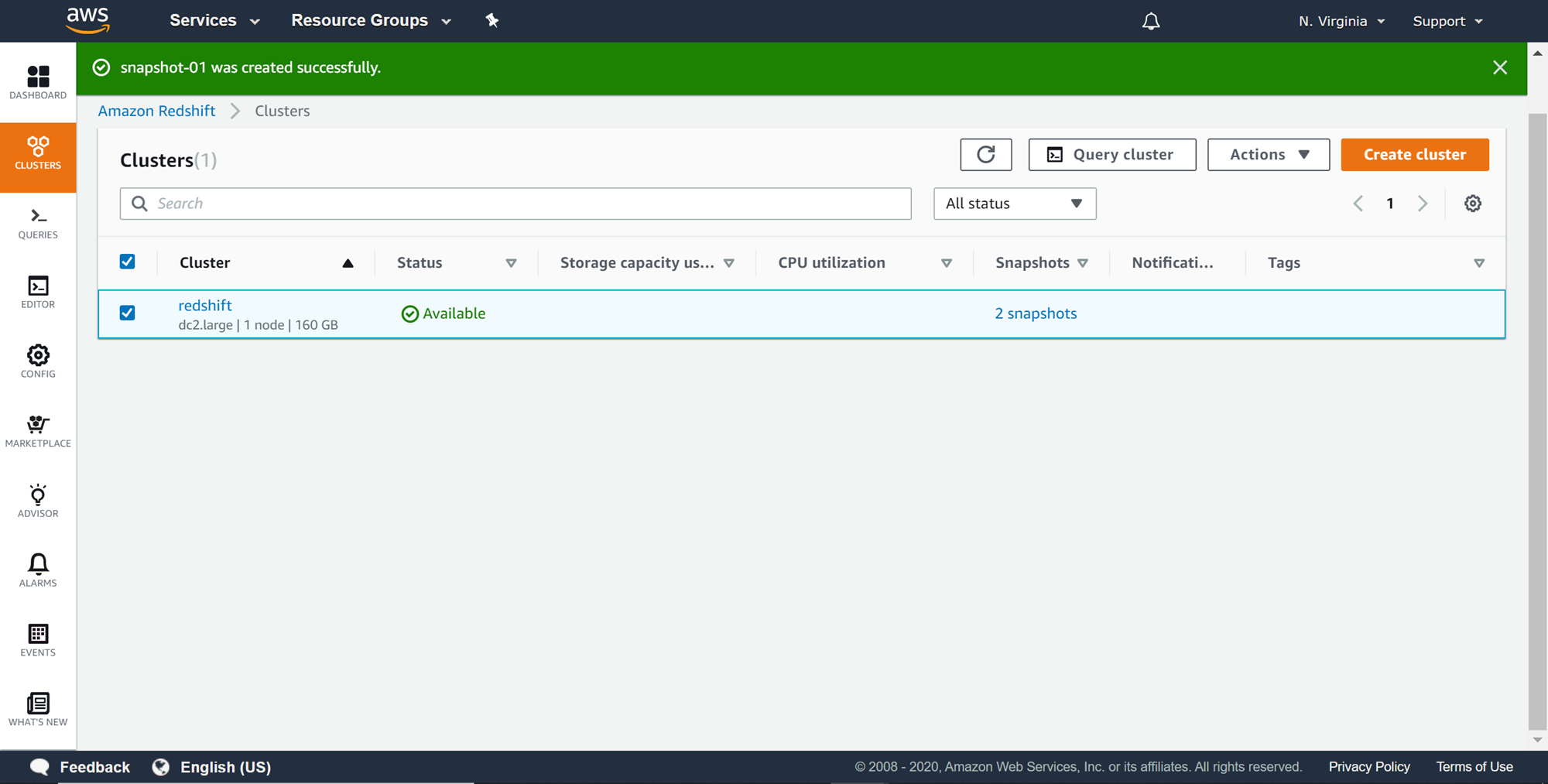
Click on the Clusters option from the left pane and you would find two snapshots for the cluster as shown below. Click on the snapshots links to view the snapshots created for this cluster.
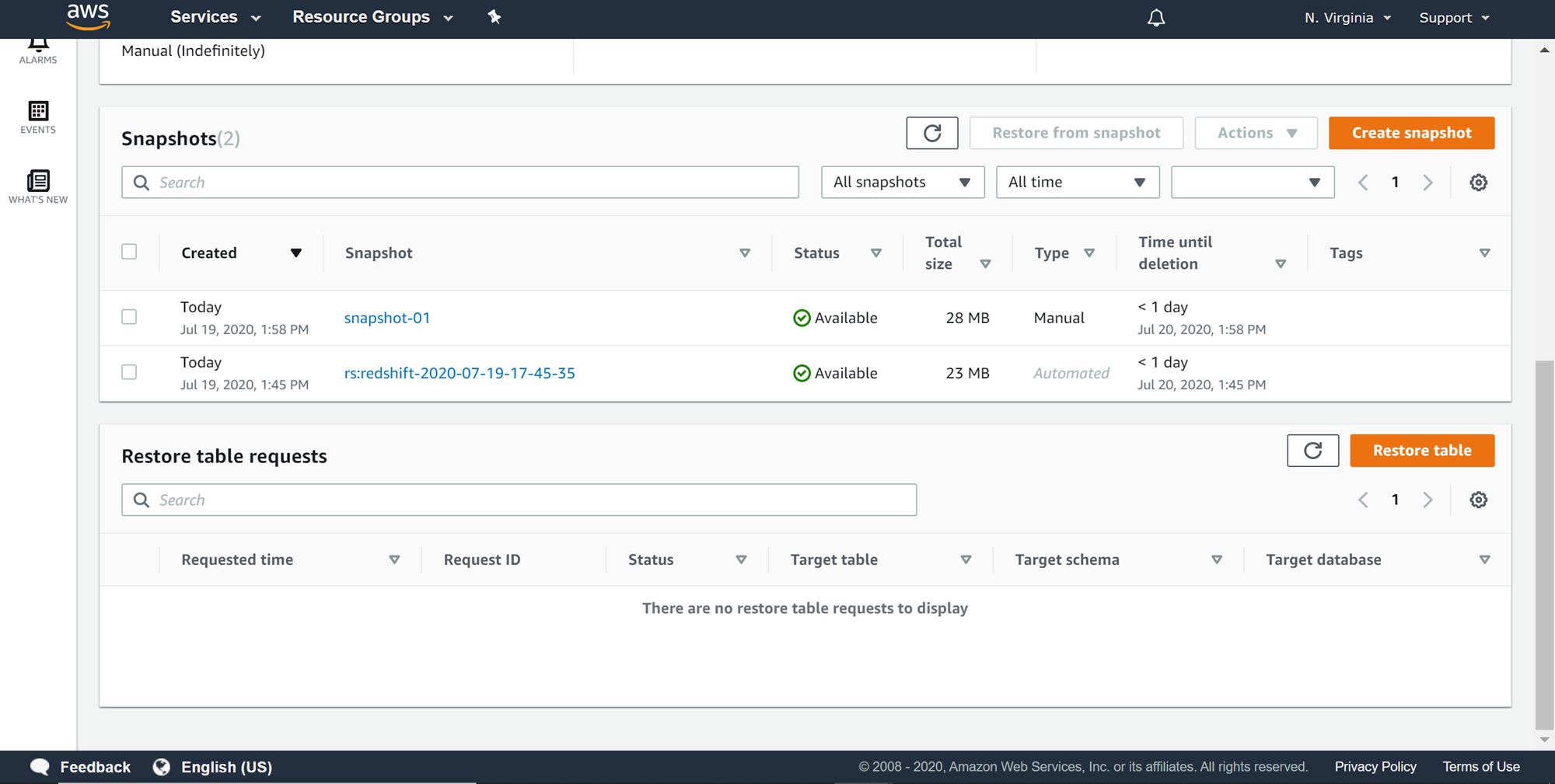
There are two snapshots available for this cluster. One is an automated snapshot that gets created when the cluster is created. This is the snapshot with the type Automated. The other snapshot is the one that we just created, with the type mentioned as Manual. You would find the difference in the size of the manual snapshot due to the additional data and the configuration information in the manual snapshot.
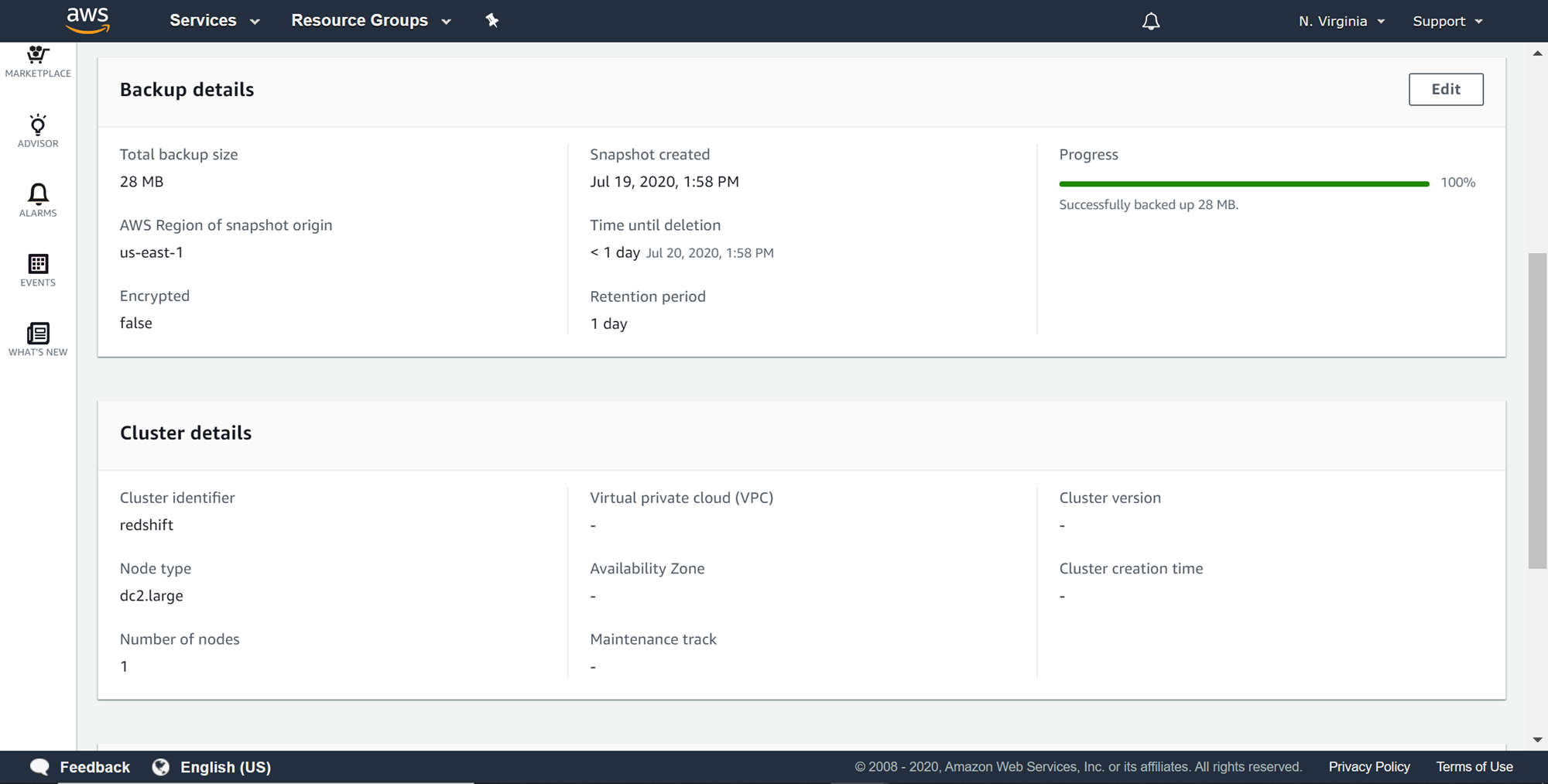
To view or modify the configuration of the manual snapshot, you can click on the name of the manual snapshot and it would show an interface as shown below. Backups of clusters with massive volumes of data may take a long time, and in those cases, this interface would show the progress of the snapshot and the rest of the details regarding the snapshot as well as the details of the cluster from which the snapshot was taken. This would be the default cluster configuration when the snapshot is being restored.
AWS Redshift Cross-Region Snapshots
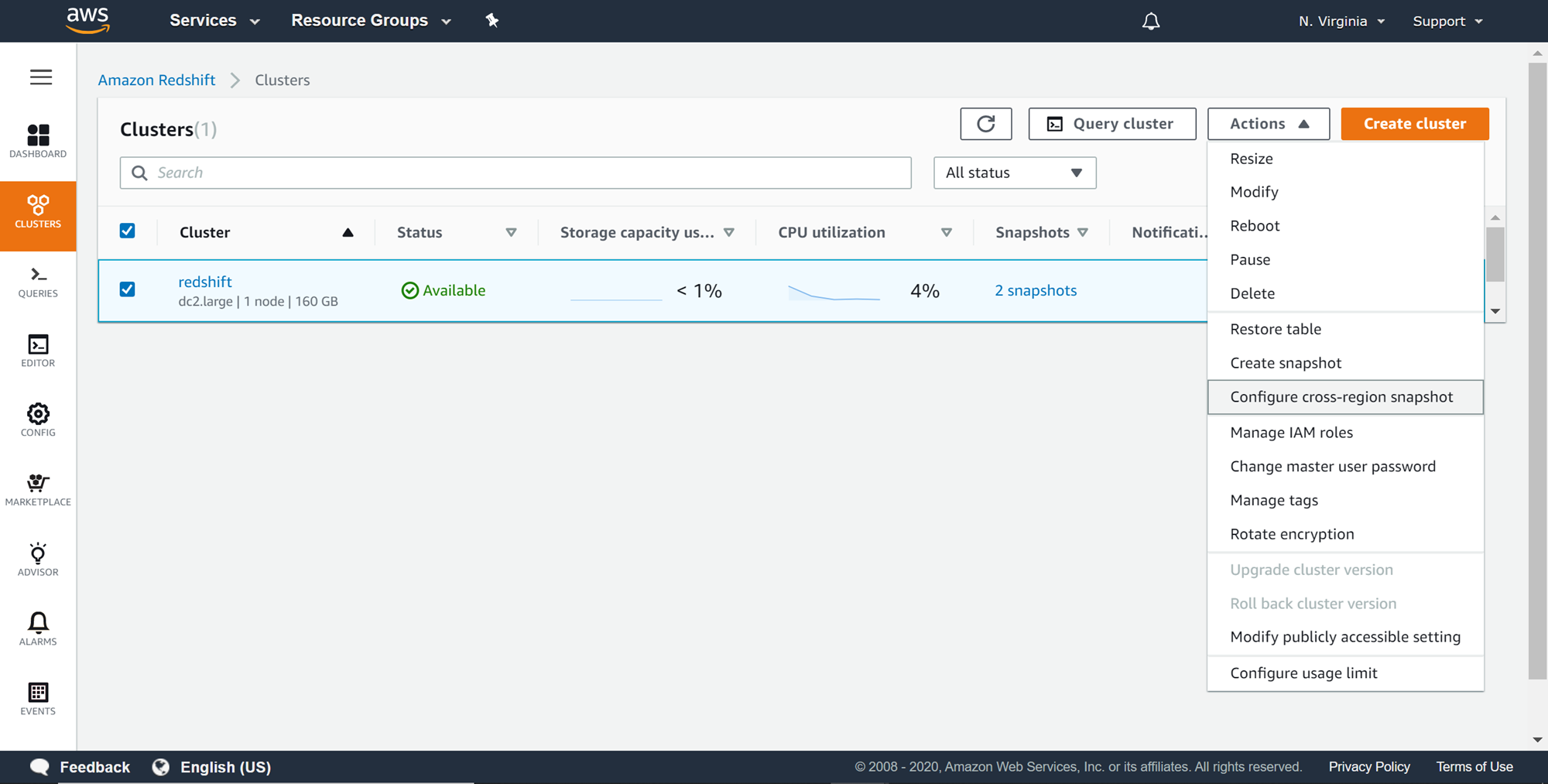
Every IT environment and component have a system or data recovery as well as disaster recovery considerations to ensure the solution and data are recoverable in case of system issues or disasters. From a data recovery perspective to recover from data corruption or data loss, incremental data backups are created in the same region as the cluster. From a disaster recovery perspective for data, in extremely rare scenarios where the entire region is disrupted due to a disaster, snapshots are stored in a different region that is physically distant from the primary location where the cluster is hosted. In this case, N. Virginia (us-east-1) is the primary region, so any other region except N.Virginia can be considered as a region for disaster recovery, for example, Ohio (us-east-2). AWS Redshift supports automated cross-region snapshots for disaster recovery purposes, which eliminates the need to self-manage the creation of snapshots in the primary region and copy the same to a different region. To accomplish the same, select the cluster, click on the Actions menu and select Configure cross-region snapshot as shown below.
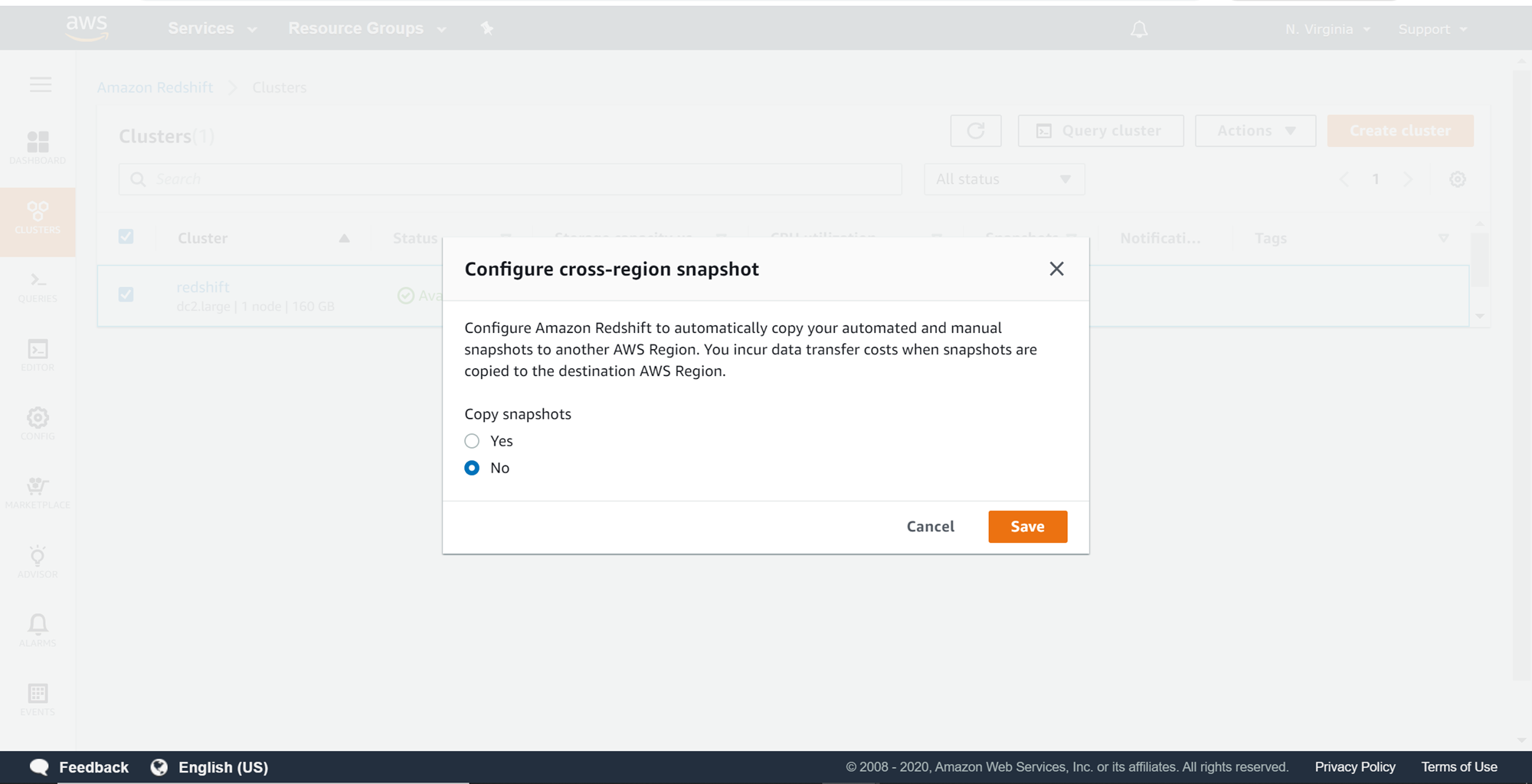
A pop-up would appear to confirm the copying of automated and manual snapshots to a new region. This would incur costs when snapshots are transferred from one region to another. Click on Yes in the copy snapshot options.
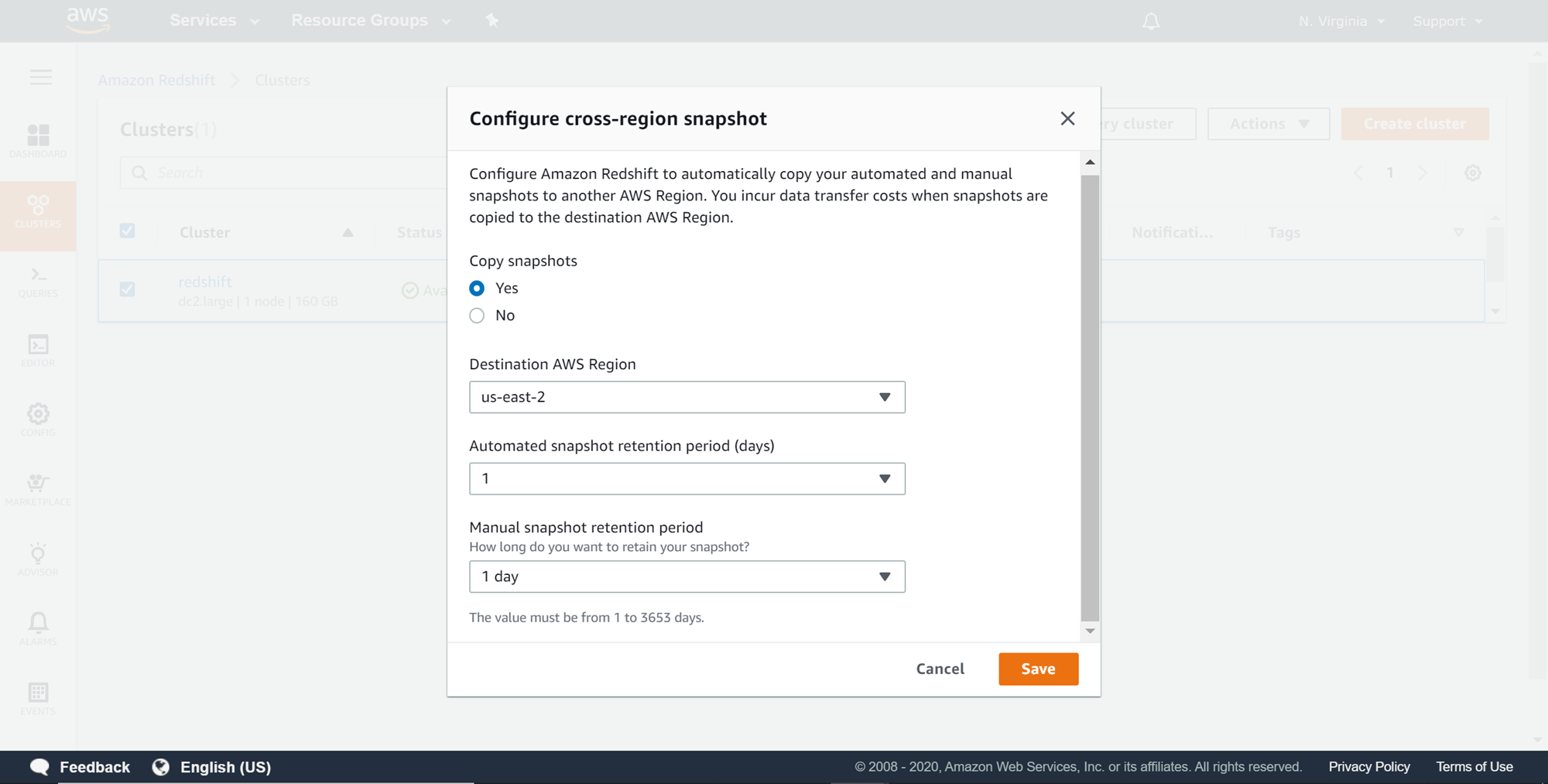
Select the destination region where we intend to copy the snapshots as shown below. Select the desired retention period of the snapshot in the destination region for manual and automated snapshots and click on the Save button.
Navigate to the backup tab of the AWS Redshift cluster properties, and you would find the cross-region snapshot settings as shown below.
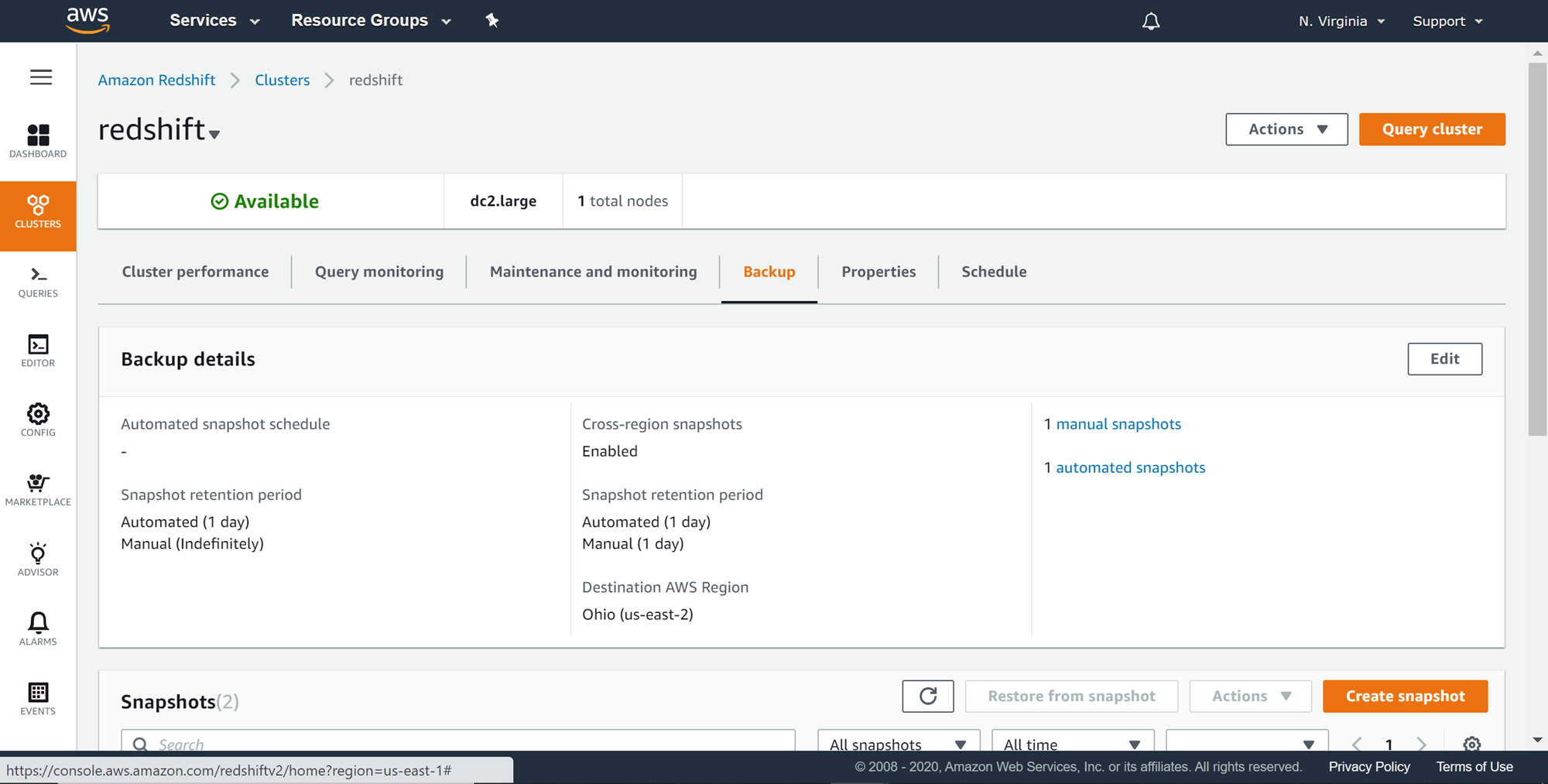
Scheduling AWS Redshift snapshots
Automated snapshots are created every eight hours by default, but often this frequency of snapshots may be either too aggressive or too passive depending on Recovery-Time-Objective and Recovery-Point-Objective of the solutions. Redshift provides an option for scheduling automated backups based on a customized duration as well as customized rules. To schedule automated backups, click on the schedule tab and an interface would appear to create snapshot schedules as shown below.
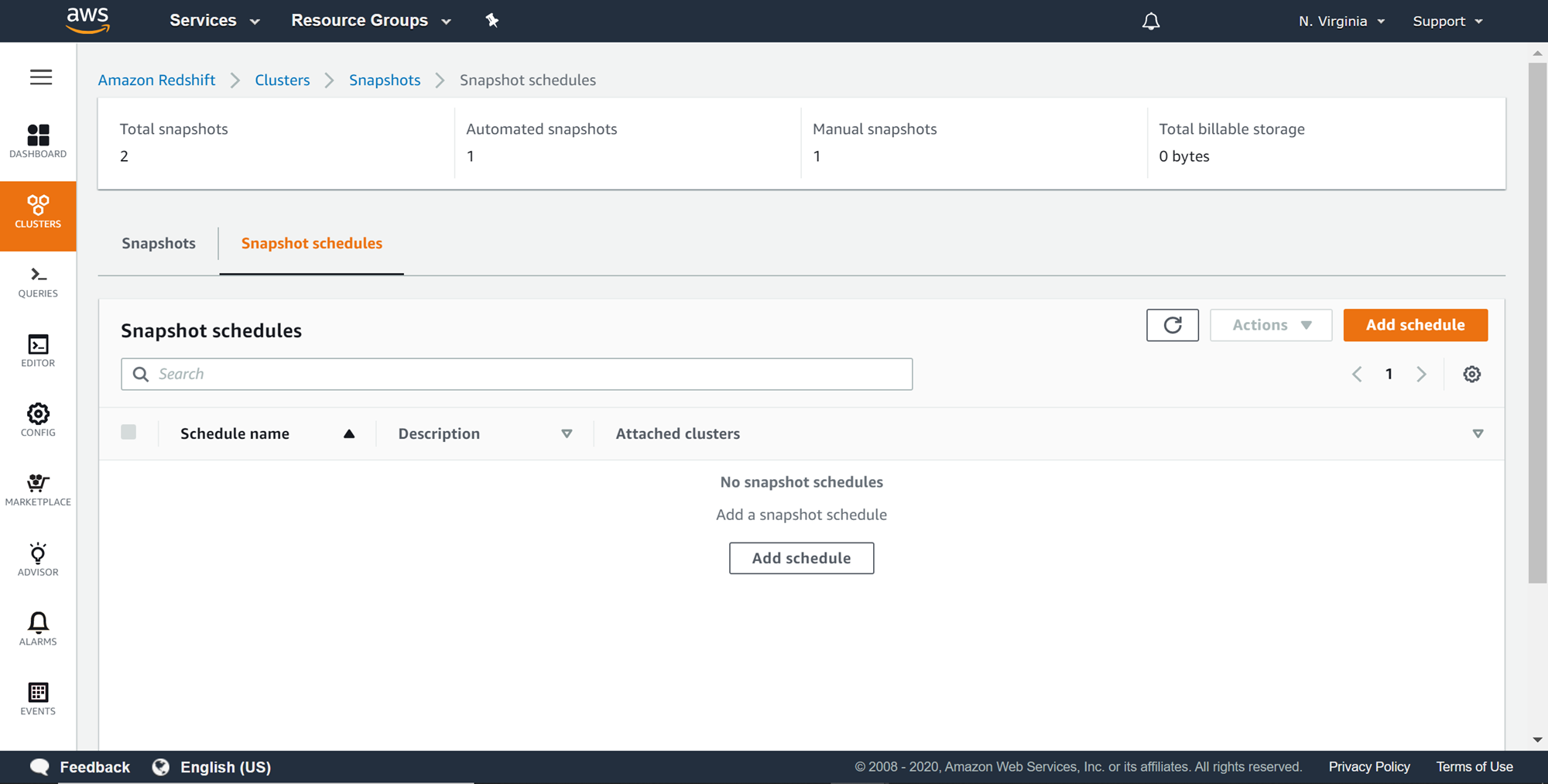
Click on the Add schedule button to create the schedule and a new wizard would open as shown below. Provide a schedule name and a relevant description for the schedule. The next detail is to configure the duration or the rule criteria based on which the snapshot should be scheduled and executed.
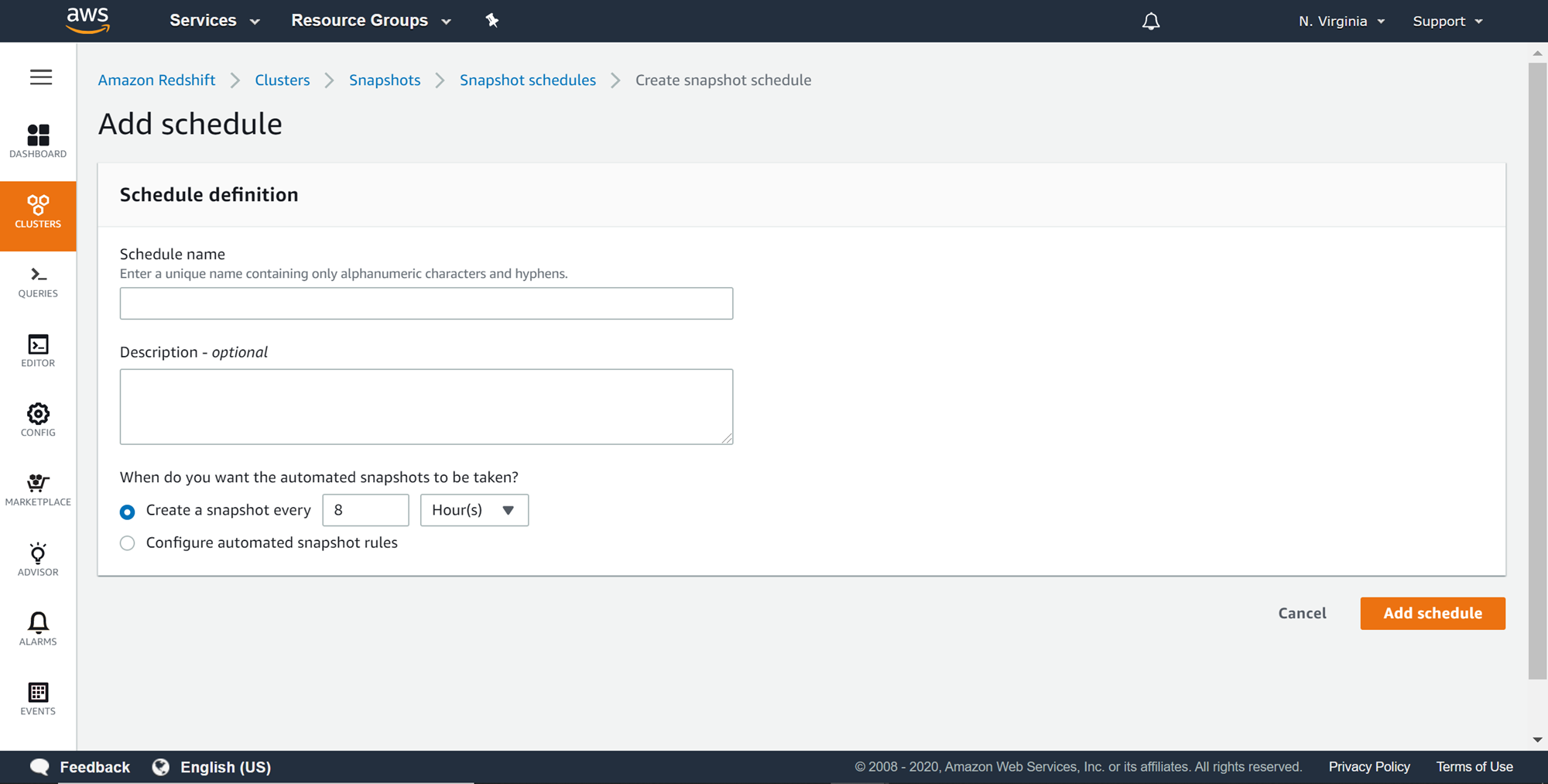
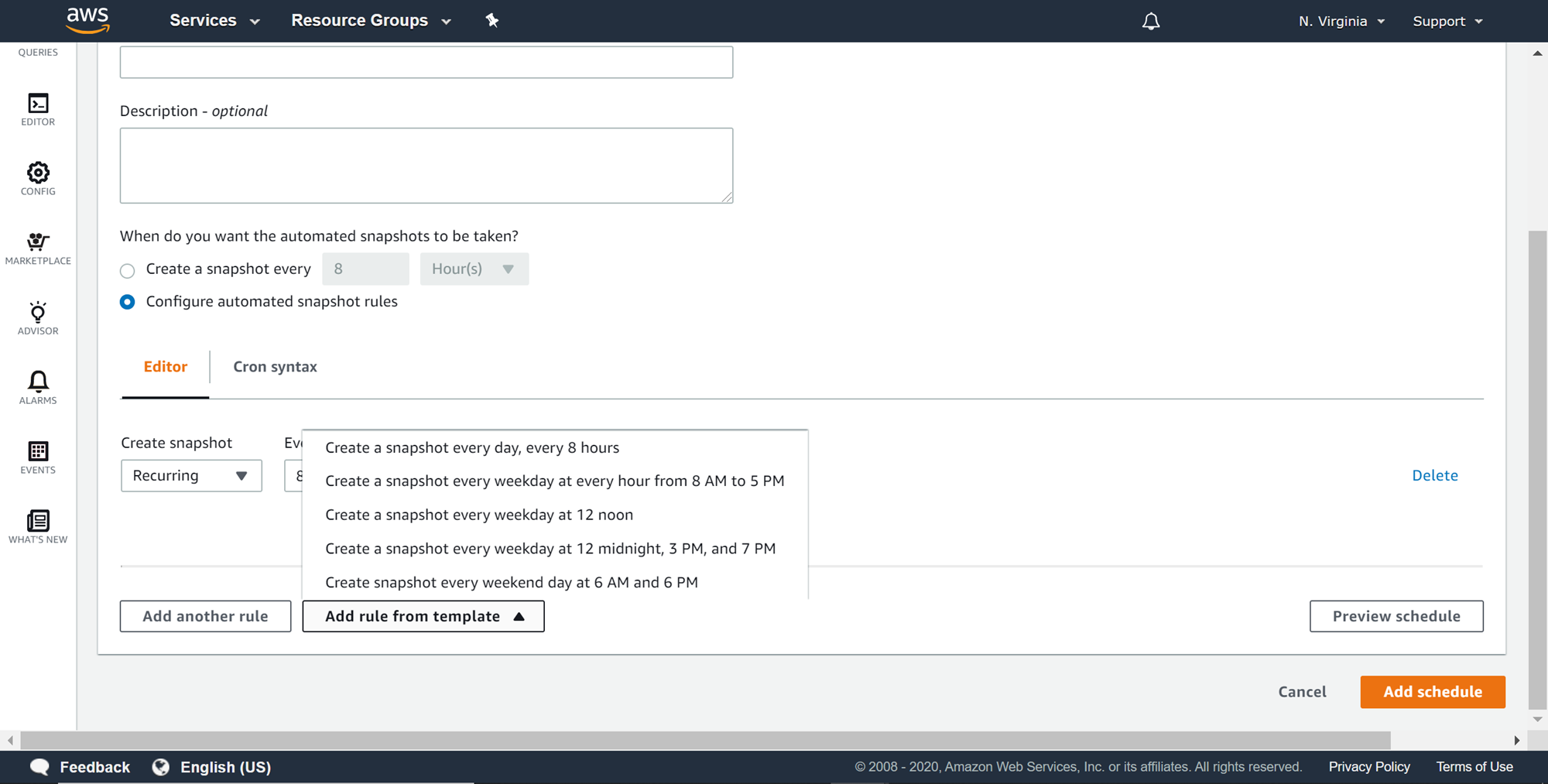
To configure the snapshot based on rules, select the Configure automated snapshot rules option. This will present more options as shown below. You can add rules from the templates like creating a snapshot at the duration of the day. You can also choose whether to create a recurring or non-recurring snapshot. You can click on the Preview schedule button to preview the schedule, and once the details are confirmed, click on the Add schedule button which will create or alter the duration of the automated snapshot schedule.
Deleting AWS Redshift Manual snapshots
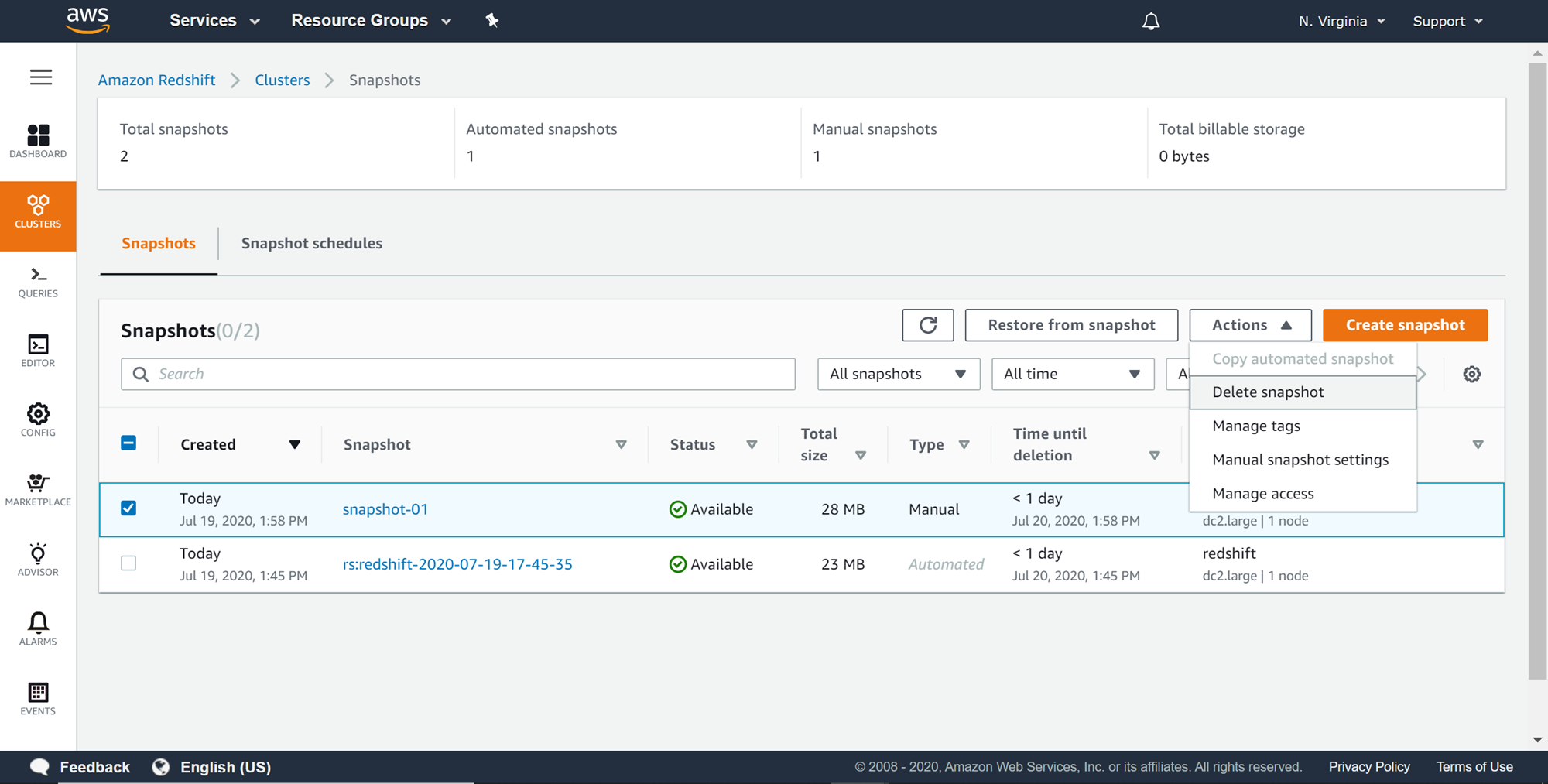
At times, one may need to delete manual snapshots before the retention period. Amazon Redshift supports the deleting of manual snapshots. From the snapshots tab, select the manual snapshot, click on the Actions menu, and select the Delete snapshot button to delete the snapshot as shown below.
AWS Redshift provides various features for automated and manual snapshot management which makes the job of database administrators (DBAs) easier.
Conclusion
In this article, we learned how to create and configure manual as well as automated snapshots in AWS Redshift. We learned how to automate snapshot creation in a cross-region for disaster recovery purposes, and schedule automated backups based on custom criteria as well as custom rules. And finally, we learned how to delete manual snapshots before the retention period of the snapshot expires.
Table of contents

He has worked internationally with Fortune 500 clients in various sectors and is a passionate author.
View all posts by Rahul Mehta
- Finding Duplicates in SQL - February 7, 2024
- MySQL substring uses with examples - October 14, 2023
- MySQL group_concat() function overview - March 28, 2023